访问地址:https://ai-ops-9g0.pages.dev/
/Users/baidu/Desktop/ke/ai/tools/ai-ops-platform
有几个地方注意
Prompt 调试模块需要真实 API Key 才能跑通流式输出,其他三个模块(知识库、监控、Token统计)全是 Mock 数据,不需要 Key 就能看效果。
监控看板的实时数据是模拟 SSE 推送,每 2 秒自动刷新一次,打开页面就能看到数据跳动。
Token 用量页的导出按钮可以直接用,会下载一个 CSV 文件。
AI 智能运营平台 · 技术文档
读懂代码 → 理解业务 → 能向面试官清楚讲解
一、项目定位与业务背景
这个项目解决什么问题
公司 AI 产品上线后,运营团队面临三个核心痛点:
痛点一:Prompt 改版依赖研发 每次想调整 AI 的回答风格,运营都要提需求给研发,研发改配置文件、重新部署,一个来回平均 3 天。这套平台让运营在界面上自己管理 Prompt,当天就能改完上线。
痛点二:知识库维护没有可视化工具 RAG(检索增强生成)的知识库是一堆向量化后的文档分块,运营根本不知道哪些内容被检索到了、哪些文档压根没人问。这套平台把分块内容可视化,还能看到每个分块的命中频率。
痛点三:AI 效果好不好,没有数据 AI 回复慢不慢、用户满不满意、Token 花了多少钱,全靠后端同学手动查日志。这套平台把这些指标实时展示出来,运营自己就能看。
用户角色
- 运营人员:使用 Prompt 管理、知识库管理模块,日常调优 AI 效果
- 产品经理:使用监控看板,关注对话质量
- 技术负责人:使用 Token 用量统计,控制 AI 成本
二、技术架构
整体架构图
┌─────────────────────────────────────────────────┐
│ 前端层 │
│ Vue3 + Vite + Element Plus + ECharts │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────────────┐ │
│ │Prompt管理│ │知识库管理│ │监控看板/Token统计 │ │
│ └──────────┘ └──────────┘ └──────────────────┘ │
└─────────────┬───────────────────────┬────────────┘
│ REST API │ SSE 推送
▼ ▼
┌─────────────────────┐ ┌─────────────────────┐
│ DeepSeek API │ │ 后端服务(Mock) │
│ 流式输出接口 │ │ 实时指标推送 │
└─────────────────────┘ └─────────────────────┘技术选型说明
| 技术 | 选型 | 选择原因 |
|---|---|---|
| 框架 | Vue3 Composition API | 逻辑复用好,响应式更直观 |
| 构建 | Vite | 开发启动快,HMR 毫秒级 |
| 组件库 | Element Plus | 企业后台最成熟的生态 |
| 状态管理 | 无(局部 ref) | 模块间无共享状态,不需要全局 store |
| 图表 | ECharts | 功能全面,配置灵活 |
| AI 接口 | DeepSeek(OpenAI 兼容) | 国内速度快,价格低,接口和 OpenAI 完全兼容 |
目录结构详解
src/
├── api/
│ ├── deepseek.js ← AI 接口封装(流式 + 普通两种调用)
│ └── monitor.js ← SSE 监控服务(真实项目替换为 EventSource)
├── components/
│ └── layout/
│ └── BasicLayout.vue ← 整体框架:侧边栏 + 顶部 Header
├── router/
│ └── index.js ← 路由配置(4个子路由)
├── utils/
│ └── mockData.js ← 所有 Mock 数据(面试时说明这里对接真实接口)
└── views/
├── prompt/ ← Prompt 管理页
├── knowledge/ ← 知识库管理页
├── monitor/ ← 监控看板页
└── token-stats/ ← Token 用量统计页三、核心模块详解
模块一:Prompt 管理
业务流程
新建版本(草稿)→ 在线调试(测试效果)→ 配置 A/B 测试 → 对比数据 → 上线关键代码讲解
1. 版本列表(**PromptView.vue**)
// versions 是响应式数组,存储所有 Prompt 版本
const versions = ref([...mockPromptVersions])
// activeVersion:当前上线的版本(status === 'active')
// 用 computed 自动从 versions 中找,不需要手动维护
const activeVersion = computed(() =>
versions.value.find(v => v.status === 'active')
)
// 上线操作:把之前 active 的版本改为 archived,再把新版本设为 active
function setActive(row) {
versions.value.forEach(v => {
if (v.status === 'active') v.status = 'archived'
})
row.status = 'active'
}面试讲解要点:上线操作的逻辑是"先归档再上线",不能直接改状态,因为要保证任意时刻只有一个 active 版本。
2. Diff 对比视图
这是技术含量比较高的部分,面试官可能会追问实现方式。
// diffLines 是 computed,自动响应 activeVersion 和 selectedVersion 的变化
const diffLines = computed(() => {
const leftText = activeVersion.value?.content || ''
const rightText = selectedVersion.value?.content || ''
// 按换行符分割成行数组
const leftLines = leftText.split('\n')
const rightLines = rightText.split('\n')
const maxLen = Math.max(leftLines.length, rightLines.length)
const left = [], right = []
for (let i = 0; i < maxLen; i++) {
const l = leftLines[i] ?? ''
const r = rightLines[i] ?? ''
// 逐行对比,不相同的行标记为 removed/added
left.push({ text: l, type: l !== r ? 'removed' : '' })
right.push({ text: r, type: l !== r ? 'added' : '' })
}
return { left, right }
})面试讲解要点:这里用的是逐行简单对比,不是 Myers 差分算法。简单对比的局限是"插入一行后所有后续行都会标红",真实项目如果要做精确的行级 diff,需要引入 diff 库(如 diff、jsdiff)。这里用简单方案是因为 Prompt 内容通常不长,简单方案够用且没有额外依赖。
3. A/B 测试流量权重联动
// A 的权重用 v-model 绑定到 el-slider
// 当 A 的权重变化时,B 自动等于 100 - A
function onWeightChange(val) {
abTest.value.weightB = 100 - val
}面试讲解要点:流量分配逻辑在后端执行,前端只负责提交配置。这是一个重要的设计原则——分流必须在服务端控制,前端控制会被用户绕过,也无法保证统计口径的准确性。
4. 流式输出调试(核心难点)
// streamChat 在 api/deepseek.js 中封装
// 返回一个 abort 函数,方便用户中止生成
abortFn = streamChat(
messages,
// onChunk:每个 token 到来时触发
// 把 token 追加到 streamBuffer,Vue 响应式自动更新 UI
(chunk) => {
streamBuffer.value += chunk
scrollToBottom() // 每次有新内容就滚动到底部
},
// onDone:流结束时触发
// 把完整内容存入消息列表,清空 streamBuffer
(fullContent, usage) => {
streaming.value = false
debugMessages.value.push({
id: Date.now(),
role: 'assistant',
content: fullContent
})
streamBuffer.value = ''
lastUsage.value = usage // 保存 token 用量,展示给用户
},
// onError:请求失败时触发
(err) => {
streaming.value = false
ElMessage.error('请求失败:' + err.message)
}
)面试讲解要点:流式输出的关键设计是"流式过程用 streamBuffer 暂存,完成后转移到消息列表"。不能边流边存到消息列表,因为消息列表里的内容是"已完成的消息",流式过程中的内容是"未完成的消息",两者在 UI 上的展示方式不同(未完成的有打字机光标)。
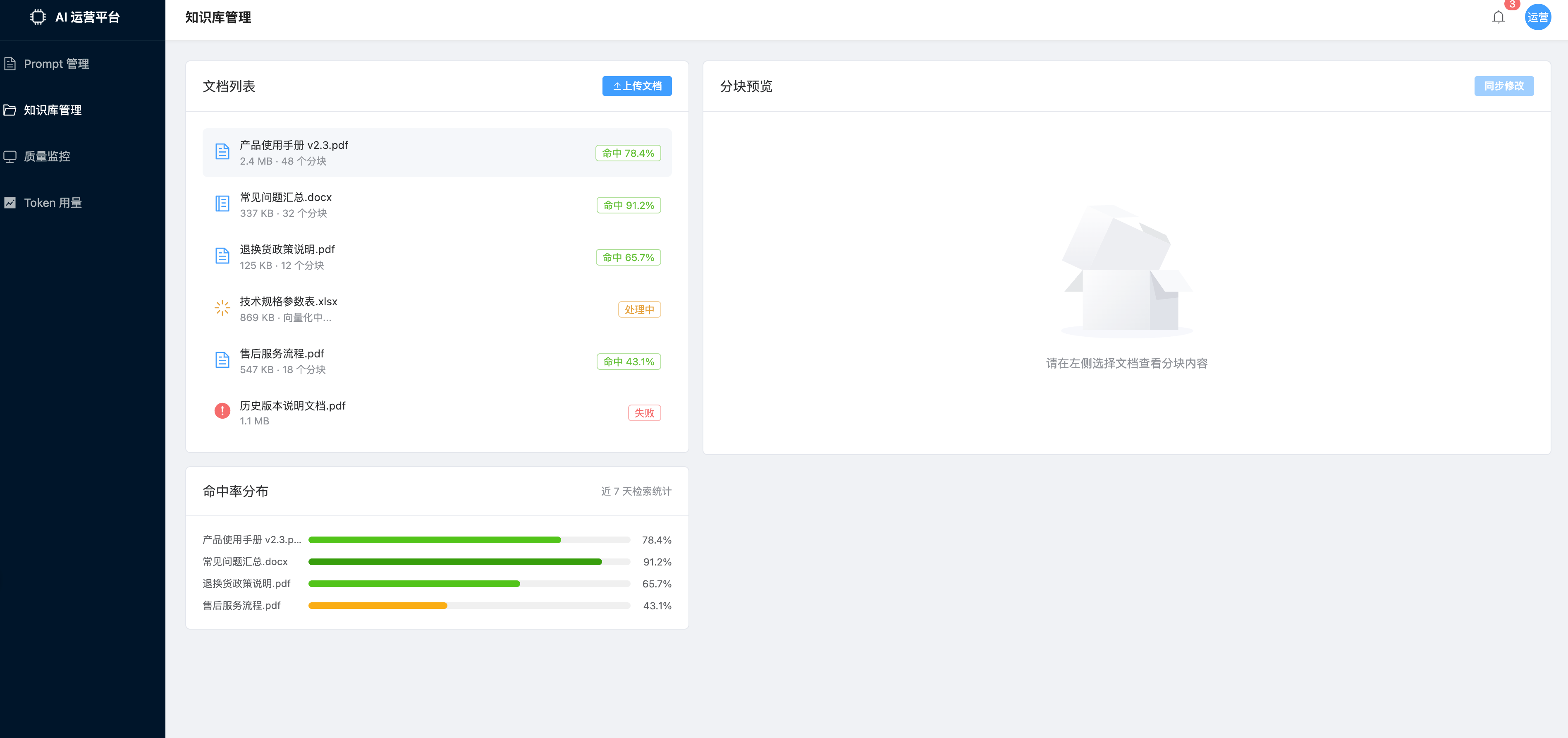
模块二:知识库管理
业务流程
上传文档 → 等待向量化完成 → 查看分块内容 → 修改不准确的分块 → 增量同步什么是 RAG 和向量化(面试必问)
RAG(检索增强生成):用户提问时,先从知识库里搜索相关内容,把搜索结果拼入 Prompt,再让 AI 回答。这样 AI 的回答就有了"参考资料"的依据,减少幻觉。
向量化:把文档内容转换成数字向量(比如 1536 维的浮点数组),这样就可以用数学方式计算两段文字的"语义相似度"。用户提问时,也把问题向量化,然后找向量最接近的文档片段返回。
分块(Chunking):一篇长文档会被切分成若干小段(每段几百字),每段分别向量化存储。这样检索时精度更高,返回的是最相关的那几段,而不是整篇文档。
关键代码讲解
1. 文档选择和分块加载
function selectDoc(doc) {
// 处理中或失败的文档不允许查看
if (doc.status !== 'ready') {
ElMessage.warning(doc.status === 'processing'
? '文档向量化中,请稍候'
: '该文档处理失败,请重新上传'
)
return
}
selectedDoc.value = doc
dirtyChunks.value.clear() // 切换文档时清空待同步列表
// 深拷贝分块数据,防止直接修改 mock 原始数据
// 真实项目这里替换为接口请求
chunks.value = mockChunks
.filter(c => c.docId === doc.id)
.map(c => ({ ...c })) // 展开拷贝,切断引用关系
}2. 增量向量化(核心设计)
// 用户修改分块内容时,把该分块标记为"脏"(dirty)
function markDirty(chunk) {
chunk.status = 'dirty'
chunk.charCount = chunk.content.length // 实时更新字数统计
dirtyChunks.value.add(chunk.id) // 用 Set 存储,自动去重
}
// 点击"同步修改"时,只处理脏块
async function syncDirtyChunks() {
syncing.value = true
// 先把状态改为 syncing,UI 上给用户反馈
chunks.value.forEach(c => {
if (dirtyChunks.value.has(c.id)) c.status = 'syncing'
})
// 模拟接口延迟(真实项目:POST /api/chunks/sync,body: { chunkIds, contents })
await new Promise(r => setTimeout(r, 1500))
// 同步完成
chunks.value.forEach(c => {
if (c.status === 'syncing') c.status = 'synced'
})
const count = dirtyChunks.value.size
dirtyChunks.value.clear()
syncing.value = false
ElMessage.success(`${count} 个分块已增量更新向量`)
}面试讲解要点:增量向量化的核心价值是"只对变更的分块重新计算 embedding,不影响其他分块"。一个文档可能有几十个分块,全量重算要调用几十次 embedding 接口,时间和成本都很高。增量方案下,改一个分块通常 2 秒内完成。
3. 命中率热力图
// 根据命中率返回颜色,让用户直观感受哪些文档"有用"
const heatColor = rate => {
if (rate >= 80) return '#389e0d' // 深绿:高频命中
if (rate >= 60) return '#52c41a' // 浅绿:中频命中
if (rate >= 40) return '#faad14' // 黄色:低频命中
return '#ff7a45' // 橙红:几乎没人问
}面试讲解要点:命中率低不等于文档没用,可能是用户没有提到相关话题。但命中率长期为零的文档值得关注——可能是分块策略有问题,或者这部分内容根本不在用户关心的范围内,可以考虑删除或重新整理。
模块三:对话质量监控
业务流程
SSE 实时推送指标 → 前端更新看板数字 → ECharts 图表实时滚动 → 异常对话自动标记 → 点击查看回放SSE 是什么(面试必问)
SSE(Server-Sent Events)是一种服务端向客户端单向推送数据的技术,基于 HTTP 协议,浏览器原生支持。
和 WebSocket 的区别:
- SSE 是单向的(服务端 → 客户端),WebSocket 是双向的
- SSE 基于 HTTP,可以走普通的 Nginx 代理,WebSocket 需要额外配置
- SSE 断线后浏览器自动重连,WebSocket 需要手动实现重连
监控看板用 SSE 而不用 WebSocket,原因是监控数据天然是"服务端主动推送",不需要客户端向服务端发数据,SSE 完全够用而且更简单。
关键代码讲解
1. MonitorSSE 类设计(**api/monitor.js**)
export class MonitorSSE {
constructor() {
this.timer = null
this.staleTimer = null
this.lastUpdateTime = Date.now()
// 基准指标值,模拟真实数据
this.base = {
onlineCount: 128,
ttffAvg: 420, // 首 token 响应时长,单位 ms
abnormalRate: 2.3,
tokenRate: 38.5
}
}
start(onMetrics, onStale) {
// 立即推一次,不让用户看到空白
onMetrics({ ...this.base })
// 每 2 秒推一次,模拟 SSE 推送频率
this.timer = setInterval(() => {
this.lastUpdateTime = Date.now()
onMetrics(this._generateMetrics())
}, 2000)
// 数据新鲜度检测:超过 30 秒没收到推送,说明连接可能断了
if (onStale) {
this.staleTimer = setInterval(() => {
if (Date.now() - this.lastUpdateTime > 30000) {
onStale()
}
}, 5000)
}
}
// 组件卸载时必须调用,防止内存泄漏
stop() {
clearInterval(this.timer)
clearInterval(this.staleTimer)
}
}面试讲解要点:stop() 方法在 onUnmounted 里调用是关键。如果不停止,即使用户切换到其他页面,定时器仍在运行,继续占用内存并触发不必要的状态更新。
真实项目替换方式:
// 把 setInterval 模拟替换为真实 SSE
start(onMetrics, onStale) {
this.es = new EventSource('/api/monitor/stream')
this.es.onmessage = (event) => {
this.lastUpdateTime = Date.now()
const metrics = JSON.parse(event.data)
onMetrics(metrics)
}
// SSE 自带断线重连,onerror 时判断是否需要提示用户
this.es.onerror = () => {
if (this.es.readyState === EventSource.CLOSED) {
// 服务端主动关闭,提示用户刷新
onStale && onStale()
}
// readyState === CONNECTING 说明在自动重连,不需要处理
}
}
stop() {
this.es?.close()
clearInterval(this.staleTimer)
}2. ECharts 实时滚动图表
function updateChart(ttff) {
ttffHistory.value.push(ttff)
// 最多保留 60 条数据,超出后删除最早的
if (ttffHistory.value.length > 60) ttffHistory.value.shift()
// 直接调用 setOption 更新数据,ECharts 内部做增量更新
chart?.setOption({
xAxis: { data: ttffHistory.value.map((_, i) => i) },
series: [{ data: ttffHistory.value }]
})
}面试讲解要点:ECharts 的 setOption 默认是合并模式,不需要重新配置颜色、样式等,只更新数据部分就够了,性能很好。
模块四:Token 用量统计
业务价值
Token 是 AI 接口的计费单位,每次请求的费用 = (prompt_tokens + completion_tokens) / 1000000 × 单价。
这个模块的核心价值:
- 发现成本异常:某天 Token 消耗突然暴增,说明可能有 bug 或者某个业务场景设计有问题
- 优化 Prompt 结构:如果 prompt_tokens 占比很高,说明 system prompt 太长或历史消息没有裁剪
- 业务线成本分摊:知道哪个业务线花了多少钱,方便做内部结算
关键代码讲解
堆叠柱状图配置
series: [
{
name: 'Prompt Tokens',
type: 'bar',
stack: 'token', // 相同 stack 名称的 series 会叠加显示
data: data.map(d => d.promptTokens),
itemStyle: { color: '#409eff' }
},
{
name: 'Completion Tokens',
type: 'bar',
stack: 'token', // 和上面同一个 stack,自动叠加
data: data.map(d => d.completionTokens),
itemStyle: { color: '#79bbff' }
},
{
name: '费用(元)',
type: 'line',
yAxisIndex: 1, // 用第二个 Y 轴(右侧),因为费用和 token 量级不同
data: data.map(d => d.cost),
smooth: true
}
]导出 CSV 功能
function exportCSV() {
const header = '日期,业务线,Prompt Tokens,Completion Tokens,合计 Tokens,费用(元)\n'
const rows = filteredUsage.value.map(d =>
`${d.date},${d.businessLine},${d.promptTokens},${d.completionTokens},${d.totalTokens},${d.cost}`
).join('\n')
// '\uFEFF' 是 BOM 标记,让 Excel 正确识别 UTF-8 编码,否则中文会乱码
const blob = new Blob(['\uFEFF' + header + rows], { type: 'text/csv;charset=utf-8' })
// 创建临时 a 标签触发下载,下载完立即释放 URL 对象
const url = URL.createObjectURL(blob)
const a = document.createElement('a')
a.href = url
a.download = `token_usage_${dateRange.value}days.csv`
a.click()
URL.revokeObjectURL(url) // 释放内存
}四、DeepSeek API 封装详解(api/deepseek.js)
这个文件是整个项目最重要的工具函数,面试几乎必然被问到。
流式请求的完整流程
用户发消息
↓
fetch('/v1/chat/completions', { stream: true })
↓
response.body.getReader() ← 获取可读流
↓
循环 reader.read() ← 每次读取一段二进制数据
↓
TextDecoder.decode() ← 解码为字符串(stream:true 处理多字节字符)
↓
按换行分割 ← SSE 每条消息以换行分隔
↓
过滤 "data: " 前缀 ← SSE 格式规范
↓
JSON.parse() ← 解析 chunk 数据
↓
取 choices[0].delta.content ← 提取增量文本
↓
onChunk(content) ← 回调给调用方核心代码
export function streamChat(messages, onChunk, onDone, onError) {
const controller = new AbortController()
const startTime = Date.now()
let firstTokenTime = null
let fullContent = ''
;(async () => {
try {
const response = await fetch(`${API_BASE}/v1/chat/completions`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${API_KEY}`
},
body: JSON.stringify({
model: MODEL,
messages,
stream: true, // 开启流式输出
max_tokens: 2000
}),
signal: controller.signal // 绑定 AbortController,用于中止请求
})
const reader = response.body.getReader()
// stream: true 保证多字节字符(中文)跨 chunk 时不会乱码
const decoder = new TextDecoder('utf-8', { stream: true })
while (true) {
const { done, value } = await reader.read()
if (done) break // 流结束
const text = decoder.decode(value, { stream: true })
for (const line of text.split('\n')) {
if (!line.startsWith('data: ')) continue
const data = line.slice(6).trim()
if (data === '[DONE]') continue // 流结束标记
try {
const chunk = JSON.parse(data)
// 记录首 token 时间(TTFF 指标)
if (!firstTokenTime && chunk.choices?.[0]?.delta?.content) {
firstTokenTime = Date.now()
console.debug(`[TTFF] ${firstTokenTime - startTime}ms`)
}
const content = chunk.choices?.[0]?.delta?.content ?? ''
if (content) {
fullContent += content
onChunk(content) // 每个 token 触发一次回调
}
if (chunk.usage) lastUsage = chunk.usage
} catch {
// 跳过无法解析的行
}
}
}
onDone(fullContent, lastUsage)
} catch (err) {
if (err.name === 'AbortError') return // 主动中止不算错误
onError(err)
}
})()
// 返回 abort 函数,调用方可以随时中止
return () => controller.abort()
}面试常见追问
Q:TextDecoder 为什么要传 **{ stream: true }**?
A:一个汉字是 3 个字节,如果网络恰好在这 3 个字节的中间切包,一个 chunk 会有截断的多字节字符。stream: true 告诉 decoder 保留未完成的字节,等到下一个 chunk 来了再拼完整解码,否则会出现乱码。
Q:为什么不用 EventSource 而用 Fetch?
A:两种方式都可以。用 Fetch 的优势是可以自定义请求头(比如携带 Authorization),而 EventSource 只能发 GET 请求,无法自定义 Headers,所以对接 AI 接口时 Fetch 是主流方案。
Q:AbortController 是什么,怎么用?
A:AbortController 是浏览器提供的原生 API,用于中止 fetch 请求。把 controller.signal 传给 fetch,调用 controller.abort() 就能取消请求。常见场景:用户点击"停止生成"按钮、组件卸载时取消未完成的请求。
五、对接真实后端的替换指南
项目里所有 Mock 的地方都在这里,对接时逐一替换:
1. Prompt 版本列表
// 当前(MockData)
import { mockPromptVersions } from '@/utils/mockData.js'
const versions = ref([...mockPromptVersions])
// 替换为
import axios from 'axios'
const versions = ref([])
onMounted(async () => {
const { data } = await axios.get('/api/prompts/versions')
versions.value = data
})2. 知识库分块列表
// 当前
chunks.value = mockChunks.filter(c => c.docId === doc.id).map(c => ({ ...c }))
// 替换为
const { data } = await axios.get(`/api/knowledge/chunks?docId=${doc.id}`)
chunks.value = data3. 增量向量化
// 当前(模拟延迟)
await new Promise(r => setTimeout(r, 1500))
// 替换为
await axios.post('/api/knowledge/chunks/sync', {
chunks: [...dirtyChunks.value].map(id => ({
id,
content: chunks.value.find(c => c.id === id)?.content
}))
})4. 实时监控 SSE
// 当前(MonitorSSE 模拟类)
const sse = new MonitorSSE()
sse.start(onMetrics, onStale)
// 替换为(在 monitor.js 里修改 start 方法)
start(onMetrics, onStale) {
this.es = new EventSource('/api/monitor/stream')
this.es.onmessage = e => {
onMetrics(JSON.parse(e.data))
this.lastUpdateTime = Date.now()
}
this.es.onerror = () => {
if (this.es.readyState === EventSource.CLOSED) onStale?.()
}
}5. Token 用量数据
// 当前
import { mockTokenUsage } from '@/utils/mockData.js'
// 替换为
const { data } = await axios.get('/api/stats/token-usage', {
params: { days: dateRange.value, businessLine: selectedBiz.value }
})六、面试话术
介绍这个项目(2-3 分钟版本)
这个项目是公司 AI 产品的运营管理后台,解决了运营团队无法自助管理 AI 效果的问题。
我独立负责前端,技术栈是 Vue3 加 Element Plus。核心做了四个模块:
第一个是 Prompt 版本管理,支持版本对比、A/B 测试配置、在线调试,接的是 DeepSeek 的真实流式接口,做了完整的 SSE 流式输出处理。
第二个是知识库管理,能看到 RAG 文档的分块内容,支持编辑单个分块并触发增量向量化,不需要全量重算。
第三个是质量监控看板,用 SSE 实时推送首 token 响应时长、异常对话率等指标,支持异常对话回放。
第四个是 Token 用量统计,做了趋势图和业务线分布,还支持一键导出 CSV,帮助公司把月度 Token 成本降了约 25%。
被追问"A/B 测试前端怎么做的"
A/B 测试的分流逻辑在后端,前端负责两件事:一是提供流量权重的配置界面,运营设置好比例提交给后端;二是展示两个版本的效果对比图表,我们选了满意度、完成率、Token 消耗这几个维度。前端不参与分流的原因是分流必须在服务端控制,否则用户刷新页面就会破坏分流的统计口径。
被追问"流式输出怎么处理截断 Markdown 的"
流式输出过程中代码块可能被截断,比如收到 ````javascript` 开头但还没有收到结束的 ````` 。我的处理方式是检测反引号的奇偶数,如果是奇数说明代码块没闭合,临时补一个结束符再传给 Markdown 渲染器,流结束后渲染完整内容。流式过程中用 50ms 防抖批量渲染,不是每个 token 都触发一次 DOM 更新。