精炼回答
在Prompt里加约束条件,本质上是为了控制模型输出的边界和质量。大语言模型是基于概率的生成系统,没有约束时会产生发散、冗长或偏离需求的回答。你可以这样理解:约束条件是为了让大模型的输出从"可能正确"变成"符合业务需求",不是模型能力不够,而是需要把通用能力导向具体目标。
有效的约束需要明确且可验证。从几个维度切入会比较清楚:格式约束直接规定输出结构,比如"以JSON格式返回,包含title和summary两个字段";长度约束控制篇幅,像"回答控制在100字以内";范围约束限定内容边界,例如"仅基于提供的文档回答,不要引入外部知识";角色约束定义回答视角,如"作为Python专家回答这个调试问题"。
约束要具体到可执行的程度。说"简短回答"不如说"不超过3句话",说"专业一点"不如说"使用技术术语,避免口语化表达"。如果你需要生成API文档,可以约束"必须包含参数类型、返回值、异常说明三部分";做代码审查时,可以要求"只指出性能和安全问题,忽略代码风格"。关键是让约束和任务目标直接关联,过度约束会限制模型发挥,约束不足则难以保证输出质量。实践中需要迭代测试,根据输出结果调整约束的严格程度。
扩展分析
为什么需要约束:从模型特性说起
要真正理解约束条件的价值,得先搞清楚大语言模型的工作机制。很多人把约束当成简单的"需求描述",但实际上这背后涉及到模型的生成特性和工程化控制思维。
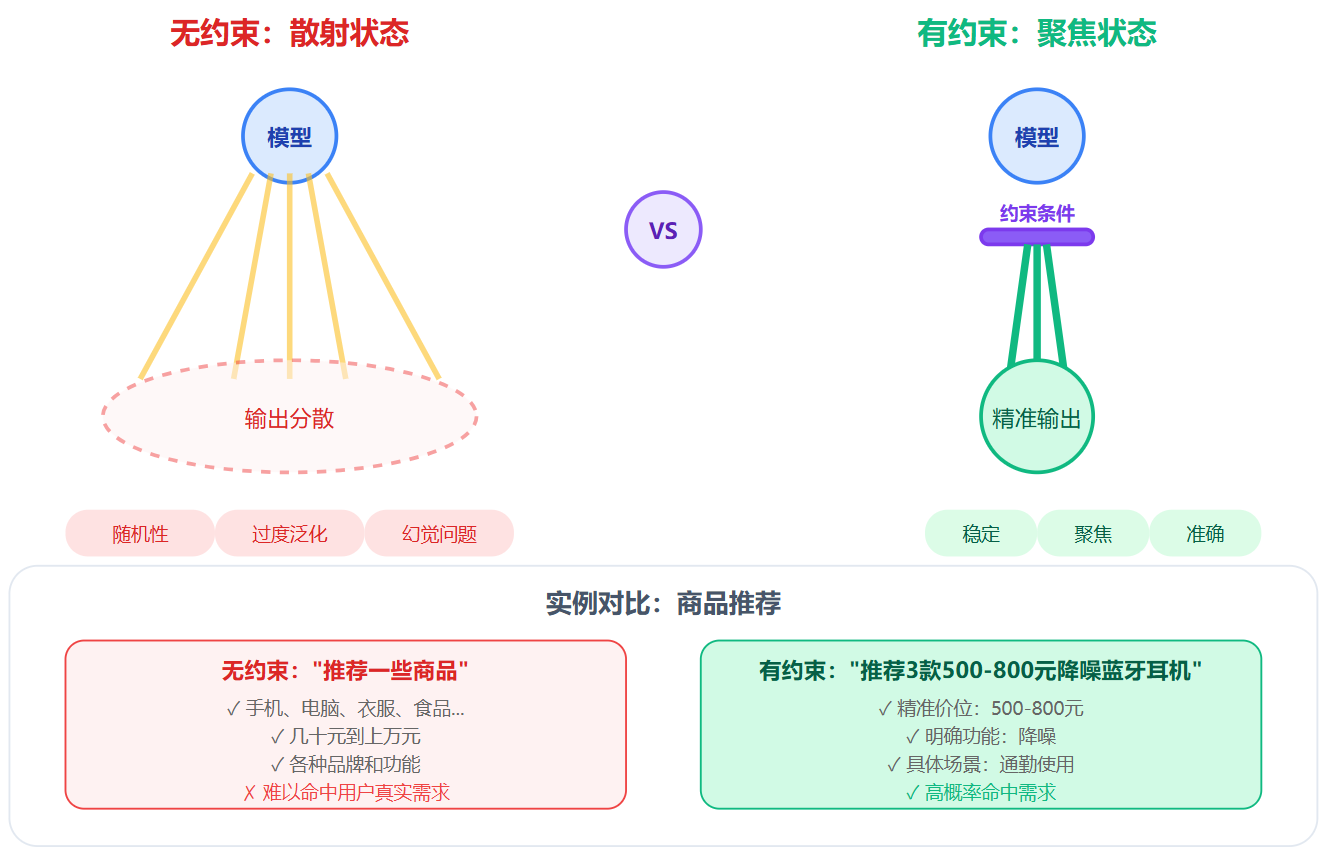
大语言模型本质上是一个概率分布预测器,每次生成下一个token时,它面对的是成千上万种可能性。没有约束的情况下,模型会基于训练数据中的统计规律自由发挥。这就带来几个典型问题:随机性导致的不稳定,同样的问题可能每次回答都不一样,今天给你详细解释,明天可能只给简短总结;过度泛化的问题更常见,你问"如何优化数据库查询",它可能从索引讲到分库分表,再扯到缓存架构,把所有相关知识都倒出来,但你可能只是想知道某个具体场景的解决方案;最麻烦的是幻觉问题,模型会非常自信地编造一些看似合理但实际不存在的信息,比如虚构API方法名或者错误的配置参数。这些特性在聊天场景下可能无伤大雅,但在生产系统里就是灾难。
约束条件其实是通过缩小解空间来提高输出质量。你可以类比成在一个巨大的可能性空间里画一个圈,告诉模型"你只能在这个圈里选答案"。圈画得越精准,模型的发挥余地越小,但命中需求的概率越高。拿商品推荐场景举例,如果你让模型"推荐一些商品",它的解空间包含所有品类、所有价位、所有风格,输出可能五花八门。但如果你约束"推荐3款500-800元的蓝牙耳机,强调降噪功能,面向通勤用户",解空间瞬间缩小到几百个选项,模型更容易给出精准结果。约束的作用不是限制模型能力,而是把模型的能量聚焦到正确的方向。
约束的类型和应用场景
格式约束主要解决输出可解析性。当你需要把大模型的输出对接到下游系统时,格式混乱就会导致解析失败。比如让模型生成用户画像,如果不约束格式,它可能用自然语言描述"这是一位25-30岁的女性用户,偏好时尚类商品",但你的系统需要的是结构化数据。这时候约束"以JSON格式返回,包含age_range、gender、preference_tags三个字段"就能保证输出直接可用。
# 没有格式约束的Prompt
prompt_loose ="请分析这条用户评论的情感倾向:'这款手机性价比不错,但拍照效果一般'"
# 加了明确格式约束的Prompt
prompt_strict ="""请分析这条用户评论的情感倾向:'这款手机性价比不错,但拍照效果一般'
请以JSON格式返回分析结果,严格遵循以下结构:
- sentiment字段只能是positive、negative或neutral之一
- keywords字段是字符串数组包含3-5个关键词
- score字段是0到100的整数
不要添加任何字段说明或额外文本。"""
# 预期输出
# {"sentiment": "neutral", "keywords": ["性价比", "拍照", "一般"], "score": 65}内容约束解决的是边界控制问题。大模型训练数据包罗万象,但业务场景往往需要它只基于特定知识回答。拿客服场景举例,用户问"这款手机支持5G吗",如果模型基于通用知识回答,可能给出过时或错误的信息。但如果约束"仅根据以下产品说明书回答,不要引入外部知识",就能保证答案的准确性和时效性。长度约束是内容约束的特殊形式,它控制信息密度。你让模型写产品描述,不约束长度可能得到500字的长文,但移动端页面只能展示100字,这时候"控制在80-100字"的约束就非常必要。
# 知识库问答的约束示例
defbuild_rag_prompt(user_question, knowledge_doc):
prompt =f"""用户咨询:{user_question}
参考文档:
{knowledge_doc}
回答要求:
- 仅基于上方文档内容回答
- 如果文档中没有相关信息,明确回复'文档中未提及该信息'
- 禁止使用文档外的知识进行推测或补充
- 回答控制在80-120个中文字符
- 如果内容超出限制,优先保留核心观点删减细节"""
return prompt风格约束定义的是表达方式,同样的信息用不同语气传达,效果完全不同。如果你在做技术文档生成,约束"使用第三人称,避免口语化,专业术语需注明英文原文"能保证文档的正式感。但如果是生成营销文案,约束"使用第二人称,口语化表达,多用疑问句引发共鸣"会让内容更有感染力。这种约束最能体现你对用户场景的理解,不能只说"专业一点"或"通俗一点",而是要说清楚专业到什么程度、通俗给谁看。
逻辑约束是比较高级的类型,它控制推理过程而不只是输出结果。当你让模型做数据分析时,可以约束"先列出关键指标,再解释变化原因,最后给出建议,每个部分单独成段"。这种约束强制模型按照特定思维路径工作,输出的可读性和说服力都会提升。代码生成场景也常用逻辑约束,比如"先写函数签名和文档注释,再实现核心逻辑,最后补充异常处理",这样生成的代码结构更清晰。
# 逻辑约束的结构化分析示例
analysis_prompt ="""请评估以下技术方案的可行性:使用Redis作为订单服务的主存储
评估要求按以下步骤进行:
第一步:列出待评估的关键维度(性能、可靠性、成本、维护复杂度)
第二步:逐个维度打分(1-10分)并说明理由
第三步:综合得分给出结论
每步之间用'---'分隔,如果提到X导致Y,必须说明中间的传导机制"""怎么加才有效:实践中的技巧
约束条件的位置选择是很多人忽略的细节。前置约束适合定义全局规则,比如"你是一个Python专家,后续所有回答都基于Python 3.8+语法",把约束放在Prompt开头,模型会在整个对话过程中保持这个设定。后置约束更像是最后的提醒,常用于强调关键要求,比如在一大段需求描述后加上"注意:输出必须是有效的JSON格式,不要包含任何解释性文字"。对于特别重要的约束,重复强调是有效策略,你可以在Prompt开头说一次"回答控制在200字以内",在结尾再重复"请确保回答不超过200字",这种重复能显著提高模型的遵守率。
约束的颗粒度控制体现的是工程化思维。约束不是越细越好,而是要匹配任务复杂度。简单任务用粗颗粒度约束就够了,比如"用一句话总结"。但复杂任务需要渐进式细化,你可以先给粗约束"生成一份产品对比报告",看输出效果,如果发现格式混乱,加上格式约束"使用表格形式,列出功能、价格、评分三列";如果发现内容偏离,加上内容约束"仅对比处理器性能和电池续航";如果发现语气不对,再加风格约束"使用客观中立的描述,不做主观推荐"。
# 动态构建约束的工程化实现
defbuild_constraint_prompt(task_type, constraints_config):
base_prompt =f"任务:{task_type}\n\n"
if"format"in constraints_config:
base_prompt +=f"输出格式:{constraints_config['format']}\n"
if"length_limit"in constraints_config:
min_len = constraints_config['length_limit'].get('min',0)
max_len = constraints_config['length_limit'].get('max')
base_prompt +=f"长度要求:{min_len}到{max_len}个字符\n"
if"forbidden_words"in constraints_config:
words ="、".join(constraints_config['forbidden_words'])
base_prompt +=f"禁止使用的词汇:{words}\n"
if"style"in constraints_config:
base_prompt +=f"表达风格:{constraints_config['style']}\n"
return base_prompt
# 使用示例:生成电商营销文案
config ={
"format":"三段式结构,每段不超过50字",
"length_limit":{"min":100,"max":150},
"forbidden_words":["最好","第一","最优","保证"],
"style":"第二人称,口语化,多用疑问句"
}
prompt = build_constraint_prompt("生成iPhone促销文案", config)当你需要组合多个约束时,优先级处理很关键。约束之间可能冲突,这时候要显式标注优先级。比如"核心约束:输出必须是有效JSON,不得包含任何格式外内容。次要约束:内容力求完整,如果字段信息不足可填充null。权衡原则:格式正确性优先于内容完整性。"这样写的好处是当模型面临两难选择时,它知道该牺牲哪一边。
实际项目中的迭代过程特别重要。没有一次写对的约束,都是在实际输出中发现问题、调整表述、再验证的循环。拿客服回复生成举例,第一版约束可能比较宽松:"用户咨询:这款手机什么时候发货?请生成客服回复,语气友好专业。"发现模型有时候会过度承诺,比如说"今天就给您发货",但实际库存可能不足。这时候加强约束:"语气友好但不做具体承诺,如果无法确定发货时间,引导用户联系人工客服,回复控制在50字以内,不得使用'肯定''一定''保证'等绝对化表述。"测试后发现模型有时候会说"应该很快"这种模糊表达,继续细化:"第一句表示理解用户需求,说明需要核实订单状态后才能确定,提供查询物流的具体方式,总字数40-60字,禁用词汇:肯定、一定、保证、应该、可能、大概。"
# 迭代优化的完整示例
defgenerate_customer_reply_v1(user_query):
prompt =f"""用户咨询:{user_query}
请生成客服回复,语气友好专业。"""
return call_llm_api(prompt)
defgenerate_customer_reply_v2(user_query):
prompt =f"""用户咨询:{user_query}
请生成客服回复,需满足以下要求:
- 语气友好但不做具体承诺
- 如果无法确定发货时间,引导用户联系人工客服
- 回复控制在50字以内
- 不得使用"肯定""一定""保证"等绝对化表述"""
return call_llm_api(prompt)
defgenerate_customer_reply_v3(user_query):
prompt =f"""用户咨询:{user_query}
请生成客服回复,严格遵守以下规则:
- 第一句表示理解用户需求
- 说明需要核实订单状态后才能确定
- 提供查询物流的具体方式(订单号查询或联系客服)
- 总字数40-60字
- 禁用词汇:肯定、一定、保证、应该、可能、大概"""
return call_llm_api(prompt)测试约束效果时,边界测试特别重要。比如约束了"回答控制在100字以内",你要故意提一个需要详细解释的复杂问题,看模型会不会突破限制。如果约束了"仅基于文档回答",你要问一个文档里没有但模型训练数据里肯定有的常识问题,检验它会不会坚持说"文档未提及"。对抗性测试更进一步,你在提问里暗示模型违反约束,比如约束了"客观陈述不做推荐",但问题里说"你觉得哪个更好",看模型会不会被诱导。
深入思考:约束的平衡艺术
好的约束让输出既满足需求又保留了模型的生成能力。如果约束后输出变得僵硬刻板,说明约束过度了;如果输出仍然飘忽不定,说明约束还不够精准。这个平衡感需要在实践中不断调整。
约束和创造性确实存在张力,但这不是零和博弈,而是需要根据任务目标动态调整的平衡关系。如果你要生成品牌slogan,这时候需要的就是创造性,约束应该只限定品牌调性和字数上限,别的不管。但如果是生成产品参数说明,这时候准确性远比创造性重要,约束就要细到每个字段的格式。实践中会先用粗约束测试,看模型在给定自由度下的发挥质量,如果输出偏离方向再逐步收紧。
不同模型对约束的遵循能力差异明显。有些模型对格式约束的理解很强,你说要JSON它就严格返回JSON,但有些模型经常会在JSON外面包一层解释文字。长度约束也类似,某些模型对"不超过100字"的执行很精准,但有些模型会理解成"大概100字左右"就给你输出150字。遇到约束遵循能力弱的模型时,有两个应对策略:一是把约束表述得更直白,比如把"简洁回答"改成"只回答核心内容,不要解释过程";二是在后处理环节加验证逻辑,检查输出是否真的符合约束,不符合就重新生成。
# 约束验证和重试机制
defgenerate_with_retry(prompt, max_retries=3):
for attempt inrange(max_retries):
response = call_llm_api(prompt)
# 验证JSON格式约束
try:
data = json.loads(response)
ifall(key in data for key in["sentiment","keywords","score"]):
return data
except json.JSONDecodeError:
pass
# 如果不符合约束,在prompt中加强提示
if attempt < max_retries -1:
prompt +="\n\n特别注意:必须严格返回有效的JSON格式,不要有任何额外文字!"
raise ValueError("模型输出未能满足约束条件")约束条件和Few-shot示例解决的问题不完全一样,约束定义边界规则,示例展示具体形式。在实践中往往需要组合使用,先用约束框定大方向,再用Few-shot让模型理解具体的表达风格。拿情感分析举例,你可以约束"输出只能是正面、负面、中性三选一",同时给出几个标注好的示例让模型理解什么样的表达对应什么情感。如果只有约束没有示例,模型可能符合格式但分类标准跟你预期不一致;如果只有示例没有约束,模型可能输出"偏正面"这种模糊答案。
在团队协作中,约束条件需要工程化管理。可以建立Prompt模板库,把常用的约束条件抽象成可复用的组件,比如format_json、limit_length、tone_professional这些约束模块可以按需组合。每次新建Prompt时不是从零开始写,而是选择合适的约束组件拼装,这样既保证了一致性又提高了效率。针对关键业务场景的Prompt,需要做版本管理和AB测试,记录每次约束调整带来的效果变化,形成迭代记录。
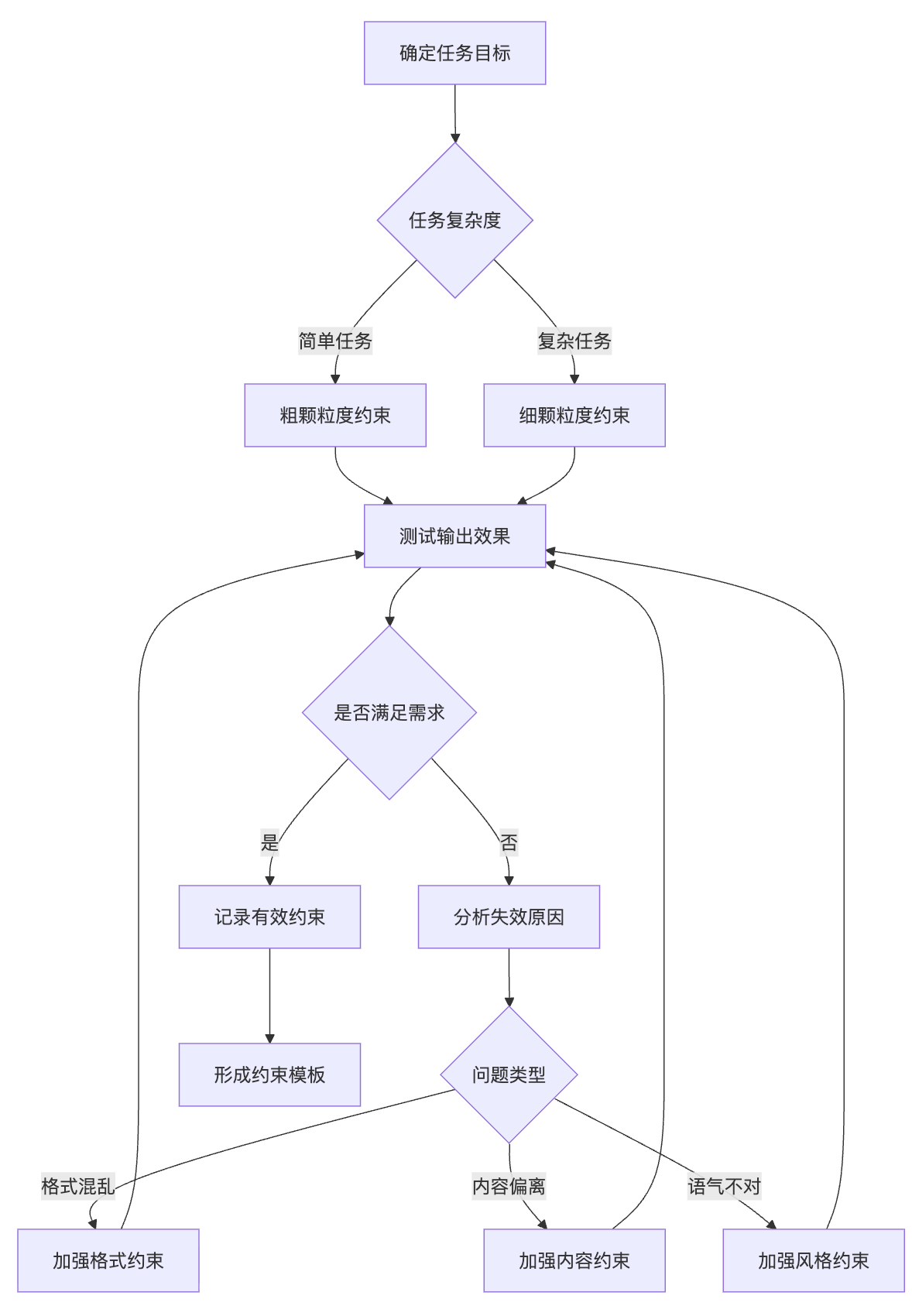
最后记住,约束条件的设计是一个持续优化的过程。从粗到细的迭代,从单一到组合的扩展,从人工验证到自动化检测的演进,每一步都需要基于真实的输出结果来调整策略。这个过程没有标准答案,但有清晰的思路:明确目标、定义边界、测试验证、迭代优化。掌握了这套方法论,你就能在不同场景下设计出真正有效的约束条件。