精炼回答
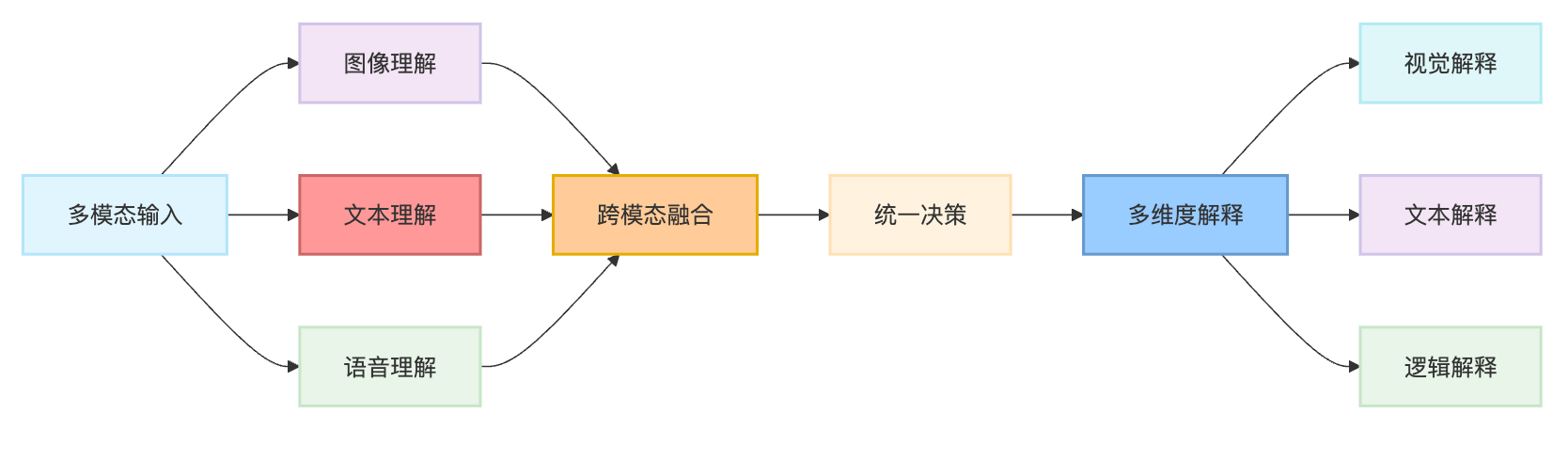
AI Agent的可解释性主要通过注意力机制可视化、决策路径追踪、规则提取等技术手段实现。在模型层面,可以使用LIME、SHAP等方法分析特征重要性,显示Agent在特定决策中哪些输入因素起关键作用。对于基于LLM的Agent,思维链(Chain-of-Thought)提示能让模型输出推理过程,而决策树、规则引擎等符号化组件可以提供明确的逻辑路径。
在架构设计上,采用模块化设计将感知、推理、执行分离,每个模块的输入输出都可以被监控和解释。工具调用记录、中间状态保存、决策日志都是重要的可解释性组件。一些系统还会生成自然语言解释,描述Agent为什么选择特定行动。
可解释性至关重要是因为它直接影响系统的可信度和实用性。在医疗诊断Agent中,医生需要理解AI的诊断依据才能做最终决策;在金融风控Agent中,监管要求必须解释拒贷原因;在自动驾驶中,事故分析需要明确决策逻辑。此外,可解释性还能帮助开发者调试优化,发现模型偏见,提升系统鲁棒性。当Agent行为透明可控时,用户才会真正信任并广泛采用这些智能系统。
扩展分析
详细解释
AI Agent的可解释性本质上解决的是一个信息不对称问题。Agent基于复杂的数学模型做决策,而人类需要基于逻辑推理来理解这个决策,可解释性就是在这两者之间搭建一座桥梁。这不仅仅是技术问题,更是关系到AI系统能否在实际业务中落地的关键因素。
从技术角度看,可解释性主要通过三个层面来实现:模型层面的特征重要性分析,架构层面的模块化设计,以及交互层面的自然语言解释生成。每个层面都有其独特的价值和适用场景。
LIME的核心思想是"局部近似",它在待解释样本附近生成扰动数据,然后用简单的线性模型来拟合黑盒模型在这个局部区域的行为。就像是用直线去逼近曲线上的一个点,虽然全局看不准确,但在这个点附近是很好的近似。SHAP则基于博弈论中的Shapley值,确保了每个特征的重要性分数加起来等于模型输出与基准值的差,这就像分蛋糕一样,确保每个人分到的份额是公平的。
publicclassExplanationEngine{
privateLimeExplainer limeExplainer;
privateShapExplainer shapExplainer;
privateAttentionVisualizer attentionViz;
publicExplanationexplainDecision(AgentDecision decision,InputData input){
// 特征重要性分析
FeatureImportance importance = shapExplainer.explain(decision.getModel(), input);
// 注意力权重可视化
AttentionWeights attention = attentionViz.getWeights(decision.getAttentionLayer());
// 决策路径追踪
DecisionPath path =traceDecisionPath(decision);
// 生成自然语言解释
String naturalLanguage =generateNaturalExplanation(importance, attention, path);
returnnewExplanation(importance, attention, path, naturalLanguage);
}
privateStringgenerateNaturalExplanation(FeatureImportance importance,
AttentionWeights attention,
DecisionPath path){
StringBuilder explanation =newStringBuilder();
explanation.append("基于以下主要因素做出决策:");
// 获取最重要的特征
List<Feature> topFeatures = importance.getTopFeatures(3);
for(Feature feature : topFeatures){
explanation.append(String.format("【%s】权重%.2f,",
feature.getReadableName(), feature.getImportance()));
}
return explanation.toString();
}
}在讨论注意力机制时,要强调它在LLM-based Agent中的特殊价值。注意力权重本身就是一种解释信号,显示了模型在做决策时关注了输入的哪些部分。但需要注意的是,注意力权重高不一定等于重要性高,这是很多人的误区。注意力更多反映的是模型的信息流动,而不是因果关系,这就是为什么我们还需要其他解释技术的原因。
不同的利益相关者对解释的需求差异很大,这是一个经常被忽视但很重要的点。用户关心的是"这个决策对我是否合理",需要简单直观的解释;开发者关心的是"模型哪里可能有问题",需要详细的技术指标;监管者关心的是"决策过程是否符合法规",需要可审计的完整记录。理解这种需求差异体现了对系统设计的全局思考。
完全可解释的模型往往性能有限,而高性能的模型通常是黑盒的。在实际项目中,需要根据业务场景来平衡这个矛盾。比如在电商的商品排序中,可能会采用两阶段设计:第一阶段用复杂模型做粗排保证效果,第二阶段用可解释模型做精排并提供解释。
实践应用
不同业务场景对可解释性的要求存在显著差异,这决定了技术方案的选型和实施策略。在金融风控这个最严格的领域,银行不仅需要知道是否放贷,更需要知道拒贷的具体原因。这不只是监管合规的要求,也是风险管理的需要。对于这种场景,通常会选择基于规则引擎和决策树的混合架构,因为它们能提供明确的决策路径,每一个拒贷决策都可以追溯到具体的风险因子和阈值。
医疗诊断场景有着不同的复杂性,需要同时满足医生的专业需求和患者的理解需求。医生需要看到模型关注了哪些影像特征、生化指标,而患者需要用通俗语言解释病情。这种双重需求往往需要分层解释架构,底层提供技术细节,上层生成自然语言描述。
publicclassMedicalDiagnosisExplainer{
publicclassLayeredExplanation{
privateTechnicalExplanation technical;// 给医生看的
privateSimpleExplanation simple;// 给患者看的
publicStringgetExplanationFor(UserType userType){
switch(userType){
case DOCTOR:
return technical.getDetailedAnalysis();
case PATIENT:
return simple.getPlainLanguageExplanation();
default:
return simple.getPlainLanguageExplanation();
}
}
}
publicLayeredExplanationexplainDiagnosis(MedicalData data,DiagnosisResult result){
// 分析关键医学指标
List<MedicalIndicator> keyIndicators =analyzeKeyIndicators(data);
// 生成专业解释
TechnicalExplanation technical =generateTechnicalExplanation(keyIndicators, result);
// 生成通俗解释
SimpleExplanation simple =generateSimpleExplanation(keyIndicators, result);
returnnewLayeredExplanation(technical, simple);
}
}电商推荐场景的可解释性要求相对灵活,但实施难点在于实时性要求。当用户点击"为什么推荐这个商品"时,系统需要在毫秒级给出解释,这就要求在推荐计算时就同步生成解释特征。通常会在推荐模型中嵌入attention机制,让模型在计算推荐分数的同时输出特征权重,然后通过模板化生成解释文本,比如"因为您购买过类似商品"或"该商品在同类中评分最高"。
监管合规场景下的可解释性有着独特的技术要求,特别是可审计性的重要性。欧盟的GDPR法规给出了"解释权"的概念,要求算法决策必须能够被解释。这意味着不能只提供事后解释,还需要保证解释的完整性和一致性。技术实现上通常需要建立完整的决策审计链路,记录从输入特征到最终决策的每个中间步骤。
对于实时性要求高的场景,比如广告投放,倾向于使用基于规则的解释生成,虽然灵活性有限但响应速度快。而对于离线分析场景,比如用户行为分析,可以使用SHAP等计算密集的方法来获得更准确的解释。
部署考虑因素往往被忽视,但这恰恰体现了系统设计能力。可解释性系统的部署需要考虑存储开销,因为需要保存大量的中间计算结果用于生成解释。还要考虑版本一致性问题,当主模型更新时,解释模型也需要同步更新,否则会出现解释与实际决策不符的情况。在生产环境中,需要定期验证解释的准确性,比如通过A/B测试检查解释是否真的提升了用户信任度,或者通过专家评审验证解释的合理性。
扩展思考
AI Agent的可解释性问题远不止技术深度那么简单,它更多地反映了对AI伦理和社会责任的理解。随着多模态Agent的普及,解释的复杂度在急剧上升。比如一个处理图文混合输入的电商客服Agent,需要同时解释为什么关注了图片中的某个区域和文本中的特定词汇,这种跨模态的解释生成目前还缺乏成熟的技术方案。
可解释性确实可能约束某些黑盒算法的使用,但这种约束也在推动技术向更好的方向发展。就像安全带约束了驾驶行为,但让汽车变得更安全一样。而且可解释性需求也在催生新的技术路径,比如神经符号融合、因果推理等方向,这些都是未来AI发展的重要方向。
publicclassResponsibleAI{
privateExplainabilityEngine explainer;
privateBiasDetector biasDetector;
privateDecisionAuditor auditor;
publicDecisionmakeDecision(Input input){
Decision decision = model.predict(input);
Explanation explanation = explainer.explain(decision);
// 检查决策是否存在偏见
if(biasDetector.hasBias(decision, explanation)){
auditor.logBiasWarning(decision, explanation);
returnDecision.withWarning(decision,"检测到潜在偏见");
}
// 记录完整的决策过程以备审计
auditor.logDecisionProcess(input, decision, explanation);
returnDecision.withExplanation(decision, explanation);
}
publicAuditReportgenerateAuditReport(TimeRange timeRange){
List<DecisionRecord> records = auditor.getRecords(timeRange);
returnnewAuditReport()
.withBiasAnalysis(biasDetector.analyzeTrends(records))
.withDecisionPatterns(analyzeDecisionPatterns(records))
.withComplianceStatus(checkCompliance(records));
}
}在实际项目中发现,用户对解释的接受度和他们的教育背景强相关。同样的技术解释,工程师觉得很清楚,但普通用户完全看不懂。这让人意识到可解释性不只是技术问题,更是交互设计和用户体验问题。需要根据不同用户群体设计差异化的解释策略,让技术真正服务于人。
AI Agent越来越多地参与到影响人们生活的重要决策中,从贷款审批到医疗诊断,从司法判决到教育评估。可解释性不仅仅是技术特性,更是确保AI技术公平、可信、负责任发展的基础设施。只有当AI系统的决策过程透明可控时,人们才会真正信任并广泛采用这些智能系统,AI技术才能真正发挥其改善社会的巨大潜力。