精炼回答
部分可观察的本质是Agent无法直接看到完整的环境状态,但又必须基于不完整信息做出合理决策。这个矛盾在现实场景中无处不在——推荐系统看不到用户真实的兴趣偏好,自动驾驶看不到其他车辆的真实意图,智能客服看不到用户背后的真正需求。
面对这个矛盾,核心策略是让Agent维护对环境的"记忆"或"信念"。技术上有两条主线:一是利用时序信息补全状态,典型做法是用LSTM这类循环网络,把历史观测序列编码成隐状态表示。就像推荐系统中,用户当前只点击了一个商品,但Agent需要结合用户最近浏览的十几个商品历史来推断真实兴趣偏好,这就是用历史观测序列补全当前不完整信息的典型场景。二是建模不确定性本身,也就是维护一个概率分布,表达Agent对当前可能处于哪些状态的判断,这在学术界被称为信念状态。
实际应用中还需要考虑主动获取信息的策略。Agent在不确定时可以采取探索性动作来收集更多信息,或者在系统设计层面增加传感器密度。这种从算法到系统的全局思考,才能真正解决工程中的部分可观察问题。
扩展分析
理论框架与技术演进
部分可观察问题的研究最早源于控制论,当时工程师发现很多实际系统无法直接测量所有状态变量——比如导弹跟踪雷达,你只能观测到目标的位置信号,但真正需要的速度和加速度却要通过连续观测推断出来。这种思想后来被形式化为POMDP框架,也就是部分可观察马尔可夫决策过程。它和完全可观察的MDP最大的区别就是引入了观测函数这个概念,承认Agent只能看到观测o,而o可能对应多个真实状态。
POMDP框架的巧妙之处在于,它把决策问题从"在状态s下该做什么"转换成"在观测历史h下该做什么",用数学语言重新定义了什么叫理性决策。这个框架虽然理论严谨,但实际求解时面临信念空间的维度爆炸问题。早期主要靠值迭代求解,后来发展出点基方法、网格逼近等技巧来降低复杂度。
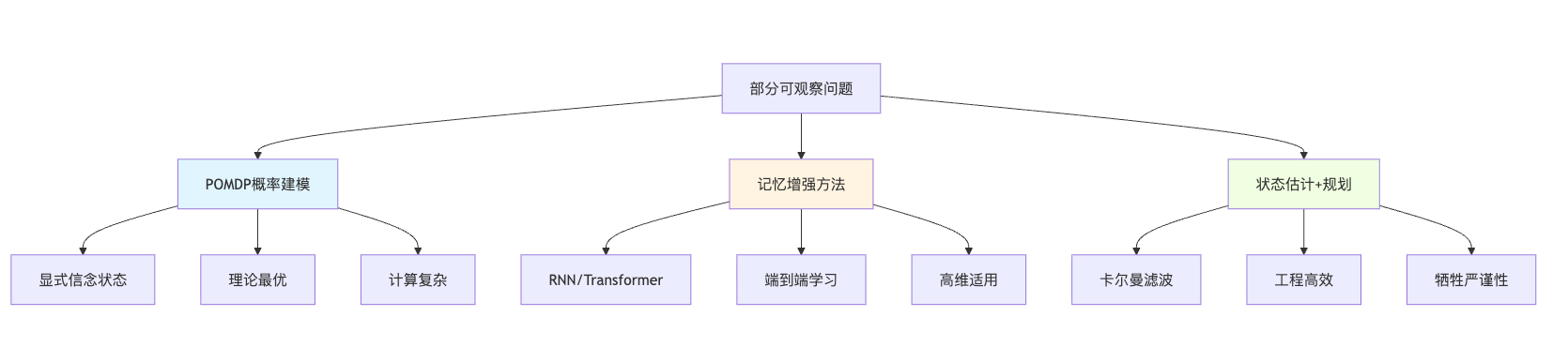
解决部分可观察问题其实有几条不同的技术路线,各有适用场景。POMDP是最严格的概率建模路线,它显式维护信念状态,理论上最优但计算复杂度高,适合状态空间不大且有精确转移模型的场景,比如医疗诊断系统,状态就是疾病类型,观测是症状,医生积累的经验可以转化为精确的概率模型。记忆增强方法是另一条路线,比如用RNN或Transformer直接从观测序列学习策略,它绕过了显式建模状态,把推断隐藏在神经网络的参数里,这在高维连续状态空间更实用,像自动驾驶从摄像头图像推断周围车辆意图,手工建模太难,端到端深度学习反而更高效。还有一种务实的状态估计加确定性规划路线,先用卡尔曼滤波之类的方法估计出最可能的状态,然后就当它是真实状态来做决策,这牺牲了一些理论严谨性但工程上很高效。
信念状态是POMDP里最精妙的设计,它把部分可观察问题转化回了完全可观察问题。虽然Agent看不到真实状态s,但它可以维护一个关于s的概率分布b(s),这个分布本身是完全可观察的——Agent确切知道自己相信什么。决策时不再基于状态s,而是基于信念b,策略变成π(b)。理论上证明了,在信念空间里做决策的最优策略,等价于在原问题里的最优策略。这种"降维"思想非常优雅:通过引入一个新的抽象层,把难问题转化成已解决的问题。
到了深度学习时代,技术演进出现了新的转折。大家发现可以用神经网络直接拟合值函数或策略,绕过显式的信念更新,这催生了Deep Recurrent Q-Network这类算法。电商推荐系统就是个典型例子,用户的真实兴趣和购买意图是隐状态,你只能观测到点击、停留时长这些信号。早期做法是协同过滤,其实隐含了一种简单的信念更新——用相似用户的行为推断当前用户的偏好分布。现在主流方案是用Transformer编码用户行为序列,本质上是让模型自己学习如何从观测历史中提取信念表示。
选择技术方案时要看三个维度。模型可得性是第一个考量,如果领域知识丰富能建立准确的概率模型,POMDP框架价值大;如果只有数据没有先验,深度学习更合适。实时性要求是第二个维度,信念更新的计算开销在高频决策场景可能承受不了,这时状态估计加快速规划更实用。可解释性需求是第三个维度,医疗、金融这些领域需要解释决策依据,显式的信念状态比黑盒神经网络更有优势。
实战落地与工程实践
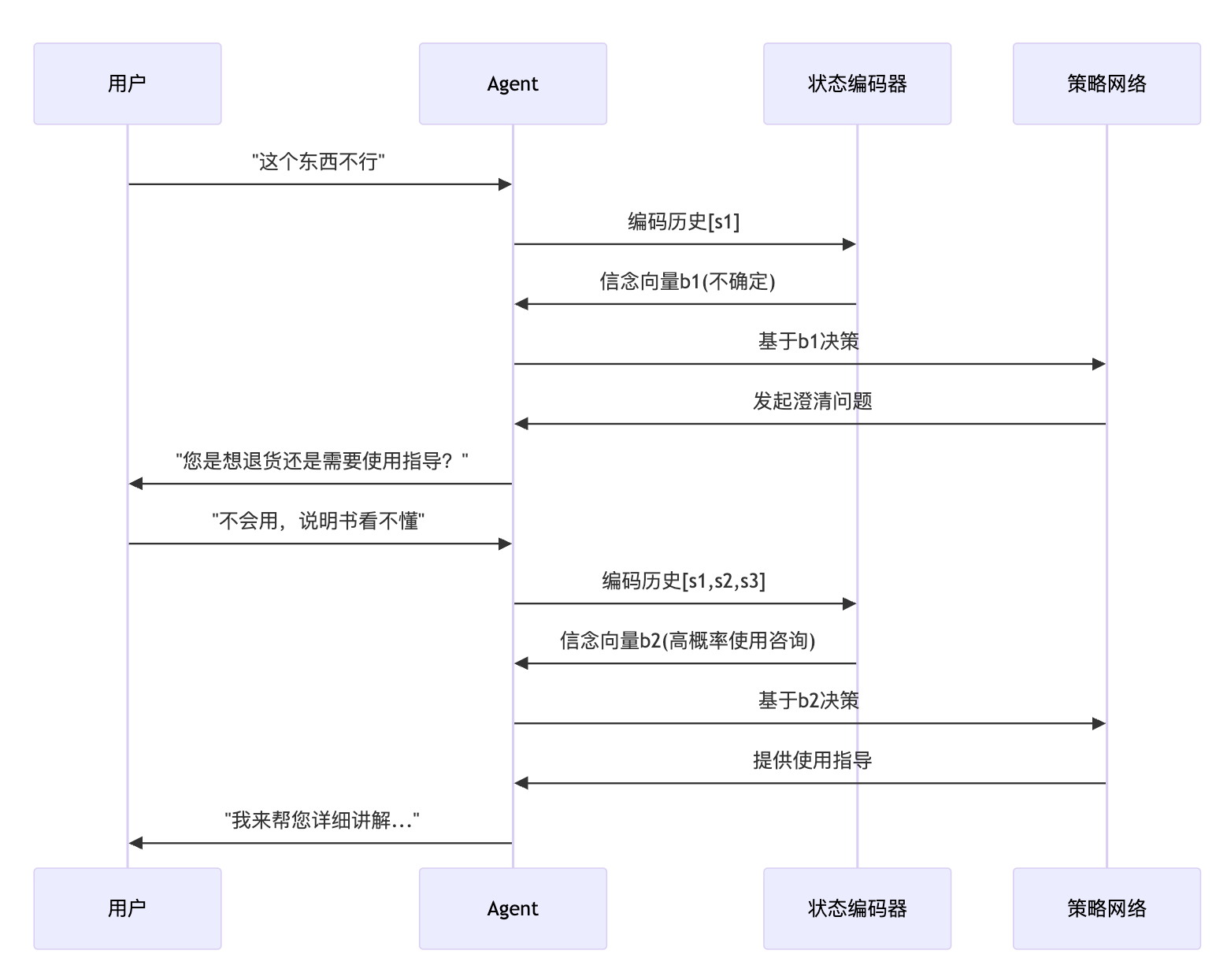
智能客服系统时有一个典型案例,用户通过文字和客服Agent交互,Agent看不到用户的真实意图,只能通过对话历史推断用户是想退货、咨询产品还是投诉。这个场景的难点在于,用户第一句话可能很模糊,比如就说"这个东西不行",你得结合后续对话才能判断他是质量问题要退货,还是不会用需要指导。
我们采用的方案是用LSTM编码对话历史,然后输出一个隐向量作为当前状态的表示,策略网络基于这个隐向量决定Agent该回复什么。这个设计包含三个关键点:用循环网络处理时序、隐向量对应信念状态、策略基于信念而非直接观测。
publicclassDialogStateEncoder{
privateLSTMModel lstm;
privateWordEmbedding wordEmbedding;
/**
* 编码对话历史,返回隐状态表示
* 这个隐向量就是Agent对当前用户意图的"信念"
*/
publicdouble[]encodeHistory(List<String> dialogHistory){
double[][] embeddings =newdouble[dialogHistory.size()][];
for(int i =0; i < dialogHistory.size(); i++){
embeddings[i]= wordEmbedding.embed(dialogHistory.get(i));
}
// LSTM在做信念更新,每读入一句新对话
// 它会结合之前的记忆调整对用户意图的判断
return lstm.encode(embeddings);
}
}
publicclassDialogAgent{
privateDialogStateEncoder stateEncoder;
privatePolicyNetwork policyNet;
privateMap<Integer,String> actionMapping;
/**
* 基于对话历史选择回复
* 核心是策略网络的输入是信念状态而不是原始对话
*/
publicStringselectResponse(List<String> history){
// 获取当前的信念状态
double[] beliefState = stateEncoder.encodeHistory(history);
// 基于信念做决策,而不是直接基于观测
int actionId = policyNet.selectAction(beliefState);
return actionMapping.get(actionId);
}
/**
* 主动信息获取:当信念不确定时,发起澄清性提问
*/
publicStringselectResponseWithUncertainty(List<String> history){
double[] beliefState = stateEncoder.encodeHistory(history);
// 计算信念的不确定性(熵)
double uncertainty =calculateEntropy(beliefState);
// 如果不确定性高,主动提问而不是直接回复
if(uncertainty > UNCERTAINTY_THRESHOLD){
returngenerateClarificationQuestion(beliefState);
}
int actionId = policyNet.selectAction(beliefState);
return actionMapping.get(actionId);
}
privatedoublecalculateEntropy(double[] beliefState){
// 将信念状态转换为概率分布并计算熵
double[] probs =softmax(beliefState);
double entropy =0.0;
for(double p : probs){
if(p >0){
entropy -= p *Math.log(p);
}
}
return entropy;
}
privateStringgenerateClarificationQuestion(double[] beliefState){
// 根据当前信念状态生成最有价值的澄清问题
// 比如在退货和使用咨询之间不确定时,问"您是想退货还是需要使用指导?"
return"能否详细说明一下您遇到的具体问题?";
}
privatedouble[]softmax(double[] input){
double[] result =newdouble[input.length];
double sum =0.0;
for(double v : input){
sum +=Math.exp(v);
}
for(int i =0; i < input.length; i++){
result[i]=Math.exp(input[i])/ sum;
}
return result;
}
privatestaticfinaldouble UNCERTAINTY_THRESHOLD =1.5;
}这里的LSTM就是在做信念更新,每读入一句新对话,它会结合之前的记忆调整对用户意图的判断。返回的隐向量就是Agent当前相信的状态表示。策略网络的输入是信念状态而不是原始对话,这就把部分可观察问题转化成了完全可观察问题——网络确切知道当前的信念向量是什么,基于它做决策就行。
工程上有几个关键要点容易踩坑。历史长度的权衡是第一个,如果把整个对话历史都喂给LSTM,会发现推理时延太高,后来做了截断只保留最近十轮对话,这在信息保留和效率之间找到了平衡点。冷启动问题是第二个,对话刚开始时历史为空,这时我们设计了一个默认的初始信念分布,假设用户各种意图的先验概率相等,随着对话推进再动态调整。
我们做了离线实验对比三种方案:只看当前句子、简单拼接历史、LSTM编码历史。在多轮对话场景下,LSTM方案的意图识别准确率比baseline高了十五个百分点,特别是那种需要三轮以上对话才能确定意图的case,提升明显。
有个教训是我一开始训练时只用了成功对话的样本,结果模型在真实环境表现很差。后来分析发现,真实场景中很多对话是用户意图多次切换的,比如先问产品后来又转向投诉。模型没见过这种pattern就不知道怎么更新信念。后来增加了困难样本,专门收集那些意图有跳变的对话进行训练,鲁棒性才上来。
我还发现一个现象,如果历史窗口太长,模型有时会过度受早期对话影响,用户明明已经转向新话题了,它还在基于十轮前的信息做决策。这其实违背了马尔可夫假设——当前状态应该包含了所有必要信息,太久远的历史反而是噪音。解决方法是引入注意力机制,让模型学会动态加权历史的不同部分。
后来我们改进了策略,Agent不光选择回复内容,还会判断当前信念的不确定性。如果发现对用户意图把握不准,它会主动问一个澄清性问题,比如"您是想退货还是需要使用指导?"这个主动提问的动作本身也是决策的一部分,本质上是用一次额外交互换取更准确的状态信息。这种主动信息获取的思路在很多场景都有价值,医生问诊时会根据已有症状决定做哪项检查,这个"问什么"本身也是决策问题。
对话系统适合用循环网络因为状态空间不大且有明确的时序依赖。但如果换成自动驾驶,车辆要从摄像头画面推断其他车的意图,这时候状态是连续高维的,可能卷积网络加时序模块更合适。关键是根据观测的模态和状态的性质选择合适的编码方式。
我的体会是,部分可观察问题的调试比普通监督学习难很多,因为你看不到真实状态,很难判断是状态估计错了还是决策策略有问题。我的做法是先在仿真环境里测,那里状态是已知的,可以单独评估信念更新的准确度,确认这部分没问题再上真实数据调策略。这种分步验证能大幅缩短调试周期。
深层思考与场景扩展
部分可观察问题和很多其他技术主题都有天然的关联。信念状态的更新本质上是个贝叶斯推断过程,和机器学习里的后验估计思想一脉相承。循环网络处理时序信息时,Transformer架构通过位置编码也能达到类似效果,但两者的归纳偏置不同——RNN有序列的先天假设,Transformer更灵活但需要更多数据。
从系统架构层面看,部分可观察问题暗含了中心化状态估计和分布式信息收集的经典矛盾。假设有个多Agent协作场景,每个Agent都只能观测局部环境,但决策需要全局信息。设计一个中心节点汇总所有观测来维护全局信念,会有单点瓶颈和通信开销。让每个Agent各自维护局部信念,通过消息传递来同步,这更鲁棒但存在一致性问题。这个trade-off在分布式系统设计里是通用思路。
可解释性是部分可观察建模的一个独特优势。如果采用显式信念状态建模,你能清楚地看到Agent"相信"环境处于什么状态,这在很多场景很重要。假设做一个医疗辅助诊断系统,如果用黑盒神经网络直接从症状预测治疗方案,医生很难信任。但如果系统能展示"我有70%把握认为是A病,20%可能是B病",并且说明这个判断是基于哪些症状观测更新来的,医生就更容易接受。
判断实际问题是否需要POMDP建模,我会看两个信号。历史信息的价值是第一个——如果加上时序依赖能显著提升效果,说明当前观测确实不充分。状态的隐藏程度是第二个——如果有些关键变量根本没有直接观测手段,只能通过间接信号推断,那就是典型的部分可观察。推荐系统里用户的长期兴趣就是隐状态,单次点击只是噪声观测,这时不考虑历史行为序列肯定不行。
POMDP和强化学习的关系经常被混淆。强化学习是决策框架,POMDP是环境建模。大部分强化学习教材讲的MDP假设状态完全可观察,但现实中Agent常常面对POMDP环境,所以需要把状态估计和策略学习结合起来。早期方案是先估计状态再学策略,这两步是解耦的。端到端深度强化学习则是让神经网络同时学会状态提取和动作选择,这种耦合在数据充足时往往效果更好。

最近有个趋势是把主动感知整合进来,Agent不仅被动接收观测,还会主动选择获取哪些信息。这种主动POMDP在机器人、诊断系统里很有前景,因为信息获取本身也是有成本的,Agent需要权衡信息价值和获取代价,在不确定性降低和资源消耗之间找平衡。这种对问题边界的拓展,正是技术不断演进的动力。