一、简要回答
这道题不要只回答:预训练是通用的,微调是垂直的。面试官想听的是你知不知道两者在训练目标、数据规模、成本结构和实际落地路径上的区别。这里提供一个参考的简要回答,见下图:
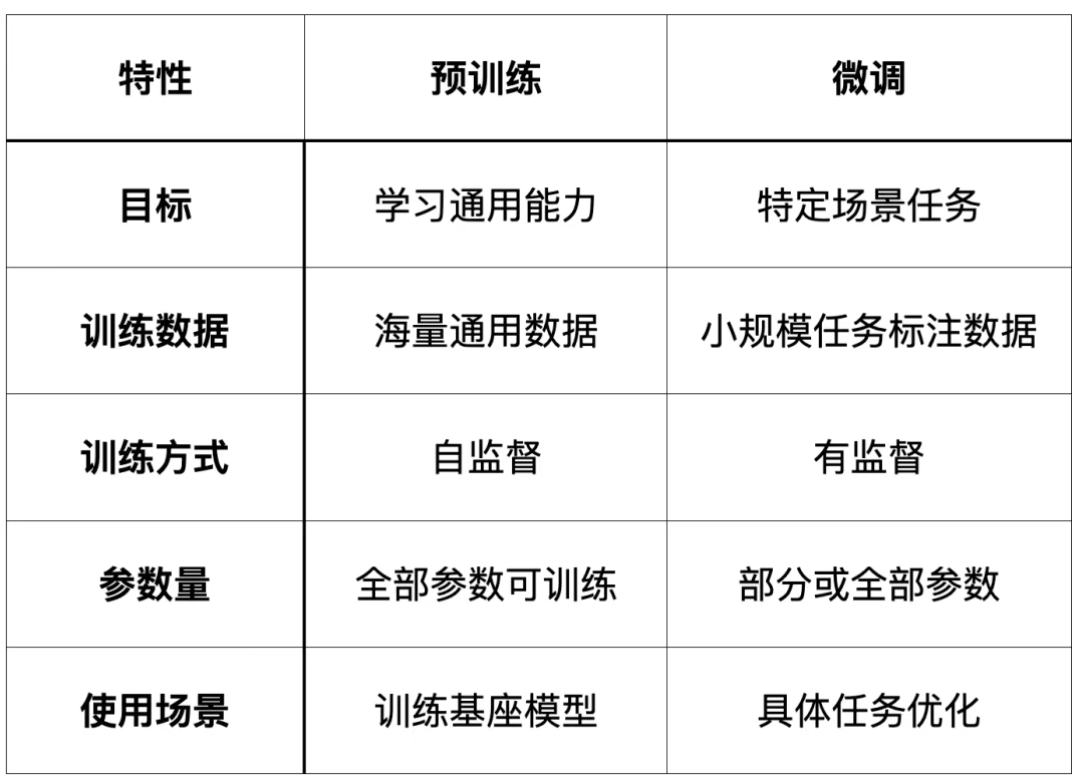
预训练是在海量通用数据上训练模型,让它先学会语言规律、通用知识和基础能力,训练出一个可以复用的基座模型。
微调是在这个基座模型之上,用更小规模、更贴近任务的数据继续训练,让模型更适合某个具体场景。
二、预训练-大模型基础能力
预训练解决的是大模型的基础能力,不会涉及到某个具体的任务场景,本质是让大模型在海量数据里学习通用规律。
训练方式是自监督学习,对大语言模型来说,最常见的做法就是不断预测下一个token。
在这个过程中,模型学到的不只是语法和表达,还会逐步形成通用知识、代码模式,以及一部分基础推理能力。
所以预训练一般有几个很明显的特点:
- 数据量极大,常见来源是网页、书籍、百科、代码和论坛文本
- 大部分数据不需要人工逐条标注,更多依赖自监督学习
- 训练时间长,算力消耗高,往往是大规模集群级别的投入
- 训练完成后得到的是基座模型,不是某个单一业务模型
三、大模型微调
和预训练相比,微调的数据规模通常小得多,但数据质量要求更高。
微调的前提,是模型已经通过预训练具备了通用能力,训练方式通常是监督微调或者指令微调。
人类负责给大模型输入和目标输出,直接告诉它这类任务应该怎么答、怎么写、怎么遵守格式,就是让大模型在某个具体领域表现得更好,例如医疗大模型、教育大模型等场景。
数据量只需要构建几千条适用于实际场景的标注数据,一般来说就够用了。
常见的微调目标包括:
- 让模型更会遵循指令
- 让模型适应某个垂直领域,比如医疗、法务、金融
- 让模型输出更符合企业自己的风格、格式和规则
微调方式
按照调整参数量的不同,把微调分为全参微调与高效微调。
全参微调(Full Fine Tuning)
在预训练模型的基础上进行全量参数微调,可能会调整全部参数,虽然没有重新训练成本高,但是全参微调一般也需要较高的训练成本。
高效微调技术(PEFT)
通过调整少量参数,来降低微调的计算成本,同时尽可能地保持模型性能,例如Adapter Tuning、Prompt Tuning 和 LoRA等方法。
在资源比较受限的情况下,一般会选择LoRA 方法,因为只要训练适配低秩矩阵就可以,通常只有原模型0.1%-1%的参数)。
四、为什么真实项目大部分选择微调模型
现实项目里大多数团队更关注微调,因为预训练和微调大模型两者的成本根本不是一个量级。
预训练要解决的是通用底座问题,意味着要准备海量语料、长周期训练和大量算力,这对绝大多数团队都不现实。
所以真实项目里更常见的是:
- 先选一个合适的基座模型
- 再根据业务目标决定要不要做微调
- 如果任务复杂度还没到那个程度,很多时候 Prompt、RAG、工作流约束就已经够用了