精炼回答
Agent的元认知能力本质上就是它能认识到自己的能力边界。这种能力体现在三个递进的层次:任务接收时判断能不能做,执行过程中监控做得对不对,输出结果时标注确定性有多高。
评估能力边界时我主要关注两个维度。第一是内部一致性检验,让Agent多次回答同一问题看答案是否稳定。如果三次回答核心语义都一致,说明模型对这个知识点掌握扎实;如果忽高忽低,就说明在猜测,这种不稳定性恰好暴露了能力边界。第二是置信度量化,通过输出概率分布判断模型是否犹豫。当发现某个回答的概率分布比较平缓,各个候选答案的分数差距不大时,就说明模型其实拿不准。
这个能力的应用价值用个具体场景就能说清楚。比如智能客服处理售后退款,当用户问"能退多少钱"时,如果Agent发现订单状态缺失或政策规则模糊,具备元认知的系统会回复"需要核实订单信息"而不是给出错误金额。没有元认知的Agent可能直接拿通用规则回答,但实际某些特殊品类的退款政策是有例外的,这种差异直接影响用户信任度。
扩展分析
元认知这个概念最早来自认知心理学,说的是人类"对自己思考过程的思考"能力。类比到Agent系统上,就是让模型不仅能输出答案,还能输出"我为什么这么答、这答案靠谱吗"的元信息。这种跨学科类比背后其实反映了技术演进的必然性。
早期的规则引擎或传统机器学习模型其实没有元认知需求,因为它们的职责边界非常清晰——要么匹配上规则给答案,要么匹配不上直接拒识。但大语言模型的出现彻底改变了游戏规则。现在的Agent基于预训练模型可以回答几乎任何问题,但这种"什么都能答"的能力反而带来了新风险:模型会一本正经地胡说八道。业内常说的幻觉问题就是指模型不知道自己不知道,编造出看似合理实则错误的内容。这时候元认知能力就成了刚需,它是Agent从"什么都敢说"进化到"靠谱的专业顾问"的关键门槛。
深入分析
当Agent接到任务时,元认知能力会驱动它做三件事。第一步是能力匹配检查,扫描任务需求和自己的知识库覆盖范围是否对得上,有点像程序员接需求时先评估技术栈是否匹配。第二步是执行过程监控,在生成答案的过程中持续评估中间步骤的可信度,就像写代码时不断跑单元测试。第三步是结果置信标注,最终输出时附带一个确定性分数,告诉用户这个答案有多靠谱。
具体怎么实现能力边界的判断,我觉得有两个评估维度特别关键。第一个是知识覆盖度检测。假设用户问"2024年某新出台政策的细节",Agent会先检索训练数据的时间截止点和知识库更新状态。如果发现知识盲区,就主动标记"该信息超出我的知识范围"。这背后其实是在训练时就给模型注入了时间戳意识和知识边界感知。比如在电商场景里,如果用户咨询的是上周刚上线的新品促销规则,而知识库最后更新时间是一个月前,系统就能识别出这个时间差,避免用旧规则误导用户。
第二个维度是一致性验证机制。对同一个问题让Agent回答三次,如果三次答案核心语义一致,说明模型对这个知识点掌握稳定;如果三次答案飘忽不定,就说明它在猜。这种不稳定性恰好暴露了能力边界。这个方法的妙处在于不需要标注数据,纯靠模型自己的输出一致性来反推可信度。在客服场景里,如果检测到回答不稳定,系统可以自动转人工,避免给出误导信息。
很多人容易把元认知和模型校准混为一谈,其实两者侧重点不同。模型校准主要解决的是概率输出和实际准确率的对齐问题,比如模型说90%置信度,实际准确率也应该接近90%,这更偏统计层面的修正。而元认知强调的是Agent能主动识别"我不该回答这个问题"的场景,是决策层面的自我约束。校准是让答案更准,元认知是知道何时不答。
执行过程监控其实需要借助思维链技术。让Agent把推理步骤显式输出成"因为A所以B所以C"的链条后,系统可以在每个推理节点检查逻辑是否成立。比如数学解题Agent在求解过程中发现某步运算结果异常,就能触发自我纠错或求助机制。这背后暗含了一个高阶认知:元认知不是孤立的能力,而是和推理透明化、可解释性等特性协同工作的。
从产品层面看,元认知能力让AI助手从"什么都敢说"变成"靠谱的专业顾问",直接降低用户信任成本。从系统层面看,它提供了自动降级和人机协作的触发机制——Agent知道自己搞不定时主动交棒,避免错误传播。从模型迭代层面看,那些被标记为"能力边界外"的case恰好指明了下一步训练数据的采集方向。这三个层次分别对应用户体验、系统架构、技术演进,把元认知的价值说透了。
实践落地
最能体现元认知价值的场景是智能问答系统。比如用户咨询"这个商品支持七天无理由退货吗",没有元认知的Agent可能直接拿通用规则回答"支持",但实际上某些特殊品类像生鲜、定制品是例外。具备元认知的系统会先检查商品类目信息是否完整,如果发现缺失关键属性,就回复"需要确认商品类目才能给出准确退货政策"。这个对比鲜明地展现了有无元认知的差异。
要做到这一点,技术上需要在Agent的决策流程里嵌入前置检查逻辑。核心思路是在生成答案前插入一个自检模块:
publicclassMetaCognitiveAgent{
privatestaticfinaldouble CONFIDENCE_THRESHOLD =0.75;
privatestaticfinaldouble CONSISTENCY_THRESHOLD =0.85;
publicResponsehandleQuery(String userQuestion){
// 第一步:解析意图和关键实体
Intent intent =parseIntent(userQuestion);
// 第二步:元认知检查 - 评估能否回答
CapabilityCheck check =evaluateCapability(intent);
if(check.confidence < CONFIDENCE_THRESHOLD){
// 置信度不足,主动拒答或转人工
returnResponse.uncertain(
"这个问题涉及的信息我需要进一步确认",
check.missingContext
);
}
// 第三步:生成答案并标注置信度
Answer answer =generateAnswer(intent);
// 第四步:多轮验证提升可信度
List<Answer> samples =generateMultipleTimes(intent,3);
double consistency =calculateConsistency(samples);
if(consistency < CONSISTENCY_THRESHOLD){
// 答案不稳定,降级处理
returnResponse.needHumanReview(
answer,
"建议人工核实,系统判断不稳定"
);
}
returnResponse.confident(answer, consistency);
}
privateCapabilityCheckevaluateCapability(Intent intent){
CapabilityCheck check =newCapabilityCheck();
// 检查知识库覆盖度
KnowledgeScope scope = knowledgeBase.queryScope(intent.domain);
if(scope.lastUpdateTime.isBefore(intent.requiredTimeRange)){
check.confidence =0.3;
check.missingContext ="知识库可能不包含最新信息";
return check;
}
// 检查必要实体完整性
List<String> requiredEntities = intent.getRequiredEntities();
List<String> missingEntities =findMissingEntities(requiredEntities);
if(!missingEntities.isEmpty()){
check.confidence =0.5;
check.missingContext ="缺少关键信息: "+
String.join(", ", missingEntities);
return check;
}
// 检查历史准确率
double historicalAccuracy =getHistoricalAccuracy(intent.category);
check.confidence = historicalAccuracy;
return check;
}
privatedoublecalculateConsistency(List<Answer> samples){
// 计算语义相似度矩阵
double totalSimilarity =0;
int pairCount =0;
for(int i =0; i < samples.size(); i++){
for(int j = i +1; j < samples.size(); j++){
totalSimilarity +=semanticSimilarity(
samples.get(i),
samples.get(j)
);
pairCount++;
}
}
return totalSimilarity / pairCount;
}
}这段代码的关键在于evaluateCapability方法,它不是简单判断关键词匹配,而是检查三件事:知识库里有没有相关规则,用户问题的上下文是否完整,历史类似问题的回答准确率。这种拆解方式既展现了技术理解,又保持了实现的可操作性。
多轮生成的一致性检测就是前面提到的验证机制。实际项目中可以用采样温度参数控制随机性,让Agent以不同策略生成几次答案。如果三次结果核心语义都一致,说明模型对这个知识点掌握扎实;如果忽高忽低,就说明在猜。当然多轮生成会增加延迟,实际应用时可以针对高风险问题做验证,比如涉及金额、法律条款的咨询,低风险的闲聊就没必要。这种trade-off的思考正是工程实践的精髓。
有个实践中的误区需要特别注意。很多人会把置信度阈值设得特别高,觉得这样最安全,但实际效果往往适得反——阈值过严会导致Agent频繁拒答,用户体验很差。更好的做法是分层设置阈值。对于事实性问题,比如"订单物流到哪了",可以要求高置信度;对于意见性问题,比如"这款商品怎么样",就可以放宽标准并附带免责说明"以下是综合评价仅供参考"。这种场景化的阈值策略既体现了技术深度,又展现了产品思维。
元认知系统上线后最重要的是建立反馈闭环。每次Agent选择拒答或转人工的case都应该记录下来做离线分析。如果发现某类问题反复触发不确定性判断,说明知识库有盲区,这时候定向补充训练数据效果最好。比如发现用户经常问"预售商品什么时候发货",Agent总是因为缺少预售规则而拒答,这时候补充一批预售相关的FAQ和规则后,下次遇到类似问题置信度自然就上来了。这个思路把元认知从静态能力变成动态优化的抓手。
更高级的做法是让元认知能力理解业务优先级。同样是不确定的答案,涉及支付安全的问题必须拒答,但推荐商品的问题可以尝试性回答并标注"猜测仅供参考"。这背后需要给不同意图打上风险等级标签,然后在决策时综合考虑置信度和风险等级。实际设计时我会考虑分层决策架构:
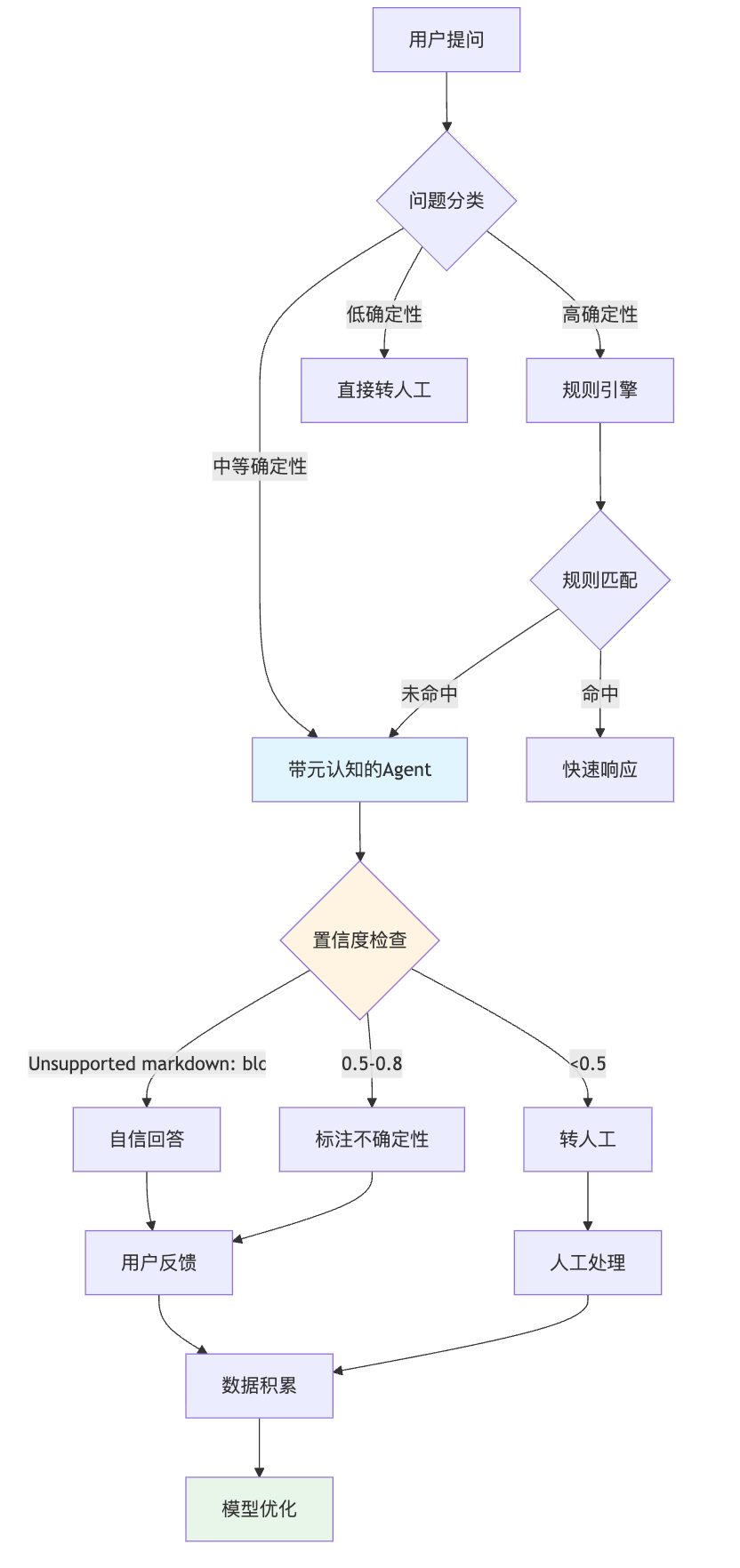
这样既保证了核心路径的稳定性,又利用了Agent的泛化能力。初期可以保守设置阈值,比如置信度低于0.8就转人工,然后根据转人工率和用户满意度逐步调优,这是个持续迭代的过程。
进阶思考
很多人会问,既然Agent可能给错答案,为什么不直接用规则系统或者人工兜底,非要搞元认知能力?这个问题的真实答案是要理解技术选型的trade-off。规则系统在明确边界的场景下确实更可靠,但问题在于现实世界的长尾需求覆盖不完。用户可能问出一万种退货相关的表述方式,写规则会陷入无限穷举。元认知能力的价值是在"灵活性"和"可控性"之间找平衡点——让Agent能处理规则覆盖不到的情况,同时通过自我检查避免瞎答。
还有人会问能不能用强化学习让Agent自己学会什么时候该拒答。理论上可以,但实际操作会遇到奖励函数设计的难题。因为"拒答"这个行为很难量化收益——拒答太多用户体验差,拒答太少错误风险高,这个平衡点在不同业务场景下标准不一样。更实用的做法是用监督学习训练一个置信度预测模型,拿历史数据中那些被人工纠正过的badcase作为负样本,让模型学会识别"这类问题我容易答错"的模式。这比纯强化学习更可控,也更容易在生产环境验证效果。
从业界动态来看,像LangChain这类Agent框架里其实已经内置了简单的异常检测机制,当工具调用失败时会触发重试或降级。GPT-4的API响应里也会返回logprobs参数,让开发者能拿到每个token的概率分布,这就是一种元信息输出。还有一些专门做可信AI的创业公司在研究不确定性量化技术,这个方向未来会成为Agent系统的标配能力。
我观察到很多AI产品其实已经在用元认知机制,只是没明说。比如搜索引擎会在结果页提示"相关信息较少,以下内容仅供参考",语音助手会说"抱歉我没理解您的意思"。这些看似简单的提示语背后,都是元认知能力在起作用——系统知道自己可能搞错了,主动降低用户预期。
最后说个更本质的理解。Agent的元认知能力其实和传统软件开发里的防御性编程思想一脉相承。写代码时我们会做参数校验、异常捕获、边界检查,本质上都是在约束程序的行为边界。元认知就是把这套思想迁移到AI系统里——让模型不仅会做任务,还懂得检查输入合法性、监控执行状态、标注输出可信度。这个类比把陌生的AI概念嫁接到了每个工程师都熟悉的编程范式上,也说明了一个道理:真正落地的AI系统,技术创新固然重要,但更关键的是用工程化思维去驾驭这些能力,让它们在真实业务场景里稳定可靠地运行。