精炼回答
HumanEval和MBPP这两个代码评测集主要测试大语言模型的代码生成能力,但侧重点有所不同。
HumanEval由OpenAI发布,包含164个Python编程题,每题给出函数签名、文档字符串和若干测试用例。模型需要根据函数描述生成函数体实现,然后通过单元测试验证正确性。它关注的是函数级别的代码补全能力,题目覆盖字符串处理、数组操作、数学计算等基础算法场景,比如实现一个判断括号是否匹配的函数。评价指标是pass@k,即生成k个候选答案中至少有一个通过所有测试用例的概率。
MBPP(Mostly Basic Python Problems)由Google发布,包含974个Python编程题,难度整体比HumanEval更基础,更贴近入门级编程任务。每题提供问题描述和3个测试用例,模型同样需要生成完整的函数实现。MBPP的题目更注重实际编程中的常见操作,比如列表去重、字符串格式化这类日常开发任务。
这两个评测集都是通过功能性测试来衡量生成代码的正确性,而不考察代码风格、效率或工程质量。它们已经成为评估代码大模型能力的标准基准,像GPT-4、Claude、DeepSeek-Coder等模型发布时都会报告在这些数据集上的表现。现在各家发新模型基本都会晒这两个数据集的分数,就像手机跑分一样,成了行业标配指标。
扩展分析
评测集的设计哲学
HumanEval虽然只有164道题,但每道题都是精心构造的。OpenAI设计这个评测集时,刻意选择了那些需要理解问题语义、而不是靠记忆就能解决的任务。比如有道题是判断字符串是否为回文,函数签名给了,docstring描述也很清楚,但模型得真正理解什么是回文,才能写出正确的判断逻辑。题目不多其实是有意为之,因为HumanEval更注重质量而非覆盖面。每道题都配了多个测试用例,包括边界情况和异常输入,确保生成的代码不是碰巧对了某个case。
就像我们在IDE里写代码,函数签名和注释都有了,现在要把函数体补全。HumanEval模拟的就是这种场景,它测的是模型能不能根据自然语言描述写出符合预期的算法逻辑。HumanEval的docstring写得像正式文档,比较严谨,会故意设计corner case来卡模型,比如空列表、负数、超大输入。
如果说HumanEval像LeetCode中等难度题,那MBPP就更像是编程入门教材的课后习题。Google发布这个数据集的出发点,是想测试模型在处理日常编程任务时的表现。比如给列表排序、统计字符串中某个字符的出现次数、把摄氏度转华氏度这类操作,都是实际工作中经常遇到的小功能。题量大意味着覆盖的编程场景更全面,虽然单个题目简单,但加起来能比较全面地考察模型对Python基础语法和常用库的掌握程度。
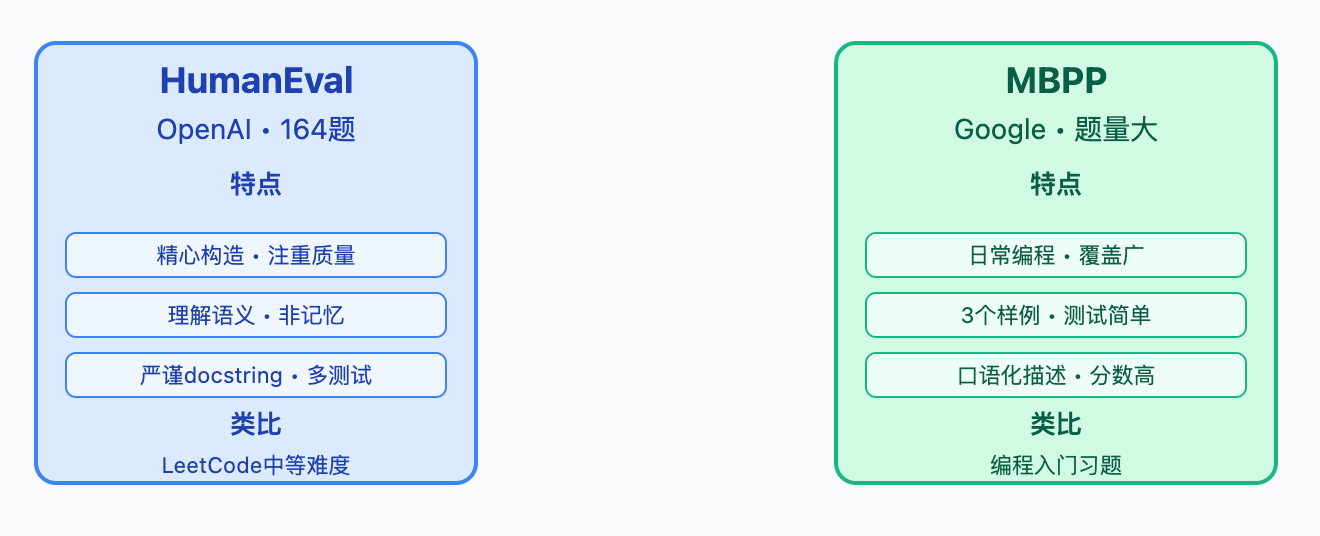
MBPP每题只给3个样例,测试用例相对简单,有时候模型只要抓住主要逻辑就能通过。这跟HumanEval那种严格的测试覆盖不太一样,所以MBPP的pass@k分数通常会比HumanEval高不少。MBPP的描述更口语化,就像老师在课堂上口头布置作业,测试相对常规,主要验证主流程能不能跑通。
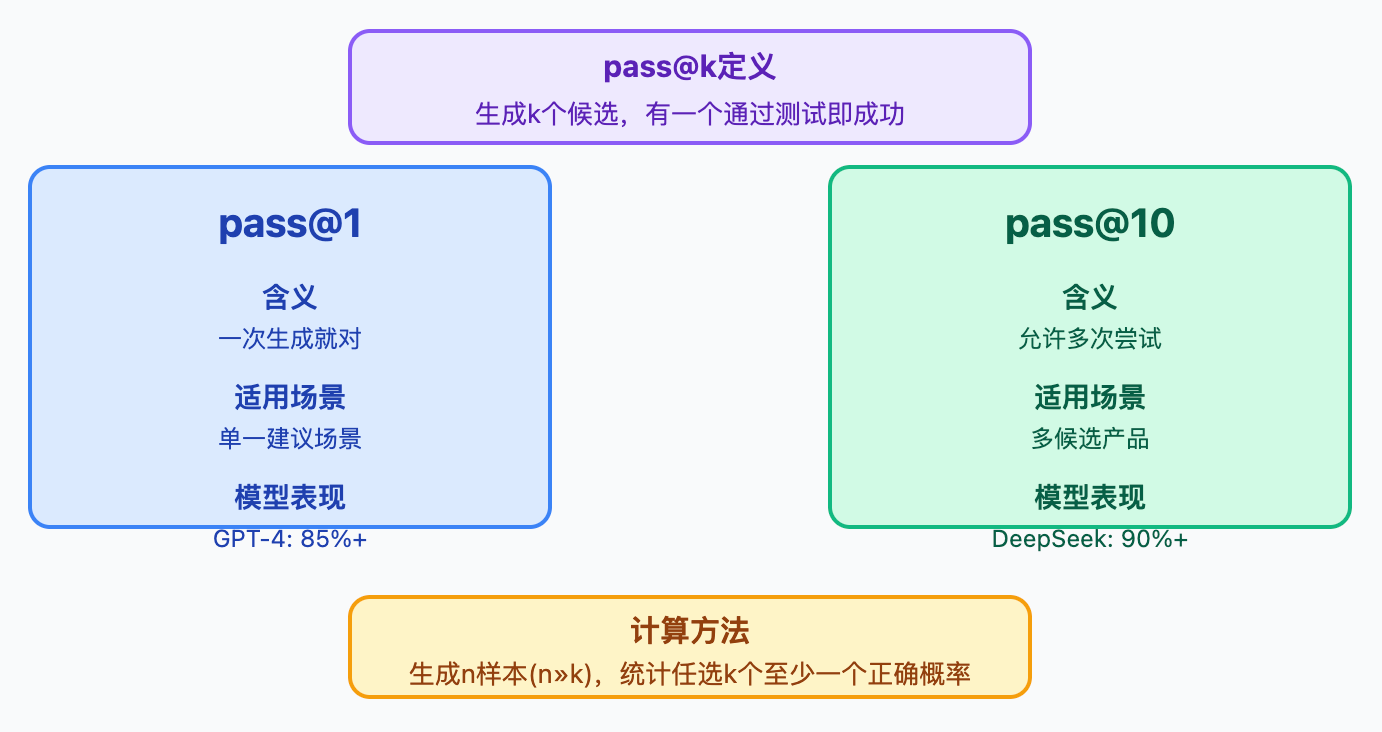
讲到评测指标时,pass@k是绕不开的核心。pass@k的意思是让模型生成k个候选答案,只要其中有一个能通过所有测试用例就算成功。因为代码生成有很大的随机性,同一个问题可能有多种实现方式。pass@1看的是模型一次生成就对的能力,pass@10则允许模型多试几次,更接近实际使用场景——开发者用Copilot时,也是在多个建议里选最合适的。具体算法是对每道题生成n个样本(n通常远大于k),然后统计从这n个里任选k个、至少有一个正确的概率,这个计算会做无偏估计,因为直接生成k个样本再重复多次,计算量太大了。
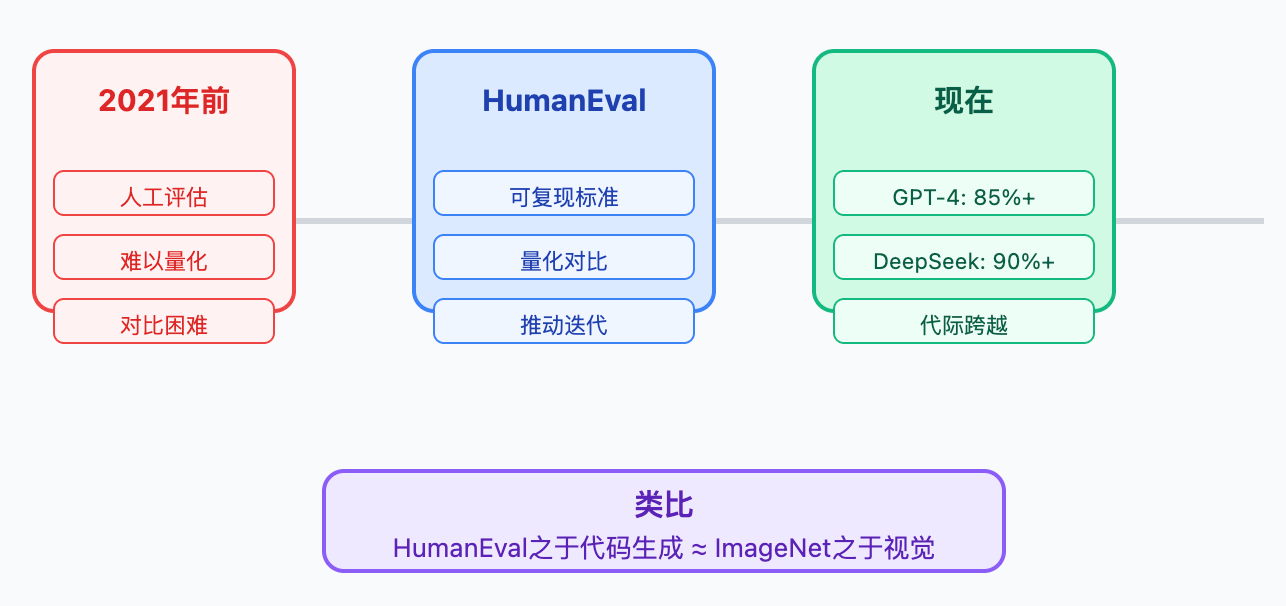
2021年HumanEval发布前,大家评估代码生成能力主要靠人工看生成结果,很难量化对比不同模型的水平。HumanEval出来后,突然有了一个可复现的标准,就像ImageNet之于计算机视觉一样,推动了整个领域的快速迭代。现在你去看任何一个代码大模型的技术报告,HumanEval和MBPP的分数都是必报项。从GPT-3.5的40%到GPT-4的80%多,再到DeepSeek-Coder这些专门模型逼近90%,数字的提升背后是模型能力的代际跨越。
工程落地的真实挑战
如果团队要评估一个代码生成模型,最直接的做法就是跑HumanEval和MBPP。这两个评测集都提供了标准的评测脚本,把模型接入进去,生成代码后自动执行测试用例,最后输出pass@k指标。实际跑评测时,我们通常会同时看pass@1和pass@10两个数值。pass@1代表模型的精准度,适合那种只给用户一个建议的场景;pass@10则反映模型的召回能力,更贴近Copilot这种提供多个候选的产品形态。
但光看这两个分数远远不够。拿金融科技系统举例,我们需要生成处理交易数据的代码,除了功能正确,还得考虑异常处理是否完善、并发场景下会不会出问题、代码的可维护性怎么样。这些维度HumanEval根本测不出来。所以实际工程中,我们会构建领域专属的评测集,比如专门准备一批涉及数据库操作、API调用、日志记录的代码生成任务,用更贴近实际业务的标准来衡量模型表现。
2025年代码生成这块,GitHub Copilot、Cursor这些产品都在用自己的模型或者调用GPT-4、Claude这类通用大模型。从公开数据看,GPT-4在HumanEval上能到85%以上,DeepSeek-Coder这种专门针对代码训练的模型甚至能逼近90%。但有意思的是,分数高不代表体验一定好。Copilot的实际体验比单纯的pass@k分数要好,因为它做了很多工程优化,比如理解上下文代码、根据项目风格调整生成结果、快速响应用户输入。这些能力在孤立的函数级评测中完全体现不出来。
评估一个代码生成模型能不能真正用起来,我会看三个层面。首先是基础能力,就是HumanEval和MBPP这些分数,这是及格线,低于70%基本不用考虑。其次是代码质量,生成的代码是不是符合团队的编码规范,变量命名是否合理,注释写得清不清楚,这需要人工抽查一批生成结果,看是不是需要大幅改动才能用。第三个也是最容易被忽略的,就是响应速度和稳定性。如果模型生成一个函数要等10秒钟,或者三天两头服务不可用,功能再强也没法集成到开发流程里。

HumanEval这类评测集本质上定义了代码助手的能力边界。早期的代码补全工具只能预测下一个词,现在大家都在往更复杂的任务演进,比如Agent化的编程助手。像现在很多团队在探索的代码Review助手,就不只是生成代码,还要能理解整个Pull Request的改动,指出潜在的bug和优化点。
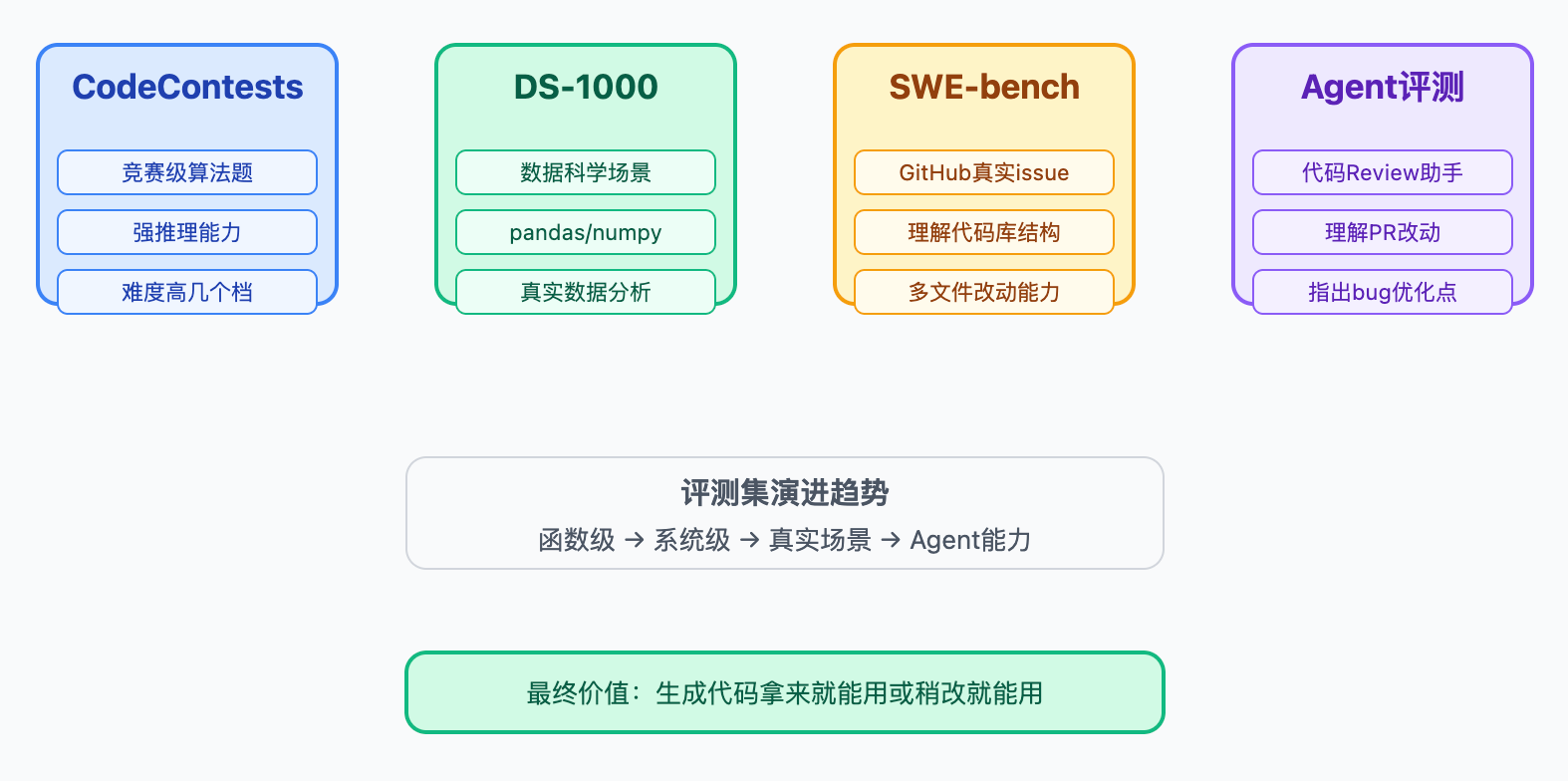
这种能力已经超出了HumanEval的测试范围,所以产品团队会参考SWE-bench这类新评测集,它测的是模型能不能解决GitHub上的真实issue,涉及多文件改动、依赖理解、测试覆盖这些复杂场景。
局限性与演进方向
这些评测集确实推动了进步,但也有明显的局限。最核心的问题是它们只测函数级的孤立任务,而真实开发中代码是系统性的。比如我们写一个支付模块,需要考虑多个类之间的协作、异常处理的层次、接口设计的一致性,这些HumanEval都测不到。它只能告诉你模型会不会写单个函数,但不知道模型能不能搭建完整的工程结构。
很多题的测试用例其实不够充分,模型可能写出了一个碰巧通过的实现,但换个输入就挂了。这在HumanEval上尤其明显,因为它不公开完整的测试集,模型训练时可能无意中记住了评测集的模式。2025年有个越来越明显的问题,很多模型训练时可能已经见过类似的题目,所以在公开评测集上刷高分变得越来越容易。真正的能力可能没那么强,只是记住了答案的模式。
HumanEval这类评测集最大的问题是只看功能正确性,但实际开发中代码质量同样重要。比如生成一个排序函数,模型用暴力的冒泡排序也能通过测试,但在生产环境处理大数据集时性能就崩了。评测集不会告诉你这个实现有问题。还有代码的可读性和可维护性,变量命名是不是语义化、逻辑是否清晰、有没有合理的注释,这些都会影响后续迭代,但pass@k指标完全反映不出来。

除了这两个经典评测集,最近也冒出来不少新的基准测试,各有各的侧重点。比如CodeContests关注的是竞赛级别的算法题,难度比HumanEval高好几个档次,需要模型有比较强的推理能力才能解出来。DS-1000则专门测试数据科学场景,看模型能不能用pandas、numpy这些库处理真实的数据分析任务。SWE-bench特别有意思,它从GitHub真实项目里抽取issue,要求模型看懂整个代码库的结构,定位问题然后修复。这已经不是写单个函数的能力了,更像是在考察模型能不能像人类工程师那样理解复杂系统。
评测集的分数再高,最终还是要看能不能真正提升开发效率。我觉得一个代码助手好不好用,关键看它能不能融入日常工作流。如果开发者还得花时间去理解生成的代码、修改各种bug,那宁可自己写。真正有价值的是那种生成的代码拿来就能用,或者稍微改改就能用的场景。所以未来的评测可能不只是测功能正确性,还要测生成速度、代码质量、对上下文的理解能力,甚至要测试在真实开发环境中的表现,这才能真正反映模型的实用价值。