精炼回答
RAG向量库的增量维护核心在于建立文档ID与向量ID的映射关系。这个问题的本质是要解决文档和向量的一致性问题,因为一个文档会被切分成多个chunk,每个chunk对应一个向量,所以文档的任何变动都需要精准地映射到向量层面的操作。
在插入阶段,每个文档切片后生成的向量都要关联原始文档ID和chunk位置信息,存入向量库的metadata字段。这样后续就能精准定位需要操作的向量。删除文档时,通过文档ID查询出所有关联的向量ID,批量调用向量库的delete接口删除。像Pinecone、Milvus这些向量库都支持基于metadata的过滤删除,一条delete语句就能清理干净。
修改文档更麻烦些,本质是先删后插。你需要先用旧文档ID删除所有向量,然后对修改后的文档重新做embedding和切片,生成新向量插入。这里有个优化点是可以对比新旧文档的chunk差异,只删除和插入变化的部分,但实现复杂度会高不少,通常全量替换就够用了。
实际应用中还要维护一张关系表,记录文档ID、向量ID列表、文档版本号和时间戳。这样既能追溯历史,也方便做并发控制。比如用户同时修改同一文档时,通过版本号判断是否需要重新embedding。另外要注意向量库的删除通常是标记删除,需要定期compact来真正释放存储空间,这点在设计定时任务时要考虑进去。
扩展分析
从整体思路到实现细节
遇到这类题目,很多同学会直接跳到"我用Milvus怎么删除向量"这种实现细节,这就掉进坑里了。更好的策略是先把问题的本质说清楚,再展开解决方案。你可以从数据层面、操作层面、工程层面这三个维度来组织思路,这样显得考虑得很全面。
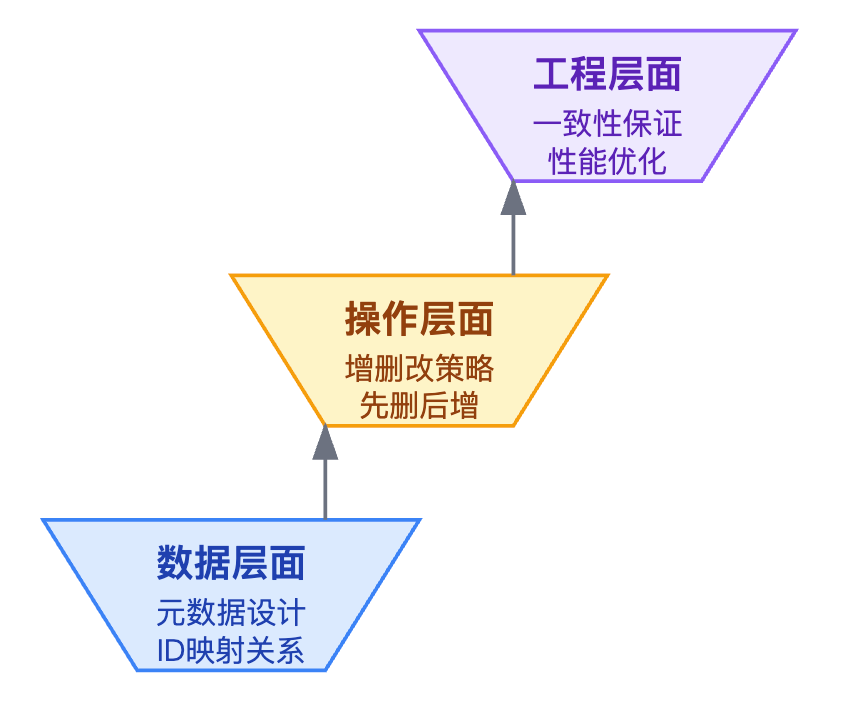
数据层面需要维护文档ID到向量ID的映射关系,这是所有操作的基础。metadata的设计至关重要,核心字段包括document_id用来关联原始文档、chunk_id标识这是文档的第几个片段、version字段做版本控制每次修改都递增、timestamp记录向量的创建时间方便做数据清理和审计。根据业务需要可能还要加source_type标识文档来源、chunk_text存一小段原文用于调试、embedding_model记录用的哪个模型版本。
说到具体操作时,从最简单的新增开始讲。当有新文档进来时,切分chunk、生成embedding、插入向量库这个流程比较直观,关键是要在向量的metadata里记录好source_doc_id和chunk_position这些信息。这个过程可以用下面的流程来表示:
删除操作是个很好的展示点,但这里面有个认知误区要特别注意。删除不是简单调用一个delete接口这么简单,你要区分两种场景来处理。如果是用户主动删除文档,通常会先做软删除,就是在metadata里加个deleted标记和deleted_at时间戳,查询时过滤掉这些向量。这样做的好处是万一用户误删了还能快速恢复,而且也方便做数据审计。真正的物理删除会放在定时任务里批量处理,比如每天凌晨把标记删除超过30天的向量彻底清理掉。
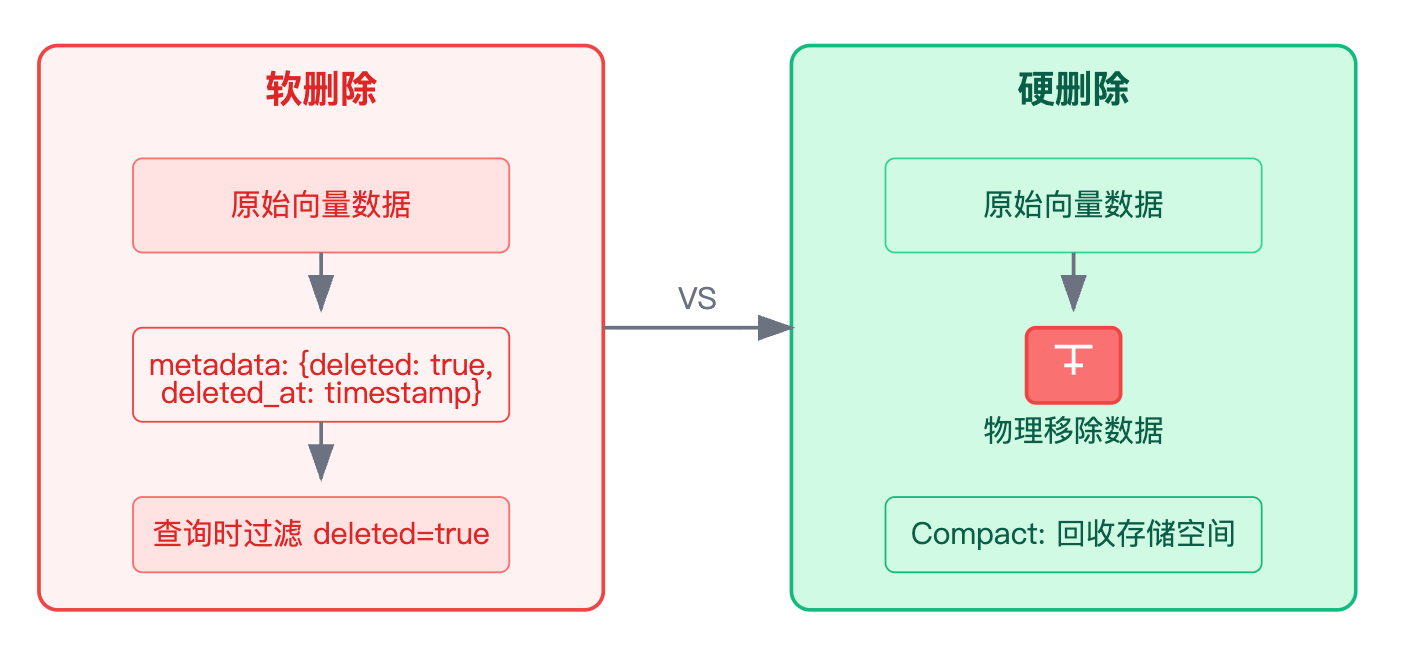
这时候就要注意向量库的compact机制了,因为Milvus这类数据库的删除是标记删除,不会立即释放存储空间,需要手动触发compaction才能真正回收。大量删除操作之后,向量索引可能会碎片化,查询性能会下降。这时候要权衡是增量维护索引还是重建索引,经验来看如果删除量超过总数据的20%,重建索引的性价比会更高。
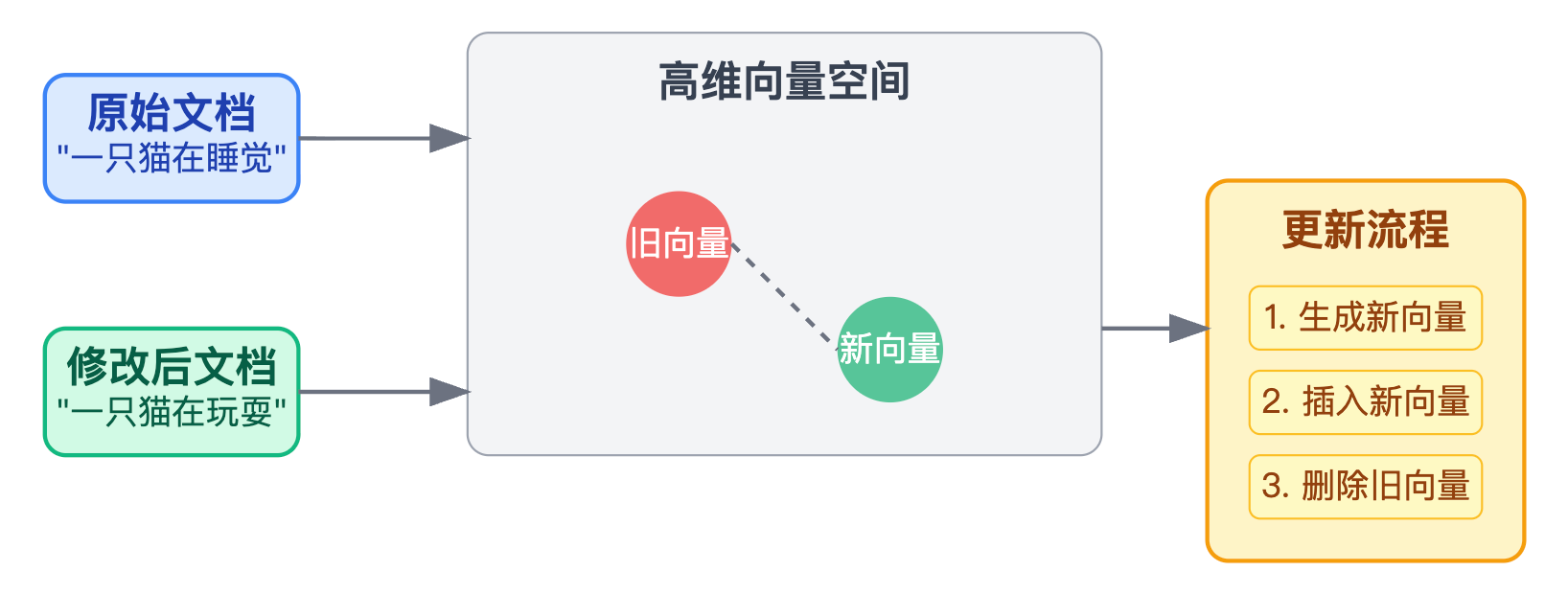
修改操作最能体现你的思考深度。你要能解释清楚为什么不能直接更新向量:向量数据库存储的向量是高维浮点数组,如果文档内容改了哪怕一个字,重新跑embedding模型生成的向量在高维空间的位置可能完全不同,没法像传统数据库那样update某几个字段,所以只能是先删后增的方式。
实现的时候有两个思路。第一种是全量替换,把文档关联的所有向量都删掉重新生成,这种方式实现简单代码逻辑清晰,对于大多数场景都够用。第二种是差分更新,适合文档特别大的情况。比如一份产品使用手册有100个chunk,用户只修改了其中一个章节,这时候可以先对新旧文档做chunk级别的diff,找出变化的部分,只删除和重新生成变化chunk对应的向量。
不过这种方式要解决几个问题:chunk的边界可能会变,修改一个段落可能影响前后chunk的切分;要实现一套稳定的diff算法;还要处理好并发场景下的版本冲突。所以除非确实有大文档更新的性能瓶颈,否则不建议过早优化。这样既展示了你知道优化方向,又体现了务实的工程思维。
向量库和源文档要保持一致性,实际做法是维护一张关系表在MySQL这类事务型数据库里,记录document_id、vector_ids数组、version、status这些信息。文档更新时先改状态为updating,向量操作完成后再改为active。这样即使中间出现异常,也能通过状态字段识别出来,定时任务可以重试或者告警。下面是一个完整的更新流程实现:
publicclassDocumentUpdateService{
@Autowired
privateVectorDatabase vectorDB;
@Autowired
privateMappingRepository mappingRepo;
@Autowired
privateEmbeddingService embeddingService;
publicvoidupdateDocument(String docId,String newContent){
// 查询旧向量ID列表
List<String> oldVectorIds = mappingRepo.getVectorIds(docId);
int currentVersion = mappingRepo.getVersion(docId);
// 标记为更新中状态,防止并发修改
boolean locked = mappingRepo.updateStatus(docId,
DocumentStatus.UPDATING, currentVersion);
if(!locked){
thrownewConcurrentModificationException(
"文档正在被其他进程修改");
}
try{
// 先生成新向量,确保embedding成功
List<String> chunks =chunkDocument(newContent);
List<Vector> newVectors =newArrayList<>();
for(int i =0; i < chunks.size(); i++){
float[] embedding = embeddingService.embed(chunks.get(i));
Map<String,Object> metadata =newHashMap<>();
metadata.put("document_id", docId);
metadata.put("chunk_id", i);
metadata.put("chunk_text", chunks.get(i).substring(0,
Math.min(200, chunks.get(i).length())));
metadata.put("version", currentVersion +1);
metadata.put("timestamp",System.currentTimeMillis());
metadata.put("deleted",false);
newVectors.add(newVector(embedding, metadata));
}
// 插入新向量到向量库
List<String> newVectorIds = vectorDB.insert(newVectors);
// 删除旧向量(先插后删,保证服务可用性)
if(!oldVectorIds.isEmpty()){
vectorDB.delete(oldVectorIds);
}
// 更新映射关系,增加版本号
mappingRepo.updateMapping(docId, newVectorIds,
currentVersion +1);
mappingRepo.updateStatus(docId,DocumentStatus.ACTIVE,
currentVersion +1);
}catch(Exception e){
// 更新失败,回滚状态
mappingRepo.updateStatus(docId,DocumentStatus.FAILED,
currentVersion);
thrownewRuntimeException("文档更新失败: "+ e.getMessage(), e);
}
}
privateList<String>chunkDocument(String content){
// 简化的切片逻辑,实际应用中需要更智能的切分策略
List<String> chunks =newArrayList<>();
int chunkSize =512;
int overlap =50;
for(int i =0; i < content.length(); i += chunkSize - overlap){
int end =Math.min(i + chunkSize, content.length());
chunks.add(content.substring(i, end));
if(end >= content.length())break;
}
return chunks;
}
}java
这段代码里有几个关键的设计考量。先插入新向量再删除旧的,虽然中间有短暂的数据冗余,但能保证服务可用性,避免删除成功但插入失败导致文档丢失的情况。版本号做乐观锁,更新前先检查版本号是否匹配,如果不匹配说明有人已经修改过了,这时候要提示用户刷新后再编辑。状态机管理,通过UPDATING、ACTIVE、FAILED三种状态来追踪文档的处理过程,即使中间出现异常也能识别出来。
主流向量库在基本操作上大同小异,Milvus和Weaviate都支持基于表达式的过滤删除,Pinecone用的是namespace隔离。真正的差异在于索引策略和一致性保证。比如Milvus支持手动flush控制数据持久化的时机,适合批量导入场景;Pinecone是全托管服务,索引维护是自动的,但灵活性会差一些。
实践场景与性能优化
典型应用主要有几类,比如企业知识库的文档更新、新闻资讯类的内容时效性维护、还有客服FAQ的动态调整。这些场景的共同特点是数据不是一次性导入就完事了,而是持续在变化。拿新闻资讯来说会比较典型,因为逻辑清晰容易理解。
单条更新在并发量大的时候效率很低,因为每次操作都要跟向量库交互。优化思路是攒批处理,比如设置一个队列,每收集到100个更新请求或者等待时间超过5秒就触发一次批量操作。具体选择实时更新还是批量更新,取决于业务的容忍度。客服FAQ这种场景,运营修改后希望立即生效,那就要用实时更新,可能就几十条数据性能压力不大。但如果是商品库存同步到搜索这种场景,每秒可能有上千次变更,必须用批量处理才扛得住。
系统上线后要重点关注几个指标。
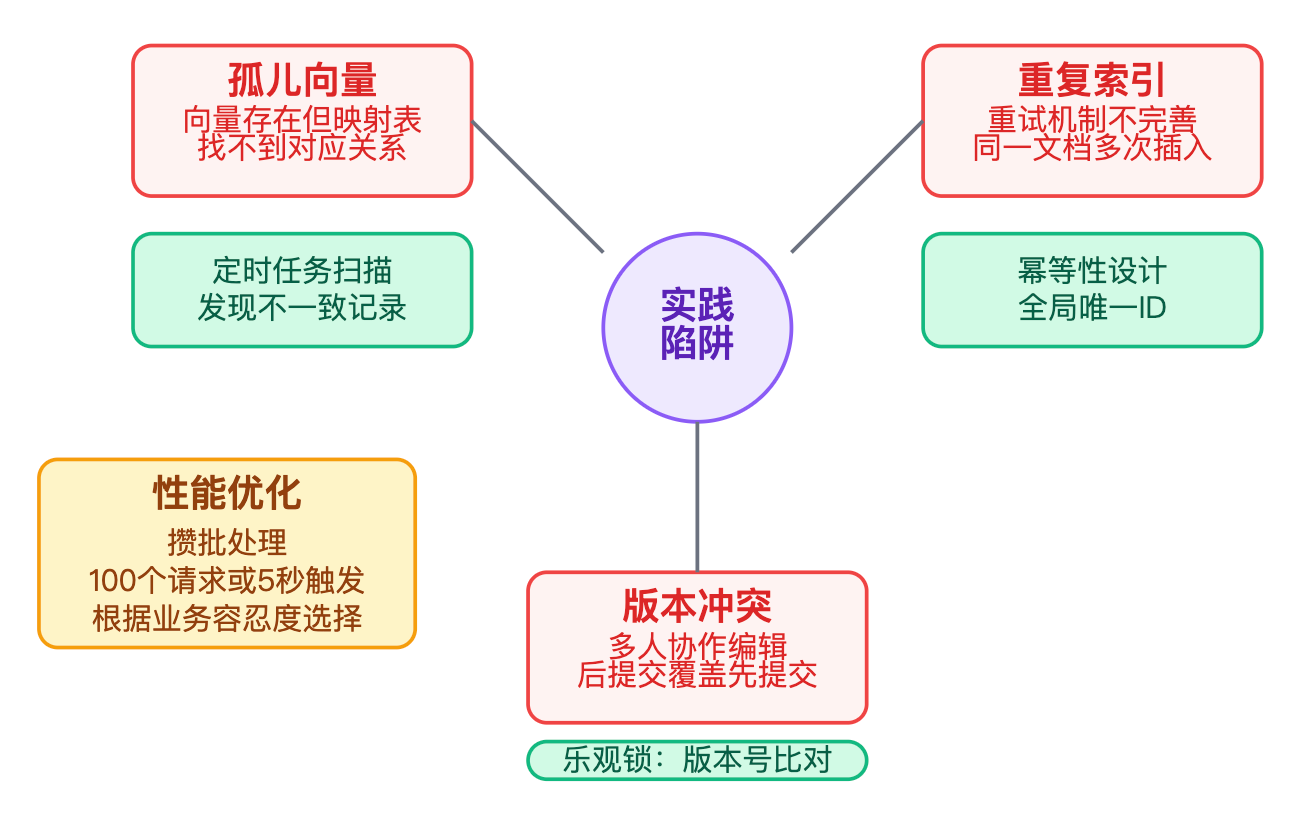
孤儿向量 是个容易出问题的地方,就是向量库里有数据但映射表里找不到对应关系,这种情况通常是因为删除操作失败或者程序异常退出导致的。可以写个定时任务,每天扫描一遍向量库和映射表,找出不一致的记录,发现孤儿向量就记录到日志里人工确认后清理掉。
重复索引是另一个常见陷阱。如果更新逻辑写得不严谨,可能会把同一个文档的向量插入多次。比如重试机制没做好,第一次请求超时了实际已经插入成功,重试时又插入了一遍,这会导致搜索结果里出现重复内容。解决方案是做幂等性设计,给每个向量分配一个全局唯一的ID,插入前先检查是否已存在。或者更简单的做法是先删除再插入,保证同一个文档只有一份数据。
版本冲突在多人协作场景下尤其明显。假设两个编辑同时在修改一篇文章,A修改了标题,B修改了正文,如果没有版本控制,后提交的人会把先提交的改动覆盖掉。可以在metadata里维护version字段,每次更新前先读取当前版本号,更新时带上这个版本号去比对。如果发现版本号不匹配,说明有人已经修改过了,这时候要提示用户刷新后再编辑,这种处理方式和Git的冲突解决思路是类似的。