精炼回答
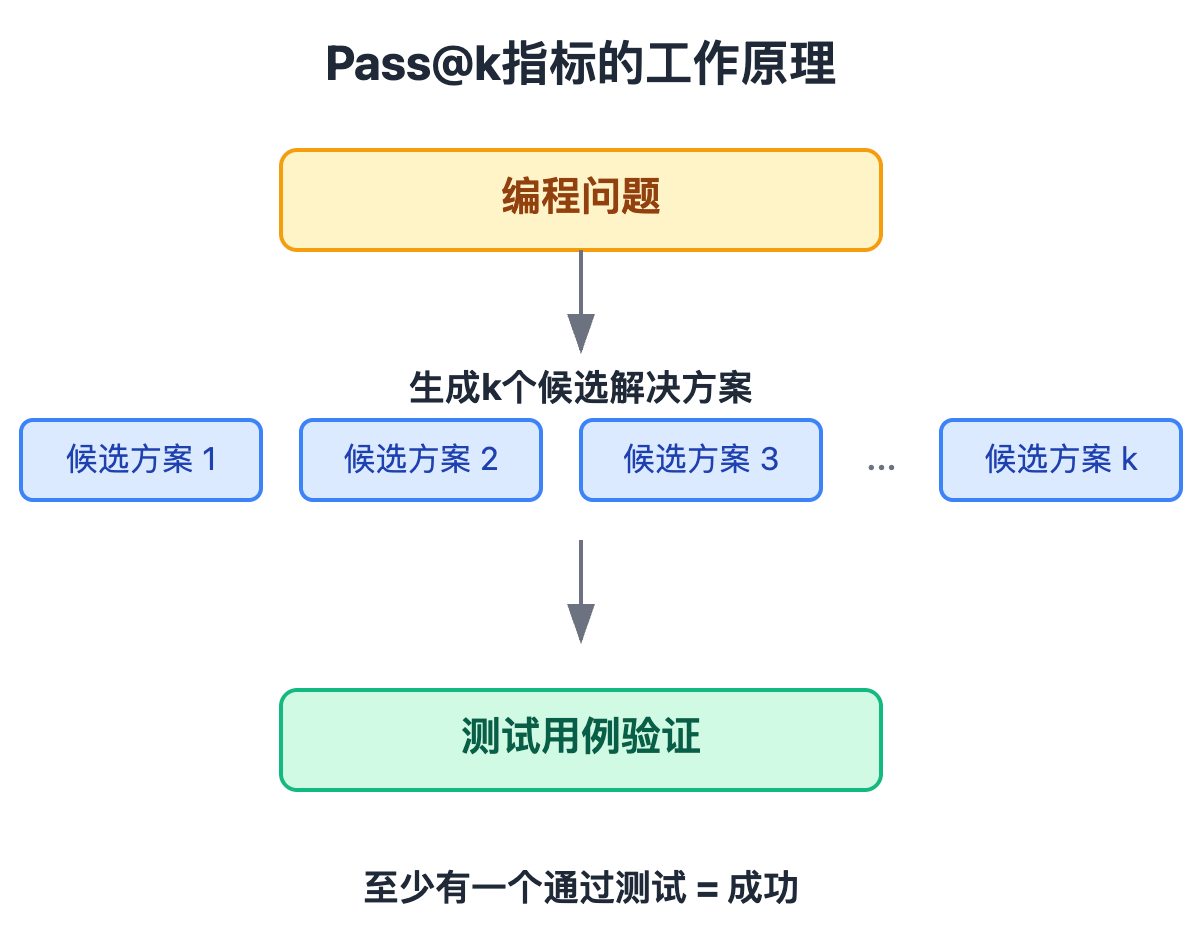
代码生成的评估指标主要关注生成代码的正确性和质量两个维度。其中Pass@k是最核心的正确性指标,它的具体含义是:对于一个编程问题,让模型生成k个不同的候选解决方案,只要其中至少有一个能通过所有测试用例,就算成功。比如Pass@1表示生成1个解决方案的通过率,Pass@10表示生成10个方案中至少1个通过的概率。这个指标反映了模型在给定多次机会时解决问题的能力,实际应用中很有意义,因为开发者可以从多个候选方案中选择。
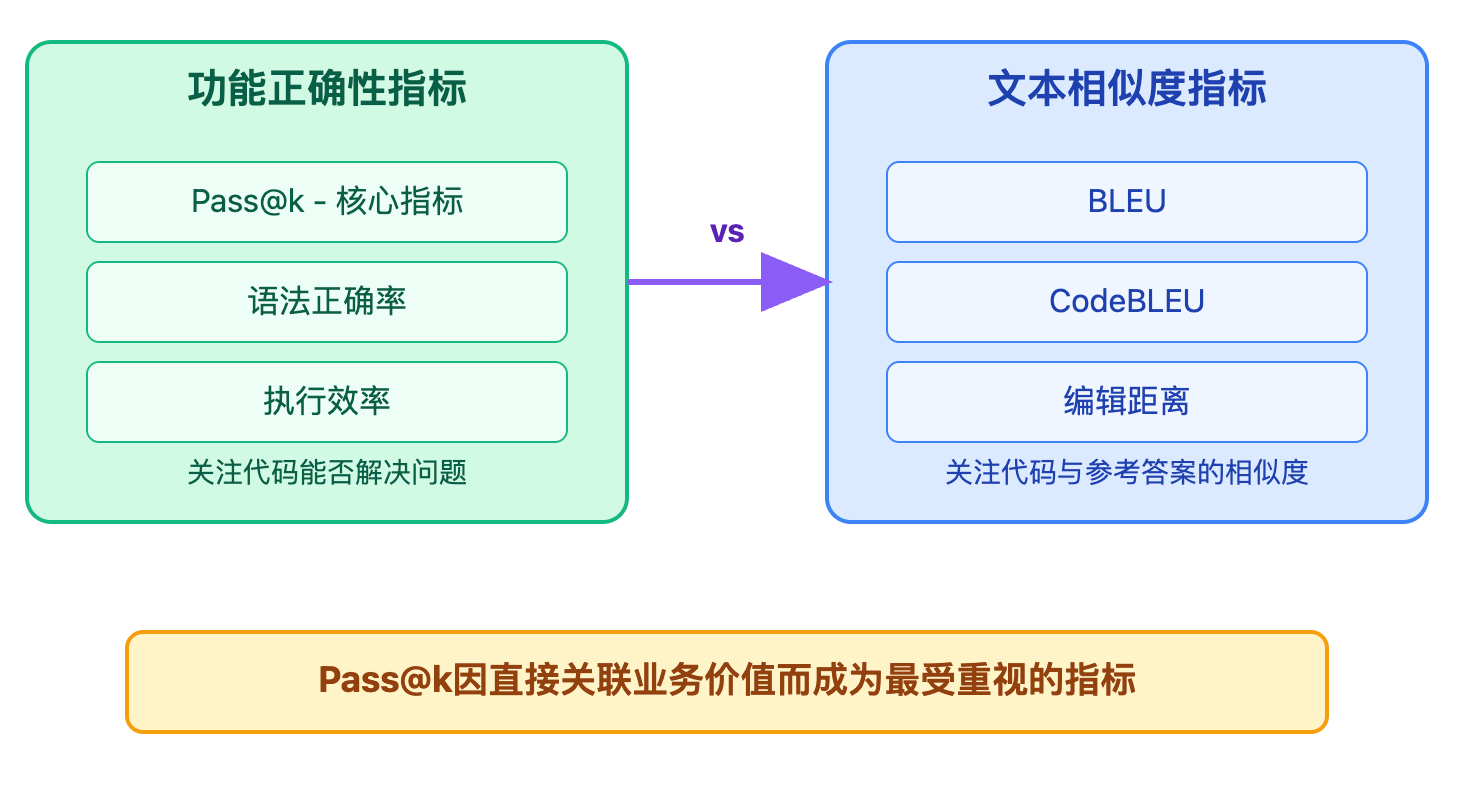
除了Pass@k,还有几个重要指标值得关注。BLEU和CodeBLEU通过n-gram匹配衡量生成代码与参考代码的相似度,但它们只看表面文本,不关心功能正确性。编辑距离测量生成代码与标准答案需要多少修改操作。语法正确率检查生成的代码是否能通过编译器或解释器的语法检查。在实际场景中,评估一个代码补全工具时,你会用Pass@k衡量它能否生成可运行的函数实现,用CodeBLEU评估代码风格是否符合项目规范,用语法正确率确保不会生成语法错误的代码浪费开发者时间。Pass@k因其直接关联业务价值(能否解决问题)而成为最受重视的指标。
扩展分析
理解代码评估的本质挑战
面试时讲到评估指标,很多候选人会习惯性地直接罗列各种指标名称,但面试官其实更想听到你为什么要设计这些指标。代码生成评估最根本的挑战在于功能等价性判断的复杂性。你可以这样切入:"评估代码生成和评估机器翻译完全不是一回事。翻译任务中,'你好'翻译成'Hello'基本是标准答案,但写一个排序函数,有人用快速排序,有人用归并排序,有人直接调库函数,这三种实现方式代码长得完全不一样,但功能都对。这就导致我们不能简单地用文本匹配来判断生成质量。"
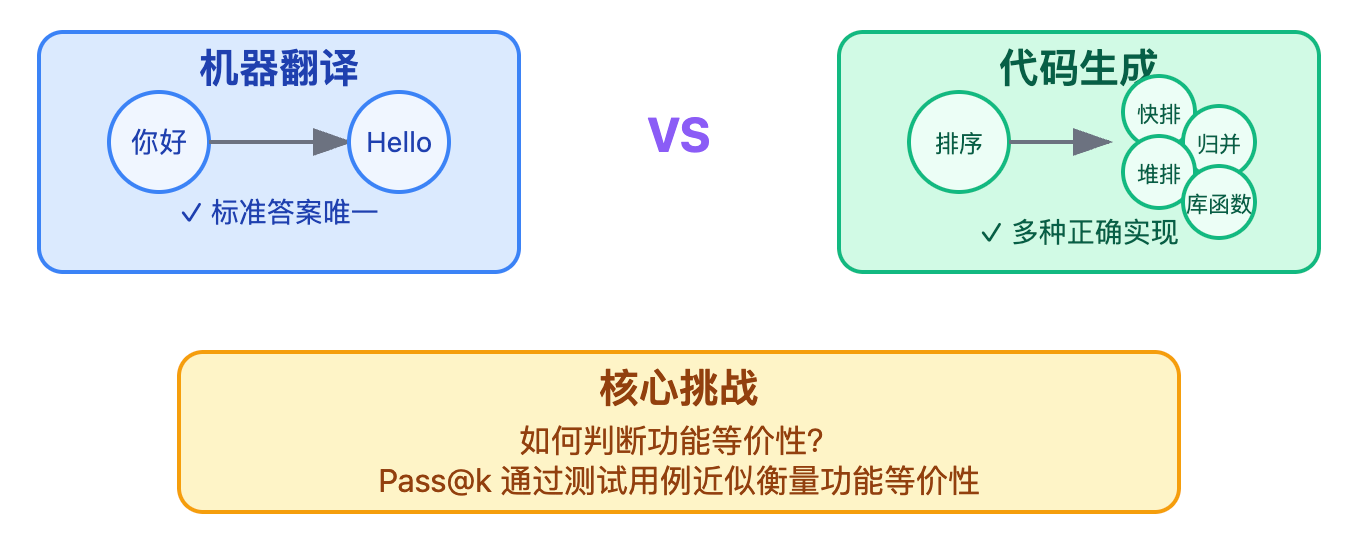
这个对比能迅速让面试官感受到你理解问题的本质。代码评估真正关心的是功能等价,也就是在所有可能的输入下,生成代码和参考代码的输出是否一致。但这在理论上是不可判定问题,实践中只能通过测试用例来近似。
Pass@k实际上就是用测试通过率来近似衡量功能等价性,这也是为什么评估指标主要分为两大类:一类是功能正确性指标,关注代码能不能跑通、能不能解决问题,像Pass@k就属于这类;另一类是文本相似度指标,比如BLEU、CodeBLEU,关注生成的代码和参考代码在表面上像不像。
Pass@k的设计精髓在于它模拟了开发者的真实使用场景。IDE的代码补全工具会给你推荐多个候选,你可以从中选一个能用的。k越大,模型在多次尝试下解决问题的能力越强,这比只看Pass@1更能反映工具的实用价值。Pass@k计算的是从n个生成样本中随机抽取k个,至少有一个通过测试的概率,具体公式是:1 - C(n-c, k) / C(n, k),这里n是总生成数,c是其中通过测试的数量。
OpenAI在HumanEval数据集论文里提到一个实用细节:直接生成k个样本会带来很大的方差,特别是k比较大的时候成本也高。所以实际操作中通常生成n个样本(比如n=200),然后用无偏估计器计算不同k值下的Pass@k。这样既降低了方差,也提高了计算效率。Pass@k中k值的选择映射着不同的应用场景,Pass@1代表模型一次性生成正确代码的能力,这对应着开发者不想做任何选择,希望模型直接给出可用方案的场景。Pass@10更接近真实的IDE辅助编程场景,比如GitHub Copilot会给你展示多个建议,你浏览一下选一个最合适的。Pass@100则常用于学术研究,评估模型的理论上限能力。
传统NLP指标的水土不服是另一个需要深入理解的点。BLEU这类指标从机器翻译领域借鉴过来,核心思路是统计n-gram重合度。它计算生成代码和参考代码之间有多少1-gram、2-gram、4-gram是相同的,然后加权平均。这个指标的问题在于它完全是表面文本匹配,两段功能完全相同但变量名不一样的代码,BLEU分数可能很低。
举个直观的例子,假设参考答案是计算数组总和,用sum作为变量名,循环变量是i。模型生成的代码功能完全一样,但变量名改成total,循环变量改成j。这两段代码功能完全一致,但因为这些变量名的差异,BLEU分数会显著下降。这就是为什么纯文本匹配指标在代码评估中不够用。
CodeBLEU的设计初衷就是弥补BLEU的不足。它在BLEU基础上增加了三个代码专属的维度:抽象语法树(AST)的匹配度,比较两段代码的结构是否相似;数据流的一致性,检查变量的定义和使用关系是否对应;关键词的权重加成,因为像if、for这些关键词比普通标识符更重要。同样是sum改成total的情况,CodeBLEU会发现虽然变量名变了,但AST结构完全一致,数据流也匹配(都是先定义变量,然后在循环里累加),所以分数不会掉那么多。
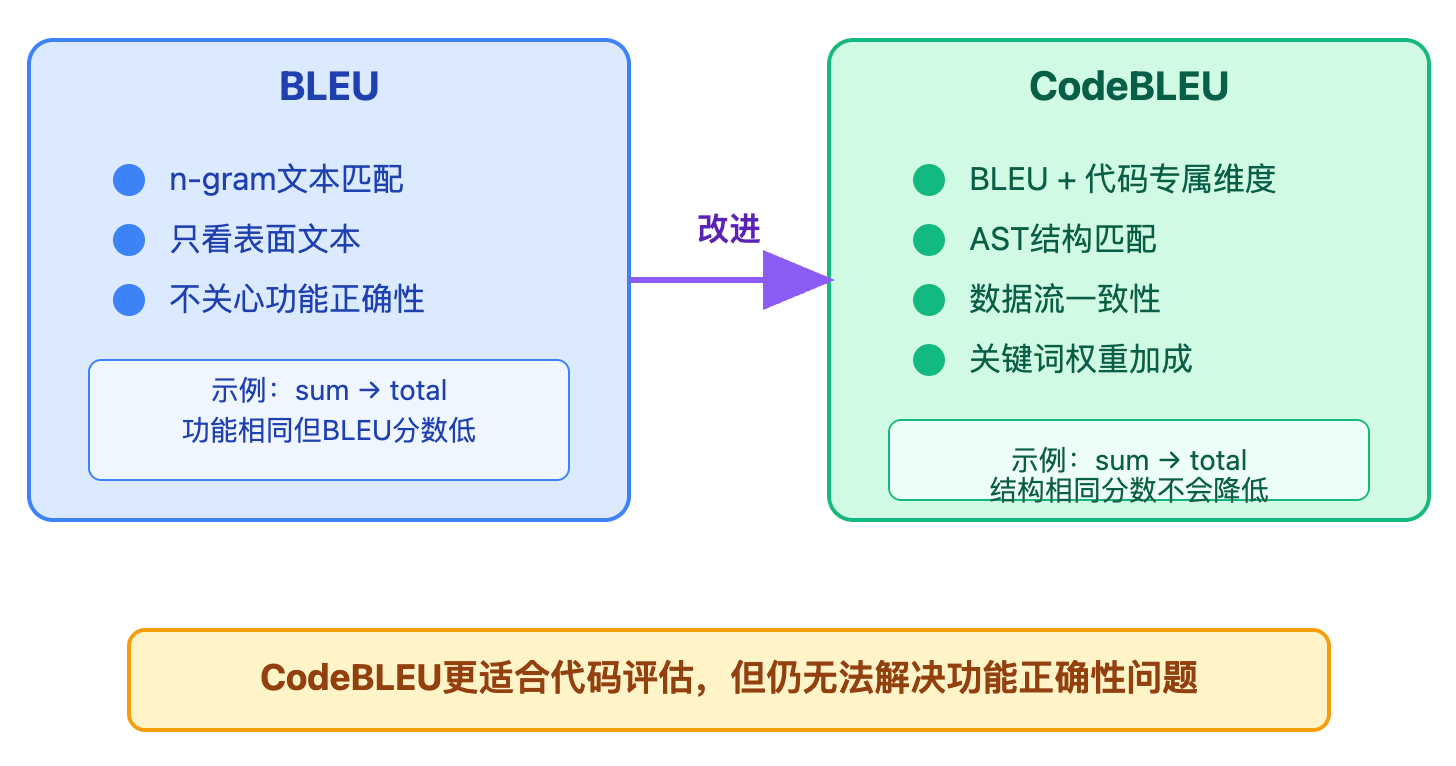
不过CodeBLEU也不是万能的,它还是在做相似度匹配,解决不了本质问题——功能正确性。两段代码AST结构很像,数据流也匹配,但可能一个有边界条件bug,一个没有,这种情况CodeBLEU分不出好坏。Exact Match(精确匹配)是最严格的指标,要求生成代码和参考答案完全一致,连空格缩进都不能差,在代码生成场景基本没有实用价值,因为它太脆弱了。即使生成的代码功能完全正确,只要格式化风格不同,Exact Match就判定为失败。
测试用例覆盖率的隐形影响是一个容易被忽视但很关键的点。Pass@k的可靠性完全依赖于测试用例的质量。HumanEval数据集每道题平均只有7.7个测试用例,这个覆盖率其实相当有限。如果测试用例没有覆盖到边界条件,一个有bug的实现可能也能通过所有测试,导致Pass@k虚高。假设要实现一个判断质数的函数,测试用例只有isPrime(2)=true和isPrime(4)=false,那么一个错误的实现也能通过测试。这种情况下高Pass@k分数并不代表模型真的学会了判断质数。
评估指标的实战应用
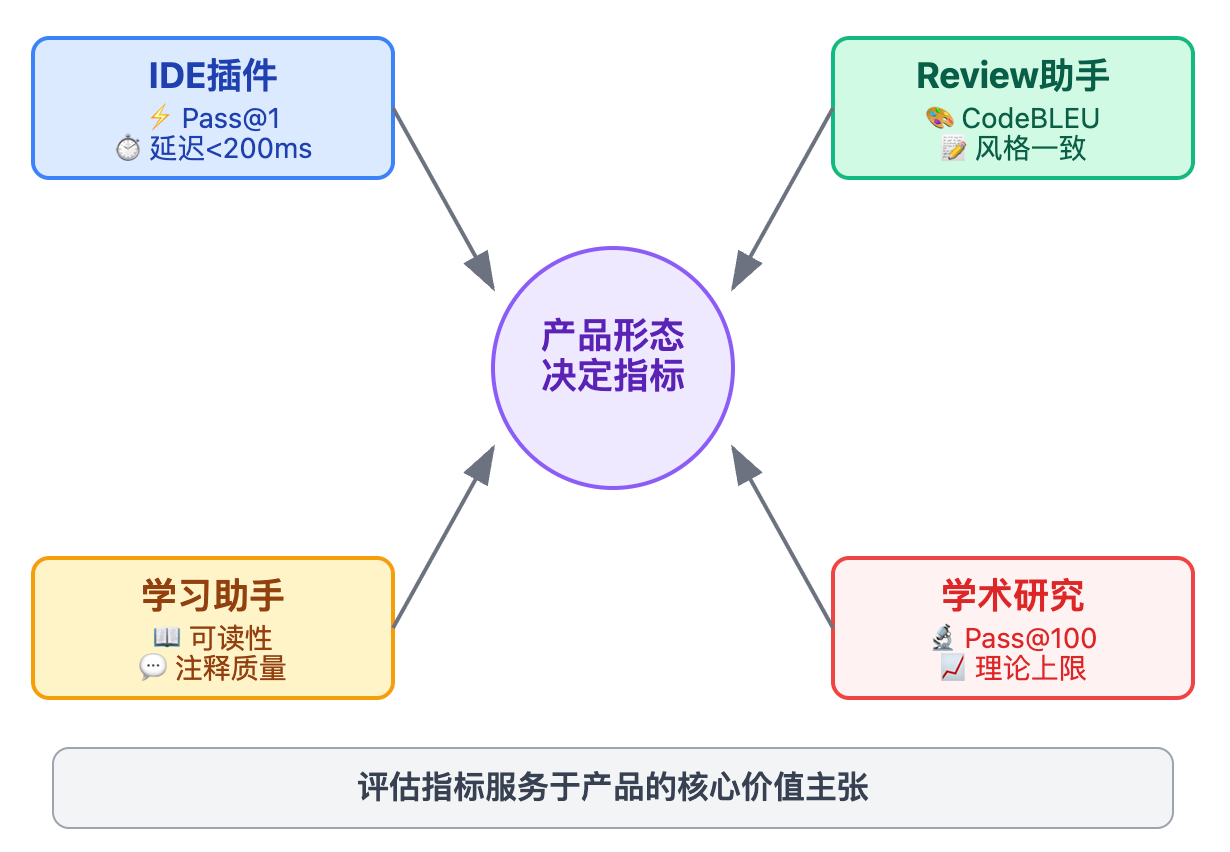
评估指标的选择要从产品形态倒推。如果是做IDE插件类的代码补全工具,核心诉求是快速给出可用建议,这时候Pass@1和响应延迟是最关键的指标,Pass@1决定了用户接受建议的频率,延迟超过200毫秒用户体验就会明显下降。如果是做代码Review助手,那CodeBLEU就更重要了,因为你要保证生成的代码风格和团队规范一致,即使功能对了但命名方式不符合规范,Pull Request还是会被打回。
一个好的测试用例集至少要覆盖三类场景:基础功能验证,就是正常输入下能不能得到正确输出;边界条件测试,比如空数组、负数、超大整数这些极端情况;异常处理,检查生成的代码遇到非法输入会不会直接崩溃。拿一个具体问题举例,假设要生成一个查找数组中第k大元素的函数,基础测试会验证[3,2,1,5,6,4], k=2返回5,边界测试要检查k=1和k=数组长度的情况,异常测试要覆盖k<=0或者k大于数组长度时是否有合理的错误提示。实际项目中至少要设计15到20个用例才能保证覆盖率。
采样策略的技术细节也是实践中的关键。实际评估时有两个关键参数要调:temperature和top-p。temperature控制生成的随机性,设置为0模型每次输出都一样,设置为1会增加多样性。评估Pass@1时通常把temperature设为0,因为要看模型最有把握的答案是否正确。但评估Pass@10或者Pass@100时,temperature要调到0.8左右,保证生成的k个候选方案足够多样,否则生成的10个方案可能有8个几乎一模一样,这就失去了多次尝试的意义。
很多团队会犯一个错误,就是评估Pass@10时让模型连续生成10次,每次都是独立的推理过程。这样做成本特别高,而且引入了很大的方差。更工程化的做法是一次性生成100个或者200个候选,然后用无偏估计器计算不同k值下的Pass@k。这样既省推理成本,统计结果也更稳定。
实际项目中绝不能只看Pass@k,因为它只能告诉你代码能不能跑通,跑不跑得快、可不可读完全看不出来。一个典型的评估体系要包含至少三个维度:功能正确性用Pass@k衡量,代码质量用CodeBLEU或者静态分析工具的评分,执行效率看生成代码的时间复杂度和实际运行时间。假设让模型生成一个排序函数,用冒泡排序和快速排序都能通过测试用例,Pass@k看不出差别,但时间复杂度一个是O(n²)一个是O(nlogn),在大数据量场景下性能差几十倍。这种情况下就需要在评估流程中加入性能基准测试,对不同输入规模测量实际运行时间。
代码可读性也是一个容易被忽视的维度。在实践中会引入代码复杂度检测,比如用圈复杂度(Cyclomatic Complexity)衡量代码的分支结构是否过于复杂,用Pylint或者SonarQube这类静态分析工具检查命名规范、代码结构。一个Pass@1很高但生成的代码全是单字母变量名、没有注释的模型,实际使用体验会很差。
避开常见的评估陷阱同样重要。最大的误区是过度追求单一指标的提升。有些团队为了刷高Pass@k,在训练数据里混入大量测试集相似的题目,结果模型在HumanEval上分数特别好看,但换到真实业务场景效果立刻崩盘,这就是典型的过拟合评估集。另一个常见问题是测试用例设计不充分,只测试Happy Path不考虑异常情况。比如生成一个解析JSON字符串的函数,如果测试用例都是合法JSON,模型可能生成一段没有任何异常处理的代码,遇到格式错误的输入直接抛异常崩溃,但在评估中依然能拿到高分。
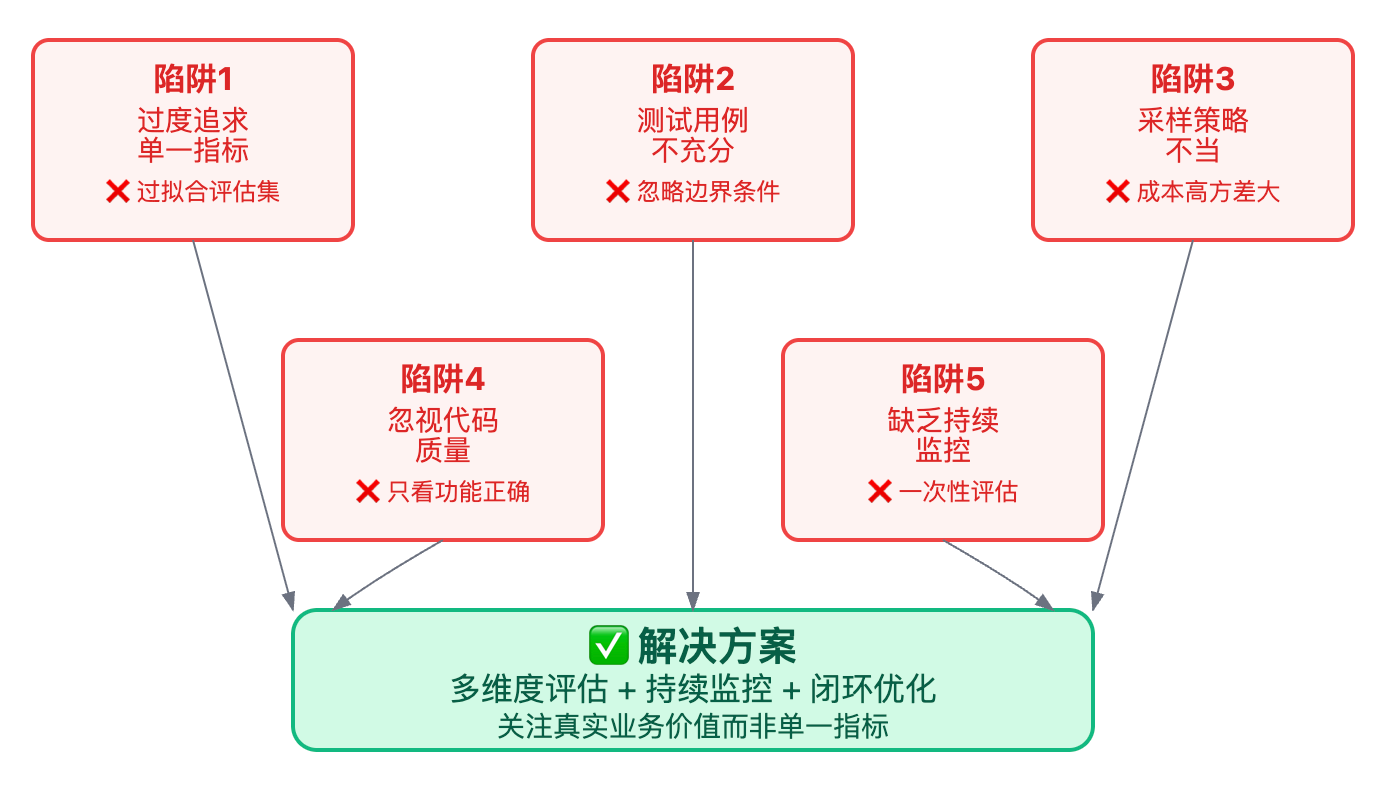
代码生成模型不是一次性评估完就结束了,特别是在生产环境中需要建立持续监控体系。记录用户实际采纳率,就是模型给出的建议有多少比例被开发者直接使用,这个指标比离线评估的Pass@k更能反映真实价值。同时要收集用户修改日志,看开发者接受建议后做了哪些修改,这些修改模式可以反哺到下一轮的模型优化中。这个闭环思维体现了对产品全生命周期的理解。
深层思考与行业趋势
当Pass@1和Pass@10差距特别大时,其实在释放一个信号:模型的生成多样性很强,但单次准确率不够。如果一个模型Pass@1只有20%,但Pass@10能达到70%,说明它能探索出正确解,但排序能力弱,没把最优答案排到第一位。这种情况下,可以考虑引入Reranking机制,用一个轻量级的判别模型对k个候选方案重新打分,把最可能正确的方案提到前面。这个分析展现了根据评估结果反推优化方向的能力。
从产品实践来看,评估方案往往需要持续演进。最初可能只看Pass@1,后来发现用户实际采纳率只有Pass@1的一半,因为生成的代码虽然功能对,但风格和现有代码库完全不搭。于是加入CodeBLEU评估风格一致性,还引入静态分析工具检查代码复杂度,最终把用户采纳率显著提升。这种从单一指标到多维度评估的演进过程,体现了技术如何服务业务价值。
2025年行业开始关注更长上下文的代码生成场景,比如让模型理解整个代码仓库后再生成新函数。这种场景下传统的Pass@k评估不够了,需要设计新指标衡量生成代码和已有代码的接口兼容性、调用关系的正确性。有团队在尝试用语义等价性验证工具,比如符号执行或者形式化验证方法,自动证明生成代码和参考实现在数学上等价。虽然这些技术还不成熟,但代表了评估方法的演进方向。
从架构思维角度看,评估指标的设计要服务于产品的核心价值主张。如果产品定位是提升开发效率,那响应速度和首位建议的准确率比Pass@100更重要。如果定位是代码学习助手,生成代码的可读性和注释质量比纯粹的功能正确性更关键。强调这种"终局思维",展现的是对技术如何创造业务价值的深刻理解,而不是为了做评估而评估。