精炼回答
Agent辩论模式是让多个Agent针对同一问题从不同立场进行论证和反驳,通过对抗性交互来暴露推理漏洞、挖掘多角度视角,最终收敛到更优质的答案。这个机制的核心是设置至少两个Agent扮演对立角色,一个提出论点,另一个质疑反驳,然后交替进行多轮辩论。在这个过程中,每个Agent都会被迫审视自己推理的薄弱环节,同时吸收对方的有效论据。
辩论模式提升答案质量的原理在于对抗性验证能有效减少单一Agent的幻觉和偏见。就像我们开技术评审会,不同同学从架构、性能、成本角度互相challenge,比一个人闷头想方案更容易发现盲区。比如在代码审查场景中,一个Agent提出某种实现方案,另一个Agent从性能、安全、可维护性角度挑战这个方案,经过几轮交锋后会暴露出初始方案可能忽略的边界条件或潜在bug。在复杂决策场景如医疗诊断建议、法律咨询中,辩论模式能确保考虑到多种可能性和风险点。
最后由裁判Agent或通过投票机制选出最佳答案,也可以让一个总结Agent整合双方观点形成综合结论。实现上需要注意给不同Agent设定明确且差异化的角色定位,避免陷入无效争论。辩论轮数通常控制在3到5轮,过多会导致成本上升而收益递减。这种模式特别适合答案具有争议性或需要多维度权衡的问题。
扩展分析
深入分析:从本质理解辩论模式的工作机理
很多人把Debate模式理解成简单的"找几个Agent投票",这就暴露了理解不到位。从本质上看,辩论模式的核心思想其实来源于一个朴素的认知规律:当我们被迫为自己的观点辩护时,思考会更加严谨。当一个Agent提出观点后,如果有另一个Agent从对立面挑战它,这个过程会强制第一个Agent重新审视自己的推理链条,找出那些经不起推敲的环节。这种对抗性的张力,恰恰是提升答案质量的关键驱动力。
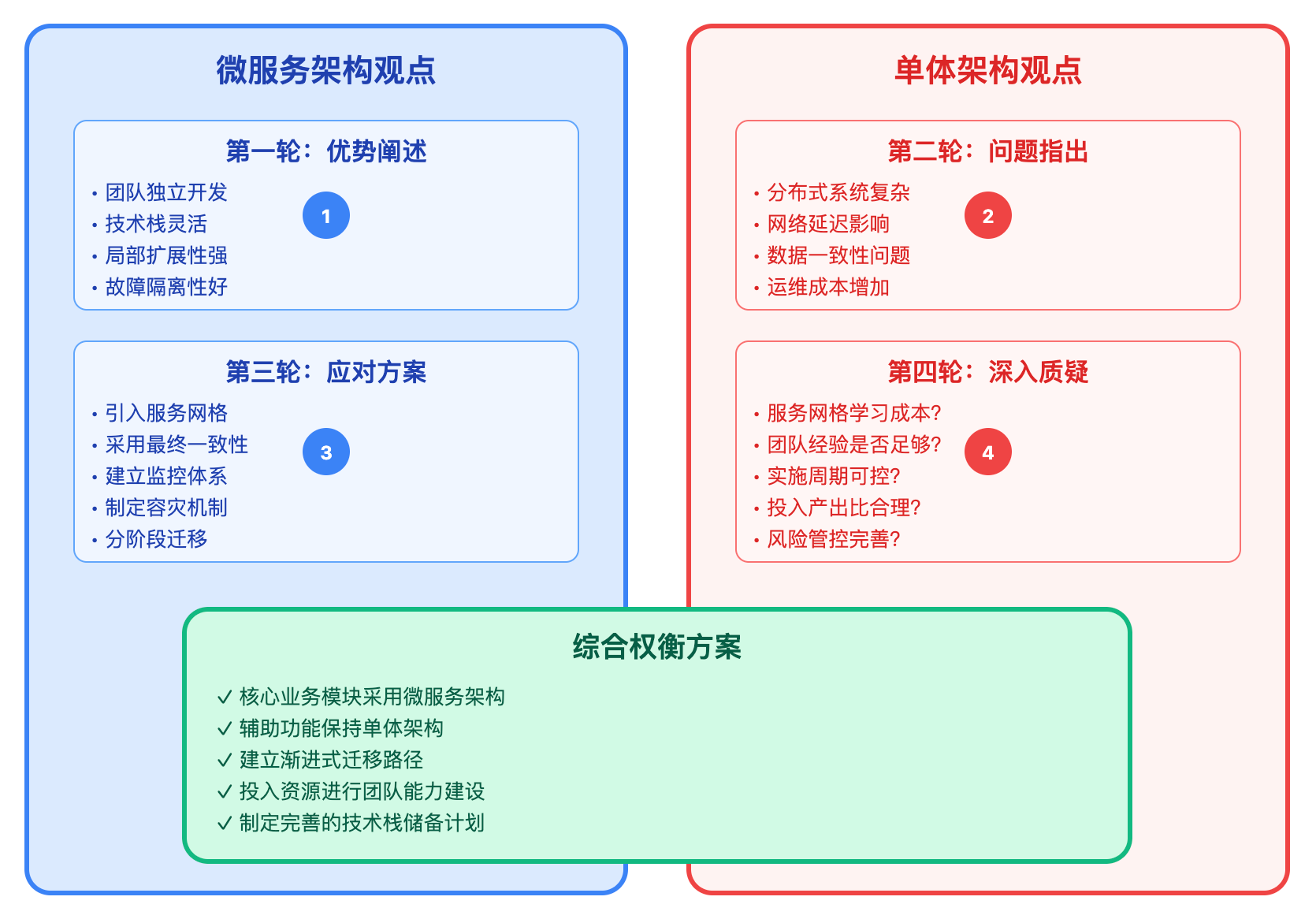
假设我们要设计一个技术方案评审系统,问题是"应该选择微服务架构还是单体架构"。在Debate模式下,我们会设置两个Agent,一个是架构师Agent偏向微服务,另一个是稳定性工程师Agent倾向单体。第一轮中,架构师Agent会提出微服务的优势——团队独立开发、技术栈灵活、局部扩展性强。稳定性工程师Agent立即反驳,指出分布式系统的复杂度、网络延迟、数据一致性问题。第二轮架构师Agent需要针对这些质疑给出应对方案,比如引入服务网格、采用最终一致性策略。稳定性Agent继续追问这些方案的实施成本和团队能力是否匹配。经过三到四轮这样的交锋,每个Agent的论述都被反复锤炼,最终我们得到的不是某一方的完胜,而是一个充分考虑了各种权衡因素的综合方案。
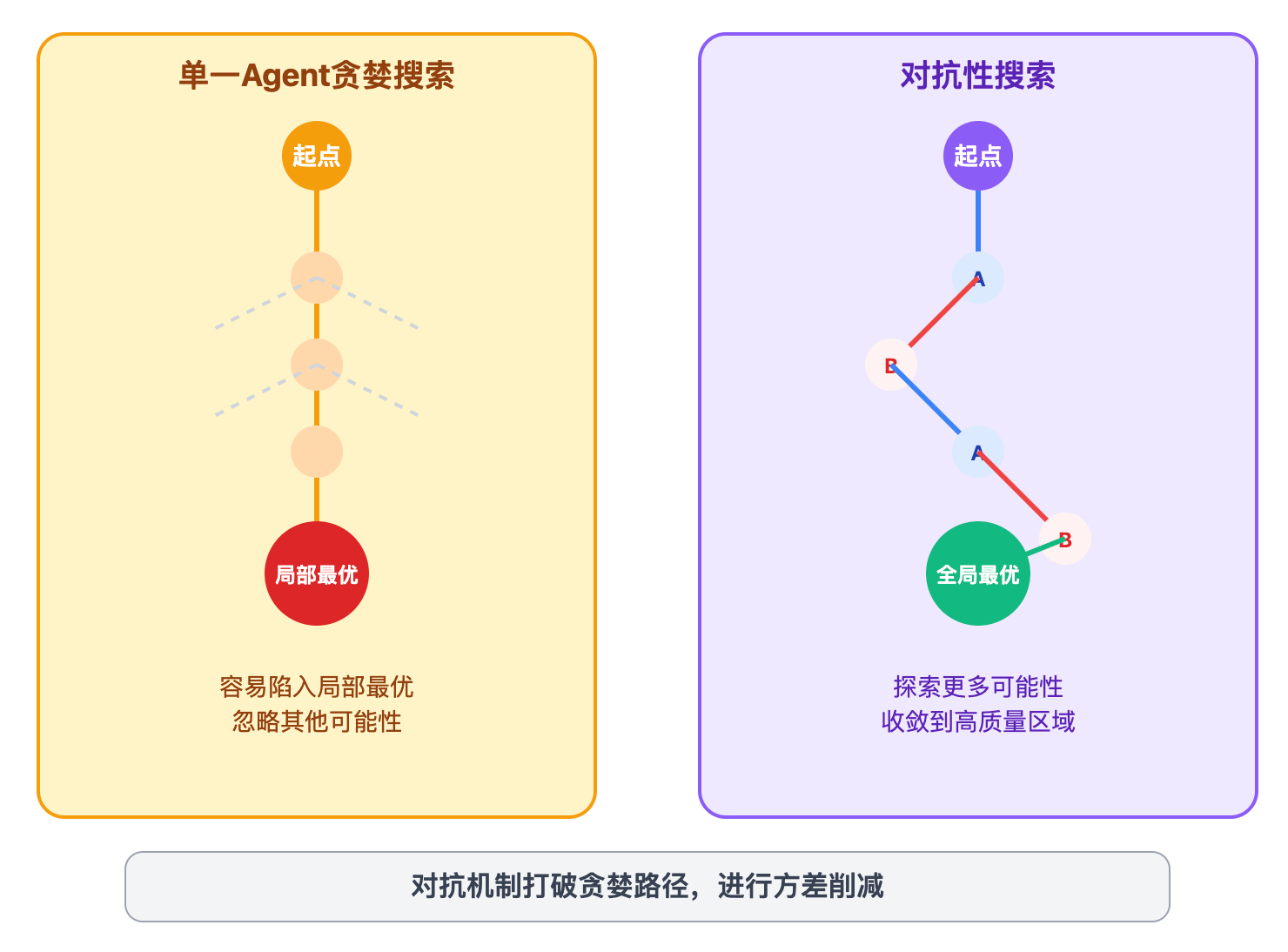
辩论提升质量的底层原理,其实是利用了对抗性搜索的思想。单个Agent生成答案时,它的推理路径往往是基于自身知识库和提示词的贪婪搜索,容易陷入局部最优。但当引入对立Agent后,它的反驳会打破这个贪婪路径,迫使原Agent探索其他可能性分支。这就像下棋时,对手的每一步都在测试你策略的漏洞,倒逼你的走法更加严密。从概率角度看,单一Agent输出的答案实际上是在其参数空间内的一次采样,存在很高的方差。通过多Agent辩论,相当于进行多次采样并通过对抗机制进行方差削减,最终收敛到更稳定的高质量区域。
实现Debate模式有几个关键设计点特别容易被低估。辩论者的角色设定直接决定辩论质量。很多人以为只要设置正反两方就行,其实角色的差异化程度是核心。比如在代码审查场景,如果两个Agent都是从功能正确性角度评审,辩论很快就会陷入无效重复。更好的设计是让一个Agent关注性能优化,另一个关注安全风险,第三个关注可维护性,这样才能形成真正的多维度张力。
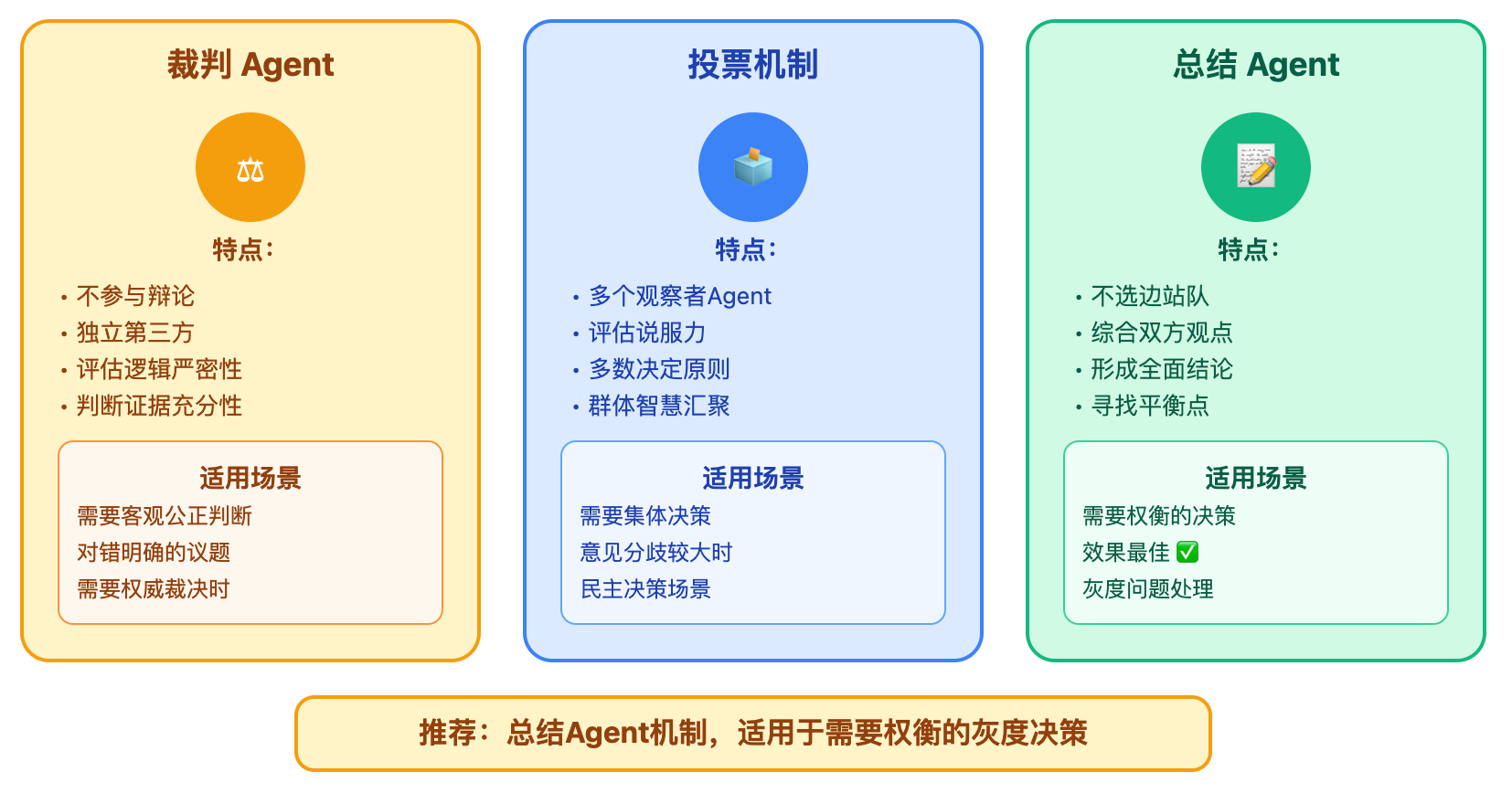
辩论结束后需要有收敛机制。常见的有三种方式:设置独立的裁判Agent,它不参与辩论,只根据双方论述的逻辑严密性、证据充分性来判断;通过投票机制,让多个观察者Agent评估哪方更有说服力;设置一个总结Agent,它的任务不是选边站,而是综合双方观点形成更全面的结论。在实际应用中,第三种方式往往效果最好,因为很多问题本身不是非黑即白,而是需要权衡的灰度决策。
辩论轮数也不是越多越好。从实验数据来看,大多数场景下3到5轮是性价比最高的。第一轮暴露主要分歧,第二轮深入论证,第三轮收敛共识。超过5轮后,边际收益会快速递减,Agent开始重复之前的论点,甚至出现为了辩论而辩论的情况。这时候成本在上升,但质量提升已经很有限了。
辩论模式跟反思模式看起来都有多轮交互,但本质不同。反思模式是单一Agent的自我批判,就像一个人写完文章后自己检查,容易受限于固有思维盲区。而Debate模式是不同Agent之间的对抗,引入了真正的外部视角。跟协作模式的区别更明显,协作模式中各Agent是分工合作关系,比如一个负责信息收集、一个负责分析、一个负责总结,大家目标一致。Debate模式中Agent之间是竞争关系,通过观点冲突来激发更深入的思考。可以说反思是自我迭代,协作是分工合作,辩论才是对抗性优化。
这里要特别澄清一个常见误解:很多人以为辩论模式就是让几个Agent各自给答案,然后投票选最多的那个。这完全曲解了辩论的价值。辩论的核心不在于最终选哪个答案,而在于论证的过程。
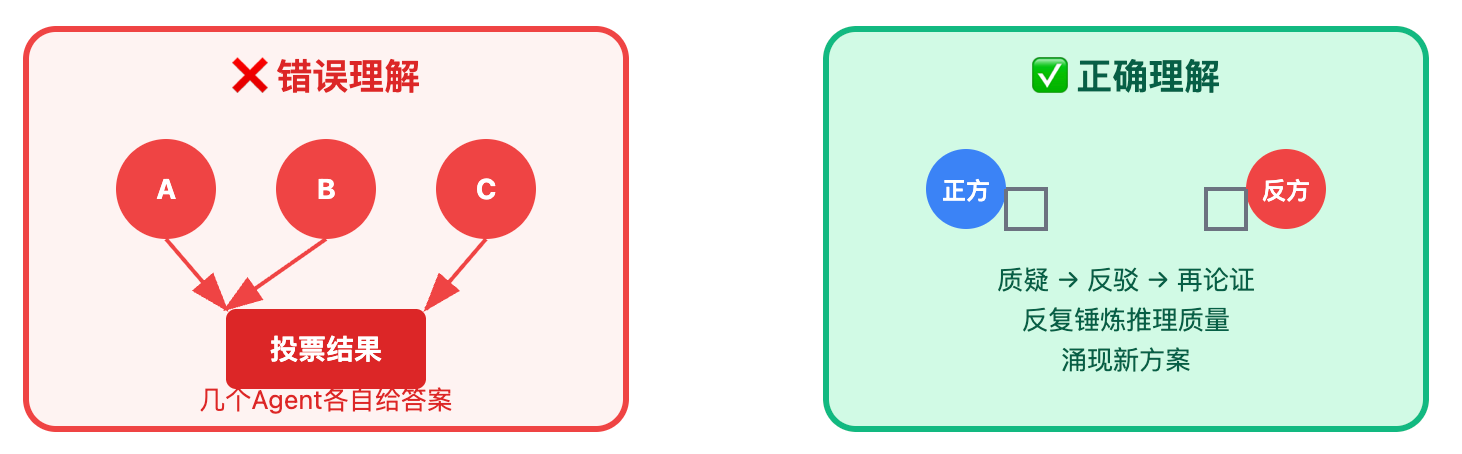
正是在一轮轮的质疑、反驳、再论证中,推理的质量得到提升。最终的答案很可能不是某一方的初始观点,而是经过多轮交锋后涌现出来的新方案。这就像我们开技术评审会,最终采纳的方案往往是讨论过程中逐步打磨出来的,而不是某个人会前准备的PPT。
实践落地:从场景选择到代码实现
辩论模式并不适合所有场景,理解什么时候该用这个模式是关键能力。辩论模式特别适合四类问题场景。第一类是事实验证类问题,比如判断某个技术方案是否可行,一个Agent从可行性角度论证,另一个从风险点角度质疑,能有效避免盲目乐观。第二类是复杂推理任务,像数学证明题或者逻辑推导,通过辩论可以发现推理链条中的跳步或者逻辑漏洞。第三类是主观评价场景,比如代码质量评审、产品方案打分,不同Agent从不同维度评估能减少单一视角的偏见。第四类是创意生成任务,多个Agent提出不同创意方向并互相挑战,往往能碰撞出更有突破性的想法。但不适合那种有明确标准答案或者纯计算类的问题,那样辩论就变成浪费算力了。
实现辩论模式有三个技术关键点。第一个是prompt设计,这决定了Agent的行为模式。辩论Agent的prompt跟普通Agent有个本质区别,除了角色定位,还要明确告诉它"你需要找到对方论述中的薄弱环节并提出质疑",同时要限制它不能简单重复自己的观点,必须针对对方最新的论述做出回应。如果prompt写得不好,Agent很容易陷入各说各话的状态。
第二个关键点是角色差异化设计。很多人会犯一个错误,就是让两个Agent分别代表支持和反对,但没有给它们明确的立场依据。更好的做法是给每个Agent赋予特定的关注点或者知识背景。拿技术选型来说,可以让一个Agent扮演注重开发效率的工程师角色,另一个扮演关注系统稳定性的SRE角色,第三个扮演考虑成本的技术管理者角色。这样每个Agent的立场是有现实依据的,不是为了反对而反对。
第三个是辩论轮次的动态控制。固定轮数的实现比较简单,但不够灵活。更实用的是设置收敛条件,比如当连续两轮辩论中双方的核心论点变化幅度小于某个阈值时,就认为已经充分交锋可以终止了。或者当裁判Agent判断某一方的论述已经明显占优时提前结束。这样既能保证充分辩论,又能避免不必要的成本消耗。
下面用Java实现一个简化的辩论框架。首先定义Agent的基础接口:
publicinterfaceDebateAgent{
/**
* 根据问题和历史辩论记录生成当前轮次的论述
* @paramquestion 待讨论的问题
* @paramdebateHistory 历史辩论记录
* @return 当前轮次的论述内容
*/
StringgenerateArgument(String question,List<DebateRecord> debateHistory);
/**
* 获取Agent的角色定位
*/
StringgetRoleName();
/**
* 获取Agent的关注维度
*/
StringgetFocusDimension();
}
publicclassDebateRecord{
privateString agentName;
privateString argument;
privateint round;
privatelong timestamp;
// 构造函数和getter/setter省略
}
接着实现具体的辩论Agent。每个Agent内部需要维护自己的角色prompt和立场,在生成论述时要同时考虑问题本身和对方的最新观点:
publicclassPerformanceAgentimplementsDebateAgent{
privatefinalLLMClient llmClient;
privatefinalString rolePrompt;
publicPerformanceAgent(LLMClient client){
this.llmClient = client;
this.rolePrompt ="""
你是一位关注系统性能的架构师,需要从以下角度论证观点:
- 系统响应时间和吞吐量
- 资源利用效率
- 可扩展性设计
在辩论中你需要:
1. 针对对方的论述找出性能相关的薄弱点
2. 提供具体的性能数据或案例支撑你的观点
3. 不要简单重复之前的论点,要基于对方的最新回应调整论述策略
""";
}
@Override
publicStringgenerateArgument(String question,List<DebateRecord> debateHistory){
StringBuilder promptBuilder =newStringBuilder(rolePrompt)
.append("\n\n待讨论问题:").append(question);
// 如果有历史记录,加入上下文
if(!debateHistory.isEmpty()){
promptBuilder.append("\n\n辩论历史:");
for(DebateRecordrecord: debateHistory){
promptBuilder.append("\n[第").append(record.getRound())
.append("轮-").append(record.getAgentName())
.append("]: ").append(record.getArgument());
}
// 特别强调需要回应的最新论点
DebateRecord lastRecord = debateHistory.get(debateHistory.size()-1);
if(!lastRecord.getAgentName().equals(getRoleName())){
promptBuilder.append("\n\n请重点回应上述")
.append(lastRecord.getAgentName())
.append("提出的观点,特别是与性能相关的部分。");
}
}
return llmClient.generate(promptBuilder.toString());
}
@Override
publicStringgetRoleName(){
return"性能架构师";
}
@Override
publicStringgetFocusDimension(){
return"系统性能与可扩展性";
}
}
publicclassSecurityAgentimplementsDebateAgent{
privatefinalLLMClient llmClient;
privatefinalString rolePrompt;
publicSecurityAgent(LLMClient client){
this.llmClient = client;
this.rolePrompt ="""
你是一位关注系统安全的工程师,需要从以下角度论证观点:
- 潜在的安全漏洞和攻击面
- 数据保护和隐私合规
- 权限控制和访问安全
在辩论中你需要:
1. 识别对方方案中可能存在的安全风险
2. 提出具体的安全加固建议
3. 基于对方的回应调整你的质疑角度,避免重复论述
""";
}
@Override
publicStringgenerateArgument(String question,List<DebateRecord> debateHistory){
StringBuilder promptBuilder =newStringBuilder(rolePrompt)
.append("\n\n待讨论问题:").append(question);
if(!debateHistory.isEmpty()){
promptBuilder.append("\n\n辩论历史:");
for(DebateRecordrecord: debateHistory){
promptBuilder.append("\n[第").append(record.getRound())
.append("轮-").append(record.getAgentName())
.append("]: ").append(record.getArgument());
}
DebateRecord lastRecord = debateHistory.get(debateHistory.size()-1);
if(!lastRecord.getAgentName().equals(getRoleName())){
promptBuilder.append("\n\n请从安全角度评估上述观点,指出可能的安全隐患。");
}
}
return llmClient.generate(promptBuilder.toString());
}
@Override
publicStringgetRoleName(){
return"安全工程师";
}
@Override
publicStringgetFocusDimension(){
return"系统安全与合规";
}
}
核心的辩论流程由协调器来管理,它负责轮流调度各个Agent并记录辩论历史:
publicclassDebateCoordinator{
privatefinalList<DebateAgent> agents;
privatefinalint maxRounds;
privatefinaldouble convergenceThreshold;
publicDebateCoordinator(List<DebateAgent> agents,int maxRounds){
this.agents = agents;
this.maxRounds = maxRounds;
this.convergenceThreshold =0.15;// 论点变化小于15%认为收敛
}
publicDebateResultrunDebate(String question){
List<DebateRecord> debateHistory =newArrayList<>();
for(int round =1; round <= maxRounds; round++){
System.out.println("=== 第 "+ round +" 轮辩论 ===");
// 所有Agent依次发表观点
for(DebateAgent agent : agents){
String argument = agent.generateArgument(question, debateHistory);
DebateRecordrecord=newDebateRecord(
agent.getRoleName(),
argument,
round,
System.currentTimeMillis()
);
debateHistory.add(record);
System.out.println(agent.getRoleName()+": "+ argument);
}
// 检查是否应该提前终止
if(round >=2&&shouldTerminateEarly(debateHistory, round)){
System.out.println("检测到辩论已收敛,提前终止");
break;
}
}
// 生成最终结论
returngenerateFinalResult(question, debateHistory);
}
privatebooleanshouldTerminateEarly(List<DebateRecord> history,int currentRound){
// 比较最近两轮中各Agent的论点相似度
Map<String,String> lastRound =newHashMap<>();
Map<String,String> currentRoundArgs =newHashMap<>();
for(DebateRecordrecord: history){
if(record.getRound()== currentRound){
currentRoundArgs.put(record.getAgentName(),record.getArgument());
}elseif(record.getRound()== currentRound -1){
lastRound.put(record.getAgentName(),record.getArgument());
}
}
// 简化的相似度计算,实际应该用更精确的语义相似度
for(String agentName : currentRoundArgs.keySet()){
if(lastRound.containsKey(agentName)){
double similarity =calculateSimilarity(
lastRound.get(agentName),
currentRoundArgs.get(agentName)
);
if(similarity <1- convergenceThreshold){
returnfalse;// 还有Agent的观点在明显变化
}
}
}
returntrue;// 所有Agent的观点都趋于稳定
}
privatedoublecalculateSimilarity(String text1,String text2){
// 这里使用简化的相似度计算
// 实际应该使用embedding向量的余弦相似度
Set<String> words1 =newHashSet<>(Arrays.asList(text1.split("\\s+")));
Set<String> words2 =newHashSet<>(Arrays.asList(text2.split("\\s+")));
Set<String> intersection =newHashSet<>(words1);
intersection.retainAll(words2);
Set<String> union =newHashSet<>(words1);
union.addAll(words2);
return union.isEmpty()?0:(double) intersection.size()/ union.size();
}
privateDebateResultgenerateFinalResult(String question,List<DebateRecord> history){
// 使用总结Agent生成综合结论
SummaryAgent summaryAgent =newSummaryAgent();
String finalConclusion = summaryAgent.summarize(question, history);
returnnewDebateResult(question, history, finalConclusion);
}
}
publicclassSummaryAgent{
privatefinalLLMClient llmClient;
publicSummaryAgent(){
this.llmClient =newLLMClient();
}
publicStringsummarize(String question,List<DebateRecord> debateHistory){
StringBuilder promptBuilder =newStringBuilder();
promptBuilder.append("""
你是一位中立的总结专家,需要基于多方辩论内容生成综合结论。
要求:
1. 客观整合各方的有效论点,不偏袒任何一方
2. 指出各方观点的合理之处和局限性
3. 给出权衡后的综合建议
4. 明确指出哪些风险需要特别关注
""");
promptBuilder.append("问题:").append(question).append("\n\n");
promptBuilder.append("辩论记录:\n");
for(DebateRecordrecord: debateHistory){
promptBuilder.append("[第").append(record.getRound())
.append("轮-").append(record.getAgentName())
.append("]\n").append(record.getArgument())
.append("\n\n");
}
promptBuilder.append("请基于以上辩论内容,给出综合结论:");
return llmClient.generate(promptBuilder.toString());
}
}
关于辩论轮次的选择,建议先跑一个小规模测试集,观察质量提升曲线。通常第一轮到第二轮的质量提升最明显,第三轮还有比较可观的增益,第四轮之后就要看具体任务了。如果发现第四轮的输出已经开始重复第二轮的论点,那就说明3轮是这个任务的最优配置。
裁判Agent的prompt设计特别关键,要明确告诉它评判标准是什么。是看逻辑严密性、证据充分性,还是看实用性、可行性,这些都要在prompt中明确。见过一些失败案例,裁判Agent只是简单地选择"更长的论述"或者"看起来更复杂的论证",这样就失去了辩论的意义。更好的做法是让裁判分维度打分,比如逻辑性、完整性、可操作性各占多少权重,然后综合评判。
辩论模式的成本确实比单Agent高,每轮辩论至少要调用两次LLM。所以要控制好使用场景,对于那些高价值、高复杂度的决策问题值得用辩论模式,但普通的信息查询类问题就没必要了。另外可以通过缓存机制优化,如果发现某个问题的辩论模式已经稳定收敛,后续类似问题可以直接复用结论,不需要每次都重新辩论。
延伸思考:局限性与组合创新
辩论模式确实不是银弹,它有几个明显的局限性值得注意。最直接的问题是成本,每轮辩论至少要调用两到三个Agent,如果再加上裁判Agent,token消耗是单Agent的好几倍。所以它只适合那些高价值的决策场景,不能滥用。更隐蔽的问题是辩论可能陷入僵局。如果两个Agent的立场过于极端且都很固执,会出现无休止的争论而无法收敛。这就需要在设计时加入明确的终止条件和裁判机制,不能让辩论无限制进行下去。还有个问题是辩论质量高度依赖Agent的角色设定。如果角色设置不合理,比如两个Agent关注点重叠或者立场差异不够明显,辩论就会流于形式,反而浪费资源。
辩论模式和RAG其实是很好的互补关系。RAG能提供外部知识支撑,让辩论基于事实而不是空谈。具体来说,可以让每个辩论Agent在论证时先通过RAG检索相关证据,然后基于这些证据构建论点。比如在技术选型辩论中,一个Agent主张用Redis做缓存,它可以通过RAG检索Redis的性能基准测试数据、成功案例来支撑观点。另一个Agent主张用Memcached,同样可以检索相关资料进行反驳。这样辩论就不是凭空臆测,而是有数据支撑的理性对话。实现上需要注意控制检索的范围和质量,不能让Agent检索到互相矛盾的信息源导致辩论陷入混乱,可能需要预先设定可信的知识库边界。
最近有些前沿研究方向挺有意思,比如MIT有个工作是让多个Agent在辩论过程中动态调整自己的立场强度,不是一直坚持初始观点,而是根据对方论据的说服力适度妥协,这样更接近人类的理性辩论。OpenAI在一些复杂的内容审核任务中用了类似的辩论机制,让不同Agent从安全性、准确性、用户体验角度评估内容,避免单一视角导致的误判。这些实践都在验证辩论模式的价值,同时也在探索更精细化的实现方式。
虽然实际项目经验可能有限,但可以基于场景假设思考改进方向。拿智能客服系统来说,现在通常是单Agent直接给答案,容易出现回复不够全面的问题。如果引入辩论模式,可以设置一个关注用户满意度的Agent和一个关注合规风险的Agent,前者会给出更灵活友好的回答,后者会检查这些回答是否符合公司政策。经过辩论后的最终回复既贴心又合规,质量会比单一视角好很多。这种基于场景的假设性分析,能展现对技术应用的深度思考。