精炼回答
在有限的上下文里塞更多信息,核心是提高信息密度和减少冗余表达。最直接的方法是使用结构化格式,比如JSON、表格、键值对来替代自然语言描述。举个例子,与其说"用户张三年龄25岁住在北京",不如直接写{name:"张三",age:25,city:"北京"},token消耗能减少30-40%。
符号化和缩写也很有效。常见术语可以约定缩写,比如"用户"写成"U","订单"写成"O",前提是在prompt开头建立映射表。代码场景里,用单字母变量名配合注释说明,比完整命名省空间。模板化处理能大幅压缩重复内容,如果要处理多条相似数据,只给一个完整示例,其他的省略字段名直接给值,让模型通过上下文推断结构。
分层摘要适合长文本。先提取关键实体和关系,构建知识图谱式的精简表示,必要时再补充细节。比如分析合同时,先列出甲乙方、金额、期限这些核心要素,条款细节按需展开。还有个技巧是利用模型的先验知识,对于公开信息,只需要给关键词触发模型记忆,而不用完整描述。比如说"GPT-4的上下文限制",不需要解释什么是GPT-4。最后,移除冗余修饰词,把"非常重要的关键问题"简化成"核心问题",这种润色在技术场景里完全可以砍掉。
扩展分析
从问题本质到分层解决方案
上下文窗口的限制本质上来自Transformer架构的self-attention机制,它的计算复杂度是O(n²),序列长度翻倍计算量就涨四倍。更实际的瓶颈在显存占用,因为attention矩阵要存储所有token两两之间的关系,8k上下文可能就要吃掉几个G显存,这直接影响推理成本和并发能力。理解了限制来源,再谈压缩方案就有了脉络。
建议按成本从低到高的顺序展开,因为这符合工程实践的决策逻辑——先用简单方案试探,不够用再上复杂度。最开始是工程优化层面的token级操作,这块看似简单但细节能体现功底。最直接的是格式优化,把自然语言改成结构化表示。假设要给模型传一批商品信息,原本可能写"iPhone 14 Pro价格7999元库存23件",改成{'id':'ip14p','price':7999,'stock':23},配合开头的字段映射表,token消耗能降到原来的40%。
接着是提示词模板的精简技巧。很多同学写prompt喜欢加"请仔细分析""注意细节"这种强调词,实测这些修饰语对模型输出质量影响不到5%,但会白白消耗token。更高效的做法是用约束格式,比如"输出JSON,包含字段X/Y/Z",既省空间又让结果可解析。
往上走一层就是语义压缩,这里要能说清楚和前面的区别。刚才说的是不改变信息本身,只优化表达形式。但碰到真正的长文本,比如要分析一份几十页的产品需求文档,这时候需要的是语义级别的压缩。一个思路是用小模型先做一轮关键信息提取,把文档转成结构化的实体-关系图谱。拿需求文档举例,提取出核心功能点、依赖关系、优先级这些要素,原本2万token的文档可能压缩到2千token的图谱表示,再喂给主模型做深度分析。
更彻底的做法是检索增强,不把全文塞进上下文,而是先对文档做embedding切片索引,用户提问时检索最相关的3-5个片段拼进prompt。这种方式压缩比能到10:1甚至更高,因为只传递跟当前任务直接相关的信息。但要能接住后续追问,比如"embedding检索会不会丢失上下文连贯性",得准备好"确实存在这个风险,所以工程上会做重叠切片,每个chunk保留前后50token的重叠区域来保持语义连续性"这样的回应。
架构设计层面,重点是体现系统性思维。当单次推理的上下文确实不够用,就得从架构上重新设计。常见的有滑动窗口方案,保留最近N轮对话加上最开始的系统设定,中间的历史用摘要占位,这样能在固定窗口里维持长期记忆。拿对话系统举例,客服机器人跟用户聊了50轮,不可能把所有历史都带着,可以每10轮做一次摘要,保留用户核心诉求和已解决问题,这样上下文始终控制在4k以内。

选择压缩方案主要看三个维度:信息密度要求、容错空间、实时性约束。代码生成任务对上下文准确性要求极高,丢失一个函数定义可能导致生成代码完全跑不通,这种场景适合用格式优化+模板化这种无损压缩,牺牲点可读性但保证完整性。文档问答类任务容错空间大,用户问财报里某个数据,只要检索到包含那个数字的段落就行,其他章节完全可以丢弃,所以embedding检索的方案很合适。对话系统介于两者之间,既要保持多轮连贯性,又不能无限膨胀上下文,滑动窗口+摘要的组合拳比较平衡。
关于压缩比和信息保留率的数据,得有量级概念。工程优化类的方法压缩比一般在1.5-3倍,基本是无损的。语义摘要能到3-10倍,但信息保留率取决于摘要质量,一般能保留70-85%的关键信息。检索增强的压缩比可以很夸张,上百倍都有可能,但它不是传统意义的压缩,更像是按需加载,信息保留率完全看检索精度,这也是为什么embedding模型的选择很关键。
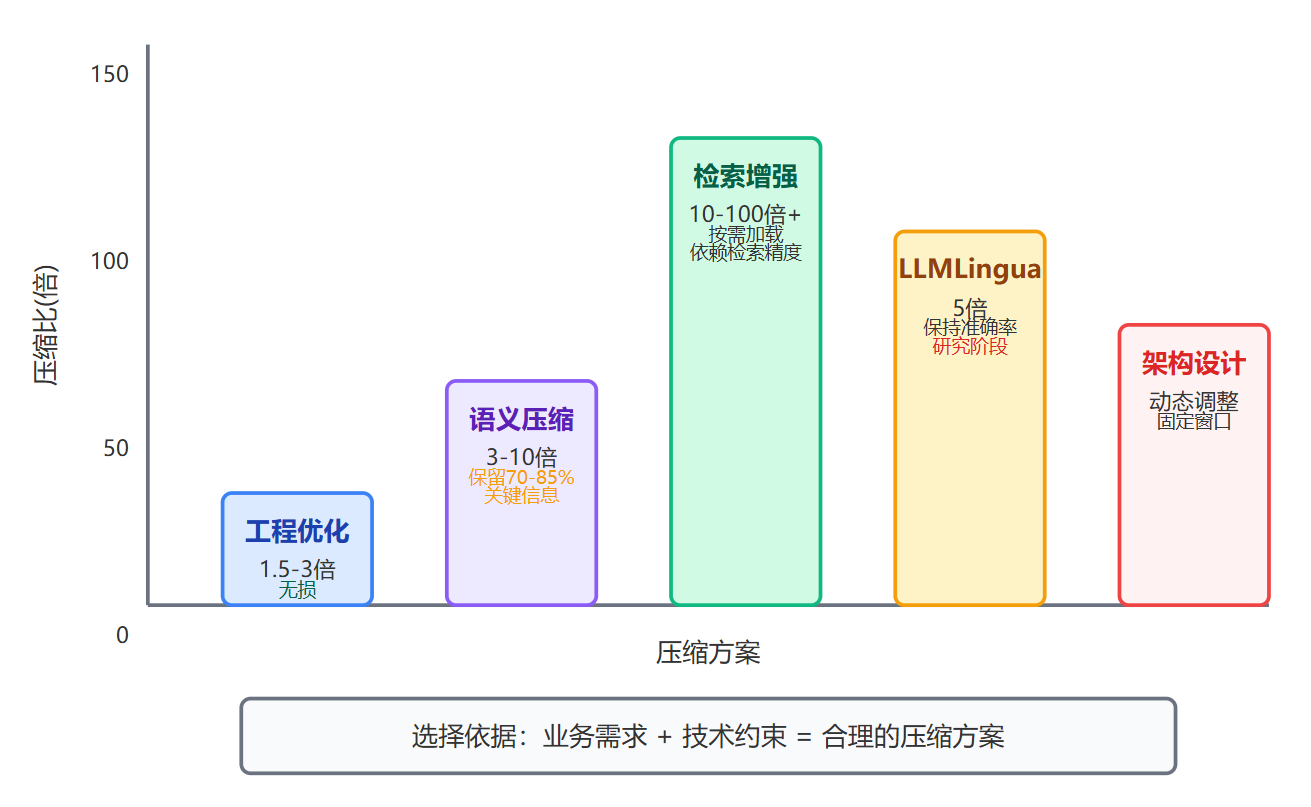
最近也有像LLMLingua这种专门做prompt压缩的研究,用小模型判断每个token的重要性然后删减,能在保持任务准确率的前提下压缩到原来的20%。不过这类方法还在研究阶段,工程化落地需要考虑额外的推理开销。
具体场景的实现方案
面试谈到这道题,如果面试官追问"能不能说个具体场景的实现方案",这就是你展示动手能力的机会了。前面讲了那么多方法论,现在得把它们落到代码和系统设计上,让面试官看到你不只是会讲概念,而是真能上手解决问题。
客服对话系统是最常见的追问场景,因为它同时涉及多轮上下文管理、信息压缩和实时响应。客服对话的特点是轮次多但每轮信息密度不均匀,前几轮往往在确认问题,核心诉求可能到第五六轮才清晰。如果无脑把所有历史都塞进上下文,不仅浪费token,还可能让模型被琐碎细节干扰。
工程上一般用滑动窗口加摘要的混合策略。保留最近3轮完整对话,确保上下文连贯性;把更早的历史做结构化提取,只保留用户身份、订单号、已确认的问题类型这些关键信息;最开始的系统设定和知识库索引始终在场。这样描述既体现了分层思维,又给出了可量化的参数。
如果面试官继续问"怎么做摘要提取",这时候可以展示代码思路。用一个轻量的信息提取prompt,专门负责把多轮对话压缩成结构化记录。核心逻辑是定义一个CompressContext方法,输入是历史对话列表,输出是精简后的上下文对象:
publicclassDialogueCompressor{
publicCompressedContextcompress(List<DialogueTurn> history,int windowSize){
CompressedContext context =newCompressedContext();
// 保留最近N轮完整对话
int recentStart =Math.max(0, history.size()- windowSize);
context.setRecentDialogues(history.subList(recentStart, history.size()));
// 压缩更早的历史
if(recentStart >0){
Map<String,Object> keyInfo =newHashMap<>();
for(int i =0; i < recentStart; i++){
DialogueTurn turn = history.get(i);
// 提取关键实体:用户ID、订单号、商品名等
extractEntities(turn, keyInfo);
}
context.setCompressedHistory(keyInfo);
}
return context;
}
privatevoidextractEntities(DialogueTurn turn,Map<String,Object> keyInfo){
// 使用正则或NER提取实体
Pattern orderPattern =Pattern.compile("订单号[::]?(\\w+)");
Matcher matcher = orderPattern.matcher(turn.getContent());
if(matcher.find()){
keyInfo.put("orderId", matcher.group(1));
}
// 提取商品名、问题类型等
// 重复出现的覆盖旧值保持最新状态
if(turn.getEntities().containsKey("product")){
keyInfo.put("product", turn.getEntities().get("product"));
}
}
}实际落地时发现,用规则提取实体容易漏掉隐含信息。比如用户说"刚才那个不要了",指代的商品需要结合上文才能确定。更稳健的做法是调一次小模型专门做摘要,比如用个7B的本地模型,给它一个固定模板:"总结以下对话的关键信息,输出JSON格式:用户诉求、涉及商品、当前状态"。这样摘要质量更高,额外开销也就几十毫秒,相比主模型推理可以忽略。
聊完对话场景,面试官可能会问RAG方案的具体实现,这是检索增强压缩的核心。回答时要能说清楚三个关键环节:怎么分块、怎么索引、怎么检索。
RAG的第一步是把长文本切成合适的chunk。面试时很多同学会说"按512 token切",但这样机械分割容易把一个完整段落拦腰斩断,破坏语义完整性。更好的做法是基于语义边界切分,比如按自然段或者章节标题分,每个chunk控制在300-500 token之间,然后做50-100 token的前后重叠,确保边界信息不丢失。
publicclassDocumentChunker{
publicList<Chunk>splitDocument(String document,int chunkSize,int overlap){
List<Chunk> chunks =newArrayList<>();
// 先按段落分割
String[] paragraphs = document.split("\n\n");
StringBuilder currentChunk =newStringBuilder();
int currentTokens =0;
String previousOverlap ="";
for(String para : paragraphs){
int paraTokens =estimateTokens(para);
if(currentTokens + paraTokens > chunkSize && currentTokens >0){
// 当前chunk已满,保存并开始新chunk
Chunk chunk =newChunk(previousOverlap + currentChunk.toString());
chunks.add(chunk);
// 提取overlap部分
previousOverlap =extractOverlap(currentChunk.toString(), overlap);
currentChunk =newStringBuilder();
currentTokens =0;
}
currentChunk.append(para).append("\n\n");
currentTokens += paraTokens;
}
// 处理最后一个chunk
if(currentTokens >0){
chunks.add(newChunk(previousOverlap + currentChunk.toString()));
}
return chunks;
}
privateStringextractOverlap(String text,int overlapTokens){
// 从文本末尾提取指定token数的重叠区域
String[] sentences = text.split("[。!?]");
StringBuilder overlap =newStringBuilder();
int tokens =0;
for(int i = sentences.length -1; i >=0&& tokens < overlapTokens; i--){
overlap.insert(0, sentences[i]);
tokens +=estimateTokens(sentences[i]);
}
return overlap.toString();
}
privateintestimateTokens(String text){
// 粗略估计:中文按字数,英文按空格分词
return text.replaceAll("[^\\u4e00-\\u9fa5a-zA-Z]","").length();
}
}接着讲索引构建。切完chunk之后要生成embedding向量,这步选型很关键。如果文档是通用领域内容,直接用OpenAI的text-embedding-ada-002就够用,768维向量,召回精度能到85%以上。但如果是垂直领域,比如法律文书或者医疗病历,最好用领域数据微调过的embedding模型,召回率能提升10-15个百分点。索引结构上,文档量小于10万可以用Faiss的flat索引暴力检索,延迟在10ms以内;量级到百万以上就得上IVF或者HNSW这种近似检索,牺牲一点点精度换取百倍速度提升。
检索环节的细节最容易出彩。用户提问时,先把问题向量化,然后在索引里检索Top-K相关chunk,这个K的选择很有讲究。K设太小可能漏掉关键信息,设太大又会引入噪声稀释上下文。工程上一般先检索Top-10,然后做二次排序:用cross-encoder模型对问题和每个候选chunk算精确相关度分数,最后取Top-3到Top-5拼到prompt里。这个rerank步骤虽然多一次模型调用,但能把准确率从70%提到90%,特别是复杂问答场景非常值得。当然rerank会增加延迟,如果业务对实时性要求极高,可以只在首次检索做精排,后续轮次用缓存。

如果面试官对LLMLingua这类工具感兴趣,可以简单聊聊实战感受。LLMLingua的思路是用小模型给prompt里的每个token打重要性分数,然后删掉低分token。试过用它压缩RAG检索回来的文档片段,压缩比确实能到5:1,而且任务准确率只掉2-3个点。但问题是压缩过程本身要调一次GPT-2规模的模型,处理1k token大概要200ms,如果检索回来5个chunk就是1秒额外开销。对于离线分析场景可以接受,但在线客服这种实时交互就不太合适,还不如直接优化检索精度,从源头减少冗余chunk。

最后说说踩过的三个典型坑。第一个坑是过度压缩导致指代不清。比如把"用户在上午咨询了商品A,下午又问B的库存"压缩成"咨询A和B",时序信息丢了,模型可能理解偏。避免方法是保留时间标记或者序号,哪怕只是"①咨询A ②咨询B"这种简单标注。第二个坑是分块时破坏了跨段落的逻辑链。文档里经常有"如前所述""综上所述"这种指代,单独的chunk看不懂。工程上除了重叠切分,还可以在每个chunk前面加一句话的上文摘要,给模型提供最小上下文。第三个坑是检索召回的chunk质量参差不齐,有的高度相关,有的只是关键词碰巧匹配。如果直接拼接,噪声chunk会干扰模型判断。解决办法是做相关度过滤,设个阈值,低于0.7分的chunk直接丢弃,宁可少给信息也不引入误导。
压缩方案没有万能配置,得根据具体场景做AB测试。习惯是先用最简单的方案跑baseline,比如直接truncate超长上下文,看看掉多少点准确率。然后逐步加入结构化、摘要、检索这些优化,每次只改一个变量,量化收益。这样既能快速验证想法,也避免过度设计。
高频问题
压缩质量怎么评估? 评估压缩质量得看两条线,一条是客观指标,拿标注好的测试集跑,对比压缩前后模型输出的F1分数或者ROUGE值,量化信息损失。另一条是业务指标,压缩是为了解决实际问题的,最终要看对用户体验的影响。举个具体场景,文档问答系统用了RAG压缩后,客观上召回率可能从92%掉到88%,但实际业务场景里用户满意度没变,因为那4个点的损失主要在边缘case上,核心场景完全覆盖。

信息损失怎么办? 信息损失不可避免,关键是识别哪些信息可以丢。压缩前要先做信息分级,把上下文里的内容分成核心要素、辅助信息和冗余噪声三类。核心要素必须保留,像用户ID、订单状态这种关键实体;辅助信息可以有损压缩,比如时间戳精确到天就够了,不需要精确到毫秒;冗余噪声直接删除,像重复出现的客套话。实际落地时会先跑一轮信息熵分析,统计每个字段对最终输出的影响权重,权重低于阈值的内容都是压缩候选。这样压缩策略就有数据依据,而不是拍脑袋决定。

还有个高频问题是压缩的计算开销值得吗? 这直接考察成本意识。压缩方案的ROI得看两个维度。一个是token成本,假设调用GPT-4,1k token输入成本是0.03美元,如果压缩能把平均输入从5k降到2k,单次请求省0.09美元,业务量大的场景一个月能省几万刀。另一个是延迟收益,输入减少60%,推理时间能降30-40%,这对实时交互的场景是硬指标。但如果压缩本身要调额外的小模型,开销可能抵消收益。比如用LLMLingua压缩,处理1k token要200ms,而直接喂给主模型可能也就多100ms延迟,这种情况下压缩就不划算,反而增加了系统复杂度。
