精炼回答
Multi-Agent系统的一致性问题核心在于多个自主Agent需要对系统状态达成统一认知。解决这个问题主要依赖分布式共识算法,其中最经典的是Paxos和Raft。
在实际应用中,Raft因其易理解性更受欢迎。它通过Leader选举机制确保同一时刻只有一个Leader负责接收请求和日志复制,当Leader向Follower发送日志条目时,必须得到多数节点确认才能提交,这保证了即使部分节点故障,系统仍能就某个决策达成一致。比如在分布式机器人协作场景中,多个机器人Agent需要协商任务分配,就可以用Raft确保所有Agent对任务分配方案有一致的认知。
另一种是拜占庭容错算法(如PBFT),它能处理恶意节点的情况。在区块链多Agent系统中特别重要,因为要防范部分Agent故意发送错误信息。PBFT通过三阶段协议(pre-prepare、prepare、commit)和超过2/3节点的投票机制来达成共识。
实践中还会用到最终一致性策略,像Gossip协议,Agent之间随机交换状态信息,虽然不保证强一致性,但在大规模Agent集群(如分布式传感器网络)中能以较低成本实现状态收敛。选择哪种算法取决于你的容错需求、性能要求和网络规模。
扩展分析
从问题本质到算法选择的完整思路
面试时遇到这个问题,你需要在开口的前30秒就让面试官感觉到"这个候选人思路清晰"。千万别上来就陷入某个具体算法的细节,那样容易让面试官觉得你只是背了些概念。正确的打开方式是先搭好框架,展现你对问题的整体把握。
你可以这样组织开场:"Multi-Agent系统的一致性问题,本质上是要让多个独立决策的Agent在分布式环境下对同一件事达成共同认知。解决这个问题有两条主线,一是选择合适的共识算法,二是根据业务特性在强一致性和最终一致性之间做权衡。"说完这句话,面试官基本就知道你理解问题的核心了。
Multi-Agent系统和传统分布式系统的关键差异值得在面试中主动指出。传统分布式系统里的节点更像是忠实执行命令的士兵,而Multi-Agent系统中的Agent更像是有自己判断能力的将领。比如自动驾驶车队中,每辆车都是一个Agent,它们要协商变道决策时,不仅要同步状态信息,还要各自基于本地传感器数据做判断。这种自主性意味着一致性问题更复杂,因为你不仅要同步数据,还要协调决策过程。
讲到这里,面试官如果点头,说明你已经建立了良好的第一印象。接下来可以自然过渡到一致性和共识的区别。很多人会把这两个词混用,但在面试中把它们区分开会显得你概念清晰。一致性是我们的目标,就是让所有Agent对某个状态或决策达成相同认知;而共识是达成这个目标的过程,是一套规则和协议。举个容易理解的例子,几个朋友决定去哪吃饭,最后大家都同意去某家餐厅,这是一致性;而大家通过举手表决、少数服从多数这个过程,就是共识机制。
CAP理论的工程权衡在这里就显得尤为重要了。在Multi-Agent系统中,我们经常面临CAP三角的权衡。一致性、可用性、分区容错性不可能同时完美达成,所以实际场景里我们要根据业务特性做选择。假设在无人机集群协同任务中,如果网络分区导致部分无人机失联,我们是选择让整个集群停止工作等待网络恢复确保一致性,还是允许分区后的子集群继续各自执行任务保证可用性?这不是技术问题,是业务问题。如果是搜救任务,可用性更重要,宁可有些重复搜索也不能停摆;如果是精密编队飞行表演,一致性更关键,不一致可能导致碰撞。
面试中能讲出这种业务驱动技术选择的思路,比单纯背算法强太多。你展现的是工程思维,而不是理论知识的堆砌。现在可以进入共识算法的部分了,但记住,面试官不需要你把论文复述一遍,他想知道的是你理解了算法的核心巧妙之处。
Raft的设计哲学就是可理解性,它把共识问题拆成了三个子问题:Leader选举、日志复制、安全性保证。重点讲Leader选举的巧妙之处:通过引入任期号(term)这个概念,Raft保证了在同一个任期内只会有一个Leader被选出来。每个节点给自己投票前会先增加任期号,而其他节点收到投票请求时会检查任期号,只给任期号更大的候选者投票。这个简单机制就避免了脑裂问题。
如果面试官追问日志复制的细节,你可以说:Leader会把客户端请求包装成日志条目,按顺序发给Follower。关键点在于它要求多数派确认,这个多数派机制保证了即使Leader挂了,新选出的Leader一定拥有所有已提交的日志。这里可以画个图会更清晰:
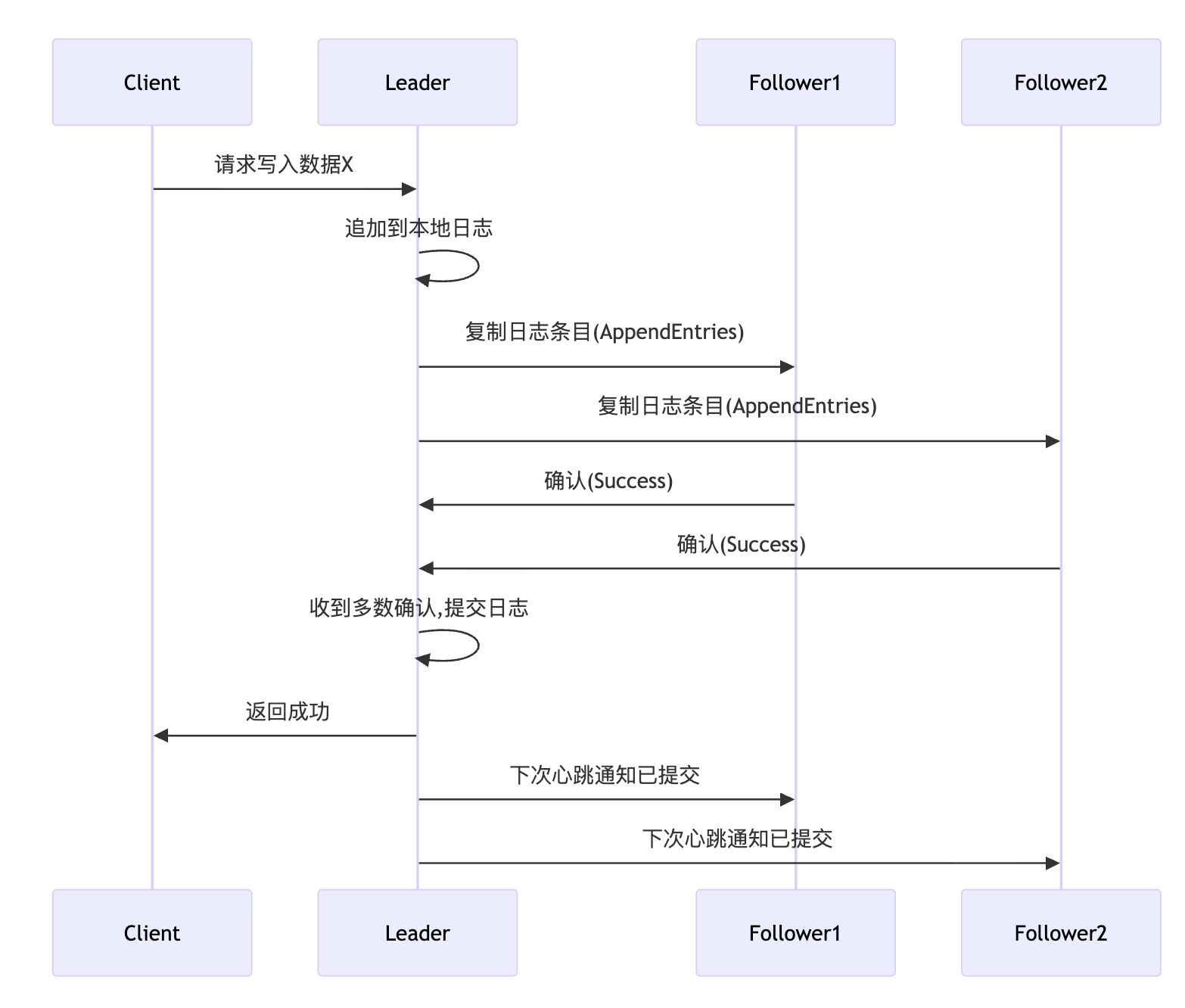
关于Paxos,校招面试其实不需要深入到三阶段的每个细节。你可以说:Paxos更加通用但也更复杂,它通过两个阶段来达成共识。第一阶段是Prepare阶段,提案者询问接受者是否愿意接受一个编号的提案;第二阶段是Accept阶段,如果得到多数派响应,就发送实际的提案值。核心思想是用提案编号来建立全局顺序,避免冲突。如果面试官没有继续追问,说明这个深度够了。
PBFT要单独强调它解决的问题不同。前面说的Raft和Paxos都是CFT算法,只能容忍节点崩溃故障。但如果系统中可能存在恶意节点,比如区块链网络里的矿工可能作恶,就需要BFT算法。PBFT引入了三阶段投票机制,pre-prepare、prepare、commit三个阶段层层确认,要求超过2/3的节点同意才能提交。为什么是2/3?因为要容忍f个拜占庭节点,你至少需要3f+1个总节点数,这样即使f个节点作恶、f个节点崩溃,剩下的f+1个诚实节点仍然能形成多数。
讲完算法原理,可以过渡到实际应用的权衡。面试官特别喜欢听候选人讲什么场景用什么方案,因为这体现了你的工程判断力。一致性强度的选择本质上是在正确性和性能之间找平衡。强一致性场景容易理解,比如银行转账系统,多个处理Agent必须对账户余额有完全一致的认知,否则就会出现超卖或者余额不对的问题。这种场景下,通常会选择Raft或Paxos,牺牲一些性能来保证正确性。
但最终一致性的场景可能更有意思。电商大促时,库存扣减的请求量非常大,如果每次扣减都要走强一致性协议,性能会成为瓶颈。实际上很多系统会采用最终一致性策略,比如先在本地扣减库存,然后异步同步到其他节点。即使短时间内不同节点看到的库存数不一样,但只要保证最终收敛到正确值,用户体验影响不大。这里可以补充一个细节:当然会有超卖风险,所以通常会预留buffer,或者在支付环节做二次校验兜底。
因果一致性是个容易被忽略但能加分的点。有些场景不需要强一致,但需要保证因果关系。比如社交网络中,用户发了一条帖子然后又发了一条评论,其他用户看到评论时必须能看到原帖,否则就逻辑混乱了。这种场景下,向量时钟(Vector Clock)可以用来追踪因果依赖,成本比强一致性低很多。
最后可以总结一下选择算法时的关键考量因素。首先是容错类型,如果只需要防崩溃故障,CFT算法就够了,性能更好;如果要防恶意节点,必须用BFT算法,但性能开销会大一个数量级。然后是性能要求:Raft在正常情况下只需要一轮RPC就能完成复制,延迟较低;Paxos理论上可以并发处理多个提案,吞吐量更高;PBFT因为要三阶段确认,延迟会明显增加。所以对延迟敏感的实时系统可能倾向于Raft,对吞吐量要求高的可以考虑Paxos变种。
网络特性也很重要。如果Agent之间的网络是相对稳定的局域网,比如数据中心内的分布式数据库,强一致性协议的开销是可接受的。但如果是广域网环境,比如跨大洲的CDN节点协同,网络延迟和分区概率都很高,这时候最终一致性配合Gossip协议可能是更现实的选择。Multi-Agent系统还有个特点是Agent可能动态加入或离开,这对共识算法提出了额外要求。Raft有成员变更协议处理这个问题,通过Joint Consensus确保变更过程的安全性。如果你的系统Agent频繁变动,需要确认选择的算法支持动态成员管理。
实践应用中的设计与实现
前面讲了这么多理论,面试官如果对你的回答满意,很可能会追问一句:"那你能举个具体的应用例子吗?"或者"如果让你设计一个这样的系统,你会怎么做?"这时候就需要展现你的实战思维了。关键不是背出某个开源项目的架构,而是让面试官看到你能把理论知识转化成可落地的方案。
要回答这个问题,我会先看三个关键特征:Agent之间的信任关系、网络环境特点、还有对一致性强度的要求。这个开场会让面试官觉得你有方法论,而不是碰运气选方案。拿分布式机器人协调场景来说,假设有一组仓储机器人需要协同搬运货物,它们要对任务分配达成一致。这个场景有几个特点:机器人都是同一个系统控制的,不存在恶意节点,所以不需要拜占庭容错;但机器人可能因为电量耗尽或者硬件故障崩溃,需要处理节点故障;另外仓储环境网络相对稳定。基于这些特征,Raft是个合适的选择。
Raft在Agent集群中应用的关键实现点可以用一些代码框架来说明。首先是心跳机制,Leader需要定期向所有Follower发送心跳,一旦Follower超时没收到心跳,就会发起新的选举:
publicclassRaftAgent{
privatevolatileRaftRole role =RaftRole.FOLLOWER;
privatevolatileint currentTerm =0;
privatevolatileString votedFor =null;
privatevolatileString leaderId =null;
privatelong lastHeartbeatTime;
privateList<RaftAgent> peers =newArrayList<>();
privateList<LogEntry> log =newArrayList<>();
privateint commitIndex =0;
privateint lastApplied =0;
// 心跳超时检测
privatevoidcheckHeartbeatTimeout(){
long elapsed =System.currentTimeMillis()- lastHeartbeatTime;
// 添加随机化避免多个节点同时发起选举
int electionTimeout =150+newRandom().nextInt(150);// 150-300ms
if(elapsed > electionTimeout && role ==RaftRole.FOLLOWER){
startElection();
}
}
privatevoidstartElection(){
currentTerm++;
role =RaftRole.CANDIDATE;
votedFor =this.nodeId;
int votesReceived =1;
// 向所有其他节点请求投票
for(RaftAgent peer : peers){
VoteResponse response = peer.requestVote(
currentTerm,
nodeId,
log.size()-1,// lastLogIndex
log.isEmpty()?0: log.get(log.size()-1).term // lastLogTerm
);
if(response.isGranted()){
votesReceived++;
}
}
// 获得多数票则成为Leader
if(votesReceived >(peers.size()+1)/2){
becomeLeader();
}
}
publicVoteResponserequestVote(int term,String candidateId,
int lastLogIndex,int lastLogTerm){
// 如果候选人的任期小于当前任期,拒绝投票
if(term < currentTerm){
returnnewVoteResponse(currentTerm,false);
}
// 如果候选人的任期更大,更新自己的任期
if(term > currentTerm){
currentTerm = term;
votedFor =null;
role =RaftRole.FOLLOWER;
}
// 检查日志是否至少和自己一样新
int myLastLogIndex = log.size()-1;
int myLastLogTerm = log.isEmpty()?0: log.get(myLastLogIndex).term;
boolean logIsUpToDate =(lastLogTerm > myLastLogTerm)||
(lastLogTerm == myLastLogTerm &&
lastLogIndex >= myLastLogIndex);
// 如果还没投票且候选人日志足够新,投票给他
if((votedFor ==null|| votedFor.equals(candidateId))&& logIsUpToDate){
votedFor = candidateId;
lastHeartbeatTime =System.currentTimeMillis();
returnnewVoteResponse(currentTerm,true);
}
returnnewVoteResponse(currentTerm,false);
}
privatevoidbecomeLeader(){
role =RaftRole.LEADER;
leaderId =this.nodeId;
// 开始定期发送心跳
startHeartbeat();
}
}
classLogEntry{
int term;
String command;
publicLogEntry(int term,String command){
this.term = term;
this.command = command;
}
}
enumRaftRole{
FOLLOWER, CANDIDATE, LEADER
}
classVoteResponse{
int term;
boolean granted;
publicVoteResponse(int term,boolean granted){
this.term = term;
this.granted = granted;
}
publicbooleanisGranted(){
return granted;
}
}面试时不需要写出完整实现,这种伪代码框架就足够说明你理解了机制。选举过程中有个细节很重要,就是要引入随机化的选举超时时间,避免多个节点同时发起选举导致分票。
日志复制的实现要点在于确保日志的顺序性。Leader会给每个日志条目分配一个递增的索引,Follower在接收时会检查前一条日志的索引和任期是否匹配,不匹配就拒绝,这样保证了日志的连续性:
publicclassRaftAgent{
// ... 前面的代码 ...
// Leader处理客户端写请求
publicbooleanhandleClientRequest(String command){
if(role !=RaftRole.LEADER){
returnfalse;
}
// 追加到本地日志
LogEntry entry =newLogEntry(currentTerm, command);
log.add(entry);
// 复制到所有Follower
int successCount =1;// 自己算一个
for(RaftAgent peer : peers){
AppendEntriesResponse response = peer.appendEntries(
currentTerm,
nodeId,
log.size()-2,// prevLogIndex
log.size()>=2? log.get(log.size()-2).term :0,// prevLogTerm
Collections.singletonList(entry),
commitIndex
);
if(response.isSuccess()){
successCount++;
}
}
// 如果多数节点确认,提交日志
if(successCount >(peers.size()+1)/2){
commitIndex = log.size()-1;
applyToStateMachine(entry);
returntrue;
}
returnfalse;
}
publicAppendEntriesResponseappendEntries(int term,String leaderId,
int prevLogIndex,int prevLogTerm,
List<LogEntry> entries,int leaderCommit){
// 更新心跳时间
lastHeartbeatTime =System.currentTimeMillis();
// 任期检查
if(term < currentTerm){
returnnewAppendEntriesResponse(currentTerm,false);
}
if(term > currentTerm){
currentTerm = term;
votedFor =null;
}
role =RaftRole.FOLLOWER;
this.leaderId = leaderId;
// 日志一致性检查
if(prevLogIndex >=0){
if(prevLogIndex >= log.size()||
log.get(prevLogIndex).term != prevLogTerm){
returnnewAppendEntriesResponse(currentTerm,false);
}
}
// 追加新日志条目
if(entries !=null&&!entries.isEmpty()){
int index = prevLogIndex +1;
for(LogEntry entry : entries){
if(index < log.size()){
// 如果存在冲突,删除这个索引之后的所有日志
if(log.get(index).term != entry.term){
log =newArrayList<>(log.subList(0, index));
log.add(entry);
}
}else{
log.add(entry);
}
index++;
}
}
// 更新commitIndex
if(leaderCommit > commitIndex){
commitIndex =Math.min(leaderCommit, log.size()-1);
// 应用已提交的日志到状态机
while(lastApplied < commitIndex){
lastApplied++;
applyToStateMachine(log.get(lastApplied));
}
}
returnnewAppendEntriesResponse(currentTerm,true);
}
privatevoidapplyToStateMachine(LogEntry entry){
// 将日志条目应用到状态机
System.out.println("Applying command: "+ entry.command);
}
}
classAppendEntriesResponse{
int term;
boolean success;
publicAppendEntriesResponse(int term,boolean success){
this.term = term;
this.success = success;
}
publicbooleanisSuccess(){
return success;
}
}网络分区的处理方式是面试官经常追问的点。Raft的处理方式很优雅,如果发生分区,旧Leader在少数派分区里会因为无法获得多数确认而无法提交新日志,这时它实际上已经失去了Leader的能力;而多数派分区里会选出新Leader继续工作。当分区恢复后,旧Leader发现新Leader的任期号更大,会自动退化成Follower,并用新Leader的日志覆盖自己未提交的日志。
很多同学会担心脑裂,就是同时出现两个Leader的情况。Raft通过任期号机制从根本上避免了这个问题,因为在同一个任期内,每个节点最多只能投一票,这保证了不可能同时选出两个Leader。即使由于网络延迟导致旧Leader还没发现自己被替换,它发出的请求也会因为任期号过时被拒绝。
性能优化在实际应用中不可忽视。纯粹按照Raft论文实现可能性能不够理想,批量处理是最直接的优化:Leader可以把多个客户端请求打包成一批再复制,减少网络往返次数。比如在高并发场景下,每10毫秒或者积累100个请求后统一复制一次,这能显著提升吞吐量。
预投票机制是个容易被忽略但很实用的优化。标准Raft里,节点心跳超时后会直接增加任期号发起选举。但如果这个节点只是网络抖动暂时失联,它发起的选举会打断当前正常工作的Leader。预投票机制要求节点在正式选举前先问一轮"如果我发起选举,你们会投给我吗",只有得到多数同意才真正增加任期号。这避免了无意义的选举干扰:
// 预投票阶段
privatebooleanpreVote(){
int preVoteCount =1;
int nextTerm = currentTerm +1;
for(RaftAgent peer : peers){
PreVoteResponse resp = peer.requestPreVote(
nextTerm,
nodeId,
log.size()-1,
log.isEmpty()?0: log.get(log.size()-1).term
);
if(resp.isGranted()){
preVoteCount++;
}
}
return preVoteCount >(peers.size()+1)/2;
}
// 只有预投票通过才发起真正的选举
privatevoidcheckAndStartElection(){
if(preVote()){
startElection();
}else{
// 预投票失败,重置超时等待下次尝试
lastHeartbeatTime =System.currentTimeMillis();
}
}
classPreVoteResponse{
int term;
boolean granted;
publicPreVoteResponse(int term,boolean granted){
this.term = term;
this.granted = granted;
}
publicbooleanisGranted(){
return granted;
}
}活锁是另一个实践中要注意的陷阱。如果多个节点几乎同时发起选举,可能会反复分票,谁也当不上Leader,系统就卡住了。解决办法是给每个节点设置随机的选举超时时间,比如150到300毫秒之间随机取值。这个随机性打破了同步性,让某个节点能率先发起选举并成功。
具体参数怎么设置要根据网络延迟来调整。比如数据中心内网络延迟一般在1毫秒级别,心跳间隔可以设置为50毫秒,选举超时设为150到300毫秒;但如果是跨大洲的广域网部署,延迟可能上百毫秒,就需要把这些参数相应放大到秒级,否则会频繁误判Leader故障。
扩展思考与前沿场景
当你回答完前面那些内容,面试官的表情会告诉你他在想什么。如果他微微点头,可能接下来会问一些更深入的问题来确认你的理解深度。理解面试官真正在考察什么,会让你的准备更有针对性。表面上看,他们在问共识算法怎么应用,但深层次其实在评估你对分布式系统的整体认知,你的工程思维,以及你的学习潜力。
追问往往围绕着算法复杂度和性能瓶颈展开。面试官可能会问:"你提到Raft需要多数派确认,那它的时间复杂度是多少?在大规模集群中会有什么问题?"Raft的每次共识需要Leader和多数Follower之间的一轮通信,时间复杂度是O(n),其中n是节点数。在几十个节点的集群里这不是问题,但如果扩展到上千个节点,Leader会成为瓶颈,因为它要给所有节点发送心跳和日志条目。这种情况下,实践中会采用分层架构,比如把集群划分成多个小的Raft组,上层再用另一套机制协调。
容错能力的追问也很常见。"你说PBFT能容忍拜占庭故障,那它最多能容忍多少恶意节点?为什么?"PBFT需要至少3f+1个节点才能容忍f个拜占庭节点。原因是这样的,假设有f个恶意节点在撒谎,你需要足够的诚实节点数量来"压倒"它们的声音。如果总共只有2f+1个节点,恶意节点可以伪装成诚实节点,让你无法区分哪些信息是可信的。但有了3f+1个节点,即使f个恶意节点和f个节点故障,剩下的f+1个诚实节点仍然比恶意节点多,能够形成可信的多数。
即使你没有实际的分布式系统项目经验,也完全可以从学校的课程设计、开源项目学习或者技术社区的讨论中提炼出有价值的素材。如果被问到"你有没有实际应用过这些算法",可以说:"我在学习分布式系统课程时,实现过一个简化版的Raft算法来加深理解。虽然只是模拟环境,但我通过这个过程理解了Leader选举中随机超时的重要性,因为我最初实现时没加随机化,结果多个节点总是同时发起选举导致活锁。"或者说:"我研究过etcd的源码,看到它在Raft基础上做了很多工程优化,比如批量处理、流水线复制这些,这让我意识到理论算法到生产系统之间还有很大的工程化距离。"
展现架构思维的关键是能够在不同场景下给出不同的选择,并且说清楚为什么。假设要设计一个智能家居系统,多个设备Agent需要协同工作,你会怎么选择共识算法?先分析场景特征:智能家居系统的Agent通常都在同一局域网内,网络延迟很低;设备之间没有利益冲突,不需要防恶意节点;但可能会有设备断电或故障的情况。基于这些特征,Raft是个合理选择。不过如果追求极致的响应速度,可能连Raft都嫌重,可以考虑最终一致性方案,因为家居设备之间短暂的状态不一致用户通常感知不到。
提到新兴技术会让面试官眼前一亮。联邦学习场景下的共识需求很有意思,多个参与方在本地训练模型后需要聚合参数,但彼此之间可能存在竞争关系,有些参与方可能会发送恶意梯度来破坏模型。这种场景不仅需要共识算法来确定哪些参与方的更新被接受,还需要结合安全多方计算等技术来保护隐私。传统的PBFT可以防恶意节点,但在联邦学习中可能需要更轻量级的方案,因为参与方可能有上百个,PBFT的通信复杂度会成为瓶颈。
边缘计算环境和传统数据中心很不一样,边缘节点之间的网络质量参差不齐,可能有些节点之间延迟很低,有些却需要绕远路。这种非对称网络下,传统共识算法假设的网络模型可能不适用。比如Raft假设心跳超时能可靠检测Leader故障,但在边缘网络里,可能只是某条链路拥塞了,其他节点还能正常通信。这时候需要更智能的故障检测机制,或者干脆放弃强一致性,采用分区容忍的最终一致性方案。
共识问题在Multi-Agent系统中是个基础但又在不断演进的话题。随着应用场景越来越复杂,比如跨云的Agent协同、移动环境下的自组织网络,可能会催生新的共识机制。我觉得理解经典算法的设计思想比记住具体实现更重要,这样才能在新场景下做出合理的改进。面试的目标不是展示你知道所有细节,而是让面试官相信你有能力学习和解决实际问题。