精炼回答
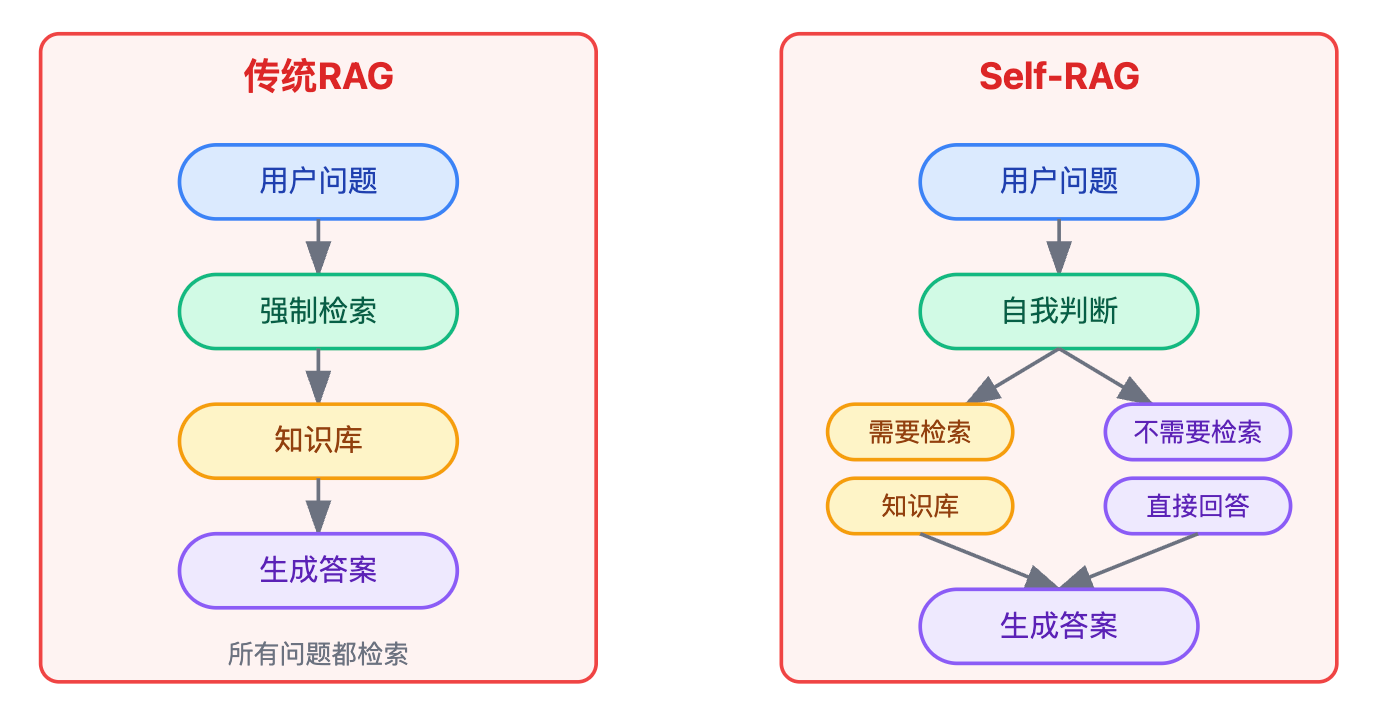
Self-RAG是一种让大模型自主决定何时需要检索外部知识的增强框架。传统RAG对所有问题都执行检索,而Self-RAG通过在训练阶段引入特殊的反思token(reflection tokens),让模型学会自我判断和控制检索行为。
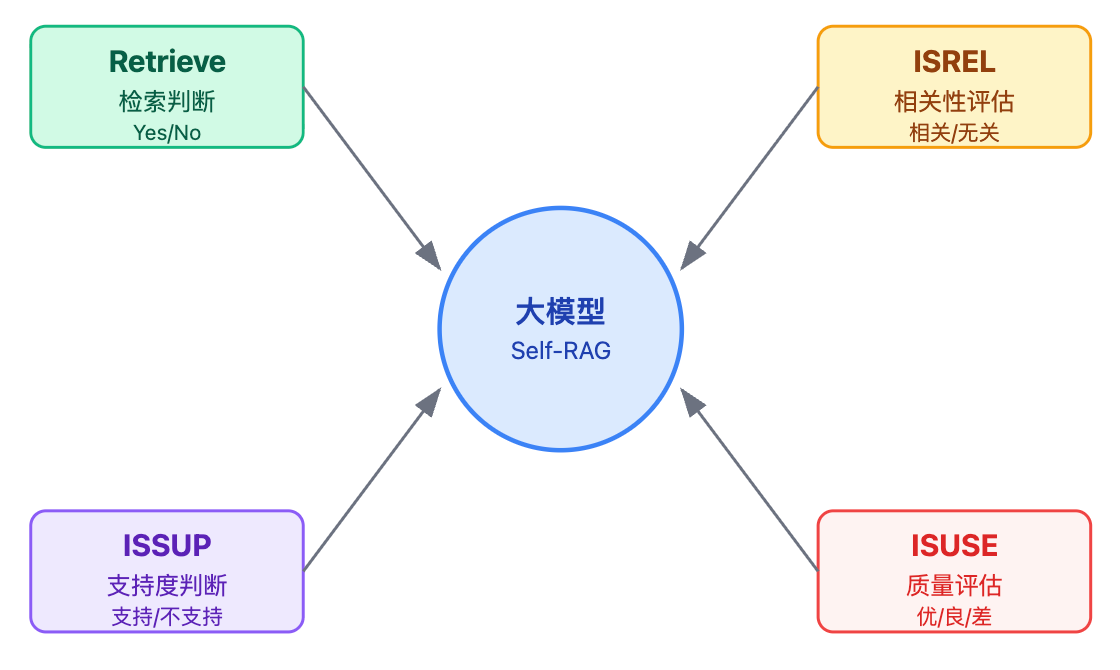
核心机制是训练模型生成几类特殊token:Retrieve标记判断是否需要检索、ISREL评估检索内容的相关性、ISSUP判断生成内容是否有检索证据支持、ISUSE评估回答的整体质量。模型在生成过程中会先输出Retrieve token,如果判定为"需要检索"才会触发外部知识库查询,否则直接用自身参数知识回答。
实现方式上,你需要构建包含这些反思token的训练数据集,让模型在监督学习中掌握判断逻辑。比如面对"今天天气怎么样"这类实时信息查询,模型输出Retrieve=Yes触发检索;而"什么是梯度下降"这种通用知识问题,模型输出Retrieve=No直接作答。这样做的好处是减少不必要的检索开销,同时通过ISREL和ISSUP这些质量评估token,能让模型在推理时对检索结果和生成内容进行自我校验,提升回答的准确性和可信度。本质上是把检索决策权交给模型本身,而不是外部规则系统。
扩展分析
深入分析:从概念到机制
面试时首先要快速建立概念框架。你可以这样开头:"Self-RAG本质上是给大模型装了一套自我反思机制,让它自己判断什么时候需要查资料,什么时候不需要。"这句话直接点出核心,比上来就讲技术细节更能抓住面试官注意力。
接着要马上对比传统RAG突出创新点。传统RAG就像个勤快但不太聪明的助手,不管什么问题都先去翻资料库,导致回答"1+1等于几"也要去检索一遍。Self-RAG的突破在于它会先思考"这个问题我自己知不知道",只有确实需要时才触发检索。这个对比要说得自然,让面试官感觉你真的理解了两者的本质差异。
关于实现思路,你需要体现技术洞察力。实现这种自主判断的关键是在模型训练时加入特殊的反思token,把检索决策变成了模型生成任务的一部分。模型在输出正常答案之前,会先生成一个Retrieve token表明态度,这个token的值决定了后续工作流是走检索分支还是直接生成分支。注意这里用"工作流分支"这种词汇,会让面试官觉得你思考过工程落地。
从问题出发建立技术共鸣
当你在核心回答中建立了框架之后,面试官很可能会追问技术细节。这时候你需要把Self-RAG的内部机制讲清楚,但千万别掉进技术名词的陷阱里。记住,面试官考察的是你能不能把复杂问题说明白,而不是背论文。
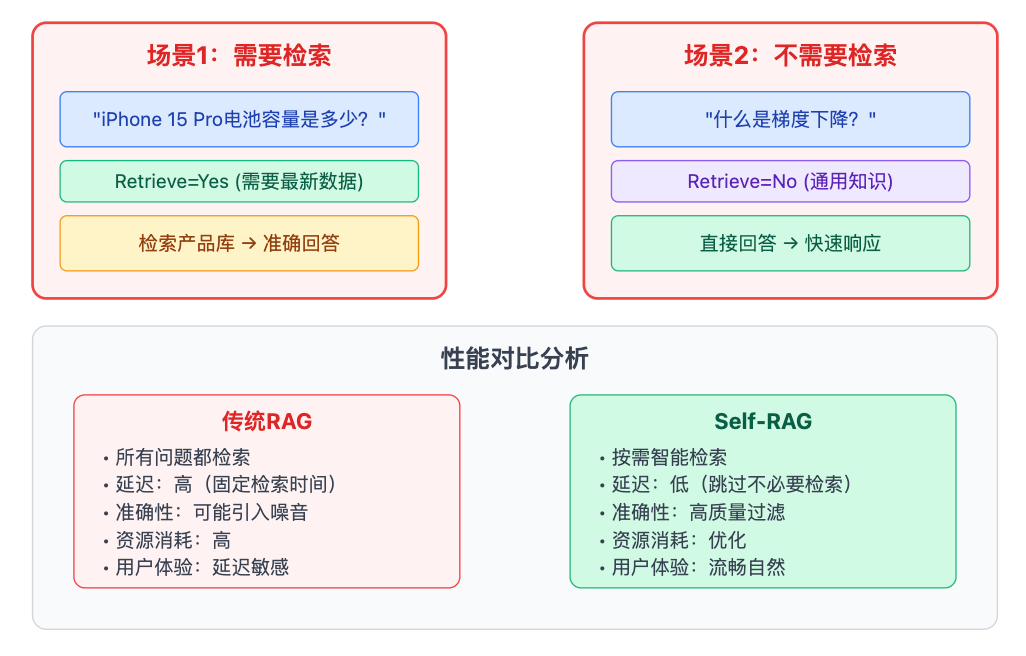
展开详细解释时,可以先抛出一个实际场景让面试官产生共鸣。比如你可以说:"咱们先想象一个真实问题,用户问'iPhone 15 Pro的电池容量是多少'和'手机为什么需要电池',传统RAG会对这两个问题都去检索产品库。但第一个问题确实需要查最新数据,第二个问题其实是通用常识,模型训练时早就见过无数次了。"这个对比能让面试官意识到,不是所有问题都值得付出检索的代价。接着你可以顺势引出:Self-RAG要解决的就是这个判断问题,它让模型在回答之前先自问一句"我需要查资料吗",这个自问的过程就是通过反思机制实现的。
说到反思机制,面试官脑子里可能还是抽象概念。你需要把它转化成可感知的流程。反思机制的核心是在模型输出层面增加了一套平行的决策流。普通模型生成文本时,每个位置输出一个词;而Self-RAG的模型在关键节点会输出特殊的反思token,这些token不是给用户看的,而是给系统看的控制信号。
然后你可以展开说这些token的具体分工。这套反思token有四个角色,各司其职。Retrieve token是守门员,在生成答案之前先判断要不要开启检索;ISREL token是质检员,检索回来的文档跟问题相不相关;ISSUP token是审计员,生成的答案有没有被检索内容支持;ISUSE token是总评委,最终答案质量够不够好。用职能角色来类比,比干巴巴地列举定义更容易记忆。
训练机制的讲解要体现工程思维
面试官接下来很可能问:"这些token怎么训练出来的?"这是个展示你工程理解的好机会。训练这套机制的关键是构造带标注的数据集。具体来说,需要对训练样本做三层标注。第一层是检索必要性标注,人工判断这个问题是否需要外部知识,比如"今天股票涨了多少"标注为需要检索,"什么是股票"标注为不需要。第二层是文档相关性标注,给定问题和检索回来的文档,标注是否真的相关。第三层是答案质量标注,包括答案是否有事实支撑、表述是否准确等维度。
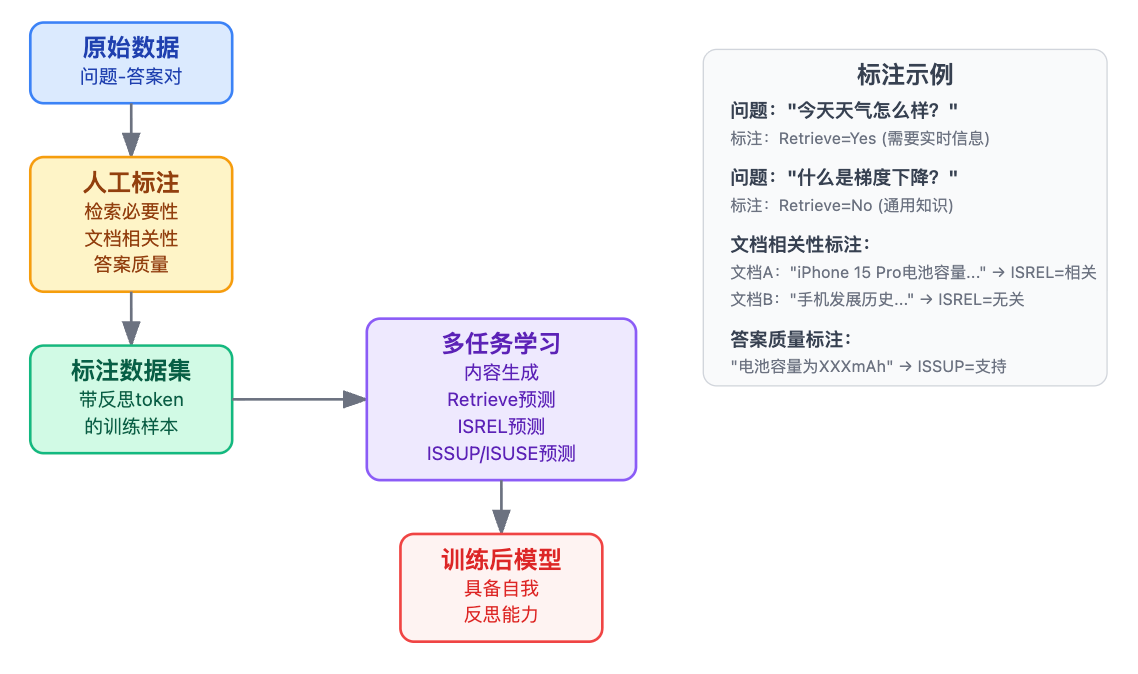
有了这些标注数据,训练过程其实是把多个任务糅合在一起。模型不仅要学会生成正常答案,还要在特定位置预测这些反思token的值。工程上可以用多任务学习的框架,让模型的不同输出头分别负责内容生成和反思判断,共享底层的语义理解能力。这里提到"多任务学习"和"输出头"这些术语,既专业又不过分深入,面试官会觉得你确实思考过实现细节。
用流程串联完整执行过程
讲完训练再讲推理流程时,千万别又变成文字罗列。你需要在面试官脑海里建立一个清晰的执行路径:实际使用时,整个生成过程变成了一个条件分支的流程。用户提问进来后,模型首先在内部生成一个Retrieve token,假设输出的是"Yes",系统就会暂停文本生成,转而调用向量数据库检索相关文档。检索回来的Top-K文档会和原始问题一起重新喂给模型,这时模型会生成ISREL token评估每个文档的相关性,把低分文档过滤掉。然后模型基于筛选后的文档开始生成答案,每生成一段内容就输出一个ISSUP token,判断这段话是不是有检索证据支撑。等全部答案生成完毕,模型最后输出ISUSE token给出整体质量评分。
面试时一定要主动点出解决的核心痛点。这个设计解决了两个实际问题:一是降低检索成本,毕竟每次调用向量数据库都有延迟和开销;二是提升回答质量,因为不必要的检索反而可能引入噪音信息。如果面试官此时点头,说明你讲到点子上了,可以再补充:更深层的价值在于,它把检索控制权从工程师写的if-else规则交给了模型自己,这是一种从规则驱动到数据驱动的范式转变。
深挖设计理念展现技术洞察
回答到这个深度时,如果面试官表现出兴趣,你就可以往更深层次引导。Self-RAG背后的设计理念其实挺有哲学意味的。它把检索从一个外部流程变成了模型推理的内生能力。传统RAG是"问题来了-先检索-再回答"的固定管道,而Self-RAG是"问题来了-思考是否需要检索-按需行动"的自适应决策。这种差异本质上是把控制权下放给了模型本身。
然后你可以联系实际场景深化理解:为什么需要这种自主判断?因为检索不是零成本的。拿电商搜索推荐系统来说,每次查询向量数据库可能要几十毫秒延迟,高并发场景下这个开销会被放大。更隐蔽的成本是噪音干扰,当用户问"为什么加入购物车后价格变了",这其实是在问促销规则逻辑,如果检索回来一堆商品详情页反而会稀释模型注意力,导致生成的答案跑偏。所以让模型自己判断什么时候真正需要外部知识,既是性能优化也是质量保障。