精炼回答
Chain-of-Thought(CoT)是一种提示技术,让大语言模型在给出最终答案前,先输出中间推理步骤。具体做法是在prompt中加入"让我们一步步思考"之类的引导,或者提供包含推理过程的示例。这个技术最早由Google在2022年的论文中正式提出,当时研究人员发现,在处理需要多步推理的任务时,只要给模型几个包含推理过程的示例,模型就能学会在回答新问题时也输出推理步骤。
CoT效果更好的核心原因在于transformer架构的计算特性。模型在生成每个token时,都会基于之前所有token进行注意力计算和特征提取。当模型直接输出答案时,只能依赖输入的有限上下文;但如果先生成推理步骤,这些中间token就成为了新的上下文,相当于给模型提供了更多的"计算空间"来处理复杂问题。
从架构层面看,Transformer在生成每个token时会对之前所有token做注意力计算。当模型直接输出答案时,它只能基于问题本身的信息进行一次性的特征提取;但如果先生成推理步骤,每生成一步,这一步的内容就会成为新的上下文,后续的注意力计算就能同时关注原始问题和已推理出的中间结果。这让模型能够将复杂任务分解成多个子问题逐步求解,在生成过程中动态调整注意力权重,聚焦于当前子问题的关键信息,利用自回归特性让后续推理建立在前面已生成的正确步骤之上。
举个实际场景:让模型解决数学应用题,直接问答可能输出错误结果;但用CoT引导它先提取已知条件、列出计算公式、逐步计算,准确率会显著提升。这不是模型"真的在思考",而是利用了更长的生成序列来增加模型的有效计算深度,本质上是用推理链扩展了模型的工作记忆空间。
扩展分析
CoT的技术原理与实现方式
CoT的实现方式主要分为两种类型,理解它们的差异对实际应用很重要。Few-shot CoT需要在prompt里先给几个完整的问题-推理-答案的示例,模型通过这些示例学会推理格式;而Zero-shot CoT就简单多了,直接在问题后面加一句"Let's think step by step"或者"让我们一步步思考",不需要任何示例。从实践来看,Zero-shot虽然方便,但在复杂任务上Few-shot的效果通常更稳定,因为示例能更明确地定义你期望的推理风格。
用一个具体例子来说明这个机制是如何工作的。假设让AI判断一个用户是否可能流失,直接问它可能只会基于最近登录时间这种浅层特征。但用CoT引导它先分析"用户最近三个月的购买频次下降了50%",再推理"购物车有商品但一周未下单",然后综合判断"高流失风险",这个过程中每一步的推理结果都会影响注意力机制关注哪些特征。模型在生成第一步分析时,注意力会集中在购买数据上;生成第二步时,注意力开始关联购物车和下单行为;到最后综合判断时,之前两步的内容都成为了新的上下文,模型可以基于完整的分析链做出决策。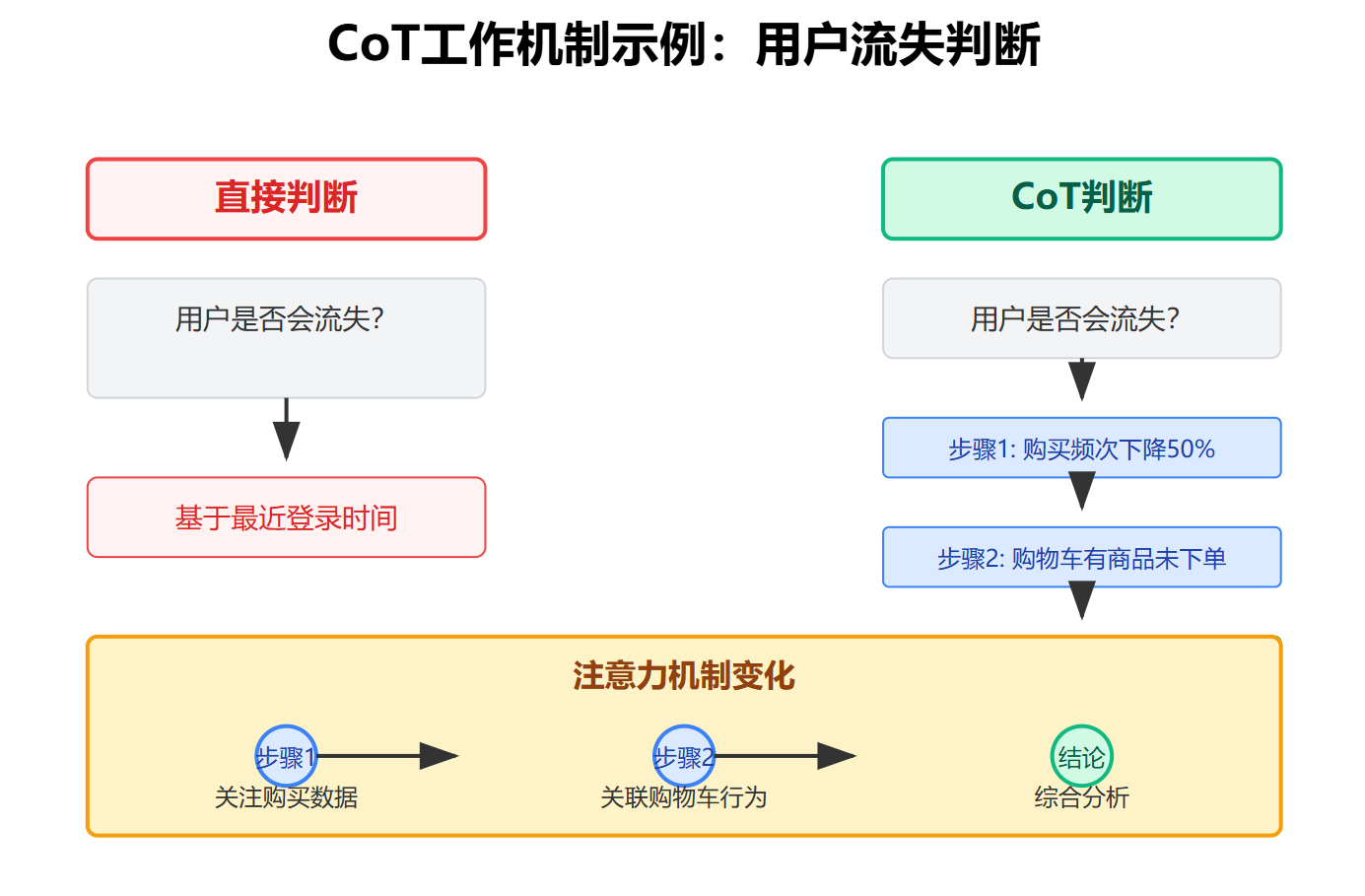 这里有个常见的误区需要澄清。有人会问"这是不是就是模仿人类思维?"表面上看确实和人类在草稿纸上分步推理很像,但本质不同。人类是真的在思考,而模型只是通过更长的生成序列获得了更多计算步骤。不过这种相似性确实有启发意义,它证明了分步骤处理信息这个策略,对人脑和神经网络都是有效的复杂问题求解方式。
这里有个常见的误区需要澄清。有人会问"这是不是就是模仿人类思维?"表面上看确实和人类在草稿纸上分步推理很像,但本质不同。人类是真的在思考,而模型只是通过更长的生成序列获得了更多计算步骤。不过这种相似性确实有启发意义,它证明了分步骤处理信息这个策略,对人脑和神经网络都是有效的复杂问题求解方式。
在prompt设计上有很多实用的技巧。最常见的Zero-shot模板就是在问题后加"Let's think step by step",但实际应用中我发现不同任务类型prompt的效果差异很大。数学题用"让我们列出解题步骤"效果好,逻辑推理题用"让我们分析每个条件"更合适,这说明prompt的措辞需要匹配任务的认知特性。直接在问题后面加"思考一下"这种模糊指令效果往往不好,更有效的是明确指定推理结构。
比如处理客服场景的退款申请,可以这样设计prompt结构化的引导:
String prompt ="用户申请退款,订单金额500元,商品已签收3天,"+
"理由是'尺码不合适'。该用户近3个月有2次退款记录。\n\n"+
"请逐步分析是否应该批准退款:\n"+
"步骤1:检查退款时效是否符合规定\n"+
"步骤2:评估退款理由的合理性\n"+
"步骤3:考虑用户退款频次是否异常\n"+
"步骤4:给出最终决策和原因";
ChatCompletionRequest request =ChatCompletionRequest.builder()
.model("gpt-4")
.messages(List.of(
newChatMessage("user", prompt)
))
.temperature(0.3)// 降低随机性让推理更稳定
.build();
ChatCompletionResult result = openAiService.createChatCompletion(request);
String reasoning = result.getChoices().get(0).getMessage().getContent();这个prompt的设计思路是把复杂的业务规则拆解成可验证的步骤,每一步都对应一个具体的判断维度,模型在生成时会沿着这个结构输出推理过程。注意这里把temperature设置得比较低,因为推理任务我们希望模型输出稳定可复现,不需要太多创造性发挥。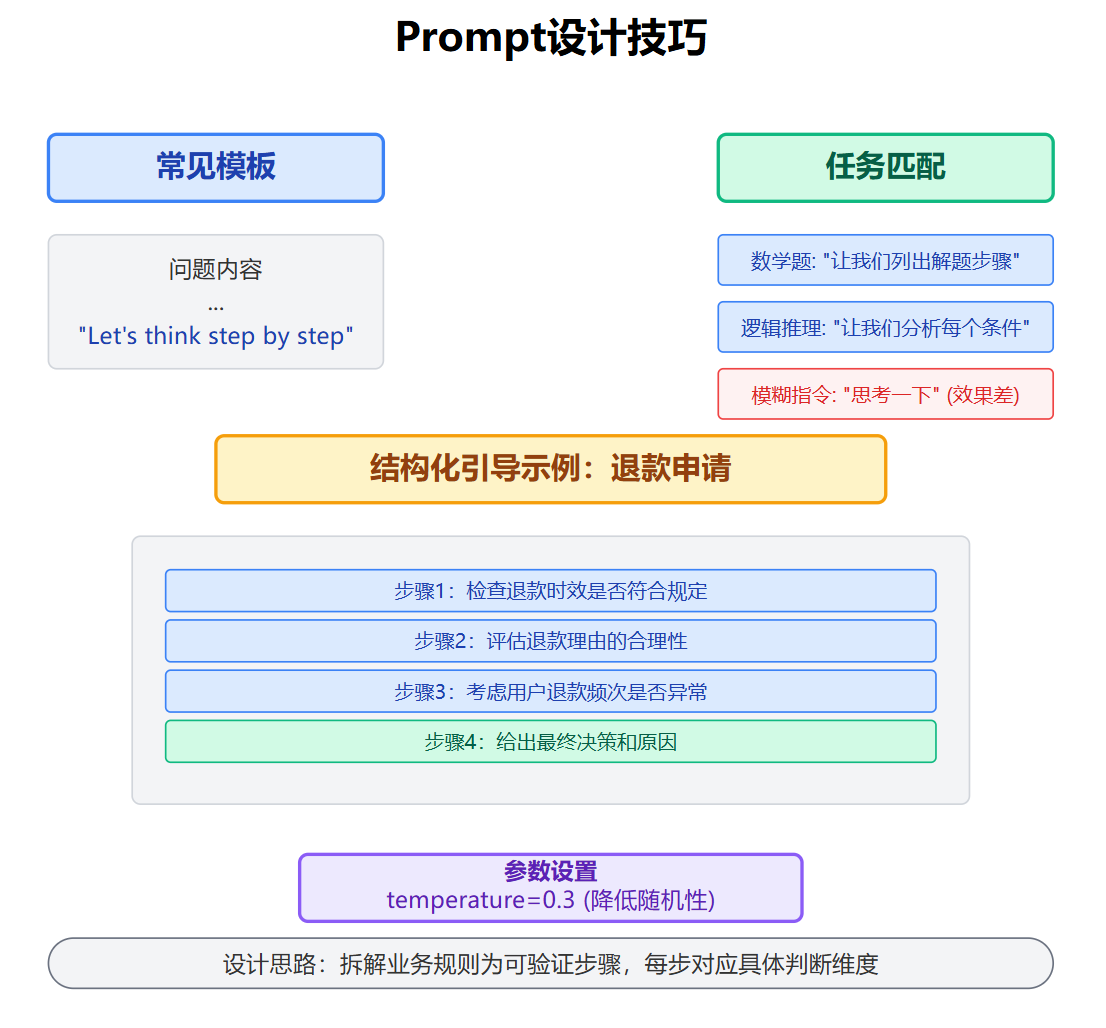
CoT还有一个进阶玩法值得了解,就是Self-Consistency。原理是让模型用CoT生成多次,每次的推理路径可能不同,然后对最终答案做投票。这利用了一个朴素的假设:正确的推理路径可能有多条,但最终答案应该一致;如果多次推理得出同一答案,这个答案正确的概率更高。不过这种方法也有明显的代价,成本直接翻好几倍,而且如果模型对某个概念本身就理解偏了,多次生成可能都是同样的错误。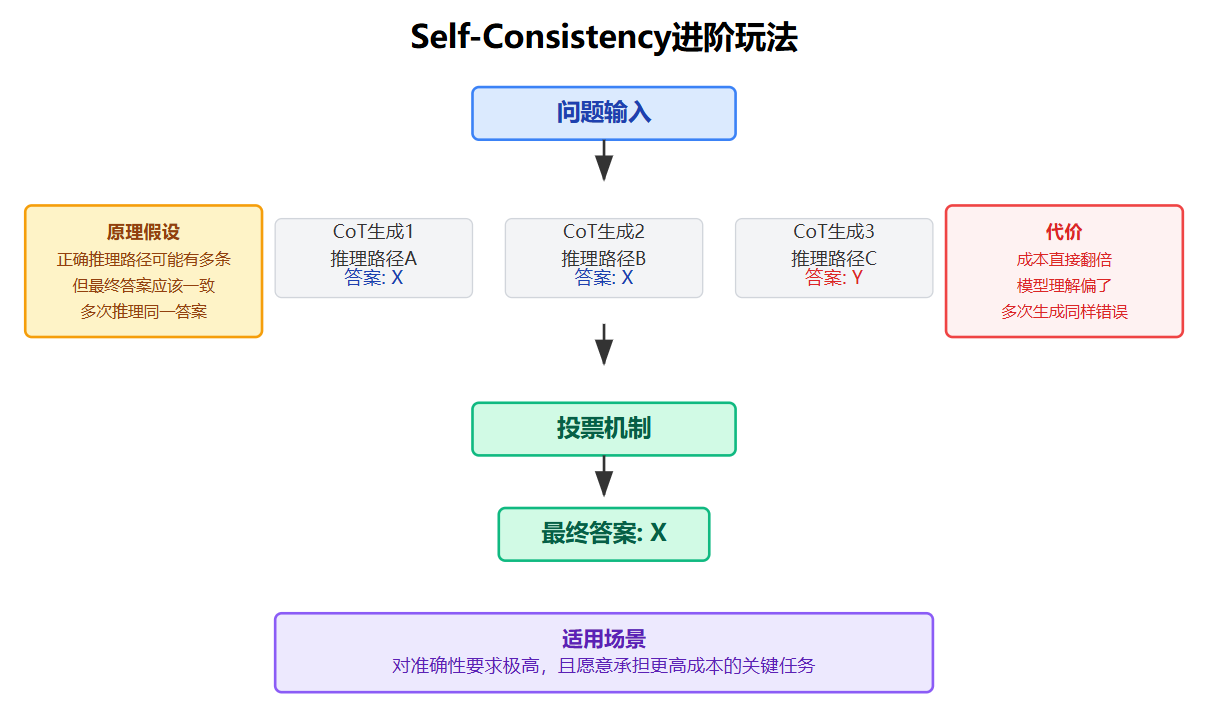
CoT的实践应用与边界
CoT在数学推理上的效果特别明显,比如解一道应用题,直接问可能算错,但加上"让我们分步骤解决:第一步找出已知条件,第二步列出计算公式,第三步逐步计算",准确率能提升30%以上。在处理需要多条件判断的问题时,比如根据用户行为判断账号是否异常,可以引导模型先列出"最近登录IP是否变化""交易金额是否异常""操作时间是否符合习惯"这些维度,再综合判断,这比直接输出结果可靠得多。
但CoT并不是万能的,它有明确的适用边界。简单的分类任务或者事实查询,比如"这段文本是正面还是负面评价"或者"北京是中国的首都吗",用CoT反而会降低效果,因为推理步骤可能引入不必要的干扰。我的经验是,如果任务需要综合3个以上的信息点才能得出结论,或者涉及多步骤计算,CoT就值得尝试;如果是直接映射式的简单判断,直接问答就够了。
成本问题是个很现实的考量。CoT有个不容忽视的问题是token消耗会显著增加,一个原本只需要10个token回答的问题,加上推理过程可能要消耗100个token,成本直接涨了10倍。实际应用中需要做个trade-off,对于高价值的决策任务比如大额退款审核,用CoT保证准确性很值得;但对于高频的简单查询,可以先用规则引擎过滤掉明显case,只有边界情况才调用CoT。
另一个降低成本的方法是两阶段调用策略。第一次用CoT生成推理过程并得出答案,把这个推理模板保存下来,后续遇到类似问题就可以用Few-shot方式,直接给模型展示这个推理案例,这样比每次都Zero-shot引导要高效。这种方法在电商场景特别实用,比如处理常见的退换货问题,把几个典型case的推理过程固化下来,既能保证质量又能控制成本。
CoT有个挺棘手的特性,就是如果模型在第一步推理就错了,后续步骤会基于这个错误继续推理,反而比直接回答错得更离谱。比如让模型分析一段代码的bug,如果它一开始就把变量含义理解错了,后面再怎么认真推理也是南辕北辙。这个观察展现了模型不是真的在思考,而是在做序列生成,它不具备人类那种"意识到自己可能想错了"的能力。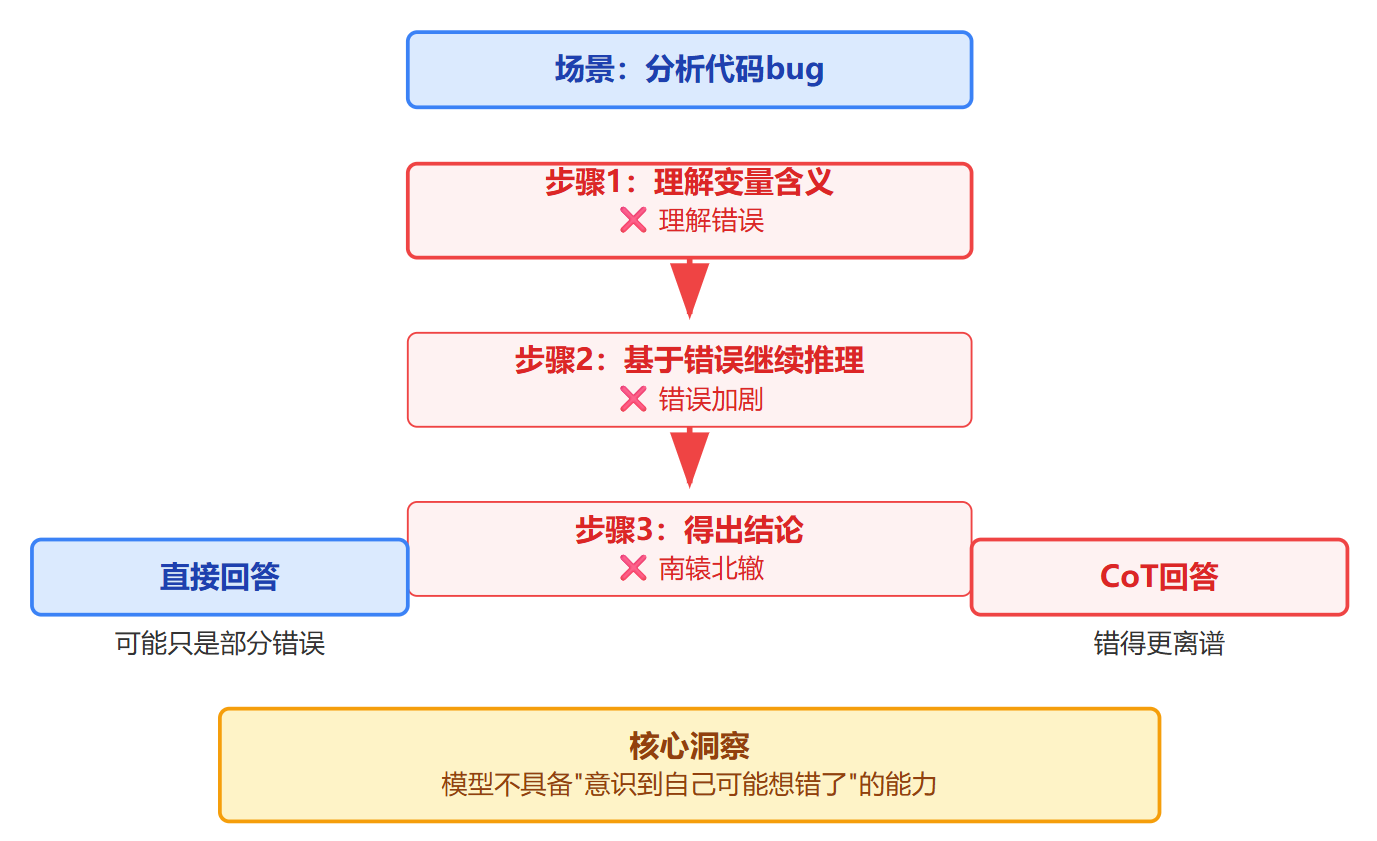
深度思考与技术演进
在实际应用中不能只看准确率,还得考虑响应时间、token成本、可解释性这些维度。有时候一个需要推理5步的CoT方案准确率95%,但响应慢3秒;而一个直接回答的方案准确率90%,体验反而可能更好。这种多维度的评估标准对技术落地很关键,不是为了用技术而用技术,而是真正在解决业务问题。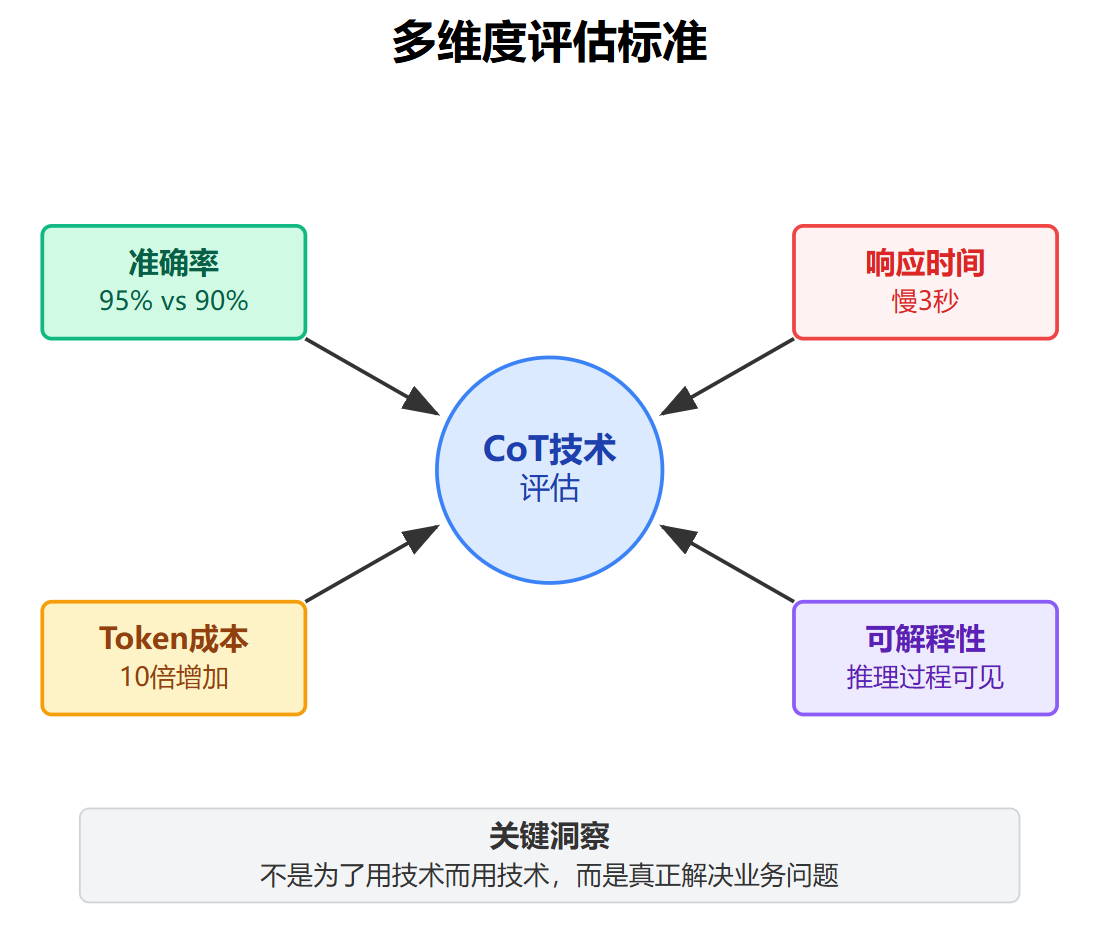
CoT更深层的价值在于它揭示了一个重要的技术方向:把推理能力从外部的prompt工程逐步内化到模型本身。现在我们需要精心设计prompt来引导模型推理,但未来的发展可能是让模型自己学会什么时候需要深度推理、什么时候直接回答。OpenAI的o1模型就在这个方向上做了探索,它不需要你在prompt里明确要求推理,模型自己就会生成思考过程。这种把CoT内化到模型能力里的思路,可能是未来的发展方向。
从工程实践的角度看,CoT接下来可能会往两个方向发展。一个是自动化,让系统自己学习什么场景需要多深的推理链,而不是每次都手动设计prompt结构。这可以通过强化学习实现,让模型在大量任务中学习到最优的推理深度。另一个是和其他技术结合,比如配合检索增强生成(RAG),在推理过程中动态查找外部知识。想象一个场景:模型在分析复杂的技术问题时,推理到某一步发现需要查阅API文档,就主动触发检索,然后基于检索结果继续推理。
有些研究在探索怎么在训练阶段就把推理能力融入模型,而不是完全依赖prompt工程。比如用推理过程作为训练数据,或者用强化学习让模型学会自己生成高质量的推理步骤。这些方向都很有前景,因为它们试图解决CoT的一个根本局限:推理质量高度依赖于人工设计的prompt,而不同的任务需要不同的引导方式,这个过程既费时又需要经验。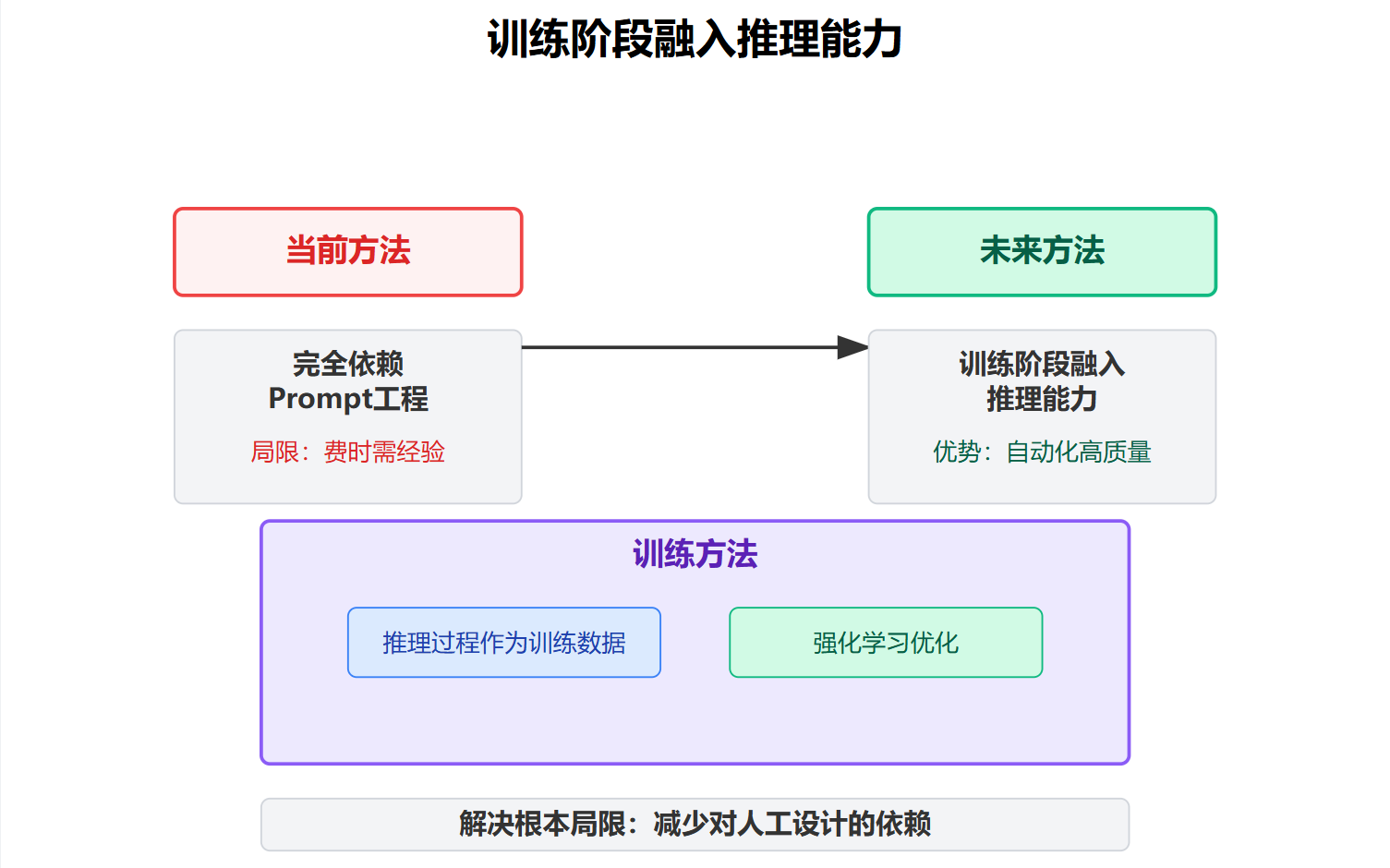
最后想分享一个实践体会。CoT虽然是个简单的技术,但它教会我一个重要的思维方式:有时候让AI"慢一点思考"比追求快速响应更有价值。在很多业务场景中,我们习惯于追求毫秒级的响应速度,但对于复杂决策任务,多花几秒钟生成一个可靠的推理过程,远比给出一个快速但错误的答案要好。这种思路不仅适用于AI系统,对我们设计整个技术架构都有启发意义。