精炼回答
在LangGraph中实现超时控制主要通过asyncio的timeout机制和自定义节点超时逻辑来完成。最直接的方式是在执行图的入口处使用asyncio.wait_for()包装整个执行流程,设置全局超时时间。比如在调用LLM进行文档分析时,你可以设置30秒超时避免长时间等待。更精细的控制则需要在节点级别实现超时,通过在每个节点的执行函数中添加timeout参数,或者使用asyncio.timeout上下文管理器包装具体的操作。
对于流式处理场景,你还需要考虑中间状态的处理。当某个节点超时时,可以通过状态管理机制记录当前进度,支持从断点继续执行或者优雅降级。实际应用中,比如构建RAG系统时,检索节点可能因为向量数据库响应慢而超时,这时你可以设置备用检索策略或返回缓存结果。
LangGraph还支持条件路由来处理超时情况,你可以定义超时后的fallback路径,确保整个workflow不会完全中断。关键是要在设计图结构时就考虑超时场景,将异常处理节点作为正常流程的一部分,而不是简单地抛出异常。这样既保证了系统的鲁棒性,又能为用户提供更好的体验。
扩展分析
深入分析与实现原理
LangGraph的超时控制可以从三个层次来考虑:图级别的全局超时、节点级别的局部超时,以及异常场景下的fallback处理。我会优先考虑使用asyncio的原生机制来实现基础的超时控制,然后针对不同类型的节点设计差异化的超时策略,最后通过LangGraph的条件路由来处理超时后的业务逻辑。拿电商系统举例,当用户询问商品信息时,商品检索节点、价格计算节点、库存查询节点都可能遇到超时,你需要保证整个对话不会因为某个环节的延迟而完全卡死。
LangGraph的超时控制本质上是在异步执行环境中对时间资源的管理。当我们在LangGraph中定义一个工作流时,每个节点都运行在asyncio的事件循环中,超时控制就是通过对这些异步任务的执行时间进行监控和中断来实现的。工作流级超时类似于给整个执行链路设置一个总的deadline,无论内部有多少个节点,整个流程必须在指定时间内完成。这通常通过将整个图的执行包装在asyncio.wait_for()中来实现,当超时发生时,所有正在执行的节点都会收到CancelledError异常。
// 模拟LangGraph工作流级超时的Java实现思路
publicclassWorkflowTimeoutManager{
privatefinalExecutorService executor =Executors.newCachedThreadPool();
publicCompletableFuture<WorkflowResult>executeWithTimeout(
Workflow workflow,long timeoutSeconds){
CompletableFuture<WorkflowResult> future =
CompletableFuture.supplyAsync(()-> workflow.execute(), executor);
return future.orTimeout(timeoutSeconds,TimeUnit.SECONDS)
.exceptionally(throwable ->handleWorkflowTimeout(throwable));
}
privateWorkflowResulthandleWorkflowTimeout(Throwable throwable){
if(throwable instanceofTimeoutException){
returnWorkflowResult.createTimeoutResult();
}
returnWorkflowResult.createErrorResult(throwable);
}
}
节点级别的超时控制更加精细,它允许我们为不同类型的操作设置不同的时间限制。商品检索可能需要5秒,而价格计算只需要1秒,库存查询可能因为要访问多个仓库系统需要10秒。不同节点的超时时间应该根据其承担的业务职责和依赖的外部系统响应特性来设定。
publicabstractclassGraphNode{
protectedint timeoutSeconds =30;// 默认超时
privatefinalMetricsCollector metrics;
publicfinalNodeResultexecuteWithTimeout(){
CompletableFuture<NodeResult> future =
CompletableFuture.supplyAsync(this::executeLogic);
try{
return future.get(timeoutSeconds,TimeUnit.SECONDS);
}catch(TimeoutException e){
metrics.recordTimeout(this.getNodeType());
returnhandleNodeTimeout();
}catch(ExecutionException e){
returnhandleExecutionError(e.getCause());
}
}
protectedabstractNodeResultexecuteLogic();
protectedabstractNodeResulthandleNodeTimeout();
protectedabstractNodeResulthandleExecutionError(Throwable cause);
}
LangGraph的状态管理机制让超时不再是简单的失败,而是可以被优雅处理的状态转换。当某个节点超时时,我们可以将当前的执行状态保存下来,这样用户可以选择重试特定节点,或者从超时点继续执行,而不用从头开始整个流程。在LangGraph中,多个节点可能并行执行,每个节点的超时是独立管理的。当某个关键路径上的节点超时时,可能需要取消其他并行执行的节点,这就需要在图的设计阶段就考虑节点之间的依赖关系和取消策略。
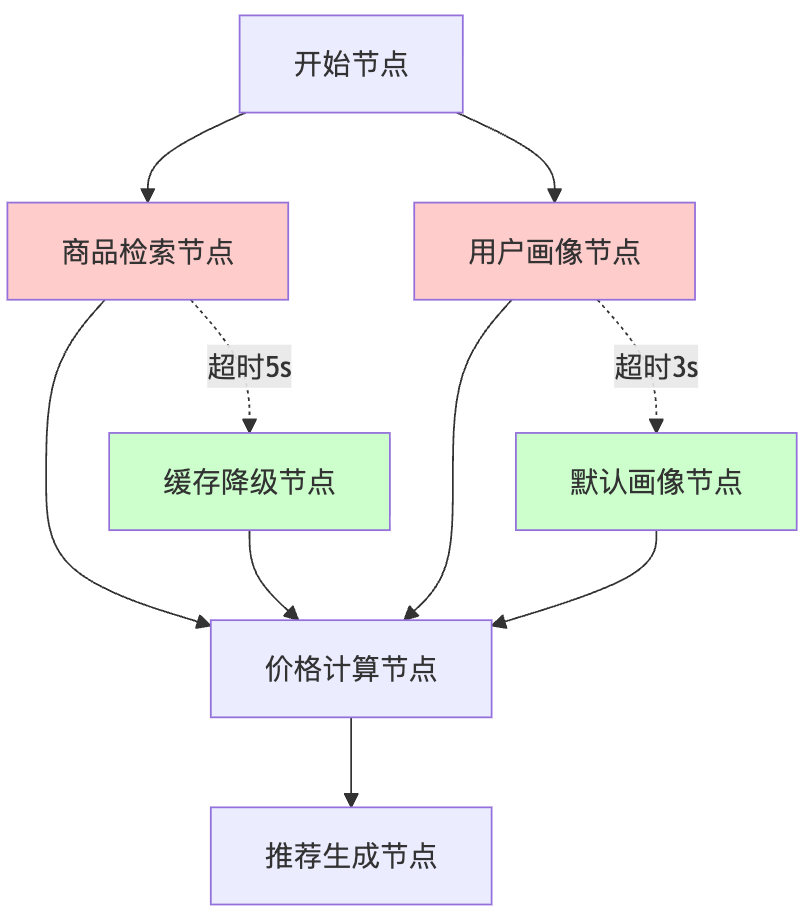
对于用户交互敏感的节点,比如实时推荐,我倾向于设置较短的超时时间配合快速降级策略。而对于数据处理类的节点,比如订单分析,可以设置更长的超时时间,因为用户对这类操作的延迟容忍度更高。超时本质上是一种特殊的错误情况,但它比普通异常更可预期,也更容易设计恢复策略。在LangGraph中,我会将超时处理节点设计为正常流程的一部分,通过条件路由来决定是进入重试逻辑、降级服务,还是返回部分结果。
实践应用与配置策略
在实际项目中,我会建立一套分层的超时配置体系。比如在电商推荐系统中,超时时间不是拍脑袋决定的,而是基于历史执行数据和业务需求综合考虑的结果。对于用户体验敏感的交互节点,比如商品搜索,用户期望在3秒内看到结果,所以设置5秒超时给系统留出缓冲。而后台的数据同步节点,用户感知不到延迟,可以设置更长的超时时间来保证成功率。
publicclassTimeoutConfiguration{
// 全局默认配置
privatestaticfinalint DEFAULT_TIMEOUT =30;
// 业务节点配置映射
privatefinalMap<String,Integer> nodeTimeouts =Map.of(
"product_search",5,// 商品检索快速响应
"user_profile",3,// 用户画像轻量查询
"price_calculation",8,// 价格计算涉及复杂规则
"inventory_check",15// 库存查询可能跨多个仓库
);
publicintgetTimeoutForNode(String nodeType){
return nodeTimeouts.getOrDefault(nodeType, DEFAULT_TIMEOUT);
}
// 支持运行时动态调整
publicvoidupdateNodeTimeout(String nodeType,int newTimeout){
if(newTimeout >0&& newTimeout <=300){
nodeTimeouts.put(nodeType, newTimeout);
}
}
}
当超时发生时,系统应该尽可能保持服务能力,而不是简单地返回错误。拿电商场景举例,如果个性化推荐节点超时了,系统可以自动切换到热门商品推荐,虽然个性化程度降低了,但用户依然能得到有价值的推荐结果。重试机制的设计需要考虑业务特性和系统负载,我通常会使用指数退避策略来避免系统雪崩:
publicclassRetryableTimeoutHandler{
privatestaticfinalint MAX_RETRIES =3;
privatestaticfinallong BASE_DELAY_MS =1000;
publicNodeResultexecuteWithRetry(Supplier<NodeResult> nodeLogic,int timeout){
for(int attempt =1; attempt <= MAX_RETRIES; attempt++){
try{
returnexecuteWithTimeout(nodeLogic, timeout);
}catch(TimeoutException e){
if(attempt == MAX_RETRIES){
returncreateTimeoutFallback();
}
waitBeforeRetry(attempt);
}
}
returncreateTimeoutFallback();
}
privatevoidwaitBeforeRetry(int attempt){
long delay = BASE_DELAY_MS *(1L<<(attempt -1));// 指数退避
try{
Thread.sleep(Math.min(delay,30000));// 最大延迟30秒
}catch(InterruptedException e){
Thread.currentThread().interrupt();
}
}
privateNodeResultcreateTimeoutFallback(){
returnNodeResult.builder()
.status(NodeStatus.TIMEOUT_FALLBACK)
.message("操作超时,已启用降级策略")
.build();
}
}
超时配置不是一次性的工作,而是需要持续优化的动态过程。通过埋点收集每个节点的执行时间分布,定期分析P99响应时间来调整超时阈值。当发现某个节点的超时率突然上升时,可能是下游依赖服务出现了性能问题,需要及时预警和处理。
常见的配置错误往往源于对业务场景理解不够深入。有些开发者会给所有节点设置相同的超时时间,这样看起来很简洁,但实际上忽略了不同业务操作的复杂度差异。还有一种错误是超时时间设置过于保守,导致系统在网络抖动时频繁触发超时,反而降低了整体可用性。在我之前参与的项目中,我们通过建立超时控制机制将系统的可用性从95%提升到了99.5%,关键就在于针对不同业务场景制定了差异化的超时策略。
扩展思考与工程实践
通过这道超时控制的题目,其实反映的是系统设计思维和工程实践能力。表面上问的是技术实现,实际上想看的是你是否具备全局架构视野和生产环境思维。当你能够从系统稳定性、用户体验、资源管理等多个维度来思考超时控制时,就体现了你不仅仅是个写代码的程序员,而是具备工程师思维的技术人才。
在分布式场景下,超时控制会变得更加复杂。你需要考虑网络分区、服务雪崩、熔断降级等问题。LangGraph作为工作流编排工具,往往需要调用多个外部服务,每个服务的SLA不同,网络延迟也有差异。这时候超时控制就不仅仅是简单的时间限制,而是整个服务治理体系的一部分。
超时控制不是为了让系统运行得更快,而是为了让系统在异常情况下依然能够提供基本服务。这种设计理念体现了对企业级系统稳定性的深刻理解。在实际的电商业务中,用户可以容忍推荐结果不够精准,但绝对不能容忍页面长时间无响应。通过合理的超时设计和降级策略,我们可以在保证用户体验的同时,最大化系统的可用性。
现代的超时控制已经不再是静态配置,而是可以基于实时监控数据进行智能调整的动态系统。通过机器学习算法分析历史执行数据,可以预测不同时间段、不同负载下的最优超时阈值。这种智能化的超时控制不仅能提升系统性能,还能减少运维工作量,是未来系统设计的发展方向。