精炼回答
AI Agent的幻觉问题主要通过多层验证策略来解决。首先在输入端进行事实核查,通过检索增强生成(RAG)技术将Agent的回答与可信知识库进行实时比对,确保信息来源的准确性。在推理过程中,我建议采用多模型交叉验证,让不同的模型对同一问题进行独立判断,通过一致性检查来识别潜在的幻觉内容。
对于输出验证,置信度评分机制非常关键,当Agent对某个回答的置信度低于阈值时,应该主动标记不确定性或拒绝回答。同时配合逻辑一致性检查,验证Agent前后回答是否存在矛盾。
在实际应用中,比如智能客服场景,可以设置人工审核触发点,当检测到高风险回答时自动转人工处理。对于金融或医疗等关键领域,还需要建立专业知识图谱验证,确保Agent的回答符合行业标准和法规要求。
另外,持续学习和反馈循环也很重要,通过收集用户纠错和专家标注,不断优化Agent的判断能力。最有效的方法是建立分层验证架构,根据问题的复杂度和风险等级采用不同强度的验证策略,既保证准确性又维持响应效率。
扩展分析
想在面试中真正展现你对AI Agent幻觉问题的深度理解,就得从根本机制说起。AI模型本质上是基于统计规律进行文本生成的,它会选择在训练数据中最可能出现的下一个词汇。问题在于,模型无法真正理解事实的真假,它只是在学习语言模式。当训练数据中存在错误信息,或者模型面对训练时未充分见过的问题时,就容易产生看似合理但实际错误的输出。
RAG技术的核心价值在于为模型提供了外部事实锚点。当Agent需要回答问题时,首先从可信知识库中检索相关信息,然后让模型基于这些事实来生成回答,而不是完全依赖参数化的记忆。在工程实现上,RAG验证需要与多重保障机制相结合。
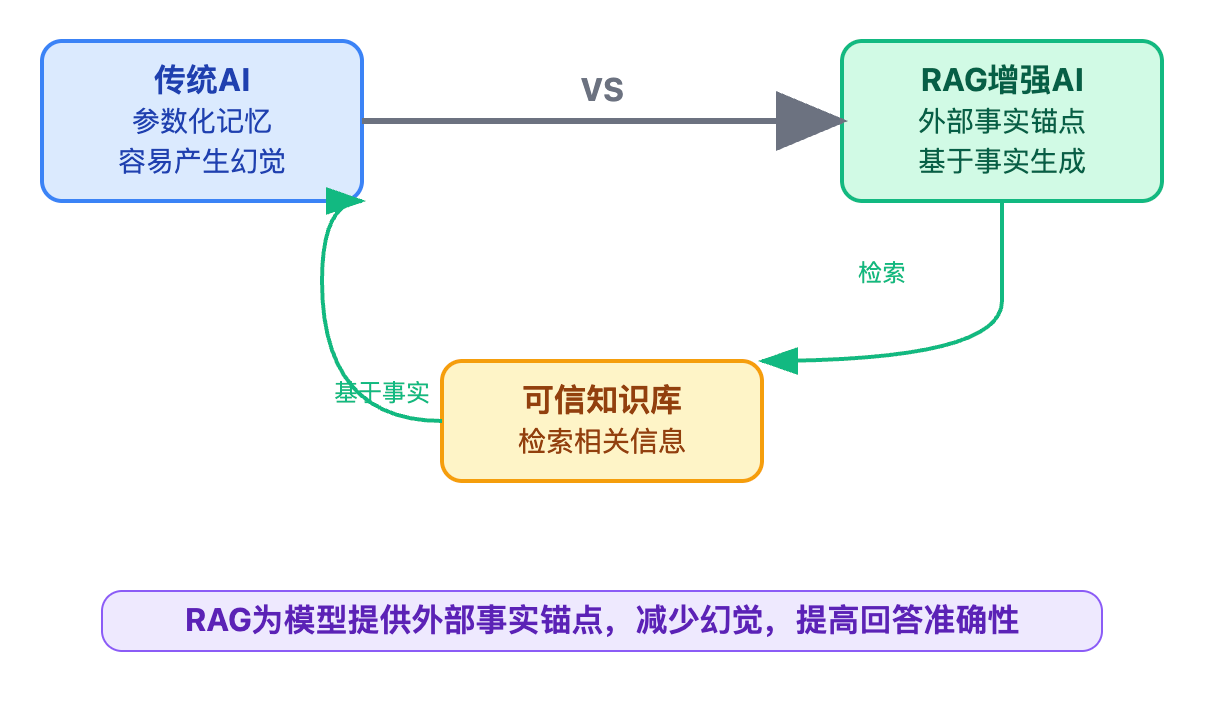
单一的验证手段都有局限性,比如知识图谱验证适合结构化信息,但对于开放性问题就力不从心。构建多层防护体系更为有效:知识图谱验证负责结构化事实的校验,比如产品规格、价格信息这类有明确答案的问题。多模型交叉验证则处理更复杂的推理场景,通过不同模型的一致性来判断回答的可靠性。
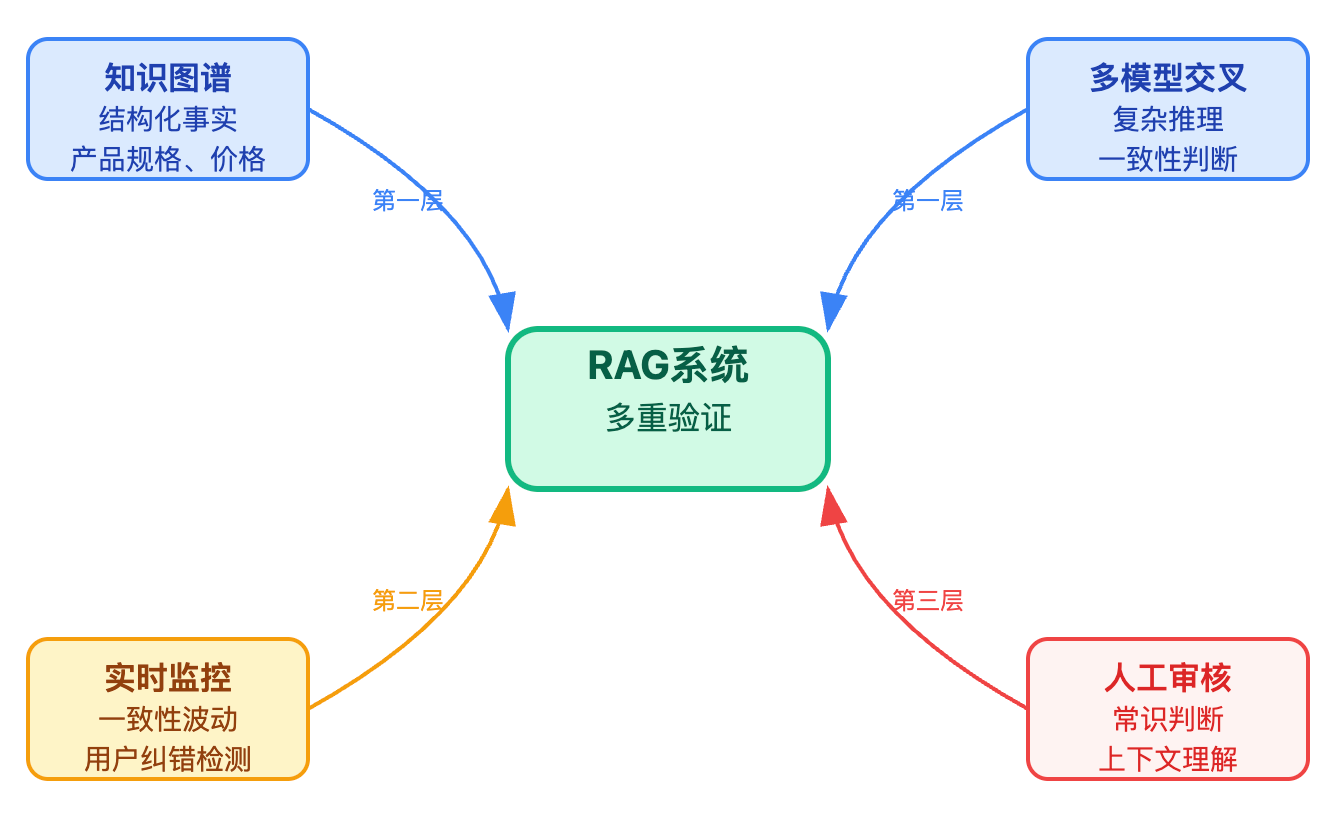
实时监控机制的设计不能仅仅依赖置信度分数,因为模型可能对错误答案也很自信。更有效的方法是监控回答的一致性波动。当同一个问题在短时间内产生了不同的回答,或者用户频繁对某类回答进行纠错时,就需要触发人工审核。
publicclassConsistencyMonitor{
privateMap<String,List<String>> responseHistory =newHashMap<>();
privatestaticfinaldouble CONSISTENCY_THRESHOLD =0.3;
publicbooleanshouldTriggerReview(String query,String response){
String queryNormalized =normalizeQuery(query);
List<String> history = responseHistory.getOrDefault(queryNormalized,newArrayList<>());
if(history.size()>=3){
// 计算回答的相似度方差
double variance =calculateResponseVariance(history);
if(variance > CONSISTENCY_THRESHOLD){
logInconsistency(queryNormalized, history);
returntrue;// 触发人工审核
}
}
history.add(response);
if(history.size()>10){
history.remove(0);// 保持历史记录在合理范围内
}
responseHistory.put(queryNormalized, history);
returnfalse;
}
privatedoublecalculateResponseVariance(List<String> responses){
// 计算语义相似度的方差,判断回答一致性
double[] similarities =newdouble[responses.size()*(responses.size()-1)/2];
int index =0;
for(int i =0; i < responses.size(); i++){
for(int j = i +1; j < responses.size(); j++){
similarities[index++]=calculateSementicSimilarity(responses.get(i), responses.get(j));
}
}
returncalculateVariance(similarities);
}
}
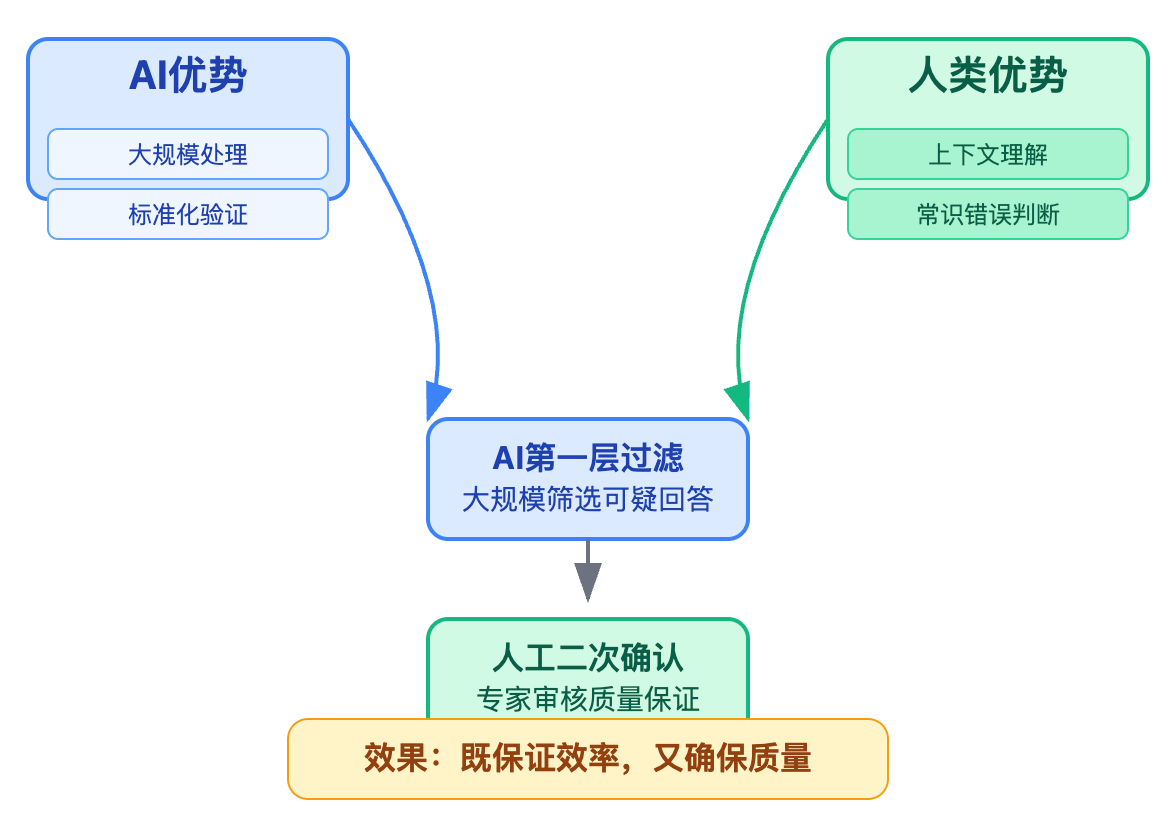
人机协作的价值在于弥补纯技术手段的盲区。AI擅长处理大规模、标准化的验证任务,但人类在理解上下文、判断常识错误方面更有优势。理想的设计是让AI负责第一层过滤,把可疑的回答交给人工专家进行二次确认。这样既保证了效率,又确保了质量。
实践应用
在电商客服场景中,当用户询问"这款手机支持无线充电吗?"时,我会设计三层验证pipeline来处理这类问题。第一层是问题分类,判断这是否属于可以通过结构化数据回答的问题。第二层是知识库验证,从商品属性数据库中检索准确信息。第三层是答案合理性检查,确保生成的回答逻辑自洽且表达清晰。
publicclassProductQueryPipeline{
privateProductDatabase productDatabase;
privateQueryRiskAssessor riskAssessor;
privateResponseValidator responseValidator;
publicCustomerResponseprocessQuery(String userQuery,String productId){
// 第一层:问题风险评估
QueryRisk risk = riskAssessor.assessQueryRisk(userQuery);
// 第二层:结构化验证
ProductInfo product = productDatabase.getById(productId);
String factualAnswer =extractRelevantInfo(product, userQuery);
// 第三层:置信度评估
double confidence = responseValidator.calculateResponseConfidence(factualAnswer, userQuery);
if(confidence <getThresholdByRisk(risk)){
returnCustomerResponse.escalateToHuman(userQuery,
"信息复杂,建议咨询专业客服");
}
returnCustomerResponse.withConfidence(factualAnswer, confidence);
}
privatedoublegetThresholdByRisk(QueryRisk risk){
switch(risk){
case LOW:return0.8;// 基本商品信息
case MEDIUM:return0.9;// 功能特性说明
case HIGH:return0.95;// 价格、售后政策
default:return0.85;
}
}
privateStringextractRelevantInfo(ProductInfo product,String query){
// 基于查询意图提取相关的产品属性
if(query.contains("无线充电")|| query.contains("充电方式")){
return product.getChargingFeatures();
}
if(query.contains("内存")|| query.contains("存储")){
return product.getMemorySpecs();
}
return product.getGeneralDescription();
}
}
置信度阈值的设置根据业务场景动态调整。商品基本信息查询的阈值可以设置为0.8,因为错误成本相对较低。但是涉及价格、促销政策的问题,阈值应该提高到0.95,因为错误信息可能导致用户投诉或商业纠纷。更关键的是,系统需要根据历史准确率来自动调整这些阈值。
A/B测试在验证策略优化中扮演着重要角色。我会同时运行两套验证策略,比较它们在准确率、响应时间、用户满意度等维度的表现。一套使用严格的多层验证,另一套采用更轻量的快速验证。通过对比实验数据,找到最适合当前业务场景的平衡点。
成本控制与准确性的平衡体现了工程师的商业思维。每次多模型验证的成本是单次推理的3-5倍,但可以将错误率从5%降低到1%。关键是要计算错误答案的业务损失,当错误成本远超验证成本时,严格验证就是值得的。对于电商场景,商品信息错误可能导致用户投诉和退货,这些隐性成本往往被低估。
在工具选择方面,LangChain框架提供了很好的RAG验证组件,可以快速搭建知识库检索流程。对于更复杂的一致性验证,可以考虑集成Haystack或者LlamaIndex这类专门的检索增强框架。最重要的是建立完整的监控-反馈-优化循环,AI系统的优化不是一次性工程,而是需要持续改进的过程。