精炼回答
上下文压缩技术主要是为了在保留关键信息的前提下减少输入token数量,这个问题的核心是在大模型应用中,如何在保证回答质量的前提下,把输入的上下文从几千甚至上万token降下来,毕竟token既影响成本也影响响应速度。
从技术实现角度来看,主要分为三个方向。过滤型通过相似度计算把不相关的内容直接删掉,比如使用embedding模型计算文档片段与查询问题的相似度,只保留相关性高的部分送入LLM,这能直接过滤掉无关内容。检索到10个文档片段,通过相似度阈值筛选后可能只需要保留3个最相关的,token消耗立刻降到原来的30%。压缩型用摘要或者关键信息提取把长文本变短,可以利用小模型做摘要提取,把长文档先压缩成关键句子或要点,再作为上下文输入。截断型设定优先级规则保留最重要的部分,比如滑动窗口策略对于超长对话历史,只保留最近N轮对话加上初始系统提示,中间部分可以用一句话摘要代替。
实际应用中,客服机器人就常用滑动窗口方法,保留最近5轮对话详情,之前的对话压缩成"用户咨询了退款问题"这类简短描述。LLMLingua这类专门的压缩框架会更激进,通过删除冗余token、保留关键词的方式,能在保持80%语义的情况下压缩到原来的20-30%。本质上就是提高每个token的信息密度,用户不会等你处理几万token,他们要的是秒级响应。
扩展分析
核心技术深度解析
当面试官让你详细展开技术细节的时候,其实是在考察你的知识深度和体系化思维。你不能简单罗列技术名词,而要展示出对每种技术的原理理解、应用场景判断和权衡取舍的能力。
语义压缩技术的核心思想是识别并删除冗余token,只保留承载关键语义的部分。LLMLingua是这个领域比较典型的代表,它的工作原理可以类比成给句子里的每个词打重要性分数,然后删掉那些得分低的词。比如一句话"这款手机的屏幕显示效果非常出色",压缩后可能变成"手机屏幕出色",token数从原来的15个降到6个,但核心语义还在。通常能达到50-70%的压缩率,同时保持70-85%的信息保留率,具体数值取决于文本冗余度。这种技术特别适合那种本来就比较啰嗦的文本,比如客服对话记录、产品描述这类内容,原始文本里有大量的礼貌用语和修饰词,压缩空间很大。
选择性上下文则是另一个思路,它不是简单删词,而是基于查询问题来判断哪些句子或段落该保留。实现原理是用一个小模型给每个句子打相关性分数,然后设定阈值过滤。假设有一份商品详细说明文档,用户问的是"电池续航怎么样",那么关于外观设计、拍照功能的段落就可以直接过滤掉,只保留电池规格和续航测试相关的内容。这种方法的信息保留率会更高,通常能保持90%以上的准确性,但压缩比相对保守,一般在30-50%左右。它和简单的关键词匹配的区别在于基于语义理解,能识别同义表达,比如"待机时间"和"电池续航"会被判定为相关。
检索增强技术这块是RAG系统里最核心的压缩手段,RAG的本质就是不把整个知识库塞进上下文,而是先检索出最相关的片段,这本身就是一种压缩。相关性排序是第一道关卡,通过embedding向量计算余弦相似度,把最匹配的top-k个文档片段拿出来。知识库里有1000篇文档,每篇2000 token,如果全部输入就是200万token,但通过向量检索只取top-5的文档片段,每个片段500 token,上下文就只有2500 token,压缩比达到了惊人的99.9%。实际场景中压缩比一般在90-95%之间。
重排序是第二道优化,它和初排的区别在于初排用的是轻量级embedding模型,速度快但精度有限,重排序用的是cross-encoder这种更精准但更慢的模型,对初排结果再精选一遍。这种两阶段策略在保证质量的同时控制了延迟。比如初排从1000个文档中筛出50个候选,耗时100ms,重排序从50个中精选出5个最优的,耗时200ms,总延迟300ms是可以接受的。如果直接用重排序模型处理1000个文档,延迟可能要4000ms,用户体验就崩了。

滑动窗口机制在对话场景特别实用,多轮对话会不断累积历史消息,如果不做处理,10轮对话后上下文可能就超过模型限制了。滑动窗口的做法是设定一个窗口大小,比如保留最近5轮对话,更早的对话要么丢弃,要么压缩成摘要。具体实现上可以这样设计,系统提示词500 token始终保留,最近5轮对话每轮平均200 token共1000 token,之前的10轮对话压缩成一段100 token的摘要,总上下文就稳定在1600 token左右。这种方法的好处是可预测性强,token消耗不会随着对话轮次线性增长。
摘要与重写技术这块,递归摘要是一个很经典的范式。当文档长度远超模型窗口时,可以先分块摘要,再对摘要进行二次摘要,形成金字塔结构。比如一份10万token的技术文档,先切分成20个5000 token的块,每块摘要成500 token,第一轮就压缩到1万token,然后对这20个摘要再做一次整体摘要,最终得到1000 token的精华版本。整体压缩比达到100:1,但要注意每次摘要都会有信息损失,多次递归后信息保留率可能降到60%以下。这种方法适合做文档索引或者预处理,不适合需要精确信息的场景。
Map-Reduce压缩是并行化的思路,把大文档分成多个小块并行处理,每块独立压缩后再合并,这能显著降低处理延迟,特别是在云环境下可以启动多个实例同时工作。处理100页的合同文档,串行摘要需要5分钟,用Map-Reduce拆成10个子任务并行处理,理论上只需要30秒加上合并的10秒,总共40秒就能完成。实际工程中要注意块之间的上下文连贯性,可以让相邻块有重叠区域,避免关键信息被切断。
上下文改写是更高级的玩法,不是简单删减,而是用更简洁的表达重述原文。比如用户提供了一段500字的问题描述,里面有很多口语化表达和重复内容,可以让一个小模型把它改写成100字的精炼版本,语义不变但token大幅减少。这种技术的信息保留率可以接近95%,因为是有监督的重写而不是无脑删除,但代价是增加了一次额外的模型调用,延迟会增加200-300ms。适合那种用户输入质量参差不齐的场景,比如工单系统、反馈收集这些地方。
结构化优化技术往往被忽视,但提到会显得你考虑得很全面。去重是最基础的优化,检索出来的多个文档片段可能包含重复内容,比如都引用了同一段产品规格说明,这些重复部分只保留一次就够了。可以用simhash或者Jaccard相似度检测重复片段,实践中能额外减少10-20%的token。模板化也很实用,比如多个商品的描述文本都遵循同样的结构"品牌+型号+核心参数+特色功能",可以抽取成结构化字段,用JSON格式组织比自然语言能省30%左右的token。引用压缩则是针对包含大量引用文献或者参考资料的文本,可以把完整引用替换成编号索引,需要时再展开。
谈到不同技术的权衡时,成本、延迟、准确性三者很难兼得,要根据业务场景做取舍。语义压缩类技术成本最低,只需要一次推理就能完成,延迟在50ms以内,但准确性相对较低,信息保留率70-85%。检索增强类技术准确性高,能达到90%以上,但需要维护向量数据库,有额外的基础设施成本,延迟在100-300ms。摘要重写类技术准确性居中85-90%,延迟也居中200-500ms,但会增加模型调用次数,API成本会翻倍。
场景适配的建议可以这样给,对话类应用优先用滑动窗口加选择性上下文,既保证连贯性又控制成本。文档问答系统用RAG的检索重排序组合,精准度最重要。内容生成类任务可以用摘要压缩,因为不需要逐字逐句的精确性。实时性要求高的场景避免用递归摘要这种耗时操作,选择embedding过滤这种轻量级方案。如果能针对具体业务特点,快速判断出应该用哪种技术组合,会让人觉得你不仅懂技术,还有业务sense。
工程落地与实践
如果问到"你在实际项目中会怎么落地这些技术",这是展示工程能力的好机会。回答的核心逻辑是先说怎么选技术,再展示你会写代码实现,然后强调你知道怎么监控效果,最后点出可能遇到的坑和解决办法。
谈到技术选型,可以这样组织思路:我会先看三个维度,业务场景的容错性、用户对响应速度的敏感度,还有团队的成本预算。举个文档问答系统的例子,如果是法律咨询类应用,准确性是第一位的,宁可慢一点也不能答错,这时候就该选检索加重排序的组合方案,保证召回的文档片段足够精准。但如果是新闻摘要生成,用户更在意速度,那直接用LLMLingua做语义压缩就行,即使偶尔丢失一些细节也问题不大。对话类应用就更直接了,滑动窗口几乎是标配,因为没人希望聊到第十轮突然提示"上下文超限"。
说到代码实现,可以用Python配合LangChain快速搭建一个压缩流程,这是实际项目中最常用的组合:
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain_openai import OpenAI
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
# 先准备基础的向量检索器
embeddings = OpenAIEmbeddings()
vector_store = FAISS.load_local("product_docs", embeddings)
base_retriever = vector_store.as_retriever(search_kwargs={"k":10})
# 用小模型做内容提取
llm = OpenAI(temperature=0, model="gpt-3.5-turbo")
compressor = LLMChainExtractor.from_llm(llm)
# 组装成压缩检索器
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=base_retriever
)
# 使用时只需要传入查询问题
query ="这款产品的退货政策是什么"
compressed_docs = compression_retriever.get_relevant_documents(query)
# 这时候拿到的文档已经是压缩过的,可以直接送给LLM
for doc in compressed_docs:
print(f"压缩后内容: {doc.page_content}")
print(f"原始长度: {doc.metadata.get('original_length','N/A')}")这个流程会先检索出10个相关文档,然后让GPT-3.5把每个文档里和问题相关的内容提取出来,不相关的段落直接丢弃。实测下来token数能从原来的5000降到1500左右,压缩率70%,但答案质量基本不受影响。
如果需要更精细的控制,可以自己实现一个基于相似度的过滤器:
from langchain.retrievers.document_compressors import EmbeddingsFilter
from langchain_openai import OpenAIEmbeddings
# 使用embedding相似度过滤,速度更快
embeddings_filter = EmbeddingsFilter(
embeddings=OpenAIEmbeddings(),
similarity_threshold=0.76,# 相似度阈值
k=5# 最多保留5个文档
)
# 组装压缩检索器
compression_retriever = ContextualCompressionRetriever(
base_compressor=embeddings_filter,
base_retriever=base_retriever
)这种方式的好处是不需要额外调用LLM,延迟可以控制在50ms以内,虽然压缩效果可能不如LLMChainExtractor精准,但在性能敏感的场景下是更好的选择。
监控和评估这块往往是容易忽略的点,但实际上很关键。上线后我会重点关注三个指标:压缩率、答案准确率和端到端延迟。压缩率很好算,就是压缩后token数除以原始token数,这个指标要和成本挂钩,比如原来每次调用花0.05美元,压缩到30%后只花0.015美元,一天1万次调用能省350美元。答案准确率就复杂一些,需要准备一个测试集,包含标准问题和参考答案,用BLEU或者ROUGE这类指标量化评估。我会准备200个典型问题,对比压缩前后的答案质量,如果ROUGE-L分数下降超过5%,就说明压缩太激进了,需要调整阈值。
延迟监控要拆分来看,我会在日志里埋点记录检索耗时、压缩耗时、LLM推理耗时,分别统计P50、P95、P99。如果发现P99延迟超过3秒,就要排查是不是压缩环节拖慢了速度,这时候可能要把LLMChainExtractor换成更轻量的EmbeddingsFilter,用相似度过滤代替模型提取,虽然压缩效果会差一点,但速度能提升5倍。
质量保证的测试策略可以这样讲,我会设计对抗性测试用例,专门找那些容易被压缩掉关键信息的场景。比如用户问题是"除了价格之外,这个产品还有什么优势",这里的"除了价格之外"是个重要限定条件,但在压缩过程中很可能被当成冗余词删掉,导致答案变成泛泛而谈所有优势。测试集里要包含这类带否定、排除、对比关系的复杂问题,确保压缩后的上下文还能支撑准确回答。还可以用AB测试,让一部分用户走压缩流程,另一部分走原始流程,对比用户满意度评分和任务完成率,这才是最真实的质量反馈。
成本优化的实际数据会让你的分析更有冲击力,拿一个日均10万次调用的知识库问答系统举例,原来每次平均消耗6000 token,按GPT-4的价格0.03美元/1K token算,每天成本是18000美元。上了检索加压缩方案后,平均token降到1800,每天成本5400美元,一个月能省37.8万美元。团队用省下来的预算给LLM升级到了更强的模型,整体效果反而提升了,这就是工程价值的体现。
常见问题这块一定要提前准备,过度压缩导致信息丢失是最典型的问题。我遇到过一个情况,用LLMLingua把压缩率设到80%后,发现系统经常答非所问。排查发现是压缩算法把一些关键的数字和专有名词删掉了,比如"iPhone 15 Pro Max"被压缩成"iPhone",型号信息全丢了。解决方案是给压缩器加白名单机制,把产品型号、人名、地名这类实体词标记为不可删除,调整后准确率恢复了正常。
压缩延迟过高也是个实际问题,如果压缩环节本身要花500ms,而省下来的token只能让LLM推理加快200ms,那反而得不偿失。这种情况多见于用大模型做摘要压缩的场景,调用GPT-4来压缩上下文,本身就是个昂贵又耗时的操作。解决办法是换成本地部署的小模型,或者用基于规则的压缩策略,虽然效果可能差一点,但延迟能控制在50ms以内,整体性能反而更优。
还有一个隐蔽的坑是压缩后的上下文碎片化,检索出来的5个文档片段,压缩后可能每个都只剩一两句话,拼在一起读起来很跳跃,LLM理解起来也吃力。这时候可以在压缩后加一个轻量级的连贯性优化步骤,用简单的模板把片段串联起来,比如加上"根据文档A"、"另外文档B提到"这样的过渡语句,token增加不到10%,但可读性提升明显。
系统级思考与业务价值
上下文压缩这个话题,背后考察的是你对AI应用成本结构的理解,还有你处理工程权衡问题的能力。很多人容易掉进技术细节的陷阱,讲了半天压缩算法多精妙,却没说清楚这个优化给业务带来了什么价值。
当你提到某个压缩方案能省70%的token时,可能随时会遇到追问"那你怎么判断这个压缩率是合理的"或者"准确率下降了5%可以接受吗"。这类问题没有标准答案,关键是你的分析框架。这取决于业务场景对错误的容忍度,智能客服答错一次退货政策可能导致用户投诉,但推荐系统偶尔推不准影响有限。所以我会先明确业务的准确率红线,再倒推能接受的最大压缩率,而不是盲目追求token省得越多越好。这种思路展现的是你能把技术指标转化成业务语言,而不是停留在算法层面。
对话系统的上下文动态管理是另一个值得深入的点,用户聊了一百轮怎么办,怎么判断哪些历史对话可以丢。这时候别只说滑动窗口保留最近N轮,要展示你对业务逻辑的理解。我会设计一个重要性评分机制,根据对话中是否包含关键实体、用户是否明确表达需求、系统是否给出承诺这些因素来打分。比如用户说"我要退货"的那轮对话必须保留,但中间的几轮闲聊可以压缩成一句摘要。这样既控制了token增长,又不会丢失关键信息导致服务断层。
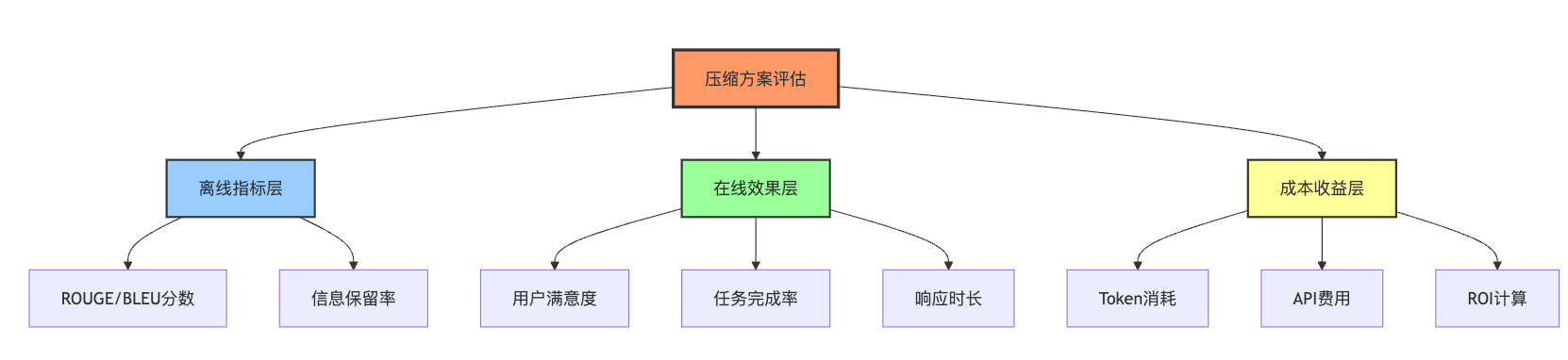
评估压缩效果需要建立三层体系,第一层是离线指标,用标注数据集测ROUGE和BLEU分数,快速验证方案可行性。第二层是在线AB测试,对比压缩前后的用户满意度评分和任务完成率,这才是真实的业务效果。第三层是成本监控,统计平均每次调用的token消耗和API费用,算出投入产出比。三个维度综合判断,避免只看单一指标导致误判。
这个优化的核心价值不只是省钱,更重要的是让AI能力能够规模化落地。如果单次调用成本太高,很多有价值的应用场景就没法商业化,比如给海量商品生成个性化描述、为每个用户提供定制化推荐理由。把token消耗降下来,就能让AI从demo变成真正的产品,服务更多用户创造更大价值。这在智能客服、文档问答这些场景特别关键,用户不会等你处理几万token,他们要的是秒级响应。
从业务视角来看,token优化和商业模式是强相关的。电商场景下,如果要给1000万个商品都配上智能问答能力,原来的方案可能每个商品每天要消耗500次查询、每次3000 token,成本完全无法承受。但通过检索压缩把单次调用降到800 token,再用缓存策略减少50%的重复查询,整体成本就能控制在合理范围内,这个功能才有可能上线。所以说技术优化最终要服务于商业价值,这是技术专家和普通工程师的区别所在。