精炼回答
代码复杂度度量主要有行数度量(LOC)、圈复杂度(Cyclomatic Complexity)、认知复杂度(Cognitive Complexity)和Halstead复杂度等方法。不过在实际工程实践中,最常用的是圈复杂度和认知复杂度这两个指标。
圈复杂度由McCabe提出,计算方式基于控制流图,公式是M = E - N + 2P(E是边数,N是节点数,P是连通分量数)。但实际编码中更简单的算法是:基础值1 + 每个判断点,判断点包括if、while、for、case、&&、||、三元运算符等。比如一个函数有3个if语句和1个for循环,圈复杂度就是1+3+1=5。这个指标关注的是代码有多少条独立执行路径,通常建议不超过10,因为它直接对应测试覆盖所需的测试用例数量。
认知复杂度是SonarSource提出的改进指标,更关注人类理解代码的难度。它的核心规则是基础结构(if、循环、catch等)+1,但嵌套时会额外累加嵌套层级,而且对break、continue这类打断线性流程的语句也会计分。比如嵌套3层的if,不仅每个if算+1,内层的if还要额外加上嵌套深度。特别的是,认知复杂度会忽略那些不增加理解负担的结构,像链式调用的&&就只算一次。这让它比圈复杂度更贴近实际的代码可读性,特别适合代码审查时评估维护成本。
扩展分析
从理论到实践:深度理解复杂度计算
代码复杂度度量这个话题其实经历了几十年的演进。最早大家就数代码行数LOC,简单粗暴但不够精准,因为一个一千行的线性流程可能比一个一百行但嵌套很深的逻辑更容易理解。后来有了Halstead复杂度,通过统计操作符和操作数来量化,但计算起来比较繁琐。真正在工程实践中广泛使用的是McCabe的圈复杂度和近些年SonarSource推出的认知复杂度。
圈复杂度的理论基础来自图论,它把代码看作一个控制流图,计算独立路径的数量。但面试时如果直接背公式,面试官可能会觉得你只是记住了定义。实际编码中完全不用画控制流图,有个更直观的算法:从基数1开始,每遇到一个判断点就加1。这里的判断点包括if、while、for、case分支、三元运算符,甚至逻辑运算符&&和||也算,因为它们会产生短路分支。
拿一个订单状态判断的场景来说明会更直观:
publicStringcheckOrderStatus(Order order){
if(order ==null){
return"INVALID";
}
if(order.isPaid()&& order.isShipped()){
return"DELIVERED";
}
if(order.isCancelled()){
return"CANCELLED";
}
for(Item item : order.getItems()){
if(item.isOutOfStock()){
return"WAITING";
}
}
return"PROCESSING";
}
这个方法的圈复杂度计算是:基数1,第一个if判空加1,第二个if加1,里面有个&&逻辑与再加1,第三个if加1,for循环加1,里面嵌套的if再加1,总共是7。这意味着要完全覆盖这个方法的所有执行路径,至少需要7个测试用例。
圈复杂度有个明显的问题,它对所有判断点一视同仁,但实际上代码嵌套越深,人理解起来的负担是指数级增长的。SonarSource就基于这个洞察提出了认知复杂度,核心思想是量化人类理解代码的认知成本。看两段代码对比会更清晰:
// 平铺结构
publicvoidprocessFlat(Order order){
if(order.isPaid()){
sendEmail();// +1
}
if(order.isShipped()){
updateInventory();// +1
}
if(order.isDelivered()){
requestReview();// +1
}
}
// 圈复杂度: 1 + 3 = 4
// 认知复杂度: 1 + 1 + 1 = 3
对比嵌套结构:
// 嵌套结构
publicvoidprocessNested(Order order){
if(order.isPaid()){// +1
if(order.isShipped()){// +2 (基础+1 + 嵌套深度1)
if(order.isDelivered()){// +3 (基础+1 + 嵌套深度2)
requestReview();
}
}
}
}
// 圈复杂度: 1 + 3 = 4
// 认知复杂度: 1 + 2 + 3 = 6
两段代码的圈复杂度都是4,但认知复杂度差异明显。嵌套结构的认知复杂度是6,因为每深入一层嵌套,就要在脑子里维护更多的上下文状态。这就是为什么我们常说"扁平化代码",因为嵌套确实增加了理解成本。
关于逻辑运算符的处理差异也值得注意。认知复杂度认为连续的&&或||是一个逻辑整体,人在阅读时不会因为多一个条件就大幅增加理解成本:
// 连续的逻辑判断
if(user.isActive()&& user.isVerified()&& user.hasPermission()){
grantAccess();
}
// 圈复杂度: 1 + 1 + 2 = 4 (每个&&都算)
// 认知复杂度: 1 (连续的&&只算一次)
但如果是&&和||混用,比如(a && b) || (c && d),那每个逻辑运算符都会计分,因为这确实增加了理解难度。业界普遍的建议是圈复杂度不超过10,超过15就应该强制重构。这个标准主要是从测试覆盖的角度来的,因为圈复杂度直接对应独立路径数,数值太高意味着测试成本会激增。认知复杂度的阈值相对灵活一些,SonarQube默认是15,但实际项目中会分场景设定,核心业务逻辑通常控制在10以内,因为这些代码变更频繁,可维护性更重要。
下面这个流程图展示了两种复杂度的计算差异:
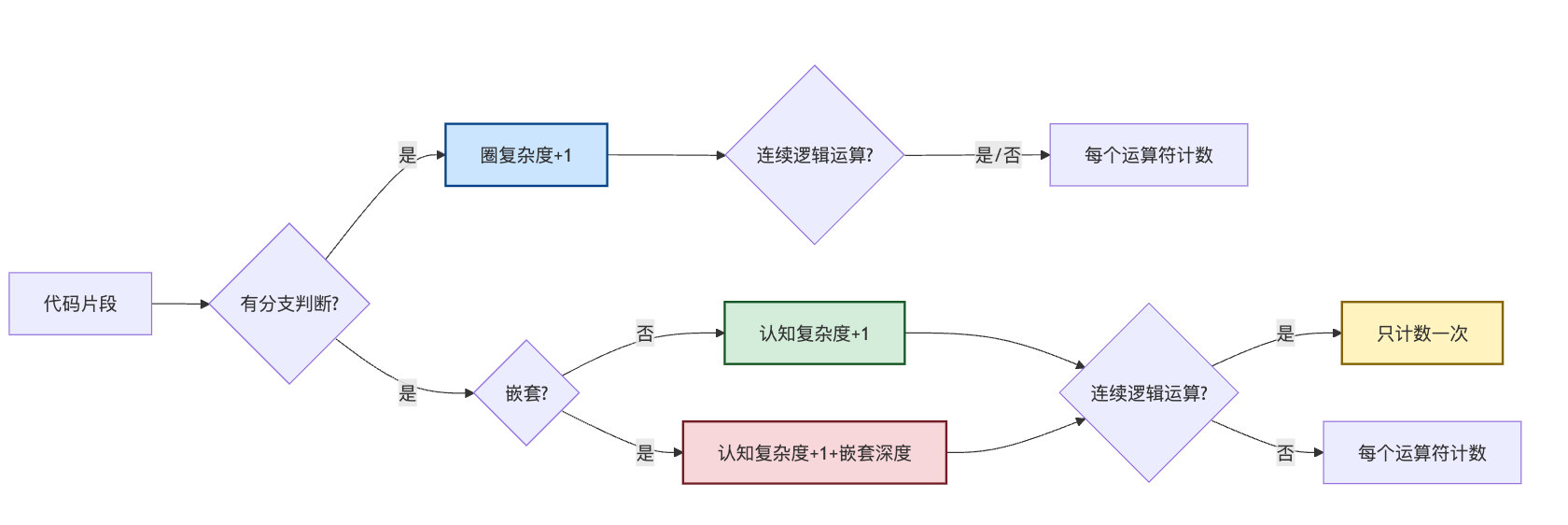
工程实践:让度量指标真正落地
在做Code Review的时候,不应该一上来就指出哪里逻辑写得不好,而是先看一眼复杂度报告。如果某个方法圈复杂度超过10,重点关注它的测试覆盖率够不够,因为高复杂度的代码最容易藏bug。如果认知复杂度特别高,比如超过15,就需要建议重构,因为这种代码后续维护成本太高。
我们团队主要用SonarQube做静态代码扫描,它同时支持圈复杂度和认知复杂度的检测。在CI流程中,会把这两个指标配置成Quality Gate的一部分。比如圈复杂度超过15直接拦截构建,这是硬性红线;认知复杂度超过20会发出警告,要求在代码提交说明里解释为什么这么写。如果是前端项目,ESLint有complexity插件可以检查圈复杂度;Java项目除了SonarQube,Checkstyle也能配置圈复杂度规则。
遇到高复杂度代码的重构策略要分场景考虑。圈复杂度高通常是分支太多,可以用提取方法、策略模式或者表驱动来化解。认知复杂度高往往是嵌套太深,这时候卫语句、提前返回、反转条件这些技巧就很有用。拿订单校验的场景举例:
// 重构前:嵌套地狱,认知复杂度12
publicbooleanvalidateOrder(Order order){
if(order !=null){
if(order.getItems()!=null){
if(!order.getItems().isEmpty()){
if(order.getTotalAmount()>0){
if(order.getCustomer()!=null){
return order.getCustomer().isActive();
}
}
}
}
}
returnfalse;
}
// 重构后:卫语句扁平化,认知复杂度5
publicbooleanvalidateOrder(Order order){
if(order ==null)returnfalse;
if(order.getItems()==null)returnfalse;
if(order.getItems().isEmpty())returnfalse;
if(order.getTotalAmount()<=0)returnfalse;
if(order.getCustomer()==null)returnfalse;
return order.getCustomer().isActive();
}
制定复杂度标准不能一刀切,要分场景。核心业务逻辑会卡得严一些,圈复杂度不超过8,认知复杂度不超过12,因为这些代码变更频繁,必须保证可读性。工具类或者配置代码可以放宽到15,因为它们往往是一次性写好后就很少改动。新规范推行的时候不能强制要求存量代码立刻达标,可行的做法是先扫描出所有超标的代码,标记为技术债务,然后要求新增代码和改动超过30%的文件必须符合标准。这样既不影响开发节奏,又能逐步改善代码质量。
复杂度指标其实是量化技术债务的一个很好的维度。定期生成一份复杂度热力图会很有帮助,横轴是代码修改频率,纵轴是复杂度数值,落在右上角的那些代码就是重构的优先级最高的,因为它们既复杂又经常改,最容易出问题。这样能让重构工作变得有的放矢,而不是凭感觉乱重构一通。
更深层的思考:度量之外的质量管理
推动质量改进最难的不是技术问题,而是怎么让团队接受改变。经验表明先做可视化,让问题浮出水面效果最好。比如把复杂度数据接入团队的仪表盘,让每个人看到自己写的代码在团队里的排名,这比开会说教有效得多。然后分阶段推进,先对新增代码和热点代码卡标准,避免一上来就要求存量代码全部达标引起反弹。
历史遗留代码不能一概而论,要看它的改动频率和业务重要性。如果是那种写好之后就再也不动的配置类代码,即便复杂度高也可以暂时容忍,毕竟重构的投入产出比不划算。但如果是核心业务逻辑,每次需求迭代都要改,那就得下决心重构,否则每次改动都是在刨坑。通常会建议用"绞杀者模式",不是推倒重写,而是每次改需求的时候顺带重构一部分,逐步把复杂度降下来。这样既不影响业务迭代速度,又能持续改善代码质量。
复杂度度量确实有盲区。比如一个方法只有几个if,复杂度不高,但如果每个分支里调用的外部依赖特别多,或者有复杂的状态变更,维护起来照样很痛苦。再比如有些业务逻辑天然就复杂,像税务计算、促销规则引擎这种,想把复杂度降到10以下不太现实,强行拆分反而会降低可读性。所以应该把复杂度指标当作预警信号,而不是绝对标准,超标了需要去review具体代码,看是业务本身复杂还是设计有问题。
我之前参与过一个核心交易系统的重构,当时代码扫描出来有个方法圈复杂度高达42,团队都觉得没法改。我们分析了修改历史,发现这个方法过去一年改了十几次,每次上线都提心吊胆。后来主导把它拆成了状态机模式,每个状态对应一个处理器,复杂度降到个位数。重构之后不光测试覆盖率上去了,新人也能快速理解业务流程。这件事让人意识到,复杂度度量的价值不在于数字本身,而在于它能帮你识别出那些最值得投入精力去优化的代码。
现在大模型在代码质量领域的应用越来越成熟了,不只是简单的代码补全。有些团队开始用AI来做复杂度分析,让模型不仅标出高复杂度代码,还能解释为什么复杂、给出重构建议。甚至可以让AI生成测试用例覆盖那些复杂的分支逻辑。虽然现阶段还不能完全信任模型的输出,但作为辅助工具确实能提升效率。
现在很多团队会在代码扫描工具里同时配置这两个指标。圈复杂度作为硬性卡点,超过阈值直接拦截合并请求;认知复杂度作为重构优先级的参考,标记出那些虽然测试路径不多但理解成本高的代码。这样既能保证测试覆盖率,又能维护代码的可读性。特别是在多人协作的场景下,新成员接手代码的学习曲线会平滑很多。这种体系化的质量管理思路,才是真正能提升团队效率的关键所在。