精炼回答
涌现能力是指大语言模型在参数规模达到某个临界点后,突然表现出小规模模型完全不具备的能力,这种能力的出现是不可预测的,呈现跨越式跃升而非线性增长。简单说,就是模型变大到一定程度后,会"突然学会"做之前完全做不了的事情,像是一个质变的过程。
这种现象最典型的表现在少样本推理任务上。比如在算术推理中,GPT-3的小版本模型答题准确率基本为零,但当参数量超过100B后,准确率突然跳到40%以上。多步推理能力也是如此,像解决需要逻辑链条的数学应用题,小模型给出的完全是随机答案,大模型却能正确分解步骤并得出结果。再看代码理解和生成能力,在某个规模阈值之前模型只能输出语法错误的片段,跨过阈值后就能写出可运行的完整函数。
另一个重要例子是指令遵循能力,小模型对"用JSON格式输出"这类指令基本无法理解,大模型则能准确执行复杂的格式化要求。值得注意的是,涌现能力的出现阈值因任务而异,某些任务可能需要更大的规模才会涌现。这种现象目前还没有完全的理论解释,是大模型研究中最令人着迷也最难预测的特性。涌现能力的发现说明模型规模不只是性能的线性提升,更可能带来能力的质变,这也是为什么业界持续投入算力扩大模型规模的核心原因。
扩展分析
从复杂系统理论理解涌现
"涌现"这个词其实来自复杂系统理论,描述的是当系统达到一定复杂度时,会突然出现整体层面的新属性,这些属性无法从单个组件推导出来。就像单个水分子不具备"湿"的属性,但无数水分子聚在一起就涌现出了液态水的流动性和湿润性。大模型的涌现能力也是这样,不是每个参数变聪明了,而是整个系统到达临界规模后,突然展现出全新的智能特征。
正常的模型性能提升是平滑曲线,比如准确率从60%涨到70%再到80%。但涌现能力的曲线完全不同,它更像一个阶跃函数——模型规模在某个阈值之前,任务表现几乎是随机猜测的水平,可能就5%的准确率;一旦跨过那个临界点,瞬间跳到50%甚至更高。用坐标图来看的话,横轴是参数量,纵轴是任务准确率,涌现能力的曲线会呈现一个近乎垂直的跳跃,而不是斜向上的平滑增长。
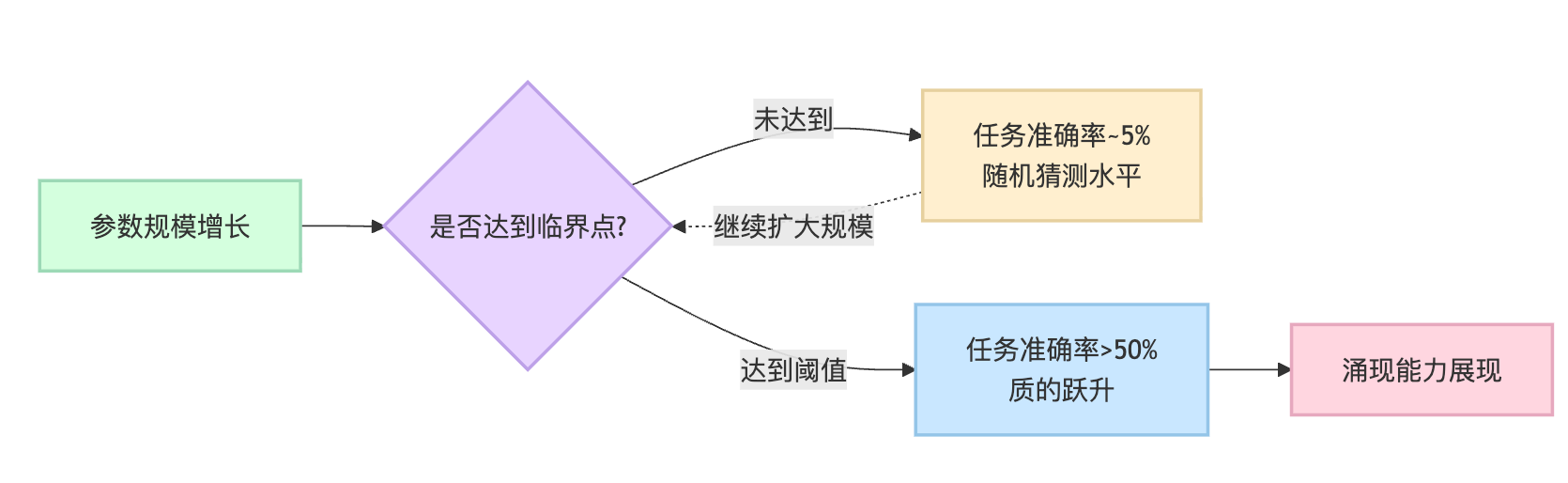
学术界一般把涌现能力归为三大类,背后对应着语言模型的不同智能层次。推理能力的涌现包括数学推理、逻辑推断、常识推理等。拿算术问题举例,给模型一道小学应用题"小明有15个苹果,给了小红3个,又买了8个,现在有多少个?"小规模模型往往直接输出一个随机数字,它根本不理解这需要连续的加减运算。但大模型会展现出步骤分解能力,它能理解"先减后加"的逻辑链条,甚至在输出时写出"15-3=12, 12+8=20"这样的中间步骤。
指令理解和遵循能力的涌现特别有意思,因为它直接关系到模型的可控性。比如你让模型"用JSON格式输出包含姓名、年龄、城市的用户信息",小模型可能就返回一段自然语言描述,完全忽略格式要求。但达到涌现阈值的大模型,不仅能输出正确的JSON结构,还能处理更复杂的嵌套指令,像"先总结这段文字,然后翻译成英文,最后用表格形式对比中英文的关键词"。这种能力对工业界特别重要,因为它决定了模型能否真正集成到产品流程中。
最高层次的涌现是知识整合和创造性任务,代码生成就是典型代表——不只是记忆代码片段,而是理解需求、设计逻辑、组合语法。举个具体例子,如果你给模型需求说"写一个函数检查字符串是否是有效的邮箱地址",小模型可能输出语法错误的伪代码或者简单的子串匹配。但涌现了代码能力的大模型会写出这样的完整实现:
publicbooleanisValidEmail(String email){
if(email ==null|| email.trim().isEmpty()){
returnfalse;
}
String regex ="^[A-Za-z0-9+_.-]+@[A-Za-z0-9.-]+\\.[A-Za-z]{2,}$";
return email.matches(regex);
}注意这里模型展现了多层次的理解——它知道需要空值检查、理解正则表达式的语法、懂得邮箱的基本格式规则,并且能用Java的标准库方法组合这些知识。这不是简单的模板填充,而是真正的知识整合。
涌现能力虽然强大但也有明确的局限性。比如数学推理方面,大模型能处理需要3-5步推理的问题,但面对需要十几步严密逻辑的复杂证明,准确率会断崖式下降。再比如代码生成,涌现的能力集中在100行以内的函数级代码,一旦涉及跨文件的系统级架构设计,模型就会出现逻辑断裂。这种实事求是的认知很重要,能帮助我们在实际应用中设定合理的期望。
学术界对涌现能力的机制其实还没有达成共识,但有几个主流的解释方向。一种观点认为,随着参数量增加,模型的表征空间维度扩大,当维度达到某个临界值时,突然能够编码任务所需的复杂模式。就像你需要至少三维空间才能表示一个球体,二维平面无论如何优化都做不到。还有研究认为,涌现可能和训练数据中的长尾知识有关。小模型容量有限,只能学习高频模式;大模型才有余力记住那些低频但关键的知识组合,而复杂任务恰恰需要这些稀疏知识的激活。
最近有一些研究提出了不同的看法,认为涌现能力可能部分是度量方式造成的假象。比如斯坦福的一篇论文指出,如果把评估指标从准确率改成交叉熵或其他连续度量,某些看似涌现的能力曲线会变得平滑。不过即使考虑度量因素,大模型在某些任务上从完全不能到基本可用的质变是客观存在的,只是我们需要更谨慎地定义什么算真正的涌现。
实践应用场景
涌现能力最直接的应用价值体现在复杂任务的自动化上。拿智能客服举例,传统的小模型只能做关键词匹配和简单问答,用户问"我的订单为什么还没发货",它只能回复预设的模板。但具备涌现能力的大模型能展现真正的推理能力——它会理解用户背后的意图,主动查询订单状态,判断是因为仓库缺货还是物流延迟,然后给出针对性的解决方案。这里的区别不是回复更流畅,而是模型突然具备了多步推理和知识整合能力,这正是涌现带来的质变。
理解涌现能力后,我们在设计AI应用时思路会完全不同。关键是要识别哪些任务依赖涌现能力,哪些不需要。如果是简单的文本分类或情感分析,其实7B左右的模型就够用,因为这些任务不需要复杂推理。但如果是生成商品详情页——需要理解产品特性、提炼卖点、组织结构化内容——这就必须用到具备涌现能力的大模型,因为小模型根本无法完成这种知识整合任务。
涌现能力对prompt设计的指导意义在于,大模型能理解复杂的上下文指令,这让我们可以用更精细的提示词来控制输出。比如让模型生成营销文案,对小模型你只能说"写一段产品介绍",它可能就随机输出一些描述性语句。但对大模型,你可以设计这样的prompt:"你是一位资深文案策划,请为这款智能手表撰写详情页文案。要求:第一段用场景化开头吸引读者,第二段列举三个核心功能并说明用户价值,第三段用对比凸显竞品优势,最后用促销信息收尾。语气专业但亲和,避免夸张词汇。"大模型能准确执行这种嵌套的、多约束的指令,而这正是涌现的指令遵循能力在发挥作用。
实际项目中不是所有场景都用最大的模型,而是要根据任务复杂度阶梯式选择。对于FAQ问答、简单改写这类任务,用7B到13B的模型就足够,响应速度快成本也低。需要多步推理的场景,比如根据用户画像生成个性化推荐理由,就得上到30B以上的模型。而真正复杂的任务——像是理解长篇客户反馈然后生成结构化分析报告——可能需要用到70B甚至更大规模的模型,因为这涉及长文本理解、信息抽取、逻辑归纳等多种涌现能力的组合。通常的做法是先用小模型快速过滤和分类,把真正复杂的case再路由到大模型,这样能平衡效果和成本。
涌现能力虽强但有明确边界,实际使用时需要特别注意几个陷阱。不稳定性是首要问题,同样的prompt在不同时候可能得到质量差异很大的输出,因为涌现能力不像传统算法那样可以精确控制。这就要求我们在产品设计时必须加入人工审核环节或者置信度检测。任务边界问题也很关键,大模型在某个能力上的涌现不代表相关能力都涌现了。比如模型能写代码,不代表它能做代码安全审计;能做文本摘要,不代表它能准确识别法律条款中的风险点。实际应用时要针对具体任务做充分测试,不能想当然地泛化。
判断模型是否真的具备某项涌现能力,不能只看demo效果,要设计系统的测试集。比如测试推理能力,需要准备不同复杂度的问题集——从两步推理到五步推理,观察准确率曲线是否出现阶跃。如果准确率随难度平滑下降,说明只是模式匹配;如果在某个复杂度阈值前后出现断崖,才能确认涌现能力的边界在哪里。
未来趋势与思考
涌现能力的发现改变了AI研究的范式。过去我们相信只要有足够标注数据,针对性地训练模型就能解决特定问题。但涌现现象告诉我们,也许不需要为每个任务单独训练模型,只要把基座模型做得足够大,它自然会涌现出处理多种任务的能力。这直接催生了Foundation Model这个方向——用一个超大规模的通用模型作为基础,然后在上面适配各种下游任务。不过这也带来了新的问题,就是算力集中化的趋势。如果真正有用的AI能力只有达到千亿参数才会涌现,那能训练这种模型的机构会越来越少,这对整个AI生态的影响值得关注。
关于可预测性问题,目前来看,涌现能力在具体任务上的阈值还很难精确预测,但scaling law给了我们一些方向性的指引。比如根据训练数据量、模型参数量和计算量的关系,我们能大致预估模型整体能力的上限,但具体哪个任务会在什么规模涌现,仍然充满不确定性。这种不可预测性其实带来了工程上的两难——你很难事先知道投入多少算力能获得期望的能力,只能通过实验不断试探。这也是为什么OpenAI、Google这些公司都采用阶梯式扩展策略,先训练中等规模模型验证方向,再决定是否投入更大算力。
实际接触过智能推荐系统后,对涌现能力的理解会更具体。小模型做推荐基本靠统计规律,比如看历史点击率、协同过滤,它不理解用户为什么喜欢某个商品。但把大模型引入推荐系统后,出现了很有意思的现象——它突然能理解商品之间的深层关联。比如用户浏览了登山装备,模型会推荐户外摄影器材,不是因为两者经常被一起购买,而是它理解了"喜欢户外运动的人可能也喜欢记录风景"这种抽象关联。这种跨品类的深层推理能力,就是典型的涌现表现。
Scaling law确实揭示了模型性能和规模之间的幂律关系,但它主要描述的是整体损失函数的下降趋势,对具体能力的涌现预测力有限。而且最近的研究发现,scaling law可能在某些任务上会遇到瓶颈。比如需要严密逻辑推理的数学证明,可能不是简单扩大规模就能解决的,还需要在模型架构或训练方法上做突破。这种认识能让我们保持清醒,不盲目相信大力出奇迹。
涌现能力虽然令人兴奋,但也要警惕过度解读。有些看似神奇的涌现,可能只是因为我们的评估方式恰好在某个阈值附近变得敏感。而且大模型的涌现能力往往伴随着巨大的不确定性和成本,在实际产品中我们还是要根据具体需求选择合适的技术路线,不能为了追求涌现能力而盲目使用大模型。理解涌现能力的关键,不是记住具体的阈值数字,而是理解规模扩大可能带来质的跃升,这种认知会直接影响我们在工程中如何选择模型和设计系统架构。