精炼回答
RAG系统支持多模态检索的核心在于将不同模态数据映射到统一的向量空间。这不是简单地支持多种数据类型,而是让图像和文本能够真正"对话"——用户上传一张图片能找到相关文字描述,输入文字能召回相关图像。具体来说,你需要使用多模态编码器(如CLIP、BLIP等)分别对文本、图像进行编码,这些编码器经过对比学习训练,能够让语义相关的图文在向量空间中距离更近。
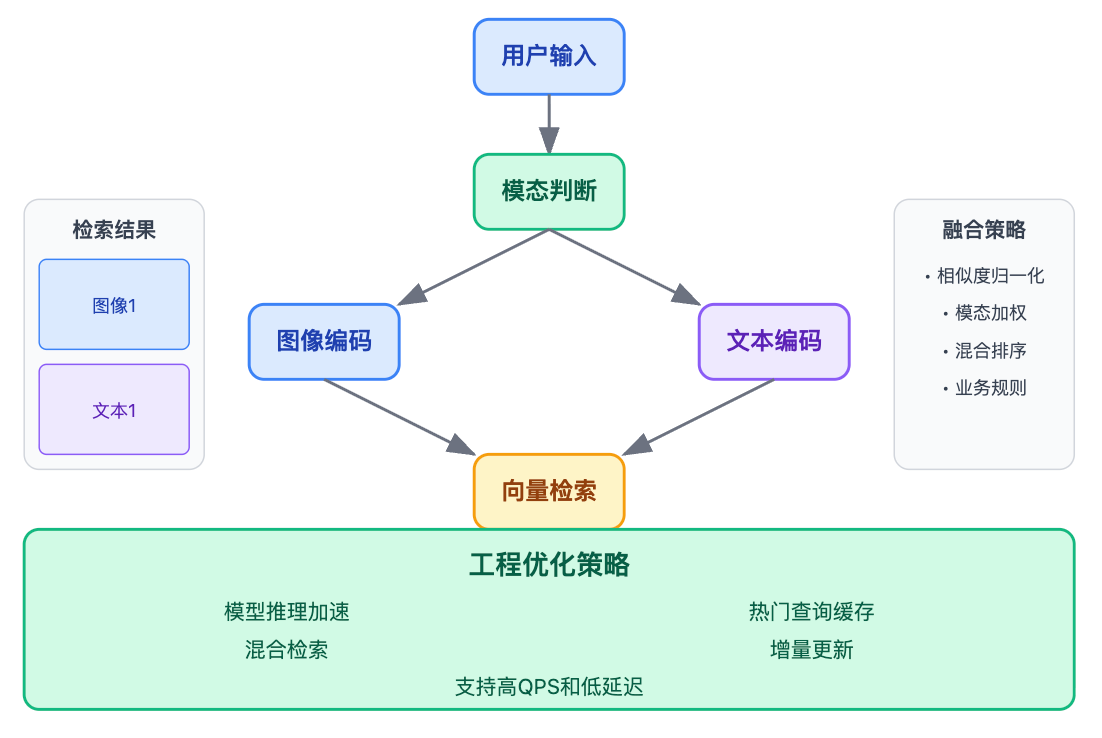
图文检索的实现流程分三步走:第一步是建立索引,用多模态编码器把知识库里的图片和文本分别编码成向量,存入支持多模态的向量数据库,同时打上模态标签。第二步是查询处理,用户无论输入图片还是文本,都用同一个编码器转成向量。第三步是跨模态检索,在向量空间做相似度匹配,这时图查文、文查图就自然实现了。
实际应用中效果非常直观。比如医疗影像分析系统,医生输入"肺部结节"这个文本查询,系统不仅能返回相关的病历文本,还能检索出相似的CT影像及其诊断报告。或者在电商场景,用户上传一张商品图片,系统能同时召回相似商品图片和对应的商品描述文本。技术栈上主要涉及三块:编码器层用CLIP或BLIP这类多模态模型,存储层用Milvus或Weaviate这种原生支持多模态的向量数据库,检索层还需要考虑模态融合策略,比如是在特征层面融合还是结果层面做重排序。
扩展分析
从单模态到多模态的本质跨越
理解多模态RAG首先要明白它和传统文本RAG的本质区别。传统文本RAG处理的是同质数据,用BERT这类文本编码器把一段话编码成768维向量,查询的时候也用同样的编码器把问题变成768维向量,然后做余弦相似度计算。这个过程完全工作在文本空间里,非常简单直接。但如果我们的知识库里有图片呢?最直观的想法可能是给图片配文字描述,然后检索这些描述,但这样就丢失了图像本身的视觉信息,而且也无法支持用户直接上传图片来检索。
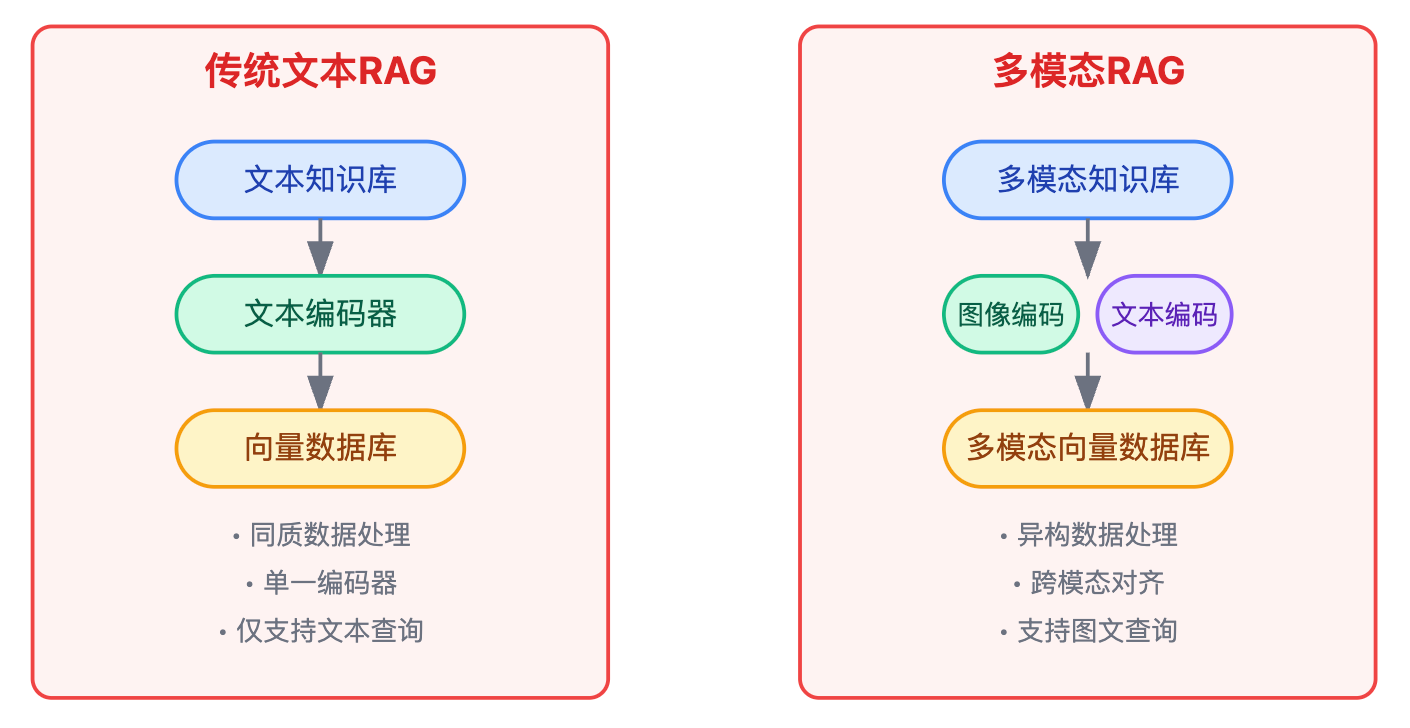
多模态的本质是要在高维空间里建立一种映射关系,让描述同一个事物的图片和文字在空间中靠得很近。比如一张猫的照片和"一只橘色的猫趴在沙发上"这段文字,虽然它们的原始数据完全不同——一个是像素矩阵,一个是token序列,但在经过特殊设计的编码器处理后,它们的向量表示应该距离很近。这就是所谓的跨模态对齐,这个概念是整个多模态RAG系统的理论基础。
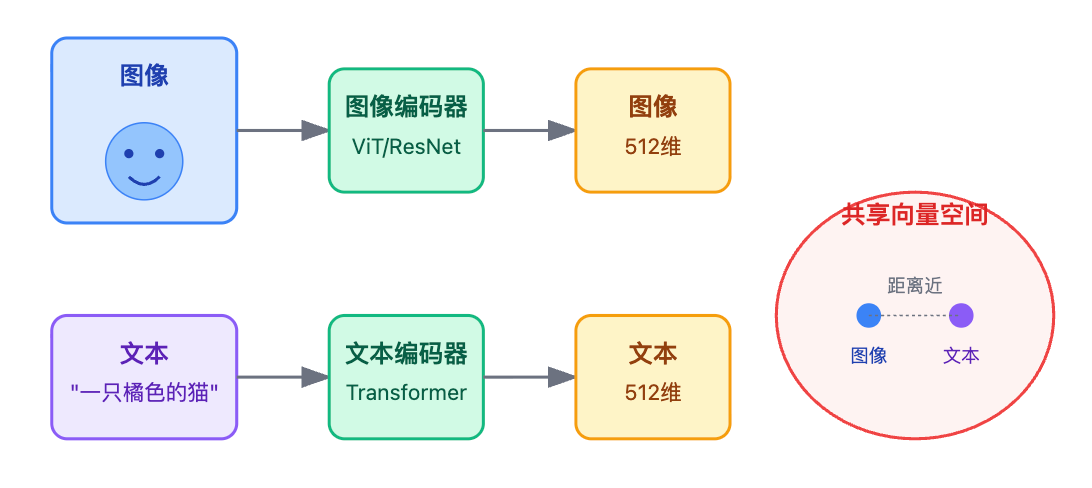
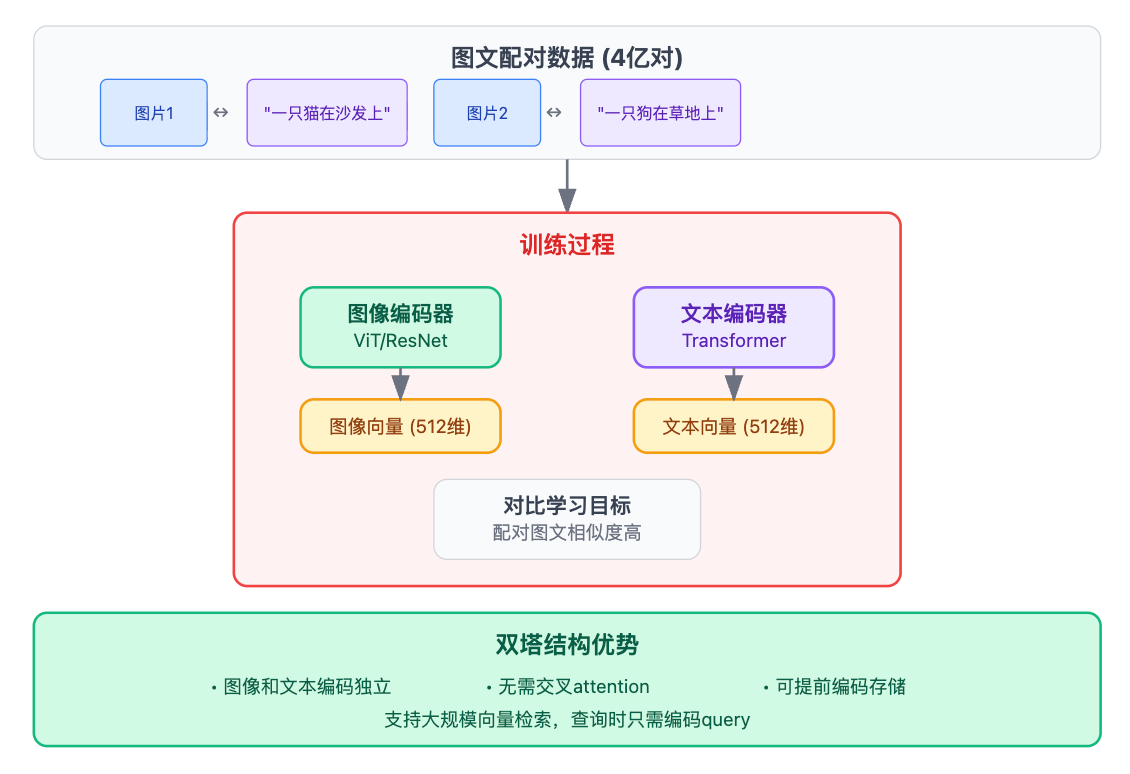
实现这种对齐的关键是对比学习,CLIP就是个典型例子。它的训练方式很巧妙——准备大量的图文配对数据,比如4亿对图片和对应的描述文字。训练时用两个编码器,一个图像编码器处理图片(通常是ViT或ResNet),一个文本编码器处理文字(通常是Transformer),它们各自输出向量。训练目标是让配对的图文向量相似度高,不配对的相似度低。具体来说,一个batch里如果有1000对图文,那每张图片的向量要和它对应的文字向量距离最近,和其他999个文字向量距离尽可能远。
这种双塔结构的设计有个巨大的优势:图像和文本的编码过程是独立的,不需要交叉attention,所以可以提前把知识库的所有图文都编码好存起来。查询的时候只需要编码query,然后做向量检索就行,速度很快。如果采用early fusion的方式,每次查询都要把query和候选文档拼一起送进模型,那在百万级知识库上根本不可行。从工程角度看,这种架构能够让我们在检索性能和语义理解之间找到平衡点。
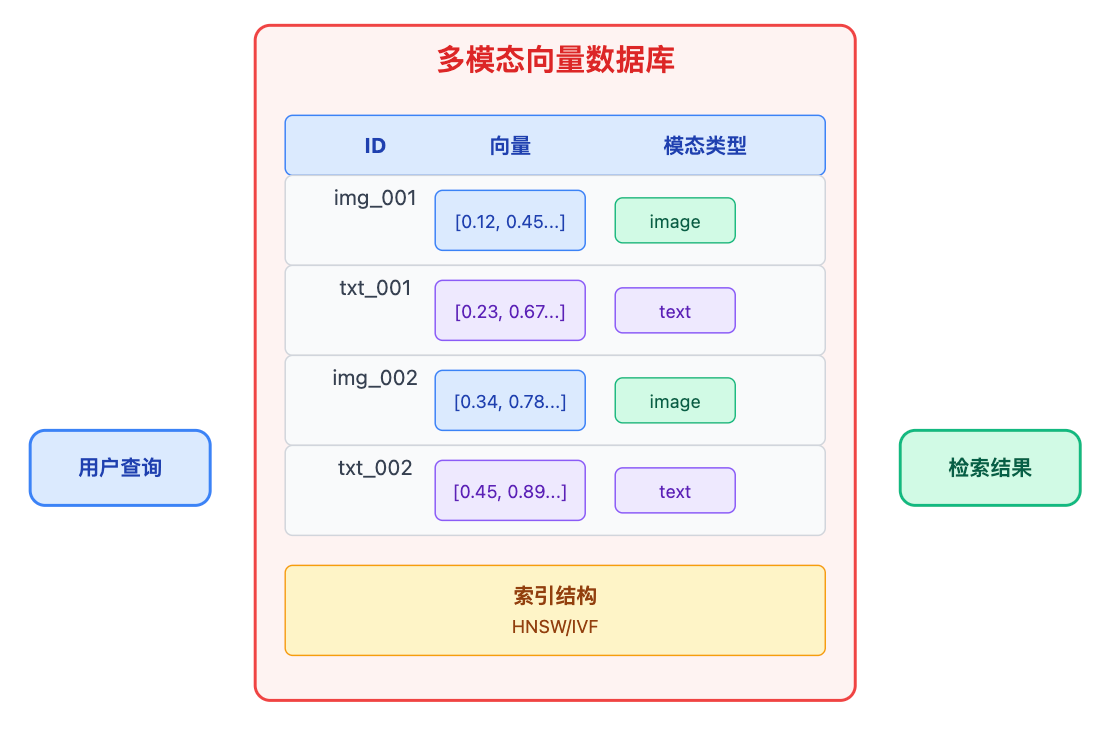
多模态向量库和单模态的主要区别在于需要记录模态类型。比如Milvus在建索引时,除了存512维的向量,还会有个metadata字段标记这条数据是image还是text,以及它的原始ID。这样做有两个好处:一是可以做模态过滤,比如用户只想看图片结果;二是在结果融合时可以根据模态类型做不同的后处理。
和传统文本RAG相比,多模态RAG的架构复杂度主要体现在三个地方:编码器从单个变成了两个,而且需要保证它们的输出空间是对齐的;向量库需要支持多模态元数据管理;检索后的结果处理更复杂,因为要处理跨模态的相关性计算。但核心的检索逻辑——基于向量相似度召回——是没变的,这也是为什么RAG能比较平滑地扩展到多模态场景。
实战落地中的工程实践
生产环境最大的挑战其实是QPS和延迟。假设系统要支持1000 QPS,单次CLIP推理大概50ms,向量检索10ms,这样算下来单机根本扛不住。优化思路要从三个方向入手。第一是模型推理加速,用TensorRT或者ONNX Runtime把CLIP模型量化到INT8,推理速度能提升2-3倍,对精度影响不大。第二是加缓存,把热门query的向量缓存在Redis,省去重复编码的开销。第三是混合检索,不是所有query都要走向量召回,可以先用商品类目做粗筛,把候选集从百万降到几万,然后再做精排。
实际落地中有几个坑值得注意。
第一个是冷启动问题,新上架的商品可能没有足够的图文配对数据,CLIP编码出来的向量质量不稳定,需要人工标注一些种子数据做微调。
第二个是模态不平衡,如果商品库里图片占90%,文本只占10%,检索时容易偏向图片结果,需要在重排序时做模态均衡。
第三个是向量更新策略,商品信息会变化,向量也要更新,全量重建成本太高,得设计增量更新机制,比如每天凌晨只更新变更的商品。上线后要盯着召回率和响应时间两个指标。召回率可以通过人工标注的测试集来离线评估,比如准备1000个query,看top10结果里相关商品的占比。响应时间要在Milvus查询日志里统计P99延迟,如果超过100ms就得排查是索引参数不合适还是数据倾斜。
进阶思考与未来演进
垂直领域的创新应用展现了多模态RAG更大的想象空间。
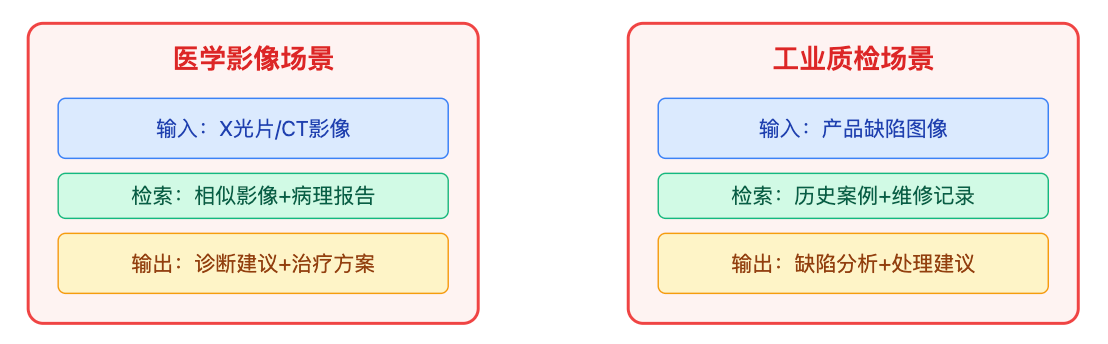
在医学影像领域,多模态RAG不仅仅是检索相似病例这么简单。医生上传一张X光片,系统能召回相似影像的同时,还能关联到病理报告、治疗方案、用药记录这些文本信息。
工业质检场景也很有代表性,制造业的缺陷检测系统,不仅要识别当前产品的瑕疵,还要从历史数据库里找到类似案例,看当时是怎么处理的。这时候图文检索的价值在于把视觉异常和对应的维修工单、工艺调整记录关联起来,形成可追溯的知识闭环。
从技术演进的角度看,下一个阶段很可能是多模态大模型和RAG的深度结合。现在CLIP这类模型主要做语义对齐,但推理能力有限。像GPT-4V这种视觉语言模型出现后,我们可以把检索和生成更紧密地结合——不只是召回相关图文,而是让模型理解检索回来的多模态内容,生成更精准的答案。比如用户问"这个商品适合什么场合穿",系统不仅要检索商品图和描述,还要理解图片里的款式风格,结合文本里的材质信息,最后生成个性化的搭配建议。这种从检索到理解再到生成的完整链路,才是多模态AI真正释放价值的方向。