精炼回答
大模型数数困难的核心原因在于tokenization机制与自回归生成特性的矛盾。当你问"strawberry有几个r"时,模型首先会把"strawberry"切分成token,可能是["str", "aw", "berry"]这样的子词单元,而不是单个字符。模型在预训练时学习的是token之间的统计关联,并没有真正"看到"每个独立字符。它需要在高维语义空间中推理字符级别的信息,这超出了它的优化目标。
更深层的问题是模型是逐token预测的,它在生成答案时依赖的是概率分布,而不是执行确定性的计算过程。数数需要的是类似循环遍历的算法逻辑:逐个扫描、匹配、累加计数器。但Transformer架构的并行注意力机制本质上是在做模式匹配和概率推断,缺少这种显式的计算能力。这就像让模型做算术题一样,"123456 * 789"它也容易算错,因为它不是真的在"计算",而是在回忆训练数据中相似问题的答案模式。对于字符计数这类需要精确操作的任务,模型只能通过海量样本学到一些近似的启发式规律,但面对具体实例时经常失效。
扩展分析
tokenization如何导致字符"失明"
面试官抛出"strawberry有几个r"这种问题,其实是在考察你对大模型底层机制的理解深度。这个问题的本质是tokenization机制导致模型无法"看见"独立字符。就像strawberry会被切分成straw-berry这样的子词单元,模型处理的是这些token的语义关联,而不是字符级别的精确信息。
tokenization就像是给文本做压缩编码。模型不直接处理原始文本,而是先把它切成一个个有意义的片段。比如strawberry这个词,常见的分词器可能切成'straw'和'berry'两个token,因为这两个片段在英文里出现频率高,语义也相对独立。问题在于,当模型看到'straw'这个token时,它接收到的是一个整体的语义单元,就像看到数字65535一样,它不会自动知道这里面包含几个1或几个5。字符'r'的信息被编码到token的高维向量表示里了,但这不是以字符计数为目标的编码方式。
这就像你问我"篮球这个词有几个木字旁",我得先把篮球两个字在脑子里拆成偏旁部首,再去数。但大模型训练的时候,优化目标是预测下一个token,不是预测下一个字符或数偏旁,所以它的"视觉系统"天然就不适合干这个活。这和人类数数完全不同,我们是逐个字符扫描匹配,但模型是在高维语义空间里回忆训练数据中类似问题的答案模式。
有人可能会问,那为什么不直接用字符级别的模型呢?这其实是个工程上的权衡。用字符级处理的话,'strawberry'要变成10个输入单元,一句话可能就是几百个字符。Transformer的自注意力机制计算复杂度是序列长度的平方,这会让训练成本爆炸。更重要的是,NLP任务的核心是理解语义,用subword级别的token既保留了词汇的语义信息,又能处理未登录词。比如'unbelievable'可能切成'un-believ-able',模型能从前缀和后缀学到语法规律。这种设计在翻译、问答这些任务上效果很好,字符计数只是个边缘场景。
需要澄清一个常见误区——大模型不是看不到字符信息。原始训练数据确实包含完整的字符序列,问题在于处理粒度。输入文本先被tokenizer切分,模型的注意力机制、位置编码、预测目标都是在token序列上操作的。字符信息被压缩编码到token的embedding向量里了,但模型没有针对字符级操作做优化。举个例子,当BPE分词器把'strawberry'切成两个token后,每个token会映射到一个768维的向量(以BERT为例)。这个向量是通过海量文本训练出来的,它编码了这个token在各种上下文中的语义特征。但这768个数字里,并没有哪一维明确表示"这个token包含几个r"。模型要回答这个问题,只能通过在预训练时见过的类似模式去推断,而不是执行确定性的字符遍历算法。
概率推断vs确定性计算的本质鸿沟
回到strawberry这个例子,模型出错的根源不是智能不够,而是架构设计时的目标就不是为了处理这类精确符号操作。这就像你不会用深度学习模型去实现排序算法一样——不是做不到,而是杀鸡用牛刀,还容易出错。模型是在做概率推断而非确定性计算,这个矛盾在所有需要精确符号操作的任务上都会暴露。
比如多位数算术运算,你问模型"47832乘以6391等于多少",它大概率算错,因为它不是在执行竖式计算,而是在回忆训练数据里相似题目的答案。再比如复杂的逻辑推理,像"如果A大于B,B大于C,C大于D,那么A和D谁大"这种传递性推理,模型也容易在中间步骤出错。本质上都是同一个问题:模型缺少显式的符号操作能力。
电商场景里也会遇到类似问题。用户问"这件商品打7.5折后再满减50,最终多少钱",模型如果直接回答,很可能算错价格。靠谱的做法是让模型先提取出原价、折扣、满减条件这些结构化信息,然后调用价格计算服务来处理。这引出了一个通用的工程原则:把大模型当作语义理解和任务编排的中枢,但具体的符号操作、数值计算、数据库查询这些确定性任务,应该路由给专门的工具来执行。
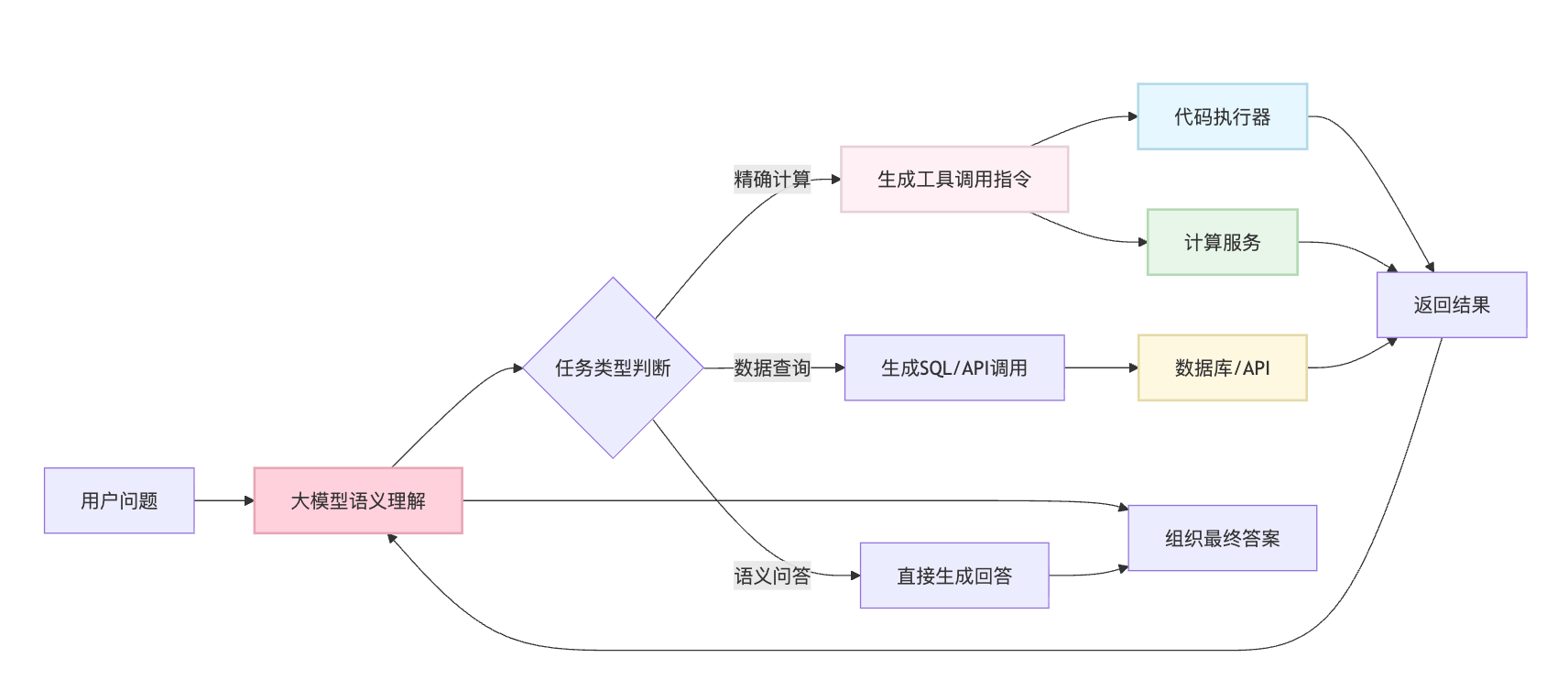
这个架构的核心是让模型做它擅长的事——理解用户意图、分解任务步骤、组织答案表达,而那些需要百分之百准确的操作,全部委托给外部工具。
实战解决方案
解决这类问题其实有不同层次的方案,分别适用于不同的准确性要求和成本约束。最轻量的方案是用思维链提示,让模型把思考过程显式表达出来。比如问strawberry有几个r,你可以在prompt里加上"请逐字符列举这个单词"。这样模型会先输出s-t-r-a-w-b-e-r-r-y,然后再统计r的数量。这个方法的好处是零成本,但可靠性不稳定,因为模型能不能正确拆分字符,本身也依赖它对单词的记忆,遇到生僻词还是可能翻车。
更可靠的做法是让模型生成代码,调用外部执行器来处理。这个方案把符号操作交给确定性系统处理,准确率可以达到百分之百。现在GPT-4的Code Interpreter、Claude的工具调用都是这个思路:
# 用户问题: strawberry有几个r
# 模型生成的代码:
defcount_character(word, char):
"""统计单词中特定字符的出现次数"""
count = word.lower().count(char.lower())
return count
word ="strawberry"
target_char ='r'
result = count_character(word, target_char)
print(f"'{word}' 中字母 '{target_char}' 出现了 {result} 次")
# 输出: 'strawberry' 中字母 'r' 出现了 3 次不过这种方案的代价是引入了额外的执行环境,需要处理代码安全沙箱、超时控制这些工程问题。而且对于高并发场景,每次调用都要启动代码解释器,响应延迟会明显增加。如果业务场景特别依赖这类精确操作,可以考虑针对性地训练或微调模型,但这只在特定垂直领域才划算。比如法律文本分析系统需要精确统计条款数量,医疗领域需要准确识别药品剂量单位,这种情况下可以构造字符级操作的训练样本,让模型学会这类任务的处理模式。
在实际应用中做选择很简单:如果是偶发的简单任务,用思维链提示就够了;涉及金钱、法律这些对准确性要求极高的场景,一定要走工具调用;只有当这类任务成为核心业务流程时,才值得投入资源做专项优化。所以现在有些改进方案是在特定任务上做字符级的微调,或者用思维链prompting让模型先把单词拆成字符列表再计数,但这本质上是在用prompt engineering绕过模型的原生处理粒度,而不是从根本上解决问题。真正需要精确符号操作的场景,更靠谱的做法是调用外部工具,比如让模型生成Python代码去执行计数逻辑。
能力边界的清醒认知
面试官抛出strawberry数不清r这个问题,表面在问技术细节,实际在考察你对AI边界的清醒认知。更值得关注的是为什么会有这些局限性。大模型本质上是通过统计规律学习语言的概率分布,它在模式识别和语义理解上表现惊艳,但遇到需要确定性算法的任务时就暴露短板了。完全消除这类局限性可能不现实,因为token化和自回归这些设计在主流任务上已经验证过有效性。我更倾向于在应用层做针对性适配,比如刚才提到的工具调用机制。
像智能客服场景中,用户问"我的订单号是123456,帮我查一下物流",模型其实不需要自己去"理解"那串数字的含义,它只要能准确提取出来,然后调用物流查询接口就够了。这种清晰的分工反而让系统更可靠。这个问题背后还有个更本质的讨论,就是我们应该把大模型定位成什么。如果把它当成万能的AGI去追求,那现在确实还有很多做不到的。但如果把它定位成语义理解和任务编排的中枢,配合各种专用工具协同工作,反而能发挥更大价值。
当然这个问题还有个更深层的讨论,就是我们到底应该期待大模型在多大程度上具备符号推理能力。现在学术界有人在研究神经符号结合的架构,也有人在探索通过强化学习让模型学会调用工具的策略。但从工程实践角度看,短期内最务实的方案还是明确大模型的能力边界,该用工具的时候别硬让模型硬算。理解了这个边界,你才能在实际项目中做出正确的架构选择,而不是盲目地把所有问题都扔给大模型去解决。