精炼回答
AI完全可以做代码Review,而且已经有成熟方案在生产环境跑起来了。核心思路是将AI集成到CI/CD流程中,当开发者提交PR时自动触发分析并生成评论。具体实现上,你可以使用GitHub Actions或GitLab CI配合OpenAI API、Claude API这些大模型,workflow会自动拉取代码diff内容,把变更发送给AI进行分析。AI会检查代码规范、潜在bug、性能问题、安全漏洞等维度,然后通过GitHub/GitLab的API自动发布review评论到具体的代码行上。
市面上已有现成工具,比如CodeRabbit、Amazon CodeGuru,开箱即用效果就不错。如果要自建方案,可以直接调用OpenAI API或者用Langchain封装,关键是要设计好prompt让AI聚焦在特定检查项上,比如"检查是否有SQL注入风险"、"验证错误处理是否完整"。实际应用中建议AI作为辅助而非替代人工review,它擅长发现明显的代码smell、格式问题、常见反模式,但对业务逻辑的合理性、架构设计的权衡判断还是需要人来把关。一个成熟的方案应该是AI先做第一轮筛查标注问题点,然后人工重点review核心逻辑部分,这样能显著提升团队效率。需要特别注意的是控制好AI的评论质量,避免产生过多噪音让开发者反感,需要持续调优prompt和过滤规则。
扩展分析
技术演进与实现路径
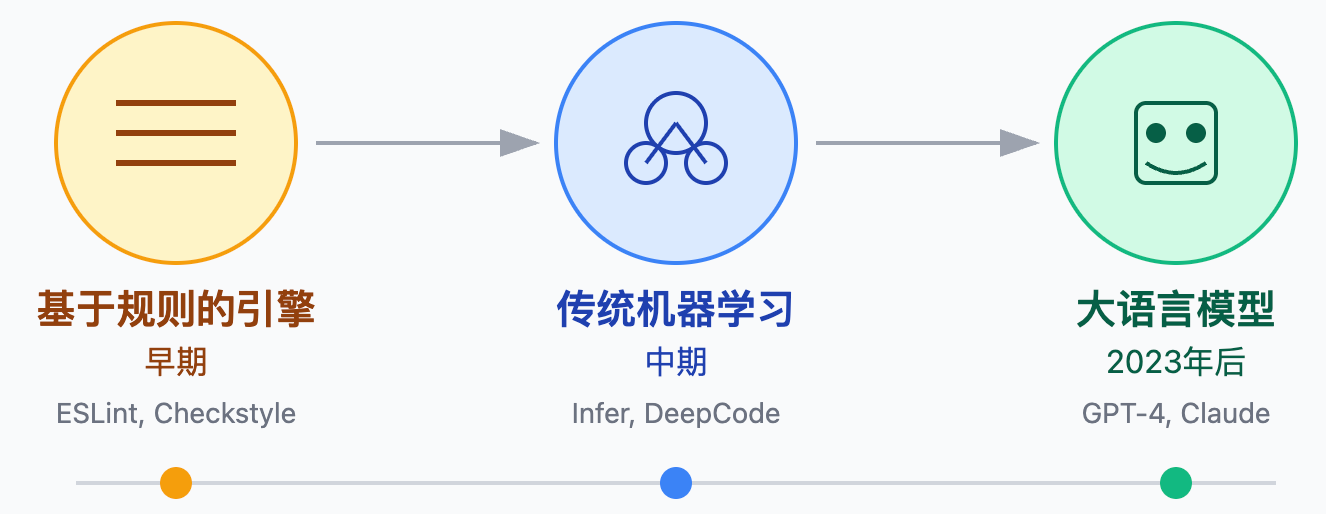
要真正理解AI代码Review的价值,得先搞清楚它经历了哪些技术迭代。最早的自动化代码审查依赖的是写死的规则引擎,就是ESLint、Checkstyle、SonarQube这些工具在做的事——检查变量命名是否符合驼峰规范、是否有未使用的import、代码行数是否超限。这种方式效率高结果稳定,但只能发现表面的格式问题,遇到逻辑性的缺陷就完全无能为力了。
第二阶段引入了传统机器学习,Facebook的Infer和早期的DeepCode是典型代表。这类方案会在大量代码库上训练模型,学习常见的bug模式,比如识别空指针异常的高危场景或者资源泄漏的API调用组合。但这种方案有个致命缺陷——需要大量标注数据,而且只能发现训练集里出现过的问题类型,泛化能力很有限。每次要检查新类型的问题就得重新标注数据训练模型,维护成本非常高。
2023年之后,GPT-4、Claude这类大语言模型的出现彻底改变了游戏规则。它们不需要专门训练,直接通过prompt就能理解代码语义,发现各种层次的问题。关键优势在于理解上下文的能力——传统工具看到一个空判断只能机械地检查语法,而大模型能理解这个变量在上下文中是否真的可能为空,如果前面已经做过非空校验就不会重复提醒。这种语义级别的理解是质的飞跃。
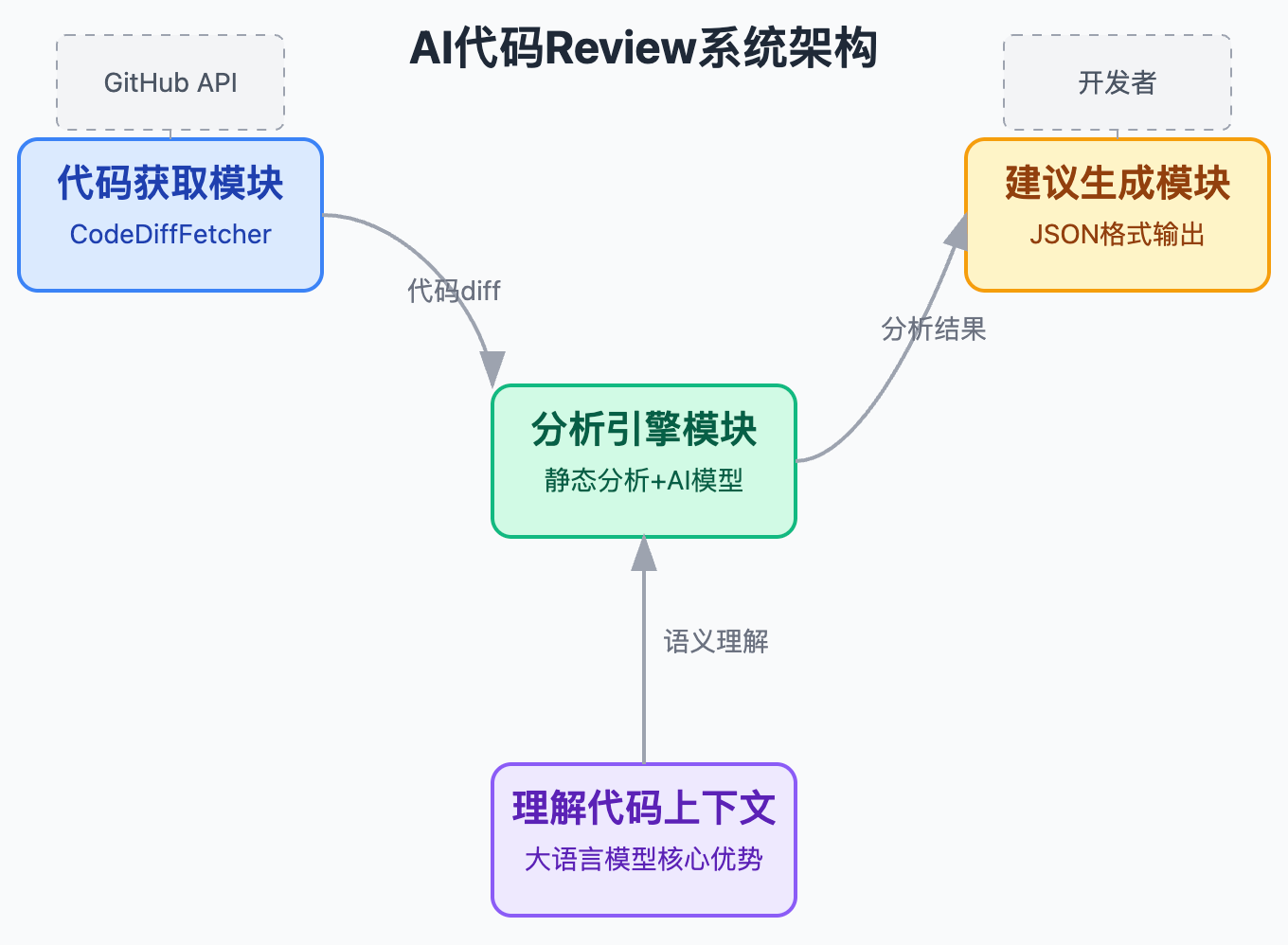
从系统架构角度看,一个完整的AI代码Review方案需要四个核心模块配合。代码获取模块负责在开发者提交PR时通过Webhook触发后端服务,服务拿到PR ID后调用GitHub API获取diff内容。这里有个关键优化点——不会把整个仓库代码都发给AI分析,只分析变更的文件和相关上下文,既能控制成本也能保证响应速度。
`publicclassCodeDiffFetcher{
publicDiffContentfetchPRDiff(String prId){
// 获取PR的变更文件列表
List
// 只保留源代码文件,过滤配置文件和文档
List
// 获取每个文件的diff内容 DiffContent result =newDiffContent(); for(ChangedFile file : codeFiles){ String diff = githubClient.getFileDiff(prId, file.getFilename()); result.addFileDiff(file.getFilename(), diff); }
return result; } }`
java
分析引擎模块是技术含量最高的部分,这里需要静态分析和AI模型配合工作。先跑一遍传统的静态分析工具把明确的规范性问题筛出来,比如代码格式、明显的语法错误,这些问题用规则引擎处理更快更准确没必要浪费AI的token。然后把静态分析发现的问题和代码diff一起送给大模型做深度分析,让大模型专注在逻辑缺陷、安全漏洞、性能隐患这三类需要语义理解的问题上。比如检查并发场景下的线程安全问题,或者SQL拼接是否存在注入风险。
建议生成模块的关键是让AI输出结构化的结果。不能让AI自由发挥返回一段文字,需要通过prompt工程让它返回JSON格式,包含问题类型、严重程度、具体位置、修改建议。现在OpenAI和Anthropic都支持JSON Schema约束输出格式,能保证AI返回的内容符合预期结构方便后续处理。这里的一个工程化细节是需要根据severity控制评论数量,如果发现20个问题不能一次性全部评论会让开发者烦躁。一般做法是Critical和High级别的问题直接评论,Medium级别的汇总成一条,Low级别的只在summary里提。
大语言模型相比传统工具的独特价值在于理解代码上下文的能力。传统工具只能做模式匹配,看到某个API调用就报警,大模型能理解调用的上下文判断是否真的有问题。拿支付场景举例,如果代码里有金额计算,传统工具可能检查不出什么,但大模型能识别出用float做金额运算会丢失精度,建议改用BigDecimal。它不是记住了这条规则,而是理解了浮点数的特性和金融场景的要求。
这里需要特别强调AI和传统工具是互补而非替代关系。ESLint这类工具就像是代码的拼写检查,速度快、结果确定、成本低,适合CI流程里每次提交都跑。而AI更像是高级审查员,专门负责需要语义理解的复杂问题,一般只在PR阶段介入。一个成熟的方案应该是分层的——commit阶段跑ESLint做基础检查,PR阶段跑SonarQube做深度扫描,最后AI做智能审查。这样既保证了效率也控制了成本。
实战落地与体验优化
如果要快速验证AI代码Review的效果,最推荐的技术选型是GitHub Actions配合OpenAI的GPT-4o,这是成本和效果平衡最好的方案。GitHub Actions的优势是零运维成本,workflow文件提交到仓库就能跑起来。GPT-4o相比GPT-4价格降了很多,而且代码理解能力基本持平。如果是私有化部署场景,可以考虑用DeepSeek Coder这类开源模型,虽然效果稍弱但数据安全可控。
在.github/workflows/目录下创建一个ai-review.yml,设置触发条件为pull_request事件,这样每次有人提交PR就会自动运行。workflow主要做三件事——用GitHub API拉取代码diff,调用OpenAI接口分析,最后把结果写回PR评论。
`name: AI Code Review on: pull_request: types:[opened, synchronize]
jobs: review: runs-on: ubuntu-latest steps: -name: Checkout code uses: actions/checkout@v4 with: fetch-depth:0
-name: Get PR diff id: diff run:| git diff origin/${{ github.base_ref }}...HEAD > changes.diff echo "diff_size=$(wc -c < changes.diff)" >> $GITHUB_OUTPUT
-name: Run AI Review
if: steps.diff.outputs.diff_size < 50000
run:|
python scripts/ai_review.py
--pr-number ${{ github.event.pull_request.number }}
--diff-file changes.diff
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}`
yaml
注意这里有个diff_size的判断,如果代码变更超过50KB就跳过AI分析,因为token成本会很高而且大模型处理超长文本效果也会下降。这种情况下可以降级为只做静态检查,或者提示开发者拆分PR。这种细节能体现工程化思维。
Prompt设计是决定Review质量的关键。Prompt不能写得太宽泛,要明确告诉模型关注哪些维度。我一般会分三类prompt——安全检查、性能分析、代码规范,针对不同文件类型使用不同的模板。拿安全检查举例,需要在prompt里限定角色让模型进入特定的分析模式,列出具体的检查项避免模型天马行空地发散,最重要的是要求结构化输出方便后续程序化处理。
`defbuild_security_prompt(code_diff:str)->str: returnf"""You are a security expert reviewing code changes. Analyze the following diff for security vulnerabilities:
{code_diff}
Focus on these specific risks:
- SQL Injection: Check if user input is used in SQL queries without parameterization
- XSS: Verify if user content is properly escaped before rendering
- Authentication bypass: Look for missing permission checks
- Sensitive data exposure: Ensure secrets are not hardcoded or logged
- Path traversal: Check file operations for proper path validation
For each issue found, return JSON in this format: {{ "file": "path/to/file.java", "line": 42, "severity": "HIGH", "issue": "SQL injection risk", "detail": "User input 'userId' is directly concatenated into SQL query", "suggestion": "Use PreparedStatement with parameterized query" }}
Only report issues with high confidence. If code looks safe, return empty array."""`
python
最后那句"只报告高置信度的问题"很关键,能明显降低误报率。我们实测发现加上这句话后,开发者关闭AI评论的比例从40%降到了15%,这种数据化的改进是真实有效的。
调用AI接口时需要重点关注错误处理和重试机制,因为OpenAI接口偶尔会超时或限流,自动重试能提高稳定性。response_format设置为json_object是利用OpenAI的结构化输出能力,确保返回格式可解析。temperature设置为0.3而不是0,是因为完全确定性的输出有时会错过边缘情况,稍微增加一点随机性反而效果更好。
`import openai from tenacity import retry, stop_after_attempt, wait_exponential
classAIReviewer: def__init__(self, api_key:str): self.client = openai.OpenAI(api_key=api_key)
@retry(stop=stop_after_attempt(3), wait=wait_exponential(min=1,max=10)) defanalyze_code(self, code_diff:str, focus_area:str)->list: prompt = self._build_prompt(code_diff, focus_area)
response = self.client.chat.completions.create( model="gpt-4o-2024-08-06", messages=[ {"role":"system","content":"You are an expert code reviewer."}, {"role":"user","content": prompt} ], response_format={"type":"json_object"}, temperature=0.3, max_tokens=2000 )
result = json.loads(response.choices[0].message.content) return self._filter_low_confidence(result.get("issues",[]))
def_filter_low_confidence(self, issues:list)->list: seen =set() filtered =[] for issue in issues: key =f"{issue['file']}:{issue['line']}:{issue['issue']}" if key notin seen and issue.get('severity')in['HIGH','CRITICAL']: seen.add(key) filtered.append(issue) return filtered`
python
把结果写回GitHub时需要理解API调用的层次结构。GitHub的Review机制分两层,一层是PR级别的summary,另一层是代码行级别的comment。高优先级问题应该用行级评论精准定位,低优先级的集中放在summary里。用create_review而不是逐条发create_comment,是因为前者会把所有评论合并成一个review事件,不会在PR里刷屏。评论格式加上emoji和建议部分,让开发者能快速识别严重程度并知道怎么修复。
`from github import Github
classGitHubCommentPublisher: def__init__(self, token:str, repo:str, pr_number:int): self.gh = Github(token) self.repo = self.gh.get_repo(repo) self.pr = self.repo.get_pull(pr_number)
defpublish_review(self, issues:list): commit = self.pr.get_commits().reversed[0]
comments =[] for issue in issues: if issue['severity']in['HIGH','CRITICAL']: comments.append({ "path": issue['file'], "line": issue['line'], "body": self._format_comment(issue) })
if comments: self.pr.create_review( commit=commit, body="🤖 AI Code Review completed", event="COMMENT", comments=comments )
def_format_comment(self, issue:dict)->str: emoji ="🔴"if issue['severity']=='CRITICAL'else"🟠" returnf"""{emoji} {issue['issue']}
{issue['detail']}
💡 Suggestion: {issue['suggestion']}
Reported by AI Code Reviewer"""`
python
成本控制主要从两个方面入手。API费用通过增量分析来控制,如果PR只改了3个文件就只分析这3个文件,不需要每次都扫描整个项目。对于超大型PR可以做异步处理,先快速返回一个"分析中"的评论,后台慢慢跑完再更新结果。还可以加缓存机制,如果同一段代码在其他PR里已经分析过,直接复用结果。
`defget_changed_files_with_context(pr_number:int)->dict: """获取变更文件及其必要的上下文代码""" pr = repo.get_pull(pr_number) changed_files ={}
forfilein pr.get_files(): ifnotfile.filename.endswith(('.java','.py','.js','.ts')): continue
patch =file.patch iffile.patch else""
对于新增或大幅修改的文件,拉取完整内容
iffile.status =='added'orfile.changes >100: content = repo.get_contents(file.filename, ref=pr.head.sha).decoded_content.decode() changed_files[file.filename]={ 'type':'full', 'content': content } else: changed_files[file.filename]={ 'type':'patch', 'content': patch }
return changed_files`
python
按GPT-4o的价格,分析一个普通PR大概花费0.5到2美元,对于中型团队来说一个月的成本可能在几百美元量级。这个成本相比人工review节省的时间是很划算的,但前提是AI的建议确实有价值。
评估体系与协同策略
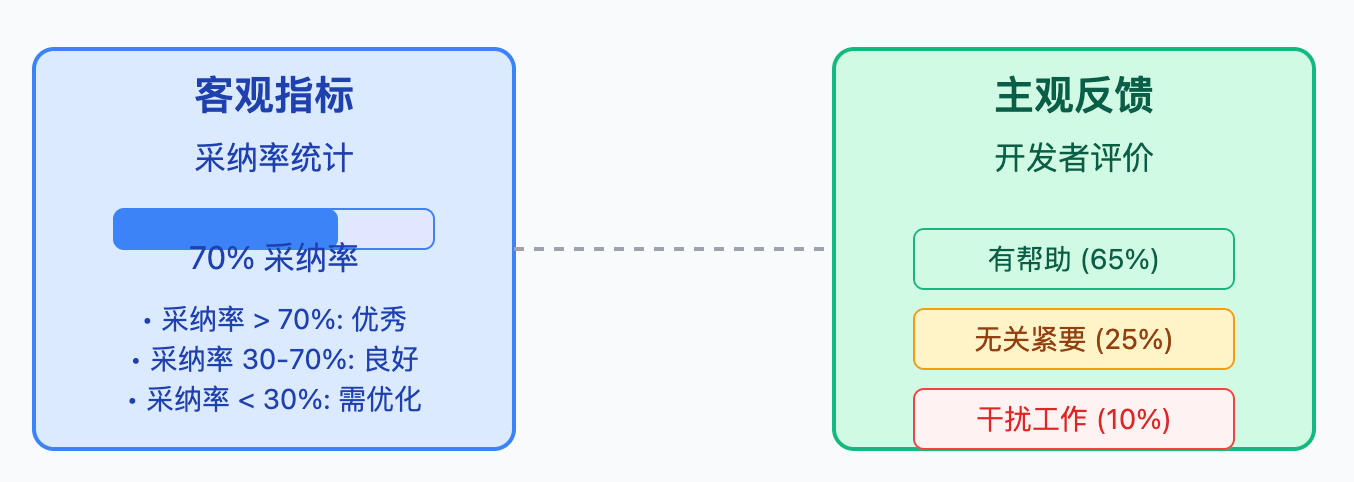
评估AI Review的效果需要从两个维度入手。客观指标方面,要统计AI发现的问题中有多少被开发者真正修复了,这个采纳率能反映AI建议的价值。如果采纳率低于30%,说明误报太多或者建议质量不高,需要调优prompt。主观反馈方面,要定期收集开发者对AI评论的反馈,是觉得有帮助、无关紧要还是干扰工作。这种定性评价配合定量数据,能比较全面地判断效果。特别要注意不能只看发现了多少问题,因为AI可能会过度敏感地报告大量低价值的建议,反而降低效率。
处理误报要分事前预防和事后优化。事前主要靠精细化的prompt设计,在prompt里加入团队特有的代码规范和常见的误报案例,告诉AI哪些模式看起来有问题但实际是合理的。事后要建立反馈机制,开发者可以标记误报,系统收集这些case后用来调整检查规则。还可以引入置信度机制,让AI对每个问题给出置信度评分,只有高置信度的才直接评论,中等置信度的放在可折叠区域供参考。这种分层处理的思路能明显改善用户体验。
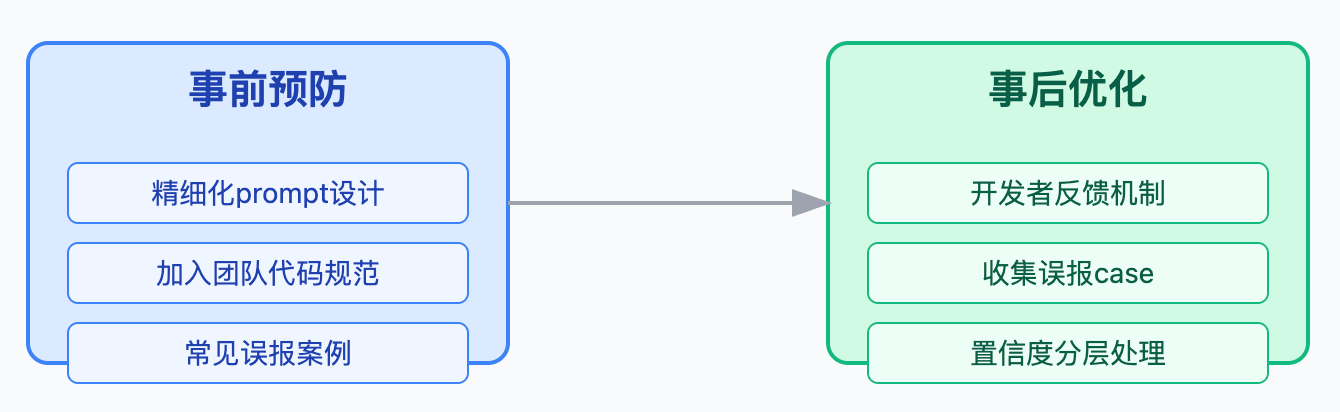
AI代码Review应该分层设计来实现与人工的有效协同。第一层是全覆盖的自动检查,每个PR都跑,但只报告确定性很高的问题,比如明显的安全漏洞或性能缺陷。第二层是针对核心模块的深度分析,比如涉及数据库操作、外部接口调用、权限校验的代码,AI会做更细致的逻辑检查。第三层是人工review,负责业务逻辑合理性和架构决策的评审。关键是要让AI和人工形成互补,AI发现的问题可以作为人工review的检查清单,人工在审查时重点验证AI标注的风险点,这样能显著提升review质量。
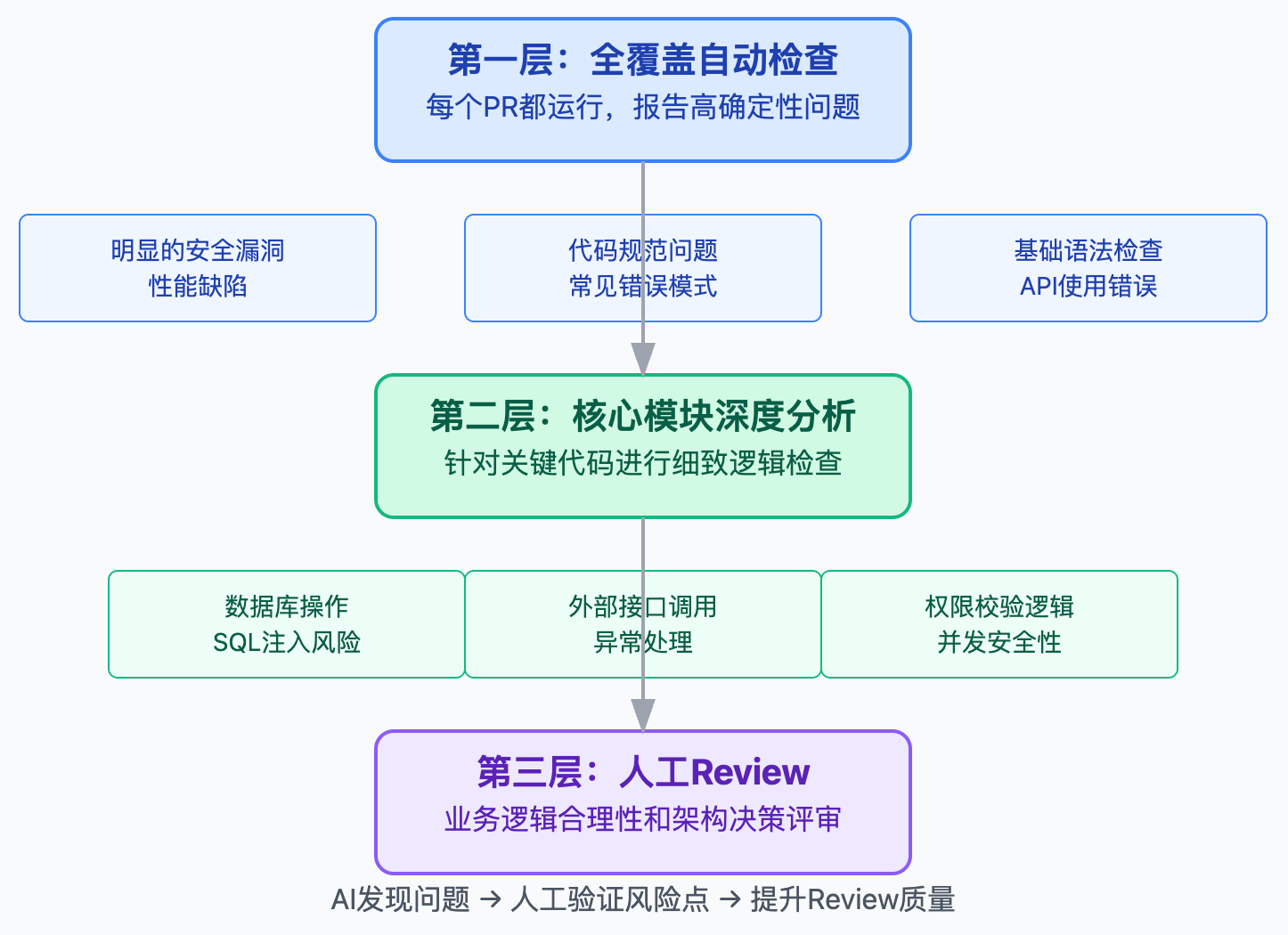
要清楚什么场景适合用AI什么场景不适合。AI特别适合处理重复性的检查任务,比如发现常见的代码异味、识别安全漏洞模式、检查异常处理的完整性。这些问题有比较明确的模式可循,AI的语义理解能力能发挥优势。但对于架构设计的合理性、技术选型的权衡、复杂业务逻辑的正确性,AI的判断就不太可靠了。比如某个微服务拆分方案是否合理,这需要理解业务演进方向和团队协作模式,AI很难做出准确判断。还有一类场景是团队特有的规范,比如某个内部框架的最佳实践,这种领域知识需要通过精心设计的prompt或者fine-tuning才能让AI掌握。
实际落地时会遇到三个主要挑战。代码隐私问题是第一道坎,把代码发给第三方AI服务很多公司的安全团队不接受。解决方案是敏感项目用本地部署的开源模型,或者跟OpenAI签企业协议确保数据不用于训练。误报率控制是第二个挑战,AI再智能也会有误判,如果开发者频繁收到错误的批评很快就会失去信任。需要持续收集反馈,把误报case加入到prompt的负面示例中。团队接受度是第三个挑战,突然冒出个AI给大家的代码挑毛病,有些资深开发者会抵触。推行时建议先在小范围试点,让大家看到AI确实能发现有价值的问题再逐步推广。
现在的AI Review主要还是被动检查,未来可能会演进成主动的代码智能体。比如AI不仅指出问题,还能直接生成修复代码并提交PR,开发者只需要review AI的修复方案是否合理。另一个趋势是AI Review会适应团队的编码风格,通过学习团队历史上的code review记录,AI能理解这个团队更关注什么、容忍什么,给出更符合团队文化的建议。这种个性化能大幅降低AI评论与团队期望的摩擦。