精炼回答
大模型确实会遗忘,而且这个问题比你想象的严重。灾难性遗忘指的是神经网络在学习新任务时,会显著丢失之前已掌握的旧任务知识,这是深度学习的固有问题。
具体来说,当你用新数据对已训练好的模型进行微调时,模型参数会向适应新数据的方向更新,这个过程会覆盖掉原本编码旧知识的参数配置。比如你先训练GPT处理医疗文本,再用法律文本微调,模型在法律任务上表现提升的同时,医疗领域的能力可能大幅下降,甚至完全丧失。
这个现象的根源在于神经网络通过分布式方式存储知识——不同任务的知识在参数空间中会有重叠,新任务的梯度更新会干扰旧任务的参数。目前主要通过几种方式缓解:持续学习技术如弹性权重巩固(EWC)会识别重要参数并限制其更新;经验回放在训练新任务时混入部分旧数据;参数隔离比如LoRA这类方法为新任务添加独立的参数模块,避免修改原始权重。
这也是为什么大模型厂商在更新模型时需要在全量数据上重新训练,而不是简单地在新数据上继续训练——就是为了避免灾难性遗忘导致模型整体能力退化。
扩展分析
深入分析:遗忘的本质机制
面试时遇到这个问题,你需要在开口30秒内让面试官感觉到你是真的理解这个概念,而不是在背书。最好直接这样开场:"大模型确实会遗忘,这其实是神经网络的固有特性,我们通常把这个现象叫做灾难性遗忘。"这个开头很关键,既回答了问题,又自然引出了技术术语。
接下来面试官最想听到的是你对这个现象的本质理解。所谓灾难性遗忘,核心现象就是当模型在学习新任务时,原本已经掌握的旧任务能力会快速衰退,甚至完全丢失。比如一个模型本来能很好地做情感分析,但当你用它去学习文本分类后,它可能就不太会做情感分析了。这里的例子要简单直白,让面试官立刻get到这个现象的直观感受。
假设我们有一个已经训练好的大模型,它能很好地处理客服对话。现在我们想让它也学会处理法律咨询,最直观的做法就是拿法律对话数据继续训练。但问题就出在这里——训练过程中,模型的参数会不断调整去适应法律领域的语言模式、专业术语和逻辑结构。这种调整不是在原有能力之上做增量,而是直接修改那些共享的参数。结果就是,当你测试时发现,模型的法律咨询能力上来了,但原本很擅长的客服对话能力却大幅下降,甚至完全不行了。
神经网络的知识不像我们在数据库里存数据,不是一条条独立存储的。它是通过几亿甚至几千亿个参数的特定组合来编码知识的。当模型学习客服对话时,某些参数组合起来代表了"客户投诉的语气特征",另一些组合代表了"礼貌回复的句式模板"。但当你用法律数据训练时,梯度下降算法会把这些参数往法律文本的方向拉——同样的参数可能被重新调整去识别"诉讼请求的格式"或者"法条引用的模式"。因为是同一批参数,新的调整就把旧的配置覆盖掉了。
这里要特别注意跟面试官强调一个容易被忽略的点:神经网络的遗忘跟人类遗忘有本质区别。人类遗忘通常是渐进的,不常用的知识会慢慢淡化,但触发适当线索还能回想起来。神经网络的遗忘更像是直接覆盖——就像你在硬盘上写新文件,直接把旧文件占用的扇区改写了,旧内容就物理上消失了。所以才叫"灾难性",因为这个过程可能非常快,训练几个epoch之后,旧任务的性能就从90%掉到30%,而且不可逆。
在大模型的应用场景里,这个问题特别突出。比如你拿一个通用的预训练模型去做特定领域的微调,像把BERT微调到金融文本分类任务上。如果你只用金融数据训练,那模型在金融任务上效果会很好,但原本预训练阶段学到的通用语言理解能力——比如对日常对话、新闻报道、科技文档的理解——可能就大幅退化。更棘手的是,如果你后续还想在这个微调过的模型基础上再去适应医疗领域,那金融领域的能力又会被遗忘。这就是为什么持续学习场景下,遗忘问题会变得特别严峻,每学一个新任务就把前面的任务忘掉一部分,模型就没法真正做到多任务胜任。
在实际评估时,我们通常会做回退测试。具体做法是,先在任务A上训练并记录性能基线,比如准确率95%。然后用任务B的数据继续训练。训练完任务B后,再回过头用任务A的测试集评估一次,这时候可能准确率就掉到了60%。这个从95%到60%的性能回退就是遗忘程度的量化指标。如果你在多任务序列上持续学习,还要追踪平均遗忘率,看每学一个新任务,对之前所有任务的平均影响有多大。
很多人第一反应是不是模型容量不够,参数太少装不下这么多知识。但实验表明,即使你把模型规模扩大十倍,灾难性遗忘依然会发生,只是程度稍微减轻。这说明问题的核心不在于容量,而在于更新策略——梯度下降天然就是一个覆盖式的优化过程,它不知道哪些参数对旧任务重要,只管让损失函数在新任务上降下来。所以解决方案的思路也不是简单加参数,而是要改变训练方式,比如约束重要参数的更新幅度,或者给不同任务分配独立的参数空间。
实战解决方案
当面试官听完你对灾难性遗忘的理论解释之后,很自然会想知道你懂不懂怎么解决这个问题。拿智能客服来说,假设你已经有一个处理售后问题的模型,现在要让它也支持预售咨询。如果直接用预售对话数据去微调,售后能力很可能就废掉了。这种场景在实际业务中特别常见,所以业界发展出了好几类解决思路。
第一类思路是在训练时给重要参数加约束,典型代表就是EWC这类正则化方法。EWC的核心想法是,既然问题出在新任务训练会破坏旧知识的参数,那我们就先识别出哪些参数对旧任务特别重要,然后在训练新任务时限制这些参数的变动幅度。具体做法是在损失函数里加一个惩罚项,当重要参数偏离旧任务训练出的值时,惩罚就变大。这样梯度更新时就会自动避开这些重要参数。这个方法的好处是实现起来比较直接,不需要保留旧数据,只需要记录参数的重要性。但缺点是计算成本高,要对每个参数计算Fisher信息矩阵,而且如果你要持续学习很多任务,约束会越积越多,到后面新任务基本学不动了。
第二类思路是经验回放,说白了就是在学新任务时混入一部分旧任务的数据。你在用预售数据训练时,每个batch里混入20%的售后数据,这样模型在优化新任务的同时也在持续复习旧任务,遗忘问题就能大幅缓解。工程实践中最大的问题是数据存储,如果旧任务数据量很大,全部保留成本太高。所以通常会做采样,只保留最具代表性的一部分样本。更进阶的做法是伪样本生成,用旧模型生成一些synthetic数据来代替真实数据,这样就不用存储原始数据集了。
# 经验回放的简单实现示例
classReplayBuffer:
def__init__(self, capacity=1000):
self.buffer=[]
self.capacity = capacity
defadd(self, samples):
"""存储旧任务的样本"""
self.buffer.extend(samples)
iflen(self.buffer)> self.capacity:
# 随机采样保持容量
self.buffer= random.sample(self.buffer, self.capacity)
defsample(self, batch_size):
"""采样旧任务数据"""
return random.sample(self.buffer,min(batch_size,len(self.buffer)))
# 训练新任务时混合旧数据
for new_batch in new_task_dataloader:
old_batch = replay_buffer.sample(batch_size //5)# 20%旧数据
mixed_batch = combine(new_batch, old_batch)
loss = model.train_step(mixed_batch)第三类是参数隔离策略,这在当前大模型时代特别流行。参数隔离的思路是给不同任务分配独立的参数空间,避免相互覆盖。LoRA就是典型代表,它不直接修改原始模型参数,而是给模型加上一些低秩的适配矩阵。训练新任务时只更新这些适配矩阵,原始参数保持冻结。这样售后能力编码在原始参数里,预售能力编码在新增的LoRA模块里,两者物理上是隔离的,自然就不会遗忘。这个方案在实际落地时特别受欢迎,因为你可以针对不同业务场景训练多套LoRA模块,推理时动态加载对应的模块就行,成本很低。而且新任务训练速度快,因为需要更新的参数量只有原模型的千分之几。
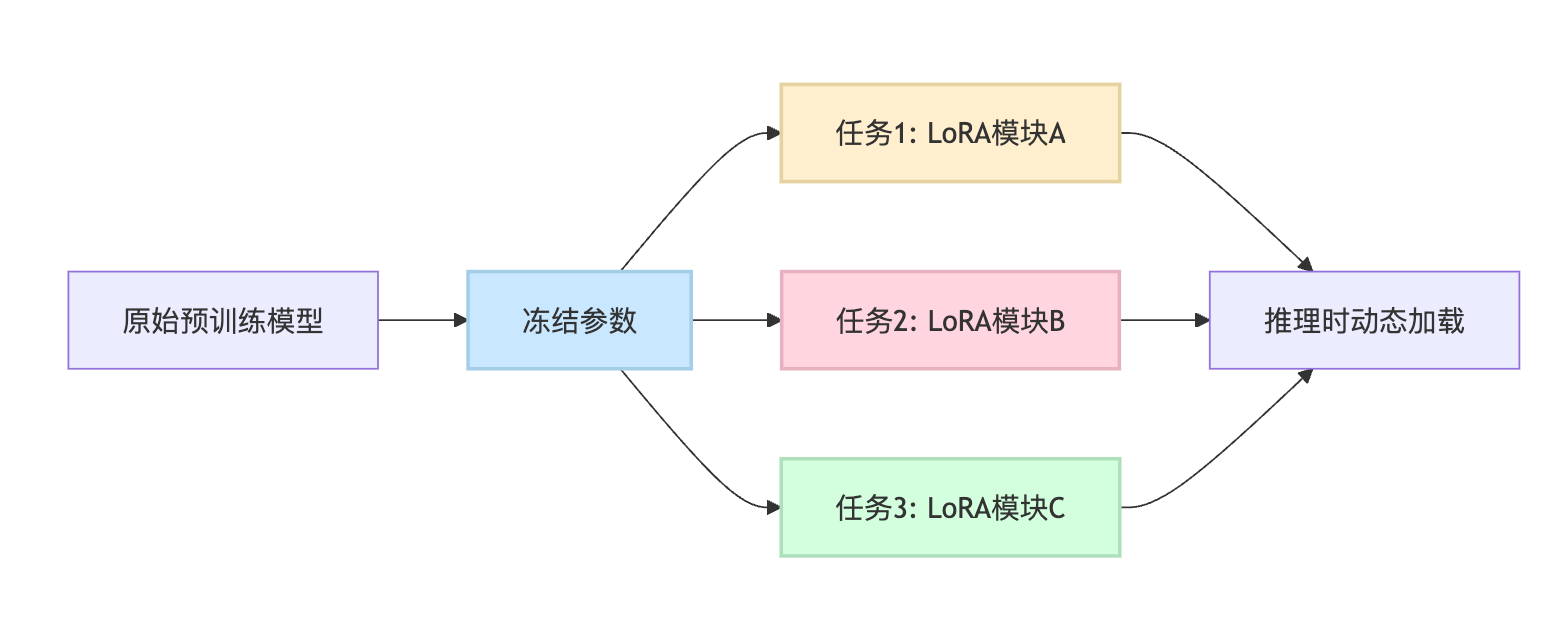
实际选方案时主要看三个因素。如果可以保留旧数据,经验回放通常是最稳妥的选择,效果好实现也简单。如果只是两三个任务,EWC这类正则化方法就够用;但如果要持续学习十几个任务,参数隔离会更合适。另外还要考虑推理成本,如果要同时服务多个任务,LoRA这种模块化方案切换灵活,更适合生产环境。
有一个常见误区是过度保护旧知识。比如用EWC时把正则化系数设得特别大,或者经验回放时旧数据占比过高,结果就是旧任务确实不遗忘了,但新任务怎么都学不好。这其实是从一个极端走向另一个极端。实际调参时要做trade-off,允许旧任务性能有小幅下降,比如从95%降到92%,换取新任务能真正学到东西。毕竟目标是让模型同时胜任多个任务,而不是让旧任务一丁点都不能退步。
更深层的思考
面试官问这个问题,表面上是在考察你对技术概念的了解,但真正想看的是你对大模型局限性有没有清醒的认识。很多校招生容易掉进一个坑,就是把大模型说得神乎其神,仿佛什么问题都能解决。当面试官抛出"大模型会遗忘吗"这个问题时,其实是在测试你是不是真正理解了AI技术的边界,还是只会人云亦云地吹捧。
讲完基本概念后,面试官很可能会追问:"那在实际项目中你会怎么平衡新旧知识?"这个问题的陷阱在于,很多人会直接说"我会用LoRA"或者"我会做经验回放",但这样回答太单薄了。面试官更想听到的是你对业务场景的判断能力。首先要看业务对旧能力的容忍度。比如一个推荐系统,如果新增了短视频推荐能力,但导致原本的图文推荐准确率从85%降到82%,这3个点的下降对用户体验影响有多大?如果业务可以接受,那就不需要上很重的防遗忘方案。但如果是金融风控模型,旧任务的性能下降可能直接导致风险敞口变大,那就必须用经验回放这类强保护手段,哪怕训练成本高也得上。
如果遇到研究导向比较强的面试官,他可能会问:"你了解持续学习或终身学习的研究前沿吗?"这时候千万别慌,即使你没读过最新论文也能答好。现在学术界在探索更本质的解决思路,比如神经架构搜索NAS,让模型在学新任务时自动扩展新的子网络,而不是修改原有参数。还有元学习的方向,让模型学会"如何学习",使得它在接触新任务时能快速适应但不破坏旧知识。不过这些方法目前还在实验室阶段,工程化落地的门槛比较高。
从架构思维的角度看,灾难性遗忘这个问题其实可以延伸到更宏观的模型生命周期管理上。遗忘问题让我意识到,模型不是训练完就一劳永逸的,它需要一套完整的版本管理策略。比如当我们发布了一个新版本模型,要不要保留旧版本作为fallback?如果新版本在某些长尾场景表现变差,怎么做灰度切换?这些都是模型迭代时必须考虑的工程问题。这种从技术问题到架构设计的思考跨度,能让面试官看到你不只是一个执行层面的工程师,而是有系统性思维的。
最后要学会判断什么场景必须解决遗忘,什么场景可以接受。并不是所有场景都要不惜代价防止遗忘。如果模型的生命周期本来就短,比如营销活动期间临时训练的文案生成模型,活动结束后就不再使用,那完全可以接受遗忘。但如果是需要长期服务的生产系统,比如搜索引擎的语义理解模型,就必须认真对待遗忘问题,否则用户会明显感觉到体验倒退。这种技术判断力的展现,会让面试官确认你不是教条主义者,而是能根据实际情况灵活决策的人。