精炼回答
增量代码生成和全量代码生成的本质区别在于是否需要感知已有代码。增量生成会识别哪些代码变了,只生成变化的部分然后合并进去,这需要通过对比源文件的变更,维护代码版本信息或使用 AST diff 算法来识别变更点。全量生成不管三七二十一,每次把所有代码完整重新生成一遍,直接覆盖目标文件,不需要复杂的差异计算。
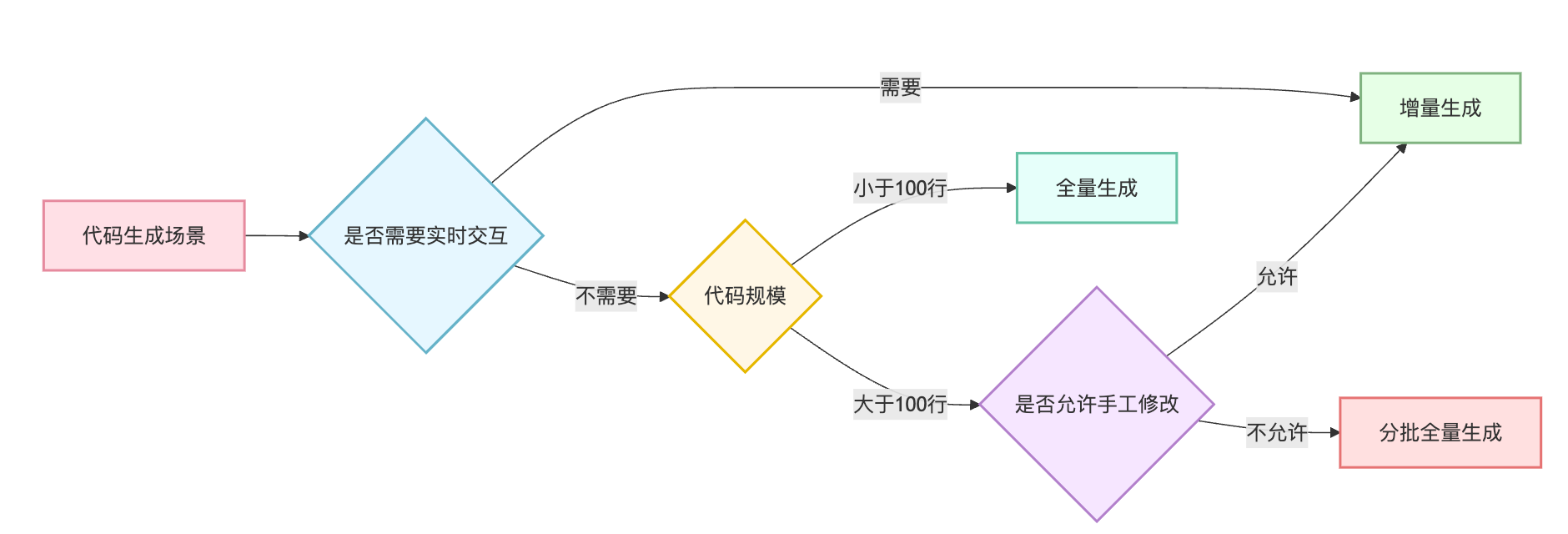
选择哪个主要看生成的代码能不能被改。像 API 接口代码、数据库映射这些,生成后不会手动改,比如 Protobuf 生成的接口代码、MyBatis Generator 生成的 DAO 层,直接用全量生成最简单,每次构建覆盖就完事。但如果是脚手架初始化、AI 辅助写代码这种场景,生成后开发者肯定要继续修改,这时候必须用增量生成,不然一次构建就把改动全覆盖了。就像现在大模型代码补全,不可能把整个文件重新生成,只能在光标位置增量插入代码片段,否则你写的逻辑全没了。
还有个实际考量是构建性能。大型项目中如果每次都全量生成成千上万个文件会很慢,增量生成能显著提升构建速度。不过增量生成的实现复杂度更高,需要处理好文件变更检测、代码合并冲突、状态管理等问题,开发成本明显更大。
扩展分析
技术实现机制的本质差异
增量生成其实和现在我们用的 AI 编程助手工作原理很像,它需要流式处理。这个切入点特别好理解,因为 2025 年几乎所有开发者都用过 Cursor 或者 Copilot,对那种代码一个字一个字蹦出来的体验有直观感受。模型在生成时不是一次性吐出完整结果,而是 Token-by-Token 地输出,每生成一小段就立即返回给客户端。这样做的好处是用户能实时看到进度,但技术挑战在于你得维护生成状态——当前生成到哪了、上下文信息是什么、如果用户中途打断了怎么恢复。
增量生成最麻烦的就是状态保持问题。假设正在生成一个复杂的服务类,写到一半用户改了需求,你不能从头再来,得能在当前位置继续生成或者局部修正。这就需要把已生成的代码结构、变量命名、依赖关系这些信息都缓存下来。比如生成一个订单处理流程,已经生成了创建订单、库存扣减两个方法,这时用户要加个优惠券校验逻辑。增量生成器得知道现有代码的调用链路,在合适的位置插入新方法,还得处理好方法参数传递。如果是全量生成,直接把整个类重新生成一遍就完事了,反正最终输出是个完整文件。
全量生成就是一次性推理,把所有输入信息——比如数据库 schema、业务规则、代码模板——全部塞进 Prompt,让模型一口气生成完整代码文件。这种方式的优势在于上下文完整,模型能全局考虑代码的一致性,生成出来的方法命名风格、错误处理逻辑都比较统一。增量生成有个天然劣势是上下文碎片化,每次只看到局部代码,可能导致前后不一致。比如前面用了 RestTemplate 做 HTTP 调用,后面补充的代码里又用了 OkHttp,虽然都能工作但代码风格割裂。全量生成就不存在这问题,所有代码都是在同一个推理过程中产出的,整体性更好。
不过全量生成也带来另一个问题——上下文窗口限制。如果要生成的代码量特别大,比如一个包含几十个方法的服务类,可能把整个文件的上下文都塞不进去,这时候要么拆分成多个小任务,要么就得用支持超长上下文的模型,成本会高很多。从响应时间看,增量生成的首字延迟特别低,可能几十毫秒就开始出字,用户体验好。但如果算整体生成时间,未必比全量快,因为要多次往返、维护状态、处理合并逻辑。全量生成看起来要等个几秒才开始输出,但对于中小规模的代码,总耗时可能更短。拿生成一个标准的 CRUD 接口来说,全量生成可能 3 秒完成,一次 API 调用,消耗 5000 个 Token。增量生成虽然 1 秒后就开始出字,但如果用户中途修改了两次需求,可能总共调了 5 次 API,累计消耗 8000 Token,总时长反而到了 10 秒。
增量生成的实时反馈对开发者心理影响很大,就像看着有人在敲键盘写代码,这种感知进度的体验会让人更有耐心。特别是生成复杂逻辑时,如果是全量生成,盯着转圈等 30 秒,会让人怀疑是不是卡住了。但增量生成也有个问题,如果生成到一半发现方向不对,用户得立即打断,这时候处理中断信号、清理状态、保证已生成代码的完整性,这些异常处理逻辑会让系统复杂度上升一个量级。
全量生成的错误处理相对简单,生成失败了就整个重试,或者给用户报个错让他调整输入。增量生成就麻烦了,假设生成了一半网络断了,是从断点续传还是整个重新开始?如果选择续传,怎么保证续传的代码和前面的衔接得上?这就需要设计检查点机制,每生成一段就保存状态快照,出错时能回滚到最近的检查点。
publicclassIncrementalGenerator{
privateGenerationState currentState;
privateList<StateSnapshot> checkpoints =newArrayList<>();
publicStreamingResponsegenerate(CodeRequest request){
try{
returnstreamGenerate(request);
}catch(InterruptedException e){
// 用户中断,保存当前进度
checkpoints.add(currentState.snapshot());
returnresumeFrom(checkpoints.get(checkpoints.size()-1));
}catch(NetworkException e){
// 网络异常,回滚到最近检查点
if(!checkpoints.isEmpty()){
StateSnapshot lastCheckpoint = checkpoints.get(checkpoints.size()-1);
currentState = lastCheckpoint.restore();
returnretryFrom(currentState);
}
throw e;
}
}
privateStreamingResponsestreamGenerate(CodeRequest request){
StreamingResponse response =newStreamingResponse();
while(currentState.hasMoreToGenerate()){
// 每生成一个代码块创建检查点
CodeBlock block =generateNextBlock(currentState);
response.append(block);
if(currentState.isCheckpointTime()){
checkpoints.add(currentState.snapshot());
}
}
return response;
}
}
质量保证的角度也很能体现技术深度。全量生成有个天然优势是容易做完整性检查。生成完了跑一遍语法解析,确保括号匹配、导入语句完整、类型检查通过,这些都是标准流程。增量生成就难办了,每次只生成一小段,怎么保证语法正确?比如正在生成一个方法,写到一半光标停那儿,这时候代码肯定是语法错误的。所以增量生成器要能容忍中间状态的不完整性,只在用户明确表示生成结束时才做完整性校验。这对代码解析器的要求很高,得支持部分代码的语法分析。
上下文一致性是另一个质量维度。假设在生成商品搜索接口,第一次生成时用了 Elasticsearch 做检索,后来用户要加个价格区间筛选功能,增量生成时要能感知到之前用的是 ES,继续用同样的查询 DSL,而不是突然冒出来一段 SQL。这就需要在状态管理里维护技术栈上下文,记录已经做过哪些技术选型决策。全量生成不存在这问题,因为所有代码都是一次性生成的,模型自然会保持技术栈一致。
实际场景的决策框架
我判断用哪种方式主要看三个维度:代码长度、用户等待容忍度、以及代码能否被手工修改。如果生成的代码不超过 50 行,而且用户需要立即看到结果,那增量生成体验更好。比如在 IDE 里写了个方法签名,按 Tab 触发补全,用户期望的是马上蹦出几行代码,而不是等两秒。但如果是要生成一个完整的 REST 接口,包含 Controller、Service、DTO 这一整套,可能几百行代码,这时候全量生成反而更合适,一次性给出完整实现,用户宁愿多等几秒也想要个结构完整的结果。
开发者在不同场景下的心理预期差异很大。当我在 IDE 里触发代码补全,如果 500 毫秒还没反应,我就会继续手敲了,这种场景必须用增量生成,让首字延迟控制在 100 毫秒以内。但如果是在代码生成平台上填了一堆配置项,点击"生成项目骨架"按钮,这时候我心理预期就是要等个 10 秒 20 秒的,因为知道系统在帮我生成完整的项目结构。
实际上现在做得好的产品都不是纯粹用一种方式,而是根据任务类型动态切换。比如在开发一个 IDE 插件时,我们的策略是这样的——单行补全和简单表达式生成用增量模式,因为这些场景用户是在连续编码过程中,需要实时反馈。但当用户选中一段代码要求重构,或者从注释生成完整函数时,就切换到全量模式,因为这是个独立的生成任务,用户会停下来等结果。
看看现在主流的 AI 编程工具就能发现选择策略。GitHub Copilot 的代码补全是典型的增量生成,在光标位置实时插入代码片段,因为它就是要和开发者的手工编码混合使用。但 Copilot 的"Generate code from comment"功能又会用全量生成,因为那是从注释生成完整方法,一次性输出更合理。再看 Cursor 的 Composer 功能,它采用的是混合策略,初始生成是全量的,给你一个完整的代码框架,但后续的修改迭代就切换成增量模式,只改你指定的部分。这种策略特别聪明,结合了两种方式的优势。所以在实际工程中,不是非黑即白地选一种方式,而是根据不同阶段、不同任务特点做动态切换。初始化阶段用全量保证整体质量,迭代阶段用增量提升交互效率,这是目前比较成熟的实践模式。
在实际项目中我们发现,有些生成请求的模式是重复的,比如用户经常会在某个特定的代码位置触发补全。这时候可以做预测性生成,在用户还没触发之前就提前算好,放到缓存里。我们统计过,在业务代码里写完 Service 方法签名后,超过 70% 的用户会在方法体第一行触发补全来生成参数校验逻辑。既然这个模式这么稳定,完全可以在用户敲完方法签名的右括号时,后台就开始预生成,等用户真正触发时直接从缓存返回,体验上就是秒出。
缓存的粒度设计很有讲究,不能简单地把整个生成结果缓存起来。我们的做法是把上下文特征做哈希,把文件路径、当前函数签名、光标位置这些信息组合成缓存键。
publicclassGenerationCache{
privatefinalConcurrentHashMap<String,CachedResult> cache =newConcurrentHashMap<>();
publicStringgetCacheKey(CodeContext context){
returnnewStringBuilder()
.append(context.getFilePath())
.append("|")
.append(context.getCurrentMethodSignature())
.append("|")
.append(context.getCursorLine())
.toString();
}
publicOptional<String>tryGetFromCache(CodeContext context){
String key =getCacheKey(context);
CachedResult result = cache.get(key);
if(result !=null&&!result.isExpired()){
returnOptional.of(result.getCode());
}
returnOptional.empty();
}
publicvoidcacheResult(CodeContext context,String generatedCode){
String key =getCacheKey(context);
cache.put(key,newCachedResult(generatedCode,System.currentTimeMillis()));
}
staticclassCachedResult{
privatefinalString code;
privatefinallong timestamp;
privatestaticfinallong EXPIRE_TIME =300_000;// 5分钟过期
CachedResult(String code,long timestamp){
this.code = code;
this.timestamp = timestamp;
}
booleanisExpired(){
returnSystem.currentTimeMillis()- timestamp > EXPIRE_TIME;
}
StringgetCode(){
return code;
}
}
}
增量生成有个棘手问题是怎么让用户知道生成完了。全量生成很简单,等待框消失就说明完事了。但增量生成是流式的,你得有个明确的结束信号。早期有些工具做得不好,代码流式输出,用户不知道是生成完了还是卡住了,特别是最后一句刚好是个完整语句时,你没法判断后面还有没有。现在主流的做法是在生成结束时发一个特殊的结束标记,或者在 UI 上给个明确的"生成完成"提示。
我们曾经做过一个对比实验,针对生成完整函数这个场景,分别用增量和全量两种方式,然后看用户的接受率。结果发现对于 20 行以内的函数,增量生成的接受率高 15%,因为用户能边看边判断,发现不对立即停掉。但超过 50 行的函数,全量生成的接受率反而高 20%,因为增量生成时用户等得不耐烦,还没生成完就放弃了。基于这些实践,我总结了一个快速判断表:单行补全、变量重命名、简单重构,用增量生成;函数生成、类生成、接口文档生成,用全量生成;多文件生成、项目初始化,用分批全量生成。特殊情况是那种用户需要高频交互的场景,比如对话式编程助手,即使生成长代码也要用增量,因为用户随时可能改主意,得支持中途调整。
产品思维与技术演进
选择增量还是全量,本质上是在平衡用户体验、实现成本和产品定位三者之间的关系。如果产品定位是提升开发效率的辅助工具,那增量生成带来的实时反馈就是核心价值,值得投入更高的实现成本。但如果只是个内部使用的代码脚手架,用户量小、使用频次低,全量生成虽然体验差点,但开发成本低、维护简单,反而是更合理的选择。这种表达展现的是工程权衡能力,实际工作中大部分时间都在做权衡取舍,很少有绝对的对错。
我们当时做 AI 代码审查功能,初期用的全量生成,提交一个 Pull Request,系统完整分析所有文件然后给出审查报告。后来发现大型 PR 等待时间太长,用户体验很差。改成增量生成后,可以边分析边返回问题,体验确实好了,但出现了一个新问题——如果代码改动跨多个文件,增量分析可能遗漏一些关联性问题。最后我们采用了分层策略,语法检查、代码规范这些局部问题用增量实时反馈,架构一致性、模块依赖这些全局问题放到后台做全量分析,分两个时间节点给反馈。这个案例展现的是问题分解能力和迭代优化思维,真实的纠结和反复才更有说服力。
现在行业的趋势是从单纯的增量或全量,走向智能混合策略。模型会根据上下文自动判断该用哪种方式,甚至在一次生成过程中动态切换。像 Claude 的 Artifacts 功能,你跟它对话让它生成代码,一开始是全量生成给你一个完整实现,但当你说"把这个函数改成异步的"时,它会切换到增量模式,只修改相关部分。这种上下文感知的生成策略,才是真正符合开发者自然交互习惯的方式。
代码生成技术的演进,其实反映的是我们对人机协作模式的理解在不断深化。早期的代码生成都是批处理式的,开发者准备好输入、等待输出、然后继续工作,这是人适应机器的逻辑。现在增量生成、流式交互这些技术,本质上是让机器去适应人的思维节奏——我们写代码本来就是增量的、是边想边写的,工具应该跟上这个节奏,而不是打断它。这种对技术本质的理解,才是真正有价值的认知。