精炼回答
直接说结论:代码生成的可靠性目前还无法达到生产级别的直接使用标准,需要通过多层手段来提升质量。这不是对AI能力的否定,而是对工程质量的基本敬畏。
从模型层面看,提示词工程是基础保障。你需要明确描述需求、约束条件、代码规范,甚至提供示例代码让模型参考。使用思维链提示可以让模型分步骤生成,减少逻辑错误。上下文注入也很关键,把相关的类定义、接口文档、已有代码片段喂给模型,能显著提高生成代码的适配性。
从工程层面看,生成后必须经过验证流程。静态检查用linter和类型检查工具快速发现语法和类型错误;单元测试是核心防线,要为生成的函数编写测试用例验证逻辑正确性;对于关键业务代码,还需要人工code review。有些团队会采用迭代生成策略,先生成框架代码,跑测试后把报错信息反馈给模型让它修正,这种自我修复机制能解决不少问题。
实际应用中,不同场景可靠性差异很大。生成标准的CRUD接口、数据转换函数这类模式化代码成功率较高,可以直接用或稍作调整;但涉及复杂业务逻辑、性能优化、并发控制的代码,生成结果往往只能作为参考原型,需要大量人工介入。所以现阶段把AI当作编程助手而非替代品是更现实的定位。
扩展分析
谈代码生成的可靠性,我们需要先建立一个认知框架:代码的可靠性不是一个单一标准,而是三个层次的递进——语法层面能不能跑起来、逻辑层面是不是真的解决了问题、安全层面会不会带来风险。
语法正确性是最基础的,现在的代码生成模型在这方面表现已经相当不错,生成的代码大概率能通过编译或解释器检查。但语法正确只是及格线,更大的挑战在逻辑正确性。比如让AI生成一个计算订单折扣的函数,它可能生成了语法完美的代码,但折扣叠加的优先级、边界条件的处理往往不符合实际业务规则。会员日折扣和满减活动能不能同时用?新用户首单优惠和品类券冲突时按什么规则处理?这些业务细节AI很难完全理解。
安全性这个维度特别能体现工程成熟度。生成的代码可能无意中引入SQL注入风险、硬编码密钥、或者绕过权限检查。AI生成数据库查询时,有时会直接拼接字符串而不用参数化查询,这种代码如果直接上线就是安全隐患。我见过生成的文件上传接口没有校验文件类型和大小,也没有做路径穿越检查,这在生产环境就是重大安全事故的导火索。
目前的代码生成工具在处理标准化、模式化的任务时表现不错,但面对复杂业务逻辑时还是会暴露出明显的短板。生成简单的数据转换、API调用封装这类代码,成功率可能在80%以上,稍作调整就能用。但如果是生成涉及多表关联查询优化的代码,或者需要处理分布式事务的逻辑,生成结果往往只能作为思路参考,需要大量人工重构。我把代码生成工具定位为高级代码补全和原型生成器,而不是自动化开发的银弹。
质量保障不是单点防御,而是多层防护网。代码生成出来之后,首先要跑静态检查工具,这能快速拦截语法错误和明显的类型问题。用Checkstyle或者SonarQube之类的工具做自动化扫描,能在几秒钟内发现潜在的代码异味。
静态检查只是第一道关卡,单元测试才是核心防线。对于生成的函数,必须编写测试用例覆盖正常路径和边界条件。比如生成了一个解析JSON的工具方法,需要测试正常格式、空值、格式错误等场景。有时候我会先写测试用例,再让AI生成满足测试的实现,这种测试驱动的方式能显著提高生成代码的质量:
// 测试先行的思路能约束AI生成更健壮的代码
@Test
publicvoidtestParseOrderData(){
// 正常情况
Order order =OrderParser.parse("{\"orderId\":\"123\",\"amount\":100}");
assertEquals("123", order.getOrderId());
// 边界条件
assertThrows(IllegalArgumentException.class,
()->OrderParser.parse(""));
assertThrows(IllegalArgumentException.class,
()->OrderParser.parse(null));
}
单元测试之后还要考虑集成测试,特别是生成的代码涉及外部依赖时。如果生成的是调用第三方服务的代码,必须在测试环境验证它能否正确处理超时、重试、降级这些场景。代码不是孤立运行的,和其他模块的交互是否正常,这是集成测试要验证的。
无论自动化测试做得多完善,关键代码的人工审查都不能省。涉及资金计算、权限控制、数据加密这类核心逻辑,必须至少两个人做Code Review。审查的重点除了看逻辑正确性,还要关注性能瓶颈、潜在的并发问题、日志是否完善这些容易被忽略的细节。
不是所有代码都要用同样的标准来要求可靠性,这种场景化思维特别重要。如果是写个数据分析脚本或者测试工具,生成的代码跑通了基本就能用,因为影响范围可控。生成一个批量修改文件名的Python脚本,或者生成一个数据格式转换的小工具,这种情况下快速验证结果正确性,没问题就直接用。因为这类代码通常是一次性或低频使用,出错了影响范围也有限。
但核心业务代码就是另一回事了。如果是生成订单状态机的核心逻辑,或者库存扣减的代码,那生成结果只能作为起点。这些逻辑涉及钱和数据一致性,出错的代价太高,所以必须经过完整的开发流程——详细设计、多轮测试、灰度验证,不能因为是AI生成就降低标准。
安全敏感场景更要单独强调。涉及用户认证、权限校验、敏感数据处理的代码,基本不会直接用AI生成的版本。这类代码的安全模型往往有特定的公司规范和合规要求,AI生成时很难完全符合,而且安全漏洞的代价是灾难性的。宁可多花时间人工编写,也不能为了效率在安全上妥协。
代码生成工具在几类任务上特别高效——生成样板代码、编写单元测试框架、生成API客户端封装、写数据迁移脚本。这些场景的共同点是模式相对固定,业务复杂度低,出错后容易发现和修正。相应的,复杂的业务编排、性能敏感的底层优化、需要深度理解领域知识的算法实现,这些场景不要指望AI生成出高质量的代码。这些场景下AI生成的代码往往缺乏全局视角,可能实现了局部功能但引入了架构层面的问题。
整个过程应该是人机协作的迭代循环。AI负责生成初版代码框架,人来补充业务逻辑和异常处理;或者人写核心算法,让AI生成周边的辅助函数和测试代码。2025年的一些开发工具已经支持把测试失败信息反馈给AI,让它自动修正代码。这个循环是:生成代码、跑测试、分析错误、调整提示词、重新生成。这种自动修复也有边界,通常迭代三轮还不行,就说明问题定义不清楚或者超出AI能力了,这时候需要人工介入重新思考方案。
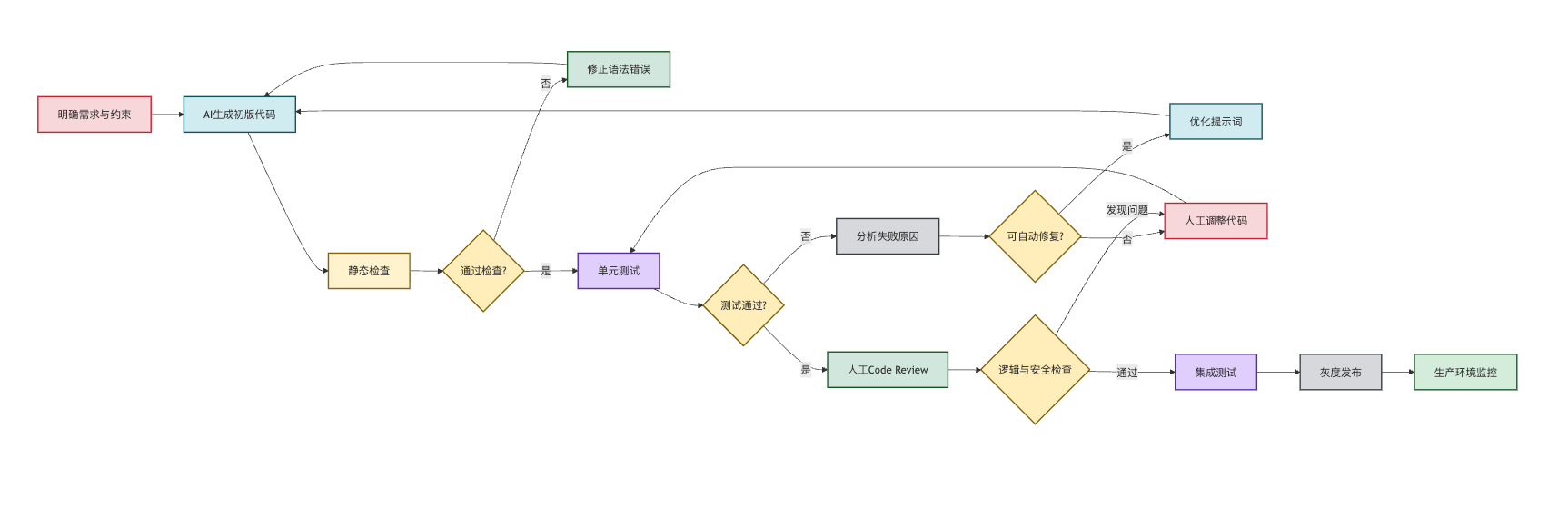
实战经验与前瞻思考
使用代码生成工具必须有一套标准流程,从需求明确到最终上线,每个环节都有对应的检查清单。生成代码之前要做好准备工作,整理好需求的边界条件、输入输出格式、异常场景,甚至把相关的接口定义、现有代码片段都准备好。这个准备过程其实就是在帮AI建立上下文,投入越充分,生成质量越高。还要明确告诉AI要遵循什么编码规范,比如要用Builder模式还是工厂模式,要不要加日志埋点,这些约束条件说清楚能少走很多弯路。
边界测试最容易被忽略,但往往能暴露生成代码的致命问题。生成了一个分页查询的方法,要专门测试页码为0、负数、超大值这些边界情况,还有查询结果为空的场景。比如这样的代码:
publicclassProductQueryService{
publicPageResult<Product>queryProducts(int pageNum,int pageSize){
// AI生成的代码可能缺少边界检查
if(pageNum <1){
thrownewIllegalArgumentException("页码必须大于0");
}
if(pageSize <1|| pageSize >100){
thrownewIllegalArgumentException("每页条数必须在1-100之间");
}
// 实际查询逻辑...
}
}
异常处理的检查是另一个重点。生成的代码要特别关注异常处理是否完整,比如调用外部接口有没有处理超时和网络异常,数据库操作有没有事务回滚。AI生成的代码往往只实现了happy path,对于异常情况要么不处理,要么就是简单粗暴地抛出去,这在生产环境是不可接受的。
性能评估容易被忽视但很重要。对于可能成为热点的代码,要做基准测试验证性能是否符合预期。如果生成的是一个数据转换方法,处理大列表时要测试它的时间复杂度和内存占用,确保不会在生产环境成为瓶颈。我遇到过生成的数据同步方法,它对每条记录都单独执行一次数据库更新,结果处理一万条数据要跑半小时。后来改成批量更新,时间缩短到几十秒。
单元测试生成是成功率最高的场景,效率提升特别明显。先写好待测试的方法,然后让AI生成测试用例覆盖各种场景。这个场景成功率高是因为测试代码的模式性很强,而且生成出来后立刻能跑,验证成本低。样板代码生成也是高价值场景,像DTO转换、Builder类、API客户端封装这种结构化很强的代码,基本都可以让AI来生成。
但也要清醒认识到,并发安全问题最容易被忽略。AI生成了一个缓存工具类,单线程测试完全正常,但上线后高并发场景下偶发数据错乱,后来发现是生成的代码用了非线程安全的数据结构。这个案例之后,我们规定凡是会被多线程访问的生成代码,必须经过并发测试。还有一次让AI生成一个文件上传的接口,它生成的代码没有校验文件类型和大小,也没有做路径穿越检查,这种代码如果直接上线就是重大安全事故。
团队推广需要解决规范统一的问题。个人用AI编程工具可以提效,但在团队层面要制定生成代码的提交规范,比如要求commit message里标注哪些部分是AI生成的、要求生成代码必须附带对应的测试用例、强制经过特定的代码审查流程。我们团队会根据代码的影响范围来分级制定标准,把生成的代码分成工具类、业务逻辑类、核心交易类三个层级,每个层级对应不同的审查深度和测试覆盖率要求。比如工具类代码只要通过单元测试就能合入,但核心交易类代码必须经过架构师审查、压测验证、灰度发布这一整套流程。
采用分阶段应用策略能降低风险。最开始只在测试代码、脚本工具、内部管理后台这些容错性高的地方用,等团队形成了一套验证规范,再考虑在主链路代码中使用。渐进式验证也很重要,不要一次性生成一大块代码,而是分步骤生成,每一步都验证通过再继续。开发一个数据导入功能,先让AI生成文件解析部分,测试通过后再生成数据校验部分,最后生成入库逻辑。这种方式虽然慢一点,但每个环节都可控,出问题容易定位。
对于AI生成后上线的代码,要特别关注它的运行指标,至少观察一个完整的业务周期。加详细的日志埋点,监控方法的调用量、耗时分布、异常率,一旦发现异常立刻人工介入排查。这种谨慎态度是对生产环境质量的基本敬畏。
代码生成正在从单纯的文本生成向理解项目上下文的方向演进。2025年的一些工具已经能索引整个代码仓库、读取项目文档、理解架构设计,生成的代码更贴合实际项目的技术栈和编码风格。MCP这类协议的出现,让AI能更好地访问项目知识库和开发工具链,这会显著提升生成代码的适配性。但技术在进步,可靠性保障的核心原则不会变——测试覆盖、人工审查、灰度验证这些环节依然是质量防线。
未来团队需要建立的是AI辅助开发的治理体系,而不仅仅是使用工具。这个体系包括什么场景适合用AI、生成代码的质量门禁、安全合规的审查机制、效率与风险的平衡策略。建立内部的代码生成最佳实践库、定期复盘AI生成代码的线上问题、组织团队分享会交流使用经验,这些都是治理体系的重要组成部分。代码生成工具确实能提效,但实践应用的核心是建立一套完整的质量保障体系。工具在进化,但工程规范和质量标准不能因为使用了AI就放松。让AI做它擅长的模式化工作,把人的精力聚焦在业务理解、架构设计、质量把控这些AI还做不好的环节,这才是人机协作的正确打开方式。