精炼回答
多跳问答需要RAG系统通过多次检索和推理才能得到答案,比如"ChatGPT的开发公司CEO是谁"需要先查到OpenAI,再查Sam Altman。处理这类问题,核心是将复杂问题分解成检索链路,让系统具备"边查边想"的能力。
实践中主要有几种做法。最直接的是迭代检索,让LLM根据初次检索结果判断是否需要继续查询,生成新的检索query,直到信息充足。这需要设计好停止条件,避免无限循环。更主动的方式是查询分解,先让LLM把问题拆成子问题序列,按依赖关系逐个检索并聚合答案,像上面例子就拆成"ChatGPT开发公司"和"该公司CEO"两步。
技术上还会用图结构增强,把知识库预处理成实体关系图,通过图遍历找多跳路径。或者采用自我提问机制,让模型在推理过程中主动生成需要补充的问题再检索。关键是上下文管理,每次检索要把前序结果带上,让模型理解完整推理链。现在也有混合方案,结合dense retrieval做初筛和reranker做精排,每一跳都保证检索质量。实际部署时要注意延迟控制,多跳会增加响应时间,通常限制在2-3跳内,并行检索可以加速但要处理好信息融合。
扩展分析
多跳问答的本质特征是答案依赖多个有逻辑关联的知识片段,需要像接力赛一样,用前一次检索的结果去触发下一次检索。传统RAG的设计假设是"一次检索就能命中答案",它会把用户问题直接向量化去匹配文档,但多跳问题的中间线索根本不在原始提问里。就像问"上个季度销量最高的品牌创始人是谁",如果直接用这句话去检索,很难同时匹配到销售数据和人物百科这两类文档,这就是传统pipeline失效的根本原因。
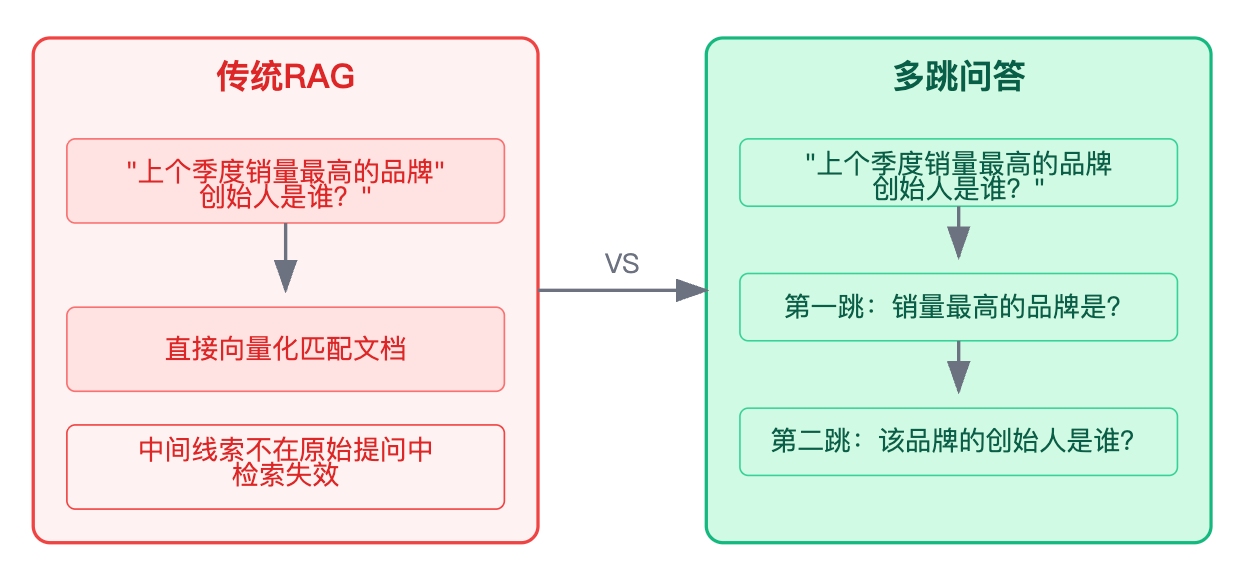
多跳问答的难点不仅仅是"检索多次"这么简单,而是涉及到三个层面的技术问题。
查询分解问题首当其冲,系统怎么知道要把原始问题拆成哪几个子问题?这需要理解问题的逻辑结构,比如"华为最新款折叠屏手机的处理器制造商是哪国企业",你得识别出这里包含"产品识别→硬件查询→厂商溯源→国别判断"这样的推理链条。检索顺序问题同样关键,如果中间某一跳检索失败或者结果有歧义,整个推理链就会断掉。结果融合问题是工程实现中最棘手的部分,每一跳检索回来的信息可能都有噪音,如何把多次检索的结果整合成连贯的推理过程,还要避免错误累积放大,这直接决定了系统的实用性。
迭代检索方案的核心思路是把检索过程变成一个循环,让LLM像侦探一样逐步收集线索。具体来说,系统先用原始问题做第一次检索,然后把检索结果交给LLM判断"信息够不够回答问题",如果不够就让LLM生成下一个查询问题继续检索,直到LLM认为信息充足或达到最大迭代次数。这种方案的优点是灵活性强,不需要预先规划推理路径,缺点是容易陷入无效循环,而且每次判断都要调用LLM,延迟会比较高。适合那种推理路径不固定、探索性比较强的场景。
publicclassIterativeRetriever{
privatestaticfinalint MAX_ITERATIONS =3;
privateLLMService llmService;
privateVectorSearchService vectorSearch;
publicStringretrieve(String question,List<String> context){
for(int hop =0; hop < MAX_ITERATIONS; hop++){
String query =generateQuery(question, context);
List<Document> docs = vectorSearch.search(query,5);
context.addAll(extractContent(docs));
if(shouldStop(question, context)){
break;
}
}
returnsynthesizeAnswer(question, context);
}
privatebooleanshouldStop(String question,List<String> context){
String prompt =String.format(
"问题:%s\n已知信息:%s\n"+
"判断已知信息是否足够回答问题。"+
"如果足够返回STOP,否则返回CONTINUE: 缺少xxx信息",
question,String.join("\n", context)
);
String decision = llmService.call(prompt);
return decision.startsWith("STOP");
}
privateStringgenerateQuery(String question,List<String> context){
if(context.isEmpty()){
return question;
}
String prompt =String.format(
"原始问题:%s\n已知信息:%s\n"+
"基于已知信息,生成下一个检索查询来补充缺失的信息:",
question,String.join("\n", context)
);
return llmService.call(prompt);
}
}这里面最关键的是停止条件判断逻辑,要明确告诉模型"如果现有信息足够回答问题就返回STOP,如果还缺关键信息就返回CONTINUE并说明缺什么"。这个设计能避免无限循环的同时也保证了检索的充分性。
查询分解方案则是提前规划的思路,让LLM先把复杂问题一次性拆解成子问题序列,然后按照依赖关系逐个执行检索。可以举个金融领域的例子:问"特斯拉最大机构股东持有的科技股中哪支今年涨幅最高",可以先拆成"特斯拉最大机构股东是谁"、"该股东持有哪些科技股"、"这些股票今年涨幅分别是多少"三个子问题,每个子问题的答案都为下一个问题提供检索条件。这种方案的好处是推理路径清晰可控,便于调试和优化,但对问题分解的准确性要求很高,如果第一步拆解错了,后面就全错了。
publicclassQueryDecompositionRetriever{
privateList<SubQuestion>decompose(String question){
String prompt =
"将问题分解为有依赖关系的子问题序列,"+
"输出JSON数组,每个元素包含id、question和depends_on字段。\n"+
"原问题:"+ question;
String response = llmService.call(prompt);
returnparseSubQuestions(response);
}
publicStringanswerWithDecomposition(String question){
List<SubQuestion> subQuestions =decompose(question);
Map<String,String> answers =newHashMap<>();
for(SubQuestion sq : subQuestions){
String enrichedQuery =enrichQuery(sq, answers);
List<Document> docs = vectorSearch.search(enrichedQuery,5);
String answer =extractAnswer(docs, sq.getQuestion());
answers.put(sq.getId(), answer);
}
returnsynthesizeFinalAnswer(question, answers);
}
privateStringenrichQuery(SubQuestion sq,Map<String,String> answers){
if(sq.getDependsOn().isEmpty()){
return sq.getQuestion();
}
StringBuilder enriched =newStringBuilder(sq.getQuestion());
for(String depId : sq.getDependsOn()){
enriched.append(" 已知:").append(answers.get(depId));
}
return enriched.toString();
}
}这里的enrichQuery方法很关键,它要把前序子问题的答案拼接到当前查询里,让检索能基于已知信息进行。比如第一跳查到"最大股东是贝莱德",第二跳的query就要变成"贝莱德持有的科技股有哪些"而不是原始的笼统问法。
图推理方案的设计思想是把知识库预处理成实体关系图,把检索问题转化为图遍历问题。比如知识库里存着"公司A→CEO是→张三"、"张三→毕业于→清华大学"这样的三元组关系,当问"公司A的CEO毕业于哪所大学"时,系统就在图上找从"公司A"到"大学"这个路径。这种方案的优势是推理路径可解释性强,而且可以利用图算法优化检索效率,但前提是知识库得结构化程度很高,而且构建和维护知识图谱的成本不低。更适合知识边界清晰、实体关系稳定的领域,比如医疗诊断、法律咨询这类专业场景。
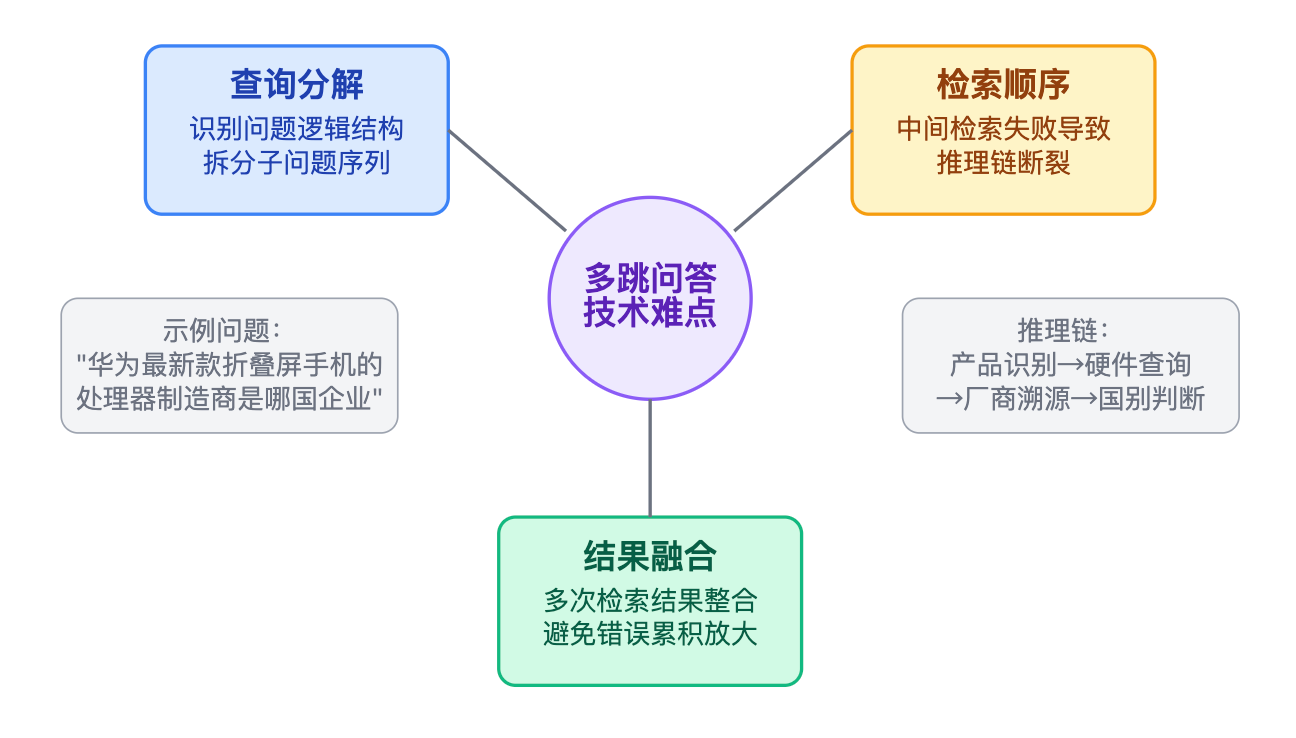
 现在比较前沿的是Agent框架方案,把整个多跳推理过程建模成Agent的规划和执行过程。系统会先制定一个推理计划,然后调用不同的工具(检索、计算、API调用等)来逐步执行,每一步都有反思和修正机制。这种方案的能力上限很高,可以处理非常复杂的推理任务,但工程复杂度也最高,需要解决工具调用的可靠性、异常处理、成本控制等一系列问题。适合那些对准确性要求极高、愿意投入较大工程资源的核心业务。
现在比较前沿的是Agent框架方案,把整个多跳推理过程建模成Agent的规划和执行过程。系统会先制定一个推理计划,然后调用不同的工具(检索、计算、API调用等)来逐步执行,每一步都有反思和修正机制。这种方案的能力上限很高,可以处理非常复杂的推理任务,但工程复杂度也最高,需要解决工具调用的可靠性、异常处理、成本控制等一系列问题。适合那些对准确性要求极高、愿意投入较大工程资源的核心业务。
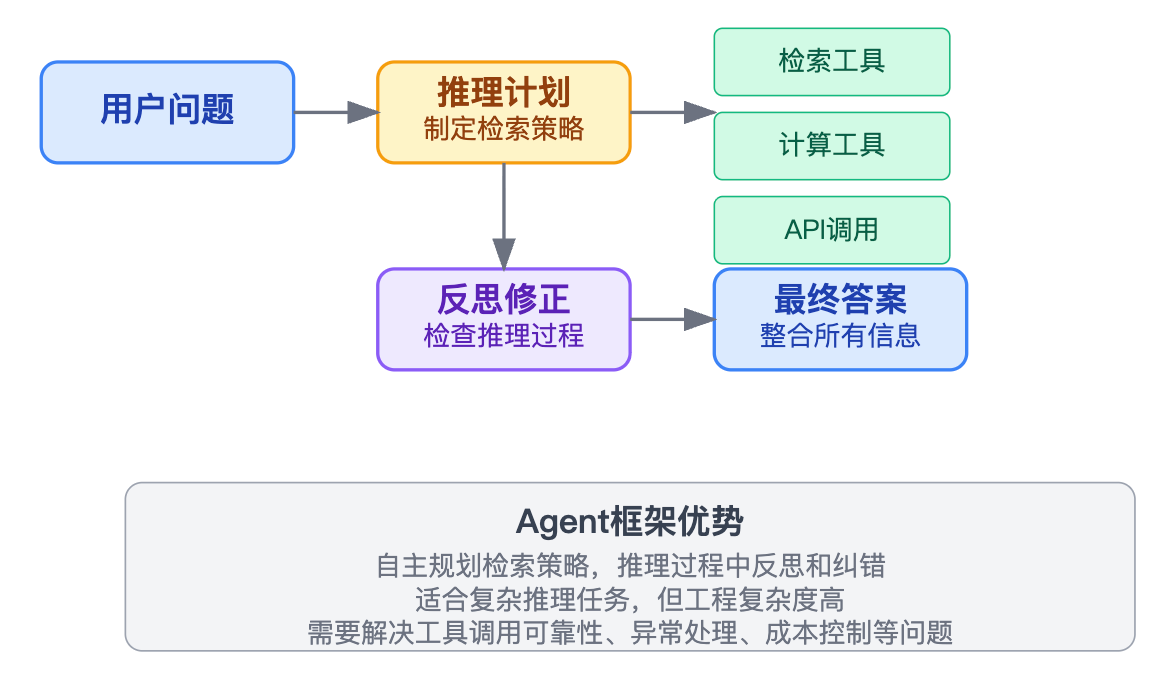
选择方案主要看三个维度的平衡。问题复杂度是第一考量,如果多跳推理的步骤通常在2-3步以内且模式比较固定,查询分解方案就够用了,没必要上Agent框架这种重型方案。准确性要求决定了你能容忍多少错误,如果是客服问答这种容错性高的场景,迭代检索可能就行,但如果是医疗诊断建议这种高风险场景,就得用图推理或Agent框架来保证推理过程的可靠性。资源成本也不能忽视,每多一跳就多一次LLM调用和检索请求,延迟和费用都会增加。实际项目中通常会设置最大跳数限制,或者用混合方案,把常见的多跳模式用查询分解固化下来,只对复杂case才启用迭代检索或Agent框架,这样能在成本和效果之间找到平衡点。
进阶思考
并不是所有看起来复杂的问题都值得用多跳处理,关键是看收益成本比。如果一个问题用单次检索能勉强回答,准确率能达到70%,但上多跳方案后准确率提升到85%,代价是延迟从500ms变成2秒,那在搜索推荐这种对延迟敏感的场景里就不划算。
但如果是法律咨询或者医疗建议,15%的准确率提升可能就意味着避免一次误诊,这时候2秒延迟完全可以接受。实际工程中可以先用规则筛选,比如检测问题里有没有"最...的...又..."这种嵌套结构,或者用一个轻量级分类器预判问题复杂度,只对真正需要的场景启用多跳推理。
成本控制需要算清楚账。假设单次LLM调用成本是0.01元,一次向量检索是0.001元,传统单跳RAG一个问题成本大概0.015元,但如果每个问题都走3跳,成本就变成0.045元,涨了3倍。如果系统日均10万次调用,一年成本差距就是百万级别。所以要有精细化的成本管控策略,比如用Prompt缓存降低重复调用成本,对高频查询路径做物化视图,避免每次都重新推理。更重要的是建立问题分级机制,核心业务问题可以放开跳数限制保证质量,长尾问题就严格限制资源消耗。
从技术演进趋势来看,Agent框架正在改变多跳问答的范式,传统方案是系统预设推理路径,但Agent可以自主规划检索策略,甚至在推理过程中反思和纠错。更激进的方向是自适应推理,系统根据知识库特点和问题分布自动学习最优的跳数和检索策略,不需要人工调参。还有混合检索策略,把稠密检索的语义理解能力和稀疏检索的精确匹配能力结合起来,每一跳都动态选择最合适的检索方式。这些前沿探索虽然还在发展阶段,但已经展现出了很大的潜力,值得持续关注和尝试。