精炼回答
代码克隆检测是识别代码库中重复或高度相似代码片段的技术,主要用于代码重构、漏洞传播分析和抄袭检测等场景。查找相似代码主要有几种技术路线。基于文本的方法直接比较源码字符串,通过计算编辑距离或使用指纹算法(如Rabin-Karp)快速匹配,但对格式变化敏感。基于词法的方法先将代码tokenize成词法单元序列,过滤掉空格、注释等干扰因素,然后用滑动窗口和哈希技术检测重复序列,像CCFinder就采用这种方式。基于语法的方法构建抽象语法树(AST),通过树匹配或子树比对来识别结构相似的代码,能容忍变量重命名等变化。基于语义的方法分析程序依赖图(PDG)或控制流图(CFG),判断代码功能是否等价,检测能力最强但计算开销大。
近年来深度学习方法开始流行,通过Code2Vec、CodeBERT等模型将代码编码成向量,用余弦相似度衡量代码相似性,能捕捉深层语义特征。实际应用中,工具如SonarQube用于持续集成中的克隆检测,帮助团队及时发现并消除重复代码;安全团队用它追踪已知漏洞代码的变种传播。选择哪种方法取决于你对精度、性能和容错能力的权衡需求。
扩展分析
从克隆类型到检测方法的完整认知
面试时被问到代码克隆检测,不要直接跳到技术细节,先用一句话把定义框架搭好:代码克隆检测就是找出代码库里那些长得差不多的代码片段,主要目的是避免重复维护、追踪安全漏洞传播、还有做代码质量分析。这样一开场就让面试官知道你理解它的业务价值,不是纯粹背概念。
接下来面试官很可能会追问"什么叫长得差不多",这时候可以顺势把克隆类型带出来。业界一般把克隆分四个等级来看,Type-1是除了空格注释完全一样的复制粘贴代码,最典型的场景就是两个开发同时收到需求要做输入校验,一个人直接复制了另一个人的代码。Type-2允许变量名和类型改了但逻辑一致,比如第二个开发觉得变量名userId不符合自己的习惯,改成了uid,或者把int改成了long,代码逻辑完全没变,这种文本比对就检测不出来了。
// Type-1克隆示例 - 完全相同
publicbooleanvalidateEmail(String email){
return email.matches("^[A-Za-z0-9+_.-]+@(.+)$");
}
// Type-2克隆示例 - 标识符改了
publicbooleancheckEmailFormat(String userEmail){
return userEmail.matches("^[A-Za-z0-9+_.-]+@(.+)$");
}
Type-3更狡猾,原始代码里有三行校验逻辑,后来有人在中间插了一行日志记录,或者把某个判断条件加强了,这时候整体结构还是相似的但局部有改动。这就涉及到相似度阈值设定的问题,一般认为70%-90%相似就算Type-3,具体阈值要根据团队对代码质量的容忍度来调。
// Type-3克隆示例 - 增删了部分语句
publicvoidprocessOrder(Order order){
validateOrder(order);
calculatePrice(order);
// 新增了库存检查
checkInventory(order);
saveOrder(order);
}
Type-4其实已经跳出传统克隆检测范畴了,它要解决的是功能等价但代码完全不同的情况,比如一个人用循环实现排序,另一个人用递归,文本、Token、语法树都不像,但功能就是一样的。检测Type-4本质上是在做程序等价性验证,这在学术界是个难题,工业界一般不会投入那么大成本去检测它,除非是做代码抄袭检测或者专利侵权分析这种特殊场景。
解决这四类克隆问题,业界的方案是从粗糙到精细一路演进过来的,每种方法都对应着特定的能力边界。最早的工具直接用字符串比对,像Unix的diff命令那样逐行对比,或者用Rabin-Karp这种滚动哈希算法快速找重复子串,速度飞快但只能检测Type-1,你哪怕多敲个空格都会漏掉。所以后来就有人想,能不能先把代码标准化,去掉所有空格和注释再比对,这就过渡到了Token级别的处理。
词法分析器把源码切成一个个Token,像if、(、userId这些,然后把变量名和字面量都做归一化处理,比如统一替换成VAR和LITERAL,这样Type-2克隆就现形了。CCFinder就是这么干的,它用滑动窗口扫描Token序列,配合后缀树算法快速找到重复模式,在大型代码库上跑得很快。Token级别的好处是可以做大规模批量处理,几十万行代码扫一遍也就分钟级别。
// Token序列示例(归一化后)
// 原始代码: int userId = 100;
// Token序列: TYPE VAR ASSIGN LITERAL SEMICOLON
// 另一段代码: long uid = 200;
// Token序列: TYPE VAR ASSIGN LITERAL SEMICOLON
// 归一化后这两段代码的Token序列完全一致
语法树抓住的是代码的结构骨架,两个函数就算变量名全不一样,只要它们的控制流结构——比如先判断后循环再赋值——是一致的,树同构算法就能把它们配对出来。比如一个if-else结构在AST里就是一个判断节点带两个子树,不管你判断条件写的是x > 0还是amount > threshold,树的形状是固定的。像做代码重构工具的时候,就特别依赖AST比对来找到可以合并的相似逻辑。
前面那些方法都还是在看代码怎么写的,语义级别要看代码做了什么,这时候就要构建程序依赖图——把数据依赖和控制依赖关系都标出来,两段代码如果依赖图同构,就说明它们在语义上等价。当然这种分析计算量很大,需要做符号执行或者抽象解释,一般只在安全审计或者关键系统验证时才会用到。在漏洞扫描场景下,语义分析能发现那些把危险函数换了个马甲的变种攻击代码。
现在2025年了,深度学习方法是必须要讲的加分项。这两年大模型起来之后,代码检测领域也迎来了范式转变,传统方法都是基于规则的硬匹配,深度学习是让模型自己学代码的语义表示。像CodeBERT、GraphCodeBERT这些预训练模型,它们在几百万个开源项目上学过,能把一段代码编码成768维的向量,然后你只需要算余弦相似度就能判断两段代码像不像,连注释的语义都能考虑进去。有些公司开始用这套方案做代码审查,当开发提交Pull Request时,自动检测是不是有人在其他模块已经实现过类似功能,避免重复造轮子。
// 使用预训练模型做相似度检测的伪代码
CodeEncoder encoder =newCodeBERTEncoder();
Vector vec1 = encoder.encode("public int add(int a, int b) { return a + b; }");
Vector vec2 = encoder.encode("public int sum(int x, int y) { return x + y; }");
double similarity =cosineSimilarity(vec1, vec2);// 0.95+
如果你要在CI流水线里做实时检测,肯定优先选Token级别的方案,因为快;如果是做定期的代码质量审计,可以上AST方案,精度更高;安全团队做漏洞追踪时可能需要语义分析;而研发效能团队想做智能推荐,那就得考虑深度学习方案。说这段话要有节奏感,让面试官感受到你是在做架构权衡而不是背书。
工程落地的完整路径
面试官听完你的理论框架后,通常会切入一个更实战的问题:"你们实际项目中怎么用这套技术的?"这个问题才是真正拉开差距的地方,因为面试官想知道你是不是真正落地过,还是只停留在理论层面。
实际项目中我们得先看具体诉求是什么,如果是想快速集成到CI流水线做每日扫描,SonarQube是个不错的选择,它本身就是个代码质量平台,克隆检测只是其中一个维度,配置简单而且有可视化报告。SonarQube底层用的是基于Token的检测算法,支持Java、JavaScript、Python这些主流语言,扫描速度在可接受范围内,几十万行代码大概十几分钟就能出结果。但如果你的代码库特别大,或者需要离线批量分析,CCFinder可能更合适,它是专门做克隆检测的工具,用后缀树算法优化过,处理百万行级别代码也很稳定。
我见过有团队一开始用PMD CPD这种轻量级工具,它是PMD静态分析套件的一部分,配置一个Gradle插件就能跑,适合小团队快速试水。但它的问题是检测粒度比较粗,误报率高,后来团队规模上来后还是切到了更成熟的方案。这种对比能展示你对不同阶段技术选型的理解,比单纯推荐一个工具要有说服力得多。
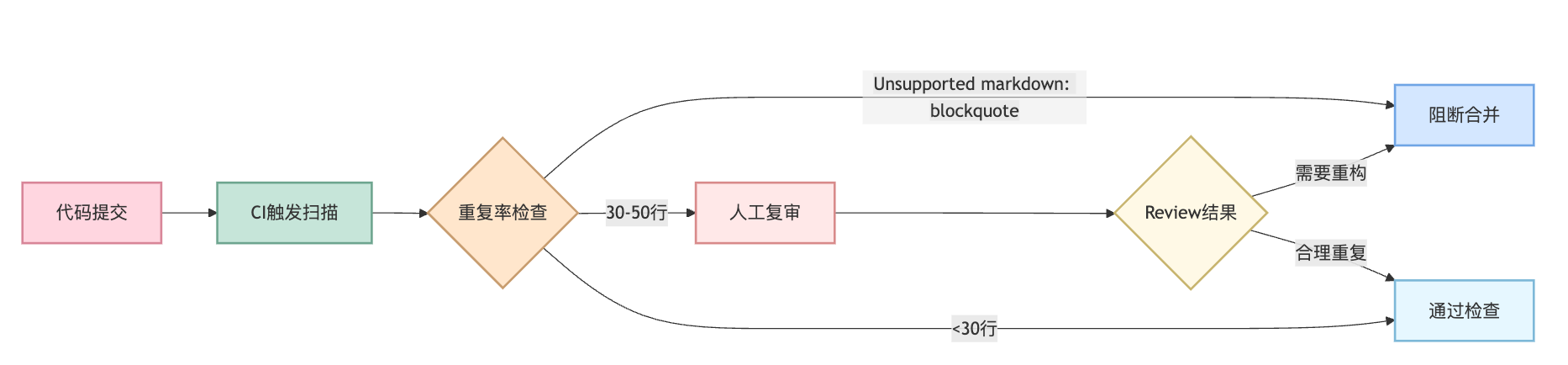
真正的实施方案要从CI/CD集成讲起,因为这是工业界最常见的落地方式。实际落地时,我们会把检测分成两个阶段,开发阶段在IDE里集成轻量级插件做实时提示,比如IntelliJ IDEA的Duplicate Code检测功能,让开发者在写代码时就能意识到重复问题。然后在代码提交时,GitLab CI或Jenkins流水线里配置SonarQube Scanner,每次MR都自动扫一遍,如果重复率超过阈值就阻断合并。阈值设定很关键,我们一般会设两档,重复超过50行且相似度95%以上的直接Block,30-50行之间的只是Warning让人工复审,这样既保证了拦截效果又不会让开发者觉得太烦。
// Jenkins Pipeline配置示例
pipeline {
stages {
stage('CodeCloneDetection'){
steps {
script {
def scannerHome = tool 'SonarScanner'
withSonarQubeEnv('SonarQube'){
sh """
${scannerHome}/bin/sonar-scanner \
-Dsonar.projectKey=myproject \
-Dsonar.cpd.minimumLines=30 \
-Dsonar.cpd.minimumTokens=100
"""
}
}
}
}
stage('QualityGate'){
steps {
timeout(time:5, unit: 'MINUTES'){
waitForQualityGate abortPipeline:true
}
}
}
}
}
拿支付系统来说,风控逻辑经常会被复制到多个支付渠道里,微信支付一套、支付宝一套、银联又是一套,表面上看是独立模块,但风控规则其实高度相似。这时候如果某个规则出现漏洞,克隆检测能帮你快速定位到所有受影响的代码位置,不用靠人工搜索或者靠开发回忆。我听说有个团队通过克隆检测发现了17处重复的金额计算逻辑,后来统一抽取成公共方法后,不仅减少了30%的维护成本,还避免了一次因为只改了部分克隆代码导致的线上故障。
检测出来的克隆代码不能一刀切全部重构,要区分对待。如果是业务逻辑克隆,优先考虑提取公共方法或者用策略模式重构;如果是配置相关的重复,可能抽成配置文件更合适;但如果是测试代码里的重复,有时候为了可读性保持一定重复反而是合理的。我见过有团队过度追求消除重复,把两段看起来像但业务语义完全不同的代码强行合并,结果后来需求一改,改一个地方就影响了另一个不相关的模块,反而增加了耦合度。
实际项目里不可能一次性把所有克隆代码都消除掉,得有个优先级策略。我们一般会按照几个维度评分:重复代码的行数、出现频率、所在模块的核心程度、变更频率这些,算出一个综合分数,优先处理那些高频变更的核心模块里的大段重复代码。比如一个被复制了5次的100行支付逻辑,比一个只重复2次的10行工具方法优先级要高得多,因为前者一旦出问题影响面大,而且每次改需求都得改5个地方,维护成本指数级增长。
开源项目里用克隆检测还能做License合规检查,比如你的项目是MIT协议,但某个开发从GitHub复制了一段GPL协议的代码进来,这种潜在的法律风险通过代码相似度检测能提前发现。现在有些工具结合大模型能力,不仅检测代码文本相似度,还能通过语义理解判断是不是从特定开源项目借鉴的逻辑,即使开发者改写过也能追溯到源头,这在商业软件开发里特别有价值。
架构视野与长期思考
面试官通过代码克隆检测这道题,表面在考你对技术的理解,实际是在透视你的工程素养和架构视野。追问的方向通常会往几个地方走。面试官可能会问"你们团队克隆率控制在什么水平",这时候别直接说百分比数字,要带着上下文说:不同类型项目阈值不一样,核心支付模块我们要求克隆率控制在5%以内,因为一处改动牵扯多处风险太大,但工具类库可能会放宽到15%,因为有些通用逻辑重复是合理的。如果他追问"大规模代码库怎么做检测",你可以说:百万行级别的项目全量扫描开销大,我们会做增量检测,每次只扫描变更的文件和它依赖的模块,配合缓存机制把扫描时间控制在分钟级别,否则开发者等不起。
传统方法依赖人工设计特征,像Token序列、AST结构这些都是研究者观察总结出来的规则。大模型的优势在于它能自己学习代码的深层表示,GraphCodeBERT不仅看代码文本,还结合了数据流图的结构信息,能捕捉到变量之间的语义关联。但深度学习方案也不是银弹,模型推理需要GPU资源,对小团队来说成本是个考量点,而且黑盒特性导致误报时很难解释原因,传统方法反而更透明可控。
有次我们发现订单处理模块的异常处理逻辑被复制到了八个地方,后来产品改需求要加一种新的异常类型,结果有两个开发只改了自己负责的模块,导致其他六个地方遗漏了。这次事故后我们强推了克隆检测,把重复逻辑抽成统一的异常处理器,不仅代码量减少了40%,后续改动点也从八个收敛到一个。这种有问题场景、解决方案、量化收益的完整叙述,比单纯说"我用过SonarQube"有说服力得多。
克隆检测用的代码向量化技术,现在也被用在代码搜索场景,开发者输入一段自然语言描述,模型就能从代码库里检索出功能相似的代码片段。再往前走一步就是智能补全和代码生成,本质都是在学习代码的语义空间。这种把单点技术串成技术图谱的能力,能让面试官感觉你不是在孤立地学技术,而是在构建自己的知识体系。
很多人觉得克隆检测是代码洁癖,但站在系统演化的角度看,代码重复率其实是架构腐化的先导指标。当一个模块的克隆率突然飙升,往往意味着抽象层次设计得不够好,开发者找不到合适的复用点只能复制粘贴。这时候就需要架构师介入,看是不是该重新梳理领域模型,把隐含的共性逻辑显式化。克隆检测不是一次性动作,我们会定期生成代码健康度报告,追踪克隆率的变化趋势。如果发现某个模块的克隆率持续上升,可能意味着架构设计有问题,需要及时介入重构。同时在代码审查时,Review工具会自动标注出新增的重复代码,提醒审查者关注,这样能从源头控制技术债务的增长。