精炼回答
单元测试生成本质上是在代码质量保障和开发效率之间找平衡点。传统手工编写测试最可靠但太耗时,现在的自动化方案让这件事变得更实用了。
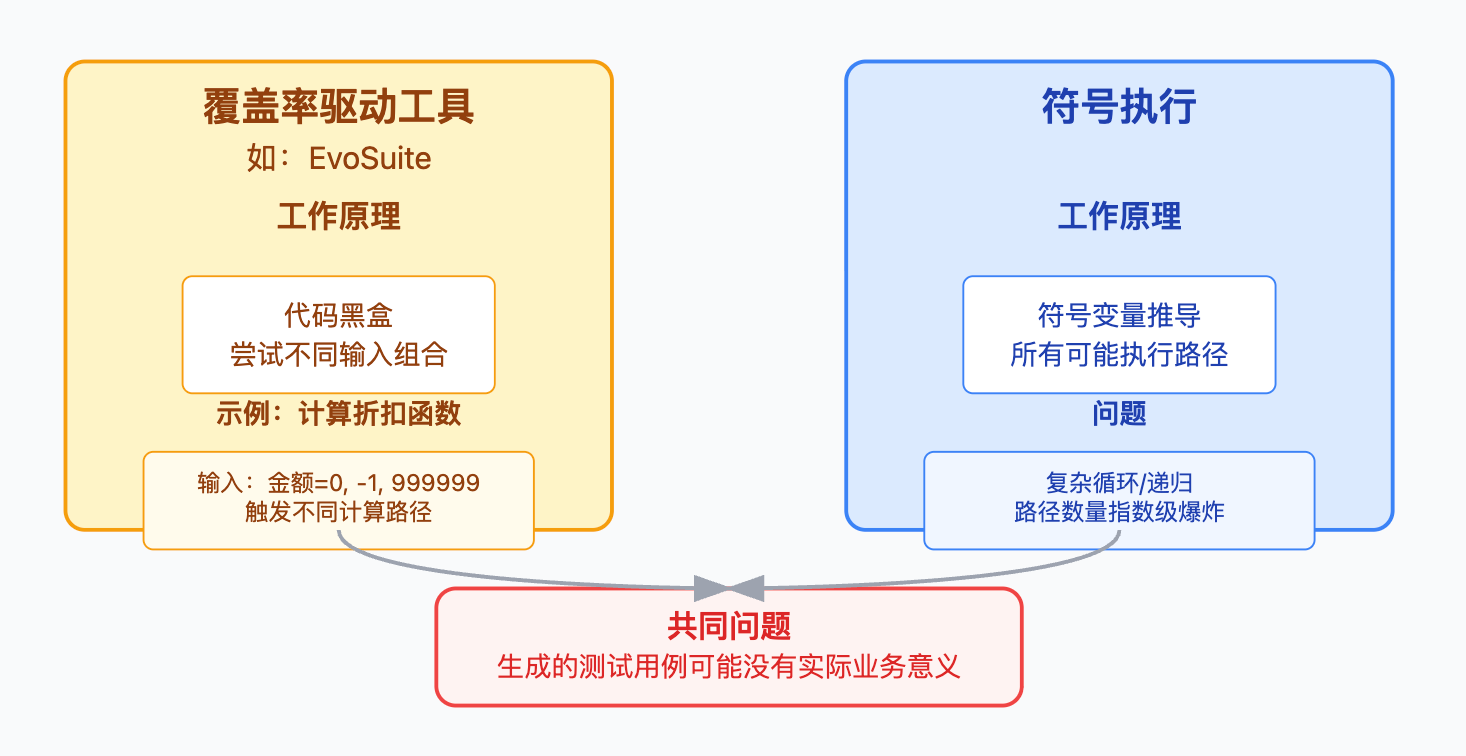
自动生成测试用例主要有三个技术方向。基于代码覆盖率的工具像EvoSuite、Randoop会分析代码结构,自动生成各种输入参数组合来提高分支覆盖率和路径覆盖率,它们的优势是能快速达到高覆盖率指标,但生成的测试用例往往缺乏业务含义。基于AI的工具像GitHub Copilot、ChatGPT这类能理解代码语义,生成的测试更符合实际业务场景,甚至能根据函数名和实现逻辑推断出合理的断言条件。基于静态分析的工具会扫描代码找出潜在的空指针、边界值等问题点,针对性生成测试。
实际工作中最有效的方式是人机协作。先用IDE插件或AI工具快速生成测试框架代码,它们能搞定基本的正常流程测试,然后你自己补充边界条件(空值、最大最小值)、异常场景(网络超时、数据库连接失败)、业务逻辑的特殊分支。完全依赖自动生成的测试质量往往不高,因为工具不理解你的业务语义,只能机械地覆盖代码路径。让工具干重复劳动,你负责关键场景的验证,这样才能真正提升测试效率和质量。
扩展分析
测试生成的完整技术链路
要把单元测试生成做好,需要理解从代码输入到测试输出的整个流程。工具首先要做代码解析,把源代码转成抽象语法树,提取函数签名、参数类型、返回值这些基础信息。接着进行依赖分析,识别这个函数调用了哪些外部服务、依赖了哪些类或模块,这决定了测试时需要mock哪些对象。然后根据代码的分支结构、循环条件、异常处理路径来设计测试用例,最后生成每个用例的断言逻辑。
传统的覆盖率驱动工具像EvoSuite的工作原理其实是把代码当黑盒,不断尝试不同的输入参数组合观察执行路径,目标是让每个if-else分支、每个循环边界都被执行到。比如一个计算折扣的函数,工具会自动尝试订单金额为0、负数、整数边界值这些输入,看能不能触发不同的计算逻辑。这种方法的问题在于生成的测试用例可能没有实际意义,你会看到输入金额是-999999这种在真实业务场景永远不会出现的数据。符号执行是另一个方向,它用符号变量来推导所有可能的执行路径,理论上能覆盖所有分支,但遇到复杂循环或递归时路径数量会指数级爆炸,工程上很难大规模应用。
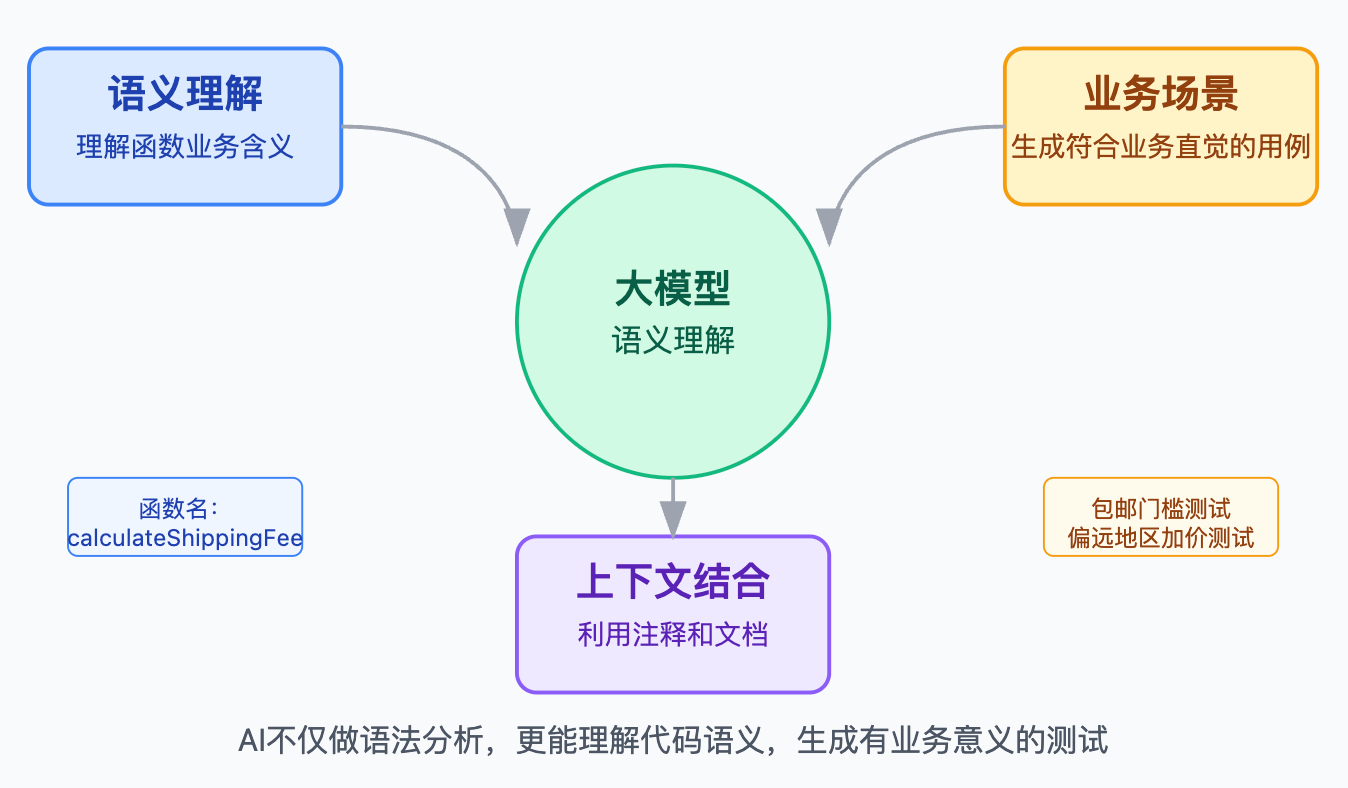
2025年大模型的介入真正改变了游戏规则。AI驱动的测试生成不只是做语法分析,而是能理解代码的语义。看到一个函数名叫calculateShippingFee,大模型能推断这是计算运费的逻辑,生成的测试用例会包含包邮门槛测试、偏远地区加价测试这些符合业务直觉的场景。它通过预训练学习了海量代码和测试代码的配对模式,面对新函数时能识别相似结构生成对应框架。更关键的是现在的AI工具能结合上下文,如果代码里有注释或文档说明,它会用这些信息来生成更精准的断言。
举个具体例子,假设有这样一个库存检查函数:
publicbooleancheckStock(String productId,int quantity){
Product product = productRepository.findById(productId);
if(product ==null){
thrownewProductNotFoundException();
}
return product.getStock()>= quantity;
}
传统覆盖率工具会生成checkStock("abc", 5)和checkStock(null, 0)这种纯粹为了覆盖路径的数据。而AI工具能生成更有业务含义的用例:
@Test
publicvoidtestCheckStock_whenStockSufficient_returnsTrue(){
when(productRepository.findById("PROD-001"))
.thenReturn(newProduct("PROD-001",100));
assertTrue(checkStock("PROD-001",50));
}
@Test
publicvoidtestCheckStock_whenProductNotFound_throwsException(){
when(productRepository.findById("INVALID-ID"))
.thenReturn(null);
assertThrows(ProductNotFoundException.class,
()->checkStock("INVALID-ID",1));
}
注意AI生成的测试用例命名更符合人类阅读习惯,mock数据也更接近真实场景,这是传统工具做不到的。
测试质量评估不能只看覆盖率数字。即使达到100%行覆盖率,也可能漏掉关键的边界条件。评估要看三个维度:覆盖度包括分支覆盖、路径覆盖、条件组合覆盖;边界测试要验证数值的最大最小值、集合的空和满、字符串的空值和特殊字符;异常场景要模拟网络超时、数据库死锁、并发冲突这些生产环境真实会遇到的问题。自动生成的测试往往在第一个维度做得好,但后两个维度需要人工深度参与。
不同生成策略的选择取决于你的测试目标。遗留代码重构需要快速建立安全网,基于覆盖率的工具最合适,先批量生成测试把主要路径保护起来。新功能开发用AI工具能节省大量时间,让你专注在核心业务逻辑的验证上。安全敏感的模块用模糊测试能发现意想不到的边界问题。关键是要明确自动生成的价值在于提效而不是替代,它帮你完成重复性的框架代码编写,但测试的核心价值是验证业务逻辑正确性,这需要对需求的深度理解。
工具实战与工程化落地
在实际项目中用GitHub Copilot生成测试时,关键技巧是给它足够的上下文。在IDE里写完函数后,直接在测试文件里敲个注释"test for xxx function",Copilot会自动补全整个测试框架。如果业务代码已经导入了JUnit和Mockito的包,生成的测试就会自动使用这些框架。更高级的用法是用自然语言描述测试意图,写个注释"测试当用户余额不足时应该抛出异常",它能生成对应的测试逻辑。但要注意生成的断言经常不够精确,它可能只写了assertNotNull(result),你需要补充具体的业务断言像assertEquals(expected.getAmount(), result.getAmount())。
用ChatGPT生成测试更要注重Prompt工程。不要直接把代码丢给它说"帮我写测试",这样质量很差。有效的Prompt应该包含函数代码、依赖说明、测试要求三个要素。比如:"下面是一个价格计算函数,依赖了DiscountService和UserRepository,请生成JUnit测试用例,要求覆盖VIP用户打折、普通用户不打折、折扣服务异常三个场景。"这种结构化的提问能让生成的测试更贴合实际需求。
// 待测试的价格计算函数
publicBigDecimalcalculateFinalPrice(String userId,BigDecimal originalPrice){
User user = userRepository.findById(userId);
if(user.isVip()){
BigDecimal discount = discountService.getDiscount(user.getVipLevel());
return originalPrice.multiply(discount);
}
return originalPrice;
}
// AI生成的测试框架(需要人工补充真实业务逻辑)
@ExtendWith(MockitoExtension.class)
classPriceCalculatorTest{
@Mock
privateUserRepository userRepository;
@Mock
privateDiscountService discountService;
@InjectMocks
privatePriceCalculator calculator;
@Test
voidcalculateFinalPrice_vipUser_shouldApplyDiscount(){
User vipUser =newUser("user123",true,VipLevel.GOLD);
when(userRepository.findById("user123")).thenReturn(vipUser);
when(discountService.getDiscount(VipLevel.GOLD))
.thenReturn(newBigDecimal("0.8"));
BigDecimal result = calculator.calculateFinalPrice("user123",
newBigDecimal("100"));
assertEquals(newBigDecimal("80.00"), result);
}
}
生成后的review环节至关重要。AI生成的测试数据往往用硬编码的魔法数字,要改成有语义的常量。测试命名也可能不够清晰,要按照"方法名_场景_预期结果"的模式重命名。断言逻辑更要仔细检查,特别是涉及金额计算的场景,要验证精度和舍入规则。
把测试生成集成到CI/CD流程时,应该作为一个独立的stage。具体策略是在代码提交时触发AI工具生成测试建议,但不直接合并,而是创建一个PR让开发者review。这样既利用了自动化效率,又保证了质量把关。GitHub Actions的配置可以这样写:
name: Auto Generate Tests
on:[pull_request]
jobs:
generate-tests:
runs-on: ubuntu-latest
steps:
-uses: actions/checkout@v3
-name: Generate tests with AI
run:|
python scripts/generate_tests.py --source-dir src --output-dir test/generated
-name: Create PR with generated tests
uses: peter-evans/create-pull-request@v5
with:
title:"Auto-generated tests for new changes"
body:"Please review and refine these tests"
这个流程的关键点是生成的测试要与手写测试分开存放,避免污染代码库;必须经过code review才能合并;要在pipeline里强制跑一遍确保生成的测试能通过;定期清理那些没有被合并的生成测试,防止积累太多无用文件。
实际项目中遇到生成的测试断言不准确时,说明给AI的上下文不够充分。解决办法是在函数注释里加上输入输出的示例,或者给AI看一个你手写的测试用例作为参考模板。还有个技巧是用AI生成测试数据构造器而不是完整测试,让它生成buildValidOrder()、buildInvalidUser()这种工厂方法,你在测试里调用这些方法,这样既省时又保持了控制力。
工程实践中的关键思考
评估生成的测试是否有效不能只看能否跑通,要看三个关键指标。首先是缺陷发现能力,好的测试应该在你故意引入bug后能快速失败,可以用变异测试来验证,工具会自动修改代码逻辑看测试能否捕获。其次是可维护性,生成的测试如果全是魔法数字和不清晰的变量名,三个月后没人看得懂就失去价值了。最后是业务覆盖度,这个需要人工review,确认关键业务规则都有对应断言。在实际项目中可以建立一个简单的checklist,新生成的测试必须通过这三个维度的检查才能合并到主分支。
复杂依赖场景的处理需要分层思考。拿支付服务举例,它依赖了风控系统、账户系统、第三方支付网关,这种多层依赖用传统工具很难自动生成有效测试。有效的策略是分层处理:最底层的纯计算逻辑可以让AI工具全自动生成,涉及外部依赖的集成点要手工编写mock策略,然后给AI提供mock模板让它生成具体用例。关键是要在代码设计时就考虑可测试性,比如用依赖注入而不是硬编码依赖,用接口而不是具体实现类,这样生成工具才能识别出需要mock的边界。
从技术演进的角度看,2025年一个明显趋势是从单纯生成代码向生成测试策略转变。新一代工具不只是给你一堆测试用例,而是先帮你做测试规划:这个模块应该用单元测试还是集成测试,哪些场景值得做端到端验证,测试数据怎么准备。更进一步的是知识库增强,把团队积累的业务知识、历史缺陷、用户反馈都喂给模型,生成的测试就不只是覆盖代码路径,而是真正覆盖业务风险点。当前的挑战在于如何保证生成测试的可信度,现在还没有很好的办法自动验证生成的断言是否正确,需要建立人机协作的review机制。
从架构层面看,自动化测试生成解决的是效率问题,但系统质量保障是个系统工程。测试金字塔原则依然适用,底层大量单元测试可以依赖生成工具快速构建,但不能因为生成容易就堆砌无效测试。中层的集成测试更需要人工设计,因为涉及多个模块的交互逻辑工具很难理解。顶层的端到端测试要和产品需求对齐,这个生成工具基本帮不上忙。团队应该建立明确的测试策略,规定哪些层次适合用生成工具、哪些场景必须人工编写、code review时怎么判断测试质量。这样才能把测试生成真正融入到工程体系中,而不是流于表面的工具堆砌。