精炼回答
代码补全的核心是基于上下文预测接下来的代码。GitHub Copilot采用的是OpenAI Codex模型,这是在GPT架构上用海量开源代码训练出来的大语言模型。具体工作流程是这样的:当你在IDE里写代码时,Copilot会把光标前的代码、当前文件内容、甚至相关文件作为上下文发送到模型,模型基于Transformer架构计算出每个token的概率分布,然后生成最可能的代码续写。它不是简单的字符串匹配或模板填充,而是真正"理解"了代码的语义和意图。
训练时使用的是因果语言建模(Causal Language Modeling)目标,也就是预测下一个token。数据来源主要是GitHub上的公开仓库代码,经过清洗和去重。模型学会了编程语言的语法规则、API使用模式、命名习惯,甚至能根据注释生成对应实现。实际使用中,比如你写了函数签名和注释,Copilot能补全整个函数体;你导入某个库后,它知道该库的常见用法。这背后是多层注意力机制捕捉到了代码中的长距离依赖关系,比如变量定义和使用、函数调用关系等。延迟控制在几百毫秒内,需要在模型规模和推理速度间做权衡。
扩展分析
从传统补全到AI时代的技术跃迁
很多人容易把代码补全简单理解成"AI预测代码",但这样回答在面试中是拿不到高分的。真正理解这个技术,需要先搞清楚它和传统IDE补全的本质差异。传统代码补全像IntelliJ IDEA的自动完成,本质是基于静态分析和规则匹配的编译器前端技术。它会把你写的代码解析成抽象语法树(AST),然后维护一张符号表记录所有变量、函数、类的定义和类型信息。当你输入"list."的时候,IDE通过符号表查到list是ArrayList类型,再通过类型系统找到这个类的所有公开方法和属性,最后用启发式规则排个序展示给你。这套机制的优点是精准可控,缺点是完全依赖静态分析,只能在类型明确的情况下工作。所以传统补全在动态语言Python里效果就比Java差很多,因为类型信息缺失。
AI代码补全彻底改变了这个逻辑,它不再依赖语法树和符号表,而是把代码当作序列来理解。这里面有两个关键突破:从规则到学习、从局部到全局。传统方法是人工定义规则,AI方法是从海量代码中学习模式;传统方法只看当前语句的类型信息,AI方法会考虑整个文件甚至跨文件的上下文。举个实际例子,你在写一个HTTP客户端调用的代码,传统IDE只能补全HttpClient类的方法列表,但Copilot能直接生成包含请求头设置、超时配置、异常处理的完整代码块,因为它在训练时见过成千上万类似的HTTP调用模式。
Copilot背后的Codex模型是在GPT-3架构基础上,用GitHub上几十亿行代码训练出来的。这里面有三个针对性优化特别值得注意。第一是训练数据全部来自GitHub的公开代码仓库,模型学到的是真实编程场景里的代码模式,而不是教科书式的示例。第二是Tokenizer做了调整,因为代码里有大量缩进、括号、特殊符号,需要设计专门的分词策略,比如把四个空格的缩进作为一个token而不是四个空格token。第三是训练任务还是因果语言建模,但会特别关注代码结构的完整性,比如括号匹配、缩进对齐这些在自然语言里不重要但在代码里必须严格遵守的规则。
整个工作流程可以这样理解:开发者在IDE输入代码时,插件会实时收集光标前的代码、当前文件内容、甚至打开的相关文件作为上下文,这些内容被编码成token序列发送到云端模型;模型通过多层注意力机制计算出每个位置的概率分布,生成多个候选补全结果;最后在客户端做排序和过滤,把最合理的建议展示给开发者,整个过程控制在几百毫秒内保证流畅体验。这里面的关键技术挑战不是模型本身,而是如何在保证效果的前提下把延迟压到用户可接受的范围内。
上下文窗口的处理是个特别能展现技术深度的点。Copilot不是简单地把整个文件塞给模型,而是有一套智能的上下文选择策略。模型的输入长度是有限制的,早期版本可能只有2048个token,现在可能扩展到了8192甚至更长,但还是不能把所有相关代码都塞进去。所以IDE插件会做几件事:优先保留光标前几百行的代码,因为这部分最直接相关;解析import语句和函数调用,把相关文件的定义部分也加进来,比如你在调用一个自定义工具类的方法,Copilot会去找那个工具类的代码作为上下文;识别文档字符串和注释,因为这些往往包含了意图信息,比注释更重要。
假设你在写一个处理订单状态流转的方法,Copilot的上下文构建过程是这样的:它会先抓取你当前写的函数签名和上面的注释,然后往前找这个类里已有的相关方法比如validateOrder()或者checkInventory(),再去找OrderStatus这个枚举类的定义,最后可能还会包含一些典型的状态机转换代码片段。这些内容拼在一起,形成一个最有可能帮助模型理解当前任务的上下文prompt。这本质上就是在做代码领域的提示工程(Prompt Engineering),而生成质量高度依赖prompt的质量。最有效的prompt组成部分包括:详细的注释说明意图,比如"计算包含优惠券和积分抵扣后的订单最终金额"比"计算金额"效果好得多;完整的函数签名,让模型知道输入输出类型;已有的相关代码作为示例,这等于在做Few-shot学习。
模型生成候选结果时用的解码策略也有讲究。最简单的是贪婪解码,每步都选概率最高的token,速度快但容易陷入重复或者生成很平庸的代码。Copilot实际用的更多是Top-k采样或者Nucleus采样,从概率分布的头部随机选,这样既能保证质量又增加多样性。更关键的是,Copilot会生成多个候选结果而不是只返回一个,比如生成3-5个不同的实现方案,然后在客户端做重排序。重排序时会考虑代码风格一致性、是否有语法错误、是否符合项目的命名规范等因素。这就是为什么你有时候按Tab接受第一个建议,按Alt+]能看到其他备选方案。

工程落地的性能优化与实战经验
理解了原理之后,更关键的问题是怎么把这个技术真正用起来。代码补全有三个关键性能指标,分别衡量不同维度的体验。首先是延迟,这是最直接影响开发者感知的指标,业界标准是P99延迟要控制在300毫秒以内,超过500毫秒用户就会明显感觉卡顿。其次是接受率,也就是生成的建议有多少比例被开发者真正采纳,Copilot这类成熟产品的接受率一般在35-40%左右,如果低于25%说明建议质量有问题。最后是准确率,但这个指标比较复杂,因为代码生成不像分类任务有明确的对错,通常会用BLEU或者CodeBLEU这类指标衡量生成代码和参考代码的相似度,同时结合语法正确性和可执行性来综合评估。有个实际观察特别有意思:接受率和延迟是强相关的,哪怕准确率一样,延迟从400ms降到200ms,接受率能提升10个百分点,因为开发者更愿等待流畅的工具。
工程化落地时最大的挑战就是延迟问题。模型侧的优化包括量化压缩,把FP32的权重压缩到INT8甚至INT4,牺牲一点点精度换取2-4倍的推理加速;KV缓存技术,因为代码是增量输入的,上次推理计算的Key-Value可以缓存起来,新输入只需要计算增量部分;推测解码(Speculative Decoding),用一个小模型快速生成候选token序列,大模型只负责验证,这样能在保持质量的前提下把延迟降低30-50%。更前沿的做法是在IDE插件侧做预测式请求,比如检测到你在写函数签名时就提前发起请求,等你写完注释的时候结果已经回来了,这样用户感知不到延迟。
部署架构上不能所有请求都打到同一个模型服务,需要做多级缓存策略。把常见的补全模式比如导入语句、标准库调用缓存在本地,只有复杂的业务逻辑才真正调用云端模型。实测发现,合理的缓存策略能让80%的简单补全请求在本地100ms内返回,只有20%的复杂场景才需要调用远程模型。还有个容易被忽略的优化点是批处理,把同一时间窗口内的多个请求合并成一个batch送给模型,能大幅提升GPU利用率。
// 多级缓存策略的实际实现
publicclassCompletionService{
privatefinalConcurrentHashMap<String,String> localCache;// L1本地缓存
privatefinalRedisCache distributedCache;// L2分布式缓存
privatefinalModelClient modelClient;// L3模型服务
publicCompletionResultcomplete(CodeContext context){
String cacheKey =buildCacheKey(context);
// 先查本地缓存,命中率约60%
String cached = localCache.get(cacheKey);
if(cached !=null){
returnnewCompletionResult(cached,CacheLevel.LOCAL,50);
}
// 再查分布式缓存,命中率约20%
cached = distributedCache.get(cacheKey);
if(cached !=null){
localCache.put(cacheKey, cached);// 回填本地缓存
returnnewCompletionResult(cached,CacheLevel.DISTRIBUTED,120);
}
// 最后调用模型推理,占比约20%
long startTime =System.currentTimeMillis();
String result = modelClient.inference(context);
long latency =System.currentTimeMillis()- startTime;
// 异步写入缓存
CompletableFuture.runAsync(()->{
distributedCache.put(cacheKey, result,Duration.ofHours(24));
});
returnnewCompletionResult(result,CacheLevel.MODEL, latency);
}
privateStringbuildCacheKey(CodeContext context){
// 基于代码上下文的哈希,相似上下文共享缓存
returnDigestUtils.md5Hex(
context.getLanguage()+
context.getFramework()+
normalizeCode(context.getPrefixCode())
);
}
}
代码补全在实际开发中哪些场景效果最好,这个问题特别能体现你是不是真用过这些工具。函数补全是最经典的场景,当你写完函数签名和注释后,模型能生成整个函数体,这种场景下模型有清晰的输入输出约束,效果通常最稳定。代码续写适合写重复性逻辑,比如你已经写了几个类似的if-else分支,模型能推断出剩下分支的模式直接补全。注释生成代码是个特别实用的场景,很多开发者习惯先用自然语言描述需求,然后让Copilot生成实现框架,这在写数据转换、格式校验这类偏模式化的代码时效率很高。测试用例生成是2024年开始火起来的新应用,你写完一个函数,Copilot能自动生成覆盖边界条件、异常情况的单元测试,虽然需要人工调整但能节省大量时间。
但在处理支付回调逻辑这种业务特定场景时,如果你先写注释"验证签名、更新订单状态、发送通知",然后写函数签名,Copilot生成的代码往往结构完整、考虑了异常处理。但如果让它凭空写一个复杂的业务状态机,效果就会打折扣,因为模型不了解你的具体业务规则。这引出了一个实用建议:代码补全在处理通用编程模式时效果最好,越是业务特定的逻辑,越需要人工介入和审核。
代码质量保障这块在企业落地时特别重要。生成的代码不能直接用,必须过一套检查流程。语法检查是最基础的,用编译器或者LSP(Language Server Protocol)验证生成的代码能不能通过编译。安全扫描要识别SQL注入、XSS、硬编码密钥这些常见漏洞,可以集成SonarQube或者Checkmarx这类工具。许可证合规性在商业项目里特别敏感,Copilot训练用的开源代码涉及各种许可证,生成的代码如果跟某个GPL项目太相似就可能有法律风险,需要做相似度检测和许可证匹配。很多企业会在IDE插件里内置这些检查,生成的代码在显示给开发者之前先过一遍扫描,有问题的直接过滤掉或者加个警告标识。
业界对比与技术演进趋势
业界主流的代码补全工具各有特点,从定位差异能看出不同的技术路线选择。GitHub Copilot现在是市场占有率最高的,背后是OpenAI的Codex模型,它的优势在于通用性强,几乎所有主流编程语言都支持,而且跟GitHub生态深度整合。Tabnine走的是另一条路线,它强调本地部署和隐私保护,很多企业不想把代码传到云端,Tabnine就提供了完全在本地运行的小模型版本,虽然效果比云端大模型差一些,但对数据安全敏感的团队来说是刚需。Amazon CodeWhisperer的特色是跟AWS服务深度绑定,如果你在写Lambda函数或者DynamoDB操作,它能生成符合AWS最佳实践的代码,还会做安全扫描提示潜在的漏洞。Codeium则是开源社区的新星,它用StarCoder这类开源模型,免费提供企业级功能,对预算有限的团队很有吸引力。
这些产品在实际效果上的对比很有意思。Copilot的接受率在40%左右但需要付费订阅,Tabnine的本地版本接受率可能只有25%但保证了数据不出企业网络,CodeWhisperer对AWS用户免费但在非AWS场景下效果一般,Codeium完全免费但模型更新速度跟商业产品有差距。这种对比不是为了分高下,而是说明不同场景下需要权衡不同的因素,没有一个工具是绝对最优的。
模型架构层面的演进也特别值得关注。Copilot用的Codex本质是GPT系列的decoder-only架构,特点是生成能力强但需要大量算力。CodeT5走的是encoder-decoder路线,它用T5的架构专门针对代码任务优化,好处是可以同时做代码理解和生成,比如既能补全代码也能生成文档。StarCoder是完全开源训练的模型,用的是类似GPT的架构但训练数据更透明,很多研究团队在这个基础上做定制化改进。Meta的Code Llama则是在Llama 2基础上用代码数据继续训练的版本,它的特色是在保持生成质量的同时把模型规模控制在7B到34B之间,推理速度比Codex快不少。2024年开始大家发现decoder-only架构在代码生成任务上几乎全面占优,所以现在新产品基本都不再用encoder-decoder了。
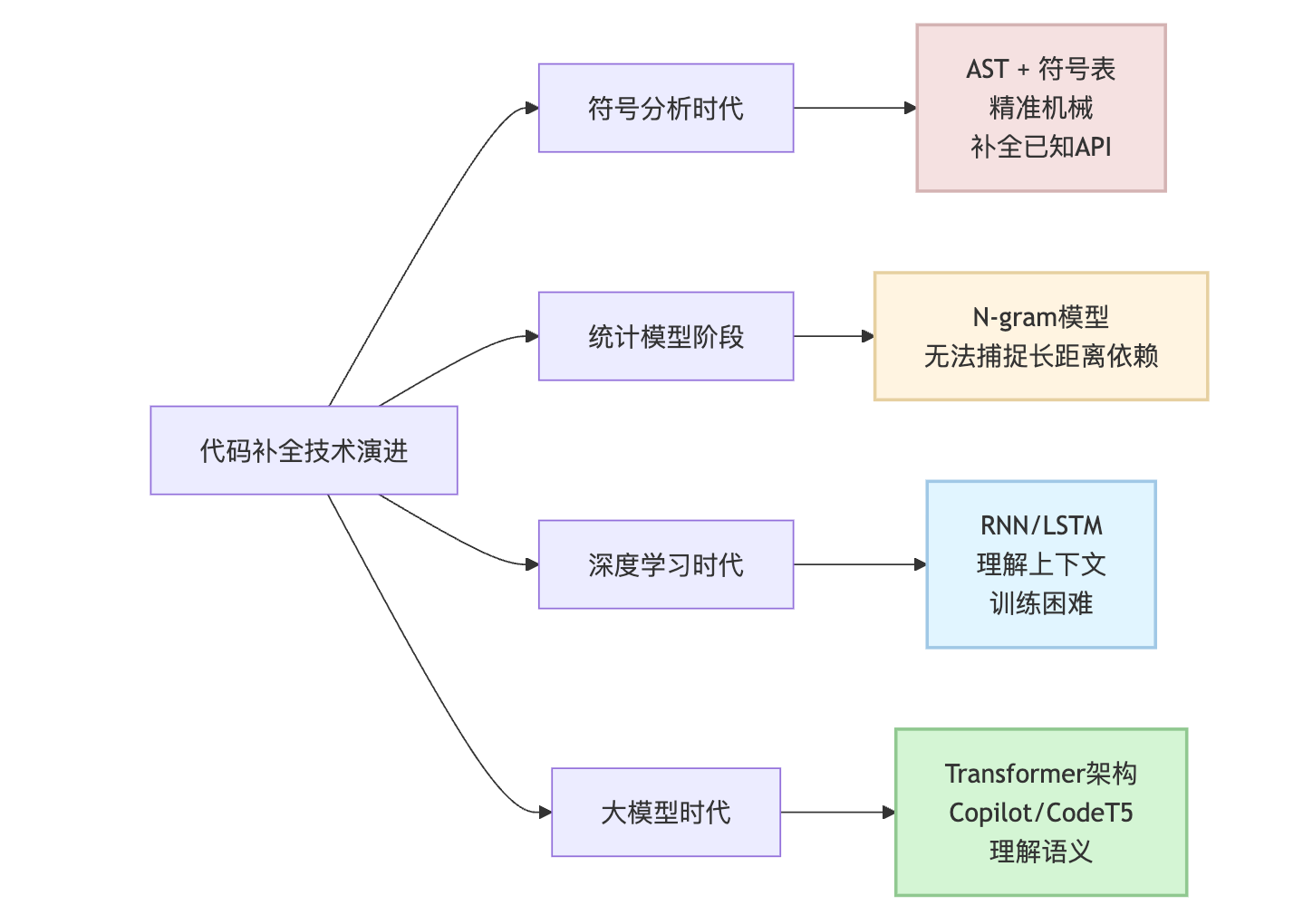
代码补全经历了从规则到统计、从局部到全局、从小模型到大模型的三次关键跃迁,每次跃迁都对应着底层技术架构的根本性突破。最早的代码补全完全靠规则匹配,IDE解析出语法树后根据类型信息列出候选项。然后进入统计模型阶段,开始用N-gram语言模型预测下一个token,但效果很有限因为无法捕捉长距离依赖。RNN和LSTM的出现带来了第一次质变,模型开始能理解上下文,但训练困难而且对长序列还是无能为力。Transformer架构在2017年横空出世,Self-Attention机制彻底解决了长距离依赖问题,这才让真正智能的代码补全成为可能。最近这几年大模型时代到来,从GPT-3到Codex再到现在的各种开源模型,参数规模从几亿飙升到上百亿,代码理解和生成能力发生了质的飞跃。
2025年的几个新趋势特别值得关注。多模态代码理解是个明显的发展方向,现在的代码补全只看文本,但实际开发中经常需要参考架构图、流程图、UI设计稿,已经有团队在尝试把图像理解能力融入代码生成模型,比如给模型看一个数据库ER图,它能自动生成对应的ORM模型定义。代码推理能力也在快速提升,不再是简单的模式匹配,而是真正理解代码的执行逻辑,比如给定函数签名和几个测试用例,模型能推导出正确的实现逻辑。个性化适配是另一个重要趋势,每个团队都有自己的代码规范和架构模式,现在开始有基于RAG的方案,从团队代码库里检索相关示例作为上下文,让生成的代码更符合项目特点。这些方向在2025年都有了实际落地案例,不再是纸上谈兵,说明代码补全正在从通用工具走向深度定制化的智能编程助手。
但是这个技术也有明显的局限性,什么场景下代码补全效果不好需要特别注意。首先是涉及敏感业务逻辑的代码,比如支付风控规则、核心算法实现,这些模型没见过的领域特定知识,生成的代码可能看着合理但逻辑是错的,必须人工仔细审核。其次是性能关键路径的代码,模型倾向于生成可读性好的常规实现,但在高并发场景可能有性能问题,比如它会生成同步阻塞的数据库调用而不是异步批量查询。还有就是安全敏感的代码,模型可能生成看似正常但有漏洞的实现,比如用MD5做密码加密、忘记参数校验等。代码补全是个效率工具而不是替代工具,它能处理90%的常规编码工作,但那10%的核心逻辑、性能优化、安全加固还是需要人的专业判断。
数据隐私和代码版权是两个绕不开的话题。云端代码补全意味着你的代码要传到服务器,对于金融、医疗这些行业来说是绝对不能接受的。最彻底的办法是本地部署,用Tabnine或者开源模型在企业内网运行,虽然效果弱一些但数据完全可控。如果一定要用云端服务,可以做代码脱敏,把变量名、函数名替换成占位符再传输,返回结果后再还原回来。Copilot训练用的GitHub公开代码涉及各种开源许可证,生成的代码如果跟某个GPL项目太相似,商业使用可能有法律风险。工程上的做法是在生成代码前做相似度检测,如果跟已知开源代码重合度超过阈值就过滤掉或者标注来源。企业使用时可以选择专门为商业用途训练的模型版本,或者用私有代码库做微调,降低版权风险。
与CI/CD集成是未来的一个明确方向,2025年有团队尝试在代码审查阶段让模型自动生成改进建议,在部署前让模型生成回归测试用例,在生产监控时根据错误日志让模型生成修复补丁。这些实践把代码补全从单纯的编码辅助扩展到了DevOps全链路,虽然还在探索阶段但代表了技术演进的一个重要方向。代码补全技术已经从最初的"写代码时的小助手",逐步发展成贯穿整个软件开发生命周期的智能化基础设施,这才是它真正的价值所在。