精炼回答
AI编程工具的代码风格一致性需要通过主动约束和配置管理来保证。核心思路是在源头就让AI按照规范生成代码,而不是生成后再大幅返工。
首先要在Prompt中明确指定代码规范,比如要求"使用ESLint Airbnb规范"或"遵循PEP 8标准",这样AI生成代码时会按照这些规则来组织。更具体的做法是在项目根目录放置.editorconfig、.eslintrc.json、prettier.config.js等配置文件,在提问时告诉AI"请按照项目中的ESLint配置生成代码",AI会识别这些规范文件。对于团队特殊规范,可以把团队的代码规范文档放入AI的上下文。比如使用Cursor或GitHub Copilot时,在.cursorrules或workspace配置中写明"函数命名必须使用驼峰式"、"禁止使用var声明变量"、"所有异步操作必须有错误处理"等具体要求。
生成代码后,必须配合自动化工具进行检查和格式化。在CI/CD流程中集成Prettier、Black、gofmt等格式化工具,以及对应的Linter,这样即使AI生成的代码有偏差,也会被自动修正。实际操作中,可以设置pre-commit hook,让每次提交前自动执行格式化和检查,这样就能确保所有代码(包括AI生成的)都符合团队标准。
扩展分析
核心要点与深度理解
面试中谈到代码风格一致性,面试官其实想听的是你的体系化思维。很多候选人会把答案局限在"用Prettier格式化"这种单点上,但有实战经验的人都知道,保证AI生成代码符合团队规范需要多层防护机制,每一层都有具体的操作方法。真正的问题本质是:AI编程工具虽然能快速生成代码,但它不会自动理解团队的编码习惯,如果不加约束,每个人用AI生成的代码风格都可能不同,这会给代码审查和维护带来麻烦。
回答时建议用分层保障的思路来组织。第一层是提示词引导,在和AI对话时就把规范要求说清楚。不是简单说"帮我写个函数",而是明确告诉它"请用Java编写一个订单处理方法,遵循Google Java Style Guide,方法名用小驼峰,异常处理用try-with-resources"。更进阶的做法是提供示例代码,比如告诉AI"参考下面这段代码的风格来生成",然后贴一段团队已有的规范代码。这种做法在2025年特别有效,因为现在的大模型对上下文理解能力更强了,给它示例代码就像给它一个模板,生成的代码风格会非常接近。
面试官可能会追问"示例代码怎么选",这时候可以说通常会从项目中找最典型的业务代码片段,比如一个标准的Service层方法实现,包含参数校验、业务逻辑、异常处理的完整结构。如果是新项目,可以先手写一个黄金模板放在团队文档里,每次让AI生成代码都带上这个模板。
第二层是工具配置层面,这是让AI理解项目规范的关键。现在主流的AI编程助手像GitHub Copilot、Cursor、Tabnine,它们都能识别项目根目录下的配置文件。比如Java项目里的checkstyle.xml、前端项目的.eslintrc.js和.prettierrc,这些文件定义了代码格式、命名规范、代码复杂度限制等规则。在提示词里明确提到"请按照项目中的Checkstyle配置生成代码",AI会自动分析这些配置文件,生成的代码就会符合团队标准。
这里有个细节可以加分:提到.cursorrules或.github/copilot-instructions.md这类2025年新出现的配置方式。这些文件专门用来告诉AI工具团队的特殊规范,比如写一条规则"所有数据库操作必须使用Mapper接口而不是直接写SQL",AI在生成代码时就会遵守。拿电商场景举例的话,可以说团队规定所有金额计算必须用BigDecimal,在.cursorrules里写明这条规则后,AI就不会生成用double处理金额的代码了。
// .cursorrules 文件示例内容
所有Service层方法需遵循以下规范:
- 方法命名使用小驼峰,动词开头(get/query/create/update/delete)
- 参数校验统一使用SpringValidation注解
- 业务异常抛出自定义BusinessException而非通用Exception
- 数据库操作必须通过Mapper接口,禁止拼接SQL字符串
- 金额类型统一使用BigDecimal,价格计算保留两位小数
- 所有外部接口调用必须设置超时时间和重试策略
第三层是IDE集成层面的配置,这是保证实时反馈的核心。面试官很关心开发过程中怎么发现问题,而不是等到提交代码才被CI挡住。可以在IDE里配置保存时自动格式化,比如在IDEA里启用"Reformat Code on Save",配合Checkstyle插件实时检查代码规范。当AI生成的代码不符合规范时,IDE会立即显示警告或错误标记,可以马上调整。如果用VSCode,可以装上Prettier和ESLint插件,在settings.json里配置"editor.formatOnSave": true,这样粘贴AI生成的代码后一保存就自动格式化了。
实践经验表明,有时候AI生成的代码结构是对的,但缩进、空格这些细节不符合团队规范,如果每次都手动调整会很烦。配置好自动格式化后,这类问题完全不用操心,保存时IDE自动搞定。这样做不仅提升了效率,还能让开发者专注于业务逻辑而不是格式问题。
第四层是CI/CD层面的兜底保障,这代表着工程化的底线思维。即使前面所有步骤都做了,依然会在代码提交前设置自动化检查,确保没有不符合规范的代码进入主分支。具体做法是在项目里配置Git Hooks,比如用Husky在pre-commit阶段执行Checkstyle或ESLint检查。
// 在 CI 流程中的检查脚本示例
mvn checkstyle:check -Dcheckstyle.config.location=checkstyle.xml
// 如果检查失败,构建会被中断
if[ $?-ne 0]; then
echo "代码风格检查未通过,请修复后再提交"
exit 1
fi
在Jenkins或GitHub Actions的流水线里,可以设置一个专门的Stage做代码风格检查,失败了就阻止合并。这种机制的好处是不管代码是人写的还是AI生成的,都要过同样的规范检查。这样做还有个隐藏价值,就是让团队对AI生成代码的信任度更高,因为大家知道所有代码都经过了统一的质量把关。
第五层是代码审查层面的人工智慧。AI生成的代码必须要Review,但怎么Review更能体现水平。在Review AI生成代码时会重点关注三个方面:首先是业务逻辑正确性,AI可能理解不准确需求,生成的逻辑看起来对实际有问题,比如优惠计算的优先级错了。其次是异常场景处理,AI倾向于写Happy Path的代码,边界条件和异常情况容易遗漏。第三是性能和安全隐患,比如AI可能生成了N+1查询或者SQL注入风险的代码。
假设让AI生成一个查询用户订单列表的方法,它可能会循环调用单个订单查询接口,而不是用批量查询。这种代码风格可能没问题,但性能上有明显缺陷,Code Review时就需要人工指出并优化。这样的处理方式展现出不是盲目信任AI,而是把它当作一个初级开发者的产出来审视。
第六层是团队规范文档的建设,这是长期保障。推动团队把编码规范文档化,不只是写一个Word文档放在Wiki里,而是把规范转化成可执行的配置文件和工具链。比如把命名规范、异常处理原则、日志规范这些内容整理成Markdown文档,同时生成对应的Checkstyle规则文件,两者放在一起维护。
更进阶的做法是建立一个团队知识库,用2025年流行的RAG(检索增强生成)技术,把团队的代码规范、最佳实践、历史Code Review意见都索引进去。这样在使用AI工具时,可以让AI先检索团队知识库,然后再生成代码,生成的结果会更符合团队习惯。
可以用一个流程图来总结这六层防护体系如何协同工作:
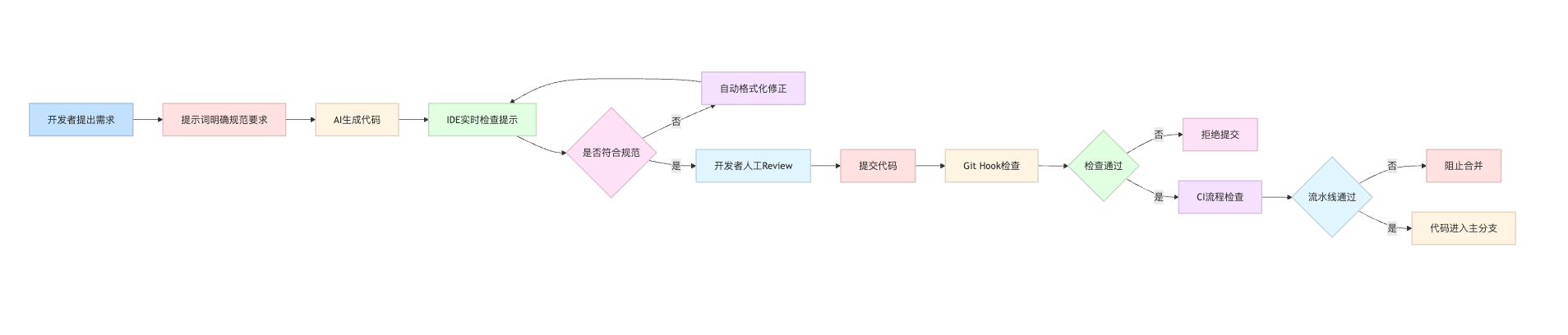
实践落地与工具配置
光说理论框架还不够,真正动手配置过这些工具才能在面试中从容应对。先说说项目级的配置文件怎么让AI工具理解团队规范。在项目根目录创建一个.cursorrules文件,把团队的核心规范写进去,AI工具会自动读取并遵循这些规则。比如团队要求所有异步方法必须返回CompletableFuture而不是直接用线程,可以在文件里写明"所有异步操作统一使用CompletableFuture封装,不允许直接创建Thread对象"。再比如日志规范,可以规定"所有业务异常必须记录ERROR级别日志,包含用户ID和操作上下文",AI生成代码时就会自动加上这些要素。
配置后让AI生成代码时,它会自动遵循这些规则。比如让它写一个商品价格计算方法,不需要特别提示,生成的代码就会用BigDecimal而不是double,还会自动加上小数位数控制。这种配置的好处是团队所有人共享同一份规范,不会因为个人习惯不同导致AI生成代码风格差异大。
提示词技巧是展现实战能力的另一个重点。可以准备一个对比案例,展示普通提示词和规范化提示词的差异。刚开始用AI工具时,提示词比较随意,比如"写一个查询订单的方法",这种模糊的需求会让AI按它默认的风格生成代码,可能用List返回结果,可能直接抛Exception,每次生成的代码结构都不太一样。后来改进成规范化的提示词:"请用Java编写一个订单查询方法,方法签名为public Result<List<OrderDTO>> queryOrders(OrderQuery query),遵循以下规范:使用MyBatis进行数据库查询,参数用@Valid注解校验,异常统一封装到Result对象的error字段,日志使用SLF4J记录关键查询参数"。这种详细的提示词生成的代码就非常接近团队规范了。
可以分享一个模板化的提示词结构:请用[语言]编写[功能描述]方法,方法签名为[具体签名],技术栈要求使用[框架/库名称]进行[具体操作],遵循[具体代码规范名称]。代码规范包括命名风格、异常处理方式、日志规范等。然后贴一段团队现有的标准代码作为参考示例。这种结构化的提示词可以系统性地引导AI工具生成符合规范的代码。
工具链集成是落地能力的关键体现。比如前端项目如何集成ESLint和Prettier。项目初始化时会在根目录创建.eslintrc.js配置文件,选择Airbnb或Standard这种业界通用规范作为基础,然后根据团队习惯做定制化调整。
// .eslintrc.js 配置示例
module.exports={
extends:['airbnb-base','plugin:prettier/recommended'],
rules:{
'no-console': process.env.NODE_ENV==='production'?'error':'warn',
'no-unused-vars':['error',{argsIgnorePattern:'^_'}],
'max-len':['error',{code:120,ignoreStrings:true}],
},
};
配合Prettier做格式化,在package.json里配置Git Hooks,代码提交前自动执行检查:
{
"husky":{
"hooks":{
"pre-commit":"lint-staged"
}
},
"lint-staged":{
"*.{js,jsx,ts,tsx}":[
"eslint --fix",
"prettier --write"
]
}
}
这套配置的核心思路是让格式问题在本地就解决掉,AI生成的代码粘贴进编辑器后,保存时自动格式化,提交前再做一次检查,这样进入代码仓库的代码都是符合规范的。如果团队用Java后端,可以类比讲Checkstyle插件和Maven插件的配置,原理是一样的。
实际问题和解决方案方面,AI生成的代码经常会出现导入包不规范的问题,可能用了通配符import java.util.*而团队规范要求明确导入具体类。解决办法是在IDE里配置自动优化导入,IDEA中设置"Optimize imports on the fly",或者在保存时触发import优化。另一个常见问题是AI生成的异常处理不符合团队规范。比如团队要求用自定义的业务异常类,AI可能直接抛RuntimeException。遇到这种情况,会在提示词里明确指定异常类型,如果多次生成还是不对,就在.cursorrules里加一条强制规则"禁止抛出RuntimeException,所有业务异常使用BusinessException"。更彻底的做法是配合静态代码扫描工具,在CI流程中检测到不允许的异常类型就直接报错。
团队实践流程方面,不建议一开始就上全套工具链,容易引起团队反弹。实践做法是先从最基础的代码格式化工具开始,比如统一配置Prettier,这个改动成本最低,几乎不影响现有代码逻辑。团队适应后再逐步引入静态检查工具,初期可以设置为Warning级别,让大家看到问题但不强制阻断。等规范稳定下来,再把检查提升到Error级别,接入CI流程强制执行。推广过程中很重要的一点是建立反馈机制。如果发现AI生成的代码经常触发某条规则报错,要分析是规则设置太严格,还是提示词没写清楚,或者是AI工具理解有偏差。定期组织团队讨论这些问题,不断优化规范配置和提示词模板。
效果评估可以从几个维度来衡量。最直观的指标是CI流程的通过率,如果AI生成代码提交后频繁因为格式或规范问题被拦截,说明配置还不到位。可以统计一下引入工具链前后的拦截率变化,比如配置完善后拦截率从30%降到5%以下,就说明效果显著。另一个指标是Code Review中关于代码风格的评论数量,如果Review意见主要集中在业务逻辑而不是格式问题,说明规范保障体系起作用了。还可以从开发体验角度评估,比如统计AI生成代码被开发者直接采用的比例。如果生成的代码经常需要大幅修改才能符合规范,说明提示词模板或配置文件还需要优化。理想状态是AI生成的代码80%以上只需要微调甚至直接可用。
前瞻思考与面试应对
面试官抛出这个问题时,真正想考察的不是你会不会用Prettier或ESLint这些工具,而是你对AI编程工具的掌控意识。很多候选人会陷入一个误区,觉得AI生成代码就是直接用,或者简单检查一下语法错误就提交了。但面试官想看到的是你对代码质量的主动管控能力,明白AI只是工具而不是决策者,最终的代码质量还是要人来把关。
回答时一定要展现出"工具为我所用"的态度。AI编程工具确实能显著提升开发效率,但它生成的代码不是拿来就用的成品,而是需要经过规范化处理的半成品。核心原则是让AI在正确的轨道上生成代码,而不是生成后再大幅返工。这种表达传递的信息是有清晰的工程判断力,不会被新工具牵着鼻子走。
面试官很可能会从几个方向追问。第一个方向是具体工具的配置细节,比如问你".cursorrules文件具体怎么写"或者"pre-commit hook配置过哪些检查项"。这时候不要慌,不需要把所有配置项背下来,重点是说清楚配置思路。团队规范文件会按照分层结构来组织,先写通用的语言规范比如命名风格和代码格式,再写框架层面的约定比如Spring Bean的命名规则,最后写业务相关的特殊要求比如敏感数据处理方式。
第二个追问方向是遇到过什么具体问题。面试官想听的不是"都挺顺利的"这种话,而是你怎么解决实际矛盾的。可以准备一个真实场景:比如团队有个老项目历史代码不太规范,新接入AI工具后生成的代码反而比老代码规范,这时候就会面临是统一改造老代码还是让新代码迁就老代码的问题。解决方案可能是先在新模块推行严格规范,老模块逐步重构,过渡期通过代码分区管理来避免混乱。这种回答既承认了现实困难,又展示了解决问题的灵活性。
第三个追问角度是团队推广经验。面试官想知道你有没有影响团队的能力。推广这套规范体系时会先做一个小范围试点,选两三个愿意尝试的同事一起配置工具链,收集反馈后再优化方案。正式推广时会组织一次技术分享,不是强制大家遵守规则,而是展示规范化后能带来什么好处,比如Code Review效率提升了多少、代码冲突减少了多少。同时提供详细的配置文档和提示词模板,降低大家的上手成本。
面试时还要注意展现对AI工具发展趋势的前瞻性思考。2025年一个明显的趋势是AI编程助手开始支持团队级的知识库对接,比如通过RAG技术让AI理解项目的历史代码和设计文档。未来我们可能不只是配置静态的规范文件,而是让AI直接学习团队代码仓库的提交历史和Code Review记录,它会自动知道团队倾向于用什么样的设计模式、常用哪些工具类、有哪些业务约定。这种演进方向既能保持规范一致性,又能避免过于僵化的约束。
最后要强调的是平衡AI效率与代码质量的思考。面试官可能会问"会不会因为配置太复杂反而降低了AI工具的效率",这时候可以说规范化和效率提升不是对立的,关键是找到合理的平衡点。经验是不要一开始就追求完美的规范,而是先解决最核心的问题比如命名风格和格式统一,这些通过自动化工具基本无感知。至于更复杂的架构规范和业务逻辑约束,可以通过Code Review和逐步迭代来完善。这种渐进式的思路既保证了代码质量底线,又不会让团队感觉负担太重。
如果面试官追问"这套体系实施起来团队会不会觉得太重",可以回答初期确实需要投入时间配置工具链和编写规范文档,但这是一次性成本。配置完成后,每个开发者都能从中受益,尤其在使用AI工具时,大家生成的代码自动就是符合规范的,反而减少了后期返工的时间。而且这套体系不只是为了约束AI,对人工编写的代码同样有效,本质上是提升团队整体代码质量的基础设施。这样回答既承认了实施成本,又说明了长期价值,展现出成熟的工程判断力。