精炼回答
代码翻译就是将一种编程语言编写的代码转换为另一种语言的等价实现,保持功能逻辑不变但适配目标语言的语法和特性。这里要特别强调的是"语义等价"而不是"语法对应",不是简单地把def改成public void就完事了,而是要确保程序的业务逻辑和运行结果完全一致。比如把Python写的推荐算法模块迁移到Java服务中,协同过滤的计算结果必须分毫不差。
Python转Java需要处理几个核心差异。首先是类型系统的转换,Python的动态类型要转换为Java的静态类型声明,name = "test"要改写成String name = "test",这个过程往往需要通过静态分析推断变量类型。其次是数据结构映射,Python的list对应Java的ArrayList,dict对应HashMap,但实际项目中更应该映射成业务对象而不是泛型集合。再就是语法和范式转换,Python用缩进表示代码块,Java用大括号;Python的列表推导式在Java里可能要写成Stream操作或者传统循环。
实际转换时要根据代码规模选择策略。简单脚本可以手动改写,先声明返回类型和参数类型,再逐行转换逻辑。复杂项目建议使用AST(抽象语法树)分析工具配合规则引擎批量转换,先解析Python代码生成语法树,再映射到Java语法树生成代码。2025年更流行的做法是让大模型先生成初版代码,然后用静态分析工具检查类型安全性,最后人工review关键业务逻辑。但要注意框架依赖和语言特有特性,比如Python装饰器、Java接口这些需要人工适配,机械转换往往会产生不符合目标语言习惯的代码。
扩展分析
代码翻译的本质与技术实现
代码翻译本质上是一个编译转换过程,只是目标不是机器码而是另一种高级语言。理解这个本质能帮你看清整个转换流程:先对源代码做词法分析把代码切分成token流,再通过语法分析构建抽象语法树,这个AST是语言无关的中间表示,接着遍历AST节点映射到目标语言的语法结构,最后生成符合目标语言规范的代码。现代工具通常会在中间表示层做类型推断和语义分析,这是保证翻译质量的关键环节。

Python转Java最棘手的挑战是类型系统差异。Python的动态类型意味着变量类型在运行时才确定,而Java要求编译时就明确类型。实际转换时我们通常采用三种策略配合使用:静态类型推断通过分析变量的赋值语句和使用上下文推断类型,比如看到count = 0; count += 1就能推断出int类型;运行时类型信息收集对于难以静态分析的场景,可以先运行Python代码收集类型trace,这在数据分析脚本转换中很常用;引入泛型或Object类型作为兜底方案,虽然损失了类型安全但保证了可转换性。
看一个具体的转换案例。假设有这样一段Python代码:
defprocess_data(items):
result =[]
for item in items:
if item >0:
result.append(item *2)
return result
转换到Java时需要推断出具体类型。这里的关键是理解items是什么类型的集合,item是什么类型的元素。通过上下文分析(比如item > 0的比较操作和item * 2的数值运算),可以推断出这是数值类型的列表:
publicList<Integer>processData(List<Integer> items){
List<Integer> result =newArrayList<>();
for(Integer item : items){
if(item >0){
result.add(item *2);
}
}
return result;
}
Python特有特性的映射是另一个关键挑战。列表推导式这种语法糖可以直接展开成for循环或者映射到Java的Stream API,但装饰器就复杂多了。Python里一个@cache装饰器在Java中可能要写成一个包装类,在方法调用前检查缓存,这本质上是用设计模式来弥补语言特性的差异。多重继承更棘手,Java只支持单继承,转换时要分析继承关系是为了复用代码还是定义接口契约,前者可以用组合替代,后者用接口实现。
大模型在代码翻译中最大的价值是处理长尾的语言特性和惯用法映射。传统基于规则的工具很难覆盖所有边界情况,而大模型通过学习海量代码能给出更符合目标语言习惯的转换结果。但模型的幻觉问题在代码翻译场景下会直接导致功能错误,所以实践中通常是大模型生成初版代码,然后用静态分析工具检查类型安全性和语法正确性,最后人工review关键业务逻辑。基于知识库的检索增强能显著提升翻译质量,比如构建常见API映射的向量库,翻译时检索相似转换案例给模型参考。
评估代码翻译质量不能只看能不能编译通过,要从多个维度衡量。语义正确性是第一位的,要跑完整的回归测试确保输入输出完全一致,这在算法密集型代码中尤其重要。可读性和惯用性同样关键,机械转换的代码可能充满不符合Java习惯的写法,比如把Python的下划线命名直接搬过来而不是用驼峰命名。性能维度也不能忽视,Python的某些写法直接翻译到Java可能效率很低,频繁的字符串拼接要改用StringBuilder。
实战中的转换策略与工具链
实际做代码翻译时,最重要的是先评估代码规模和复杂度,决定是人工重写、工具辅助还是AI生成。这个判断标准很实用:单个函数或百行以内的脚本,直接手写最快;成百上千行的模块,用转换工具打底再人工优化;如果是整个项目迁移,需要建立自动化流水线配合人工审查。
转换流程要把控好每个细节。假设要把Python的价格计算函数迁移到Java服务中,第一步是给Python代码补类型注解,这能极大降低后续推断难度。Python 3.5之后支持Type Hints,把函数签名改成def calculate_discount(price: float, rate: float) -> float:,转换工具或大模型就能直接对应到Java的方法签名。
from typing import List, Dict
defcalculate_total(items: List[Dict[str,float]])->float:
total =0.0
for item in items:
total += item['price']* item['quantity']
return total
有了类型注解后转换就清晰多了,但这里要特别注意:不要机械翻译,要写出符合Java习惯的代码。Python的字典在这里应该映射成Item对象而不是HashMap,这样类型更安全也更易维护:
publicclassItem{
privatedouble price;
privatedouble quantity;
publicdoublegetPrice(){return price;}
publicdoublegetQuantity(){return quantity;}
}
publicdoublecalculateTotal(List<Item> items){
return items.stream()
.mapToDouble(item -> item.getPrice()* item.getQuantity())
.sum();
}
工具链的选择要组合使用多种方案。传统的AST转换工具像Py2Java或者自己用JavaParser写转换脚本,适合处理语法层面的机械转换,优点是规则可控、输出稳定。但遇到复杂的语言特性,现在更常用的方式是让Claude或GPT-4这类大模型来做初版转换,它们对两种语言的惯用法理解更好,生成的代码可读性更高。关键是要配合静态检查工具,转换完用CheckStyle检查代码规范,用SpotBugs找潜在bug,用JUnit跑测试保证功能正确。
最近尝试用MCP(Model Context Protocol)来增强大模型的转换能力,建立了一个API映射知识库,记录常见的Python标准库到Java类库的对应关系。比如把pandas.DataFrame的操作转换成Java的流式处理或者直接用开源的Tablesaw库,这些映射规则存在向量数据库里,转换时检索相似案例提供给模型参考,翻译质量能提升一大截。
测试验证环节最能体现工程严谨性。代码能编译通过只是第一步,真正的验证要建立完整的测试体系。理想情况是Python原有的测试用例能够迁移到Java,用同样的输入数据跑测试,对比输出结果是否一致。如果是算法类代码,要特别注意浮点数精度问题,Python和Java的浮点运算可能有微小差异,需要设置合理的误差容忍度。对于Web服务迁移,可以建立影子流量测试,让Python和Java版本同时处理线上请求,对比响应结果和性能指标。
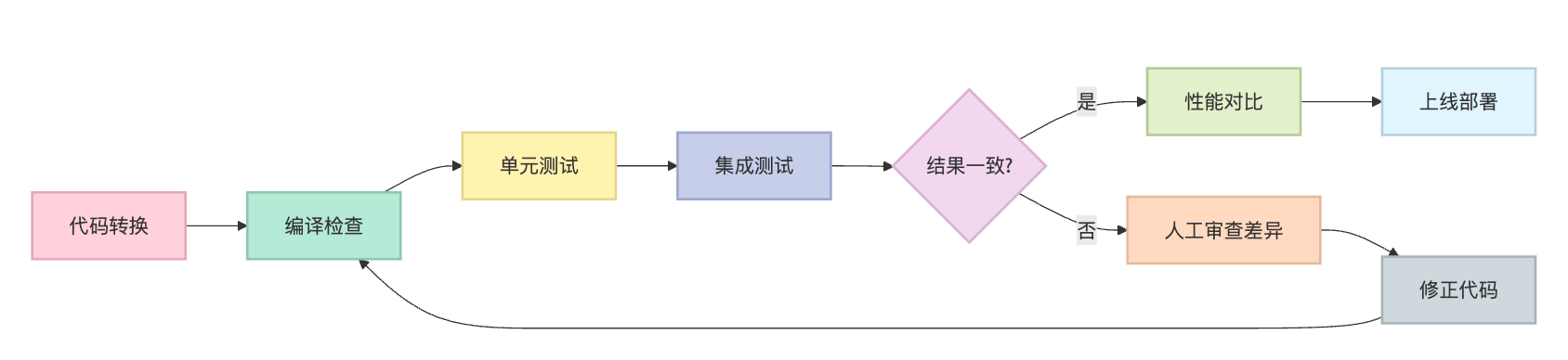
应用场景要贴近实际业务需求。系统迁移是最常见的场景,遇到过Python写的数据分析脚本要整合到Java微服务架构中的情况,因为公司主技术栈是Spring Boot,Python脚本独立部署维护成本高。这时候把核心计算逻辑翻译成Java工具类,保留Python作为数据预处理层,用RESTful接口打通,是个折中方案。多语言团队协作也是典型场景,算法团队用Python快速验证模型,工程团队要用Java部署到生产环境,代码翻译能加速这个交接过程。
避坑指南要记在心里。直译代码最大的问题是不惯用,比如把Python的item_list.append(x)直译成itemList.add(x)没问题,但如果整段代码充斥着过程式风格的循环累加,就该重构成Java的Stream API或者用合适的设计模式,让代码符合Java生态的最佳实践。性能陷阱也要当心,Python的列表拼接result = result + [item]直译成Java的result.addAll(Arrays.asList(item))效率极低,要意识到直接用add方法。异常处理的差异容易遗漏,Python常用鸭子类型不显式检查异常,Java的受检异常必须处理,转换时要补充try-catch或者在方法签名声明throws,否则代码根本编译不过。
架构视角下的代码翻译实践
代码翻译表面上在考察语言转换能力,实际上反映的是对技术架构演进的理解。技术选型不是一成不变的,当初选Python可能是为了快速验证业务,现在业务稳定了需要Java的高性能和完善生态,代码翻译就成了架构演进的必经之路。这种转换本质上是技术债务偿还的一种方式,背后反映的是技术选型决策的生命周期。
结合项目经验看,代码翻译往往发生在技术栈统一的关键节点。团队原本Python和Java服务并存,维护两套CI/CD流水线和监控体系成本太高,决定统一到Java栈。这时候不是简单的代码转换,而是整个技术体系的重新梳理。要考虑服务间的依赖关系,哪些模块可以渐进式迁移,哪些需要一次性切换。要建立双轨运行机制,新旧系统并行一段时间,通过灰度发布逐步验证翻译后代码的稳定性。
多语言服务整合的场景更复杂。算法团队用Python训练模型并导出预测逻辑,业务系统是Java的,中间需要代码翻译来打通。但实际操作时要权衡是全部翻译还是保持异构系统。如果预测逻辑相对稳定,翻译成Java能减少跨语言调用的开销;如果算法迭代频繁,保持Python用容器化部署,通过gRPC或RESTful接口集成可能更合理。这种判断需要综合考虑团队技能、维护成本、性能要求等多个因素。
2025年AI辅助编程已经是主流实践,代码翻译更多是人机协作模式。大模型负责生成初版代码,人类专注在语义验证和边界情况处理上,这种分工让翻译效率提升了一个数量级。但要保持清醒的认识,不是所有代码都值得翻译,有些模块保持原语言用容器化部署更合理,通过服务化接口集成比强行翻译性价比更高。拿着锤子看什么都是钉子是技术决策的大忌。
从长远来看,代码翻译能力也是评估团队技术广度的一个维度。能在多个技术栈间游刃有余,说明你对编程语言的本质有深刻理解,而不是停留在语法层面的认知。这种能力在面对技术选型调整、遗留系统改造、跨团队协作时都能发挥关键作用。记住,代码翻译不是目的,而是实现业务目标、优化技术架构的一种手段,战略判断力才是核心竞争力。