精炼回答
API文档确实可以自动生成,核心是从代码中提取结构化信息,再转换成可读文档。具体做法分两类:第一类是基于注释的生成,比如Java的Javadoc、Python的Sphinx、JavaScript的JSDoc,你在代码里按规范写注释(参数类型、返回值、描述),工具解析后生成HTML文档。Go语言更直接,godoc直接从函数签名和注释生成文档,连特殊标记都不需要。第二类是基于代码分析的生成,像Swagger/OpenAPI,通过装饰器或配置文件标注路由信息,自动生成RESTful API的交互式文档,能直接在浏览器里测试接口。
但自动生成有局限:它只能提取你写进代码的信息,业务逻辑、使用场景、最佳实践这些需要人工补充。所以实际工作中通常是半自动化——工具生成框架和基础信息,开发者补充example、注意事项等内容。现在也有基于LLM的方案,比如让GPT读代码生成文档初稿,但准确性还需要人工审核。工程上推荐做法是把文档生成集成到CI/CD,代码提交时自动触发文档更新并部署,这样API文档就能跟代码同步演进。关键是要在开发时就写好注释,而不是事后补文档,否则自动化就失去意义了。
扩展分析
从信息提取到文档生成的完整链路
面试时谈文档生成,最忌讳的是直接列举工具。面试官更想听到你对问题本质的理解——什么能自动化,什么必须靠人。文档生成本质上是一条信息流动的链路:从代码里抽取信息、转换成结构化描述、最后渲染成可读内容。传统方法和AI方法的根本差异在于,前者是静态解析代码符号,后者是理解代码语义。
以Swagger为例,它本质是做了两件事:一是通过注解或配置把接口元信息结构化,二是按OpenAPI规范序列化成JSON描述文件。在Spring Boot里,@GetMapping注解告诉Swagger这是个GET请求,@ApiOperation注解提供接口描述,返回值的类型定义又能自动推导出响应结构。开发者只需在正常写接口时多加几个注解,工具就能遍历所有Controller类提取信息,最后渲染成可交互的文档页面。
@RestController
@RequestMapping("/api/products")
publicclassProductController{
@ApiOperation(value ="查询商品详情", notes ="根据商品ID获取详细信息")
@GetMapping("/{id}")
publicResult<ProductDTO>getProduct(
@ApiParam(value ="商品ID", required =true)@PathVariableLong id){
return productService.findById(id);
}
}
这段代码能自动生成包含路径、参数类型、返回结构的文档,但Swagger不知道什么时候该用这个接口、哪些字段可能为空。这就引出传统方法的边界——它只能处理代码中显式声明的信息。TypeScript的文档生成效果比JavaScript好很多,因为类型定义本身就包含大量语义信息,工具能直接推导参数约束和返回结构,而动态语言需要开发者手动补充大量注释。这种方式的优势是开发者的心智负担小,但代价是文档只有骨架没有血肉。
LLM改变的正是这个天花板。传统工具是静态解析,LLM是理解语义。让GPT-4读一段接口实现代码,它能推断出"这个接口用于库存扣减,并发场景下需要注意幂等性",这些信息藏在业务逻辑里,规则工具提取不出来。实际方案里会给模型提供多种上下文:代码本身、单元测试用例、相关接口的文档、甚至Git的提交记录。测试用例特别重要,因为它展示了参数的实际取值和边界情况。拿支付接口举例,测试代码里有金额为零的异常case、有并发调用的压测脚本,这些都能帮模型理解接口的约束条件。
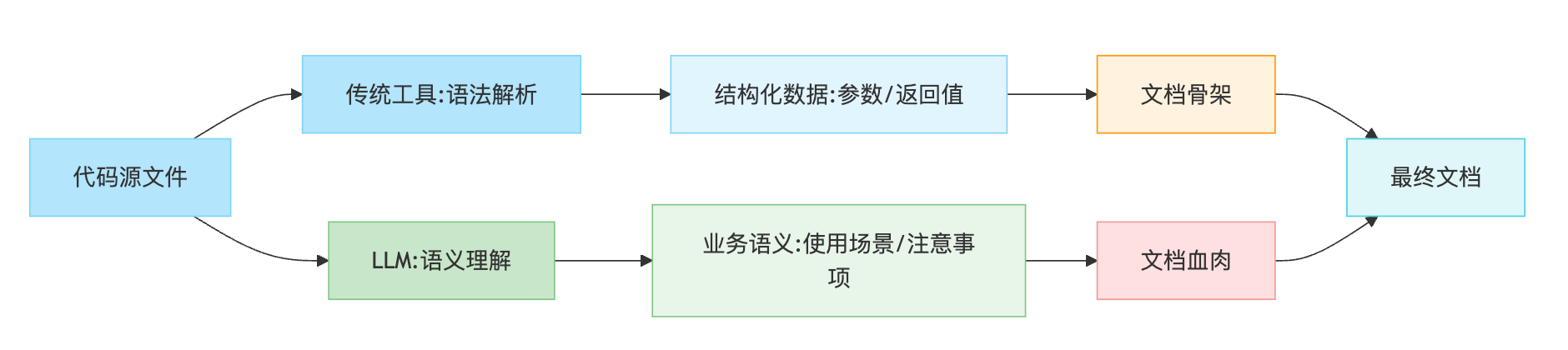
但生成的文档需要结构化验证,比如检查是否包含必需的章节、参数说明是否与代码签名一致、示例代码能否真正运行。实际项目里的做法是让另一个LLM做审核,或者人工抽查高频接口的文档。文档质量的上限取决于能获取的信息丰度,除了代码注释和类型定义,还有三个常被忽视的来源:API的实际调用日志能看到真实的参数分布和错误case,团队的知识库文档里会说明接口的依赖关系,线上问题的工单记录能总结出常见的误用场景。2025年很多团队用RAG的方式,把这些散落的信息源都向量化存到知识库,生成文档时让LLM先检索相关context再生成,准确性能提升一大截。
整个文档生成系统的架构可以分为三层:解析层负责从多源头提取信息,这里的关键是做好缓存,避免每次都全量扫描代码。生成层是传统和AI方法的分叉点,实际系统里两者常常并存——结构化信息走模板引擎快速生成,需要理解语义的部分调LLM。渲染层不只是展示,还要处理文档版本和API版本的对应关系,用户能切换查看不同版本的文档。
这套架构最容易出问题的地方是增量更新,代码修改后如何精准识别哪些文档需要重新生成。实际做法是给每个接口打指纹(基于签名和注释的hash),只重新生成变更部分,这样CI流水线里的文档生成能控制在分钟级。文档质量有四个维度,但它们经常互相冲突:准确性要求严格对齐代码实现,但可读性可能需要简化技术细节;完整性希望覆盖所有边界case,但会让文档变得冗长。电商的优惠券接口可能有十几种优惠叠加规则,如果全写进API文档会让调用方看晕,实际做法是文档里只说明通用逻辑和核心参数,复杂规则放到业务设计文档里。这就引出自动化程度的选择:全自动生成基础信息层(参数、返回值、错误码),半自动生成业务逻辑层(工具生成初稿、人工补充场景),完全人工编写最佳实践层(使用建议、性能优化)。这种分层既保证底层信息的同步更新,又不牺牲高层内容的质量。
工具链搭建与团队落地
谈具体怎么落地,最能看出你有没有真干过项目。关键是展示"从零搭建到稳定运行"的完整路径,而不是只会说用某个工具。工具链选择要根据技术栈来,但更重要的是考虑团队的接受度。Java项目里,Springdoc-openapi是个很实用的选择,它能和Spring Boot无缝集成,开发者在Controller上加几个注解就能自动生成OpenAPI 3.0规范的文档。
@Configuration
publicclassOpenApiConfig{
@Bean
publicOpenAPIcustomOpenAPI(){
returnnewOpenAPI()
.info(newInfo()
.title("订单服务API")
.version("v1.0")
.description("负责订单创建、查询、状态流转等核心功能"))
.servers(List.of(
newServer().url("https://api.prod.com").description("生产环境"),
newServer().url("https://api.test.com").description("测试环境")));
}
}
这个配置看起来简单,但实际项目里经常遇到的问题是多环境管理。你得确保测试环境的文档URL指向测试服务器,生产环境指向生产服务器,不然调用方拿着文档测试时会请求到错误的地址。
工具能生成什么样的文档,上限取决于注释写得有多规范。实际做法是制定团队级别的注释模板,明确哪些信息必须写。一个完整的接口注释应该包含业务场景、注意事项、参数说明、异常情况,像这样:
/**
* 创建订单接口
* <p>业务场景:用户选择商品加入购物车后,点击结算生成订单</p>
* <p>注意事项:
* 1. 库存不足时会抛出业务异常,前端需展示具体缺货商品
* 2. 优惠券使用后立即锁定,订单取消时需释放
* 3. 接口具有幂等性,相同的请求ID重复调用返回首次结果
* </p>
*
* @paramrequest 订单创建请求,包含商品清单、收货地址、优惠券等信息
* @return 订单创建结果,包含订单号和预计送达时间
* @throwsInsufficientStockException 库存不足时抛出
* @throwsInvalidCouponException 优惠券不可用时抛出
*/
@PostMapping("/orders")
publicOrderResponsecreateOrder(@Valid@RequestBodyOrderRequest request){
return orderService.create(request);
}
传统工具能从这段注释里提取出参数说明和返回值结构,但那些业务场景、注意事项、幂等性说明,是调用方最需要的信息。要在代码评审阶段检查注释完整性,设置卡点——如果注释缺少必需字段,CI流水线直接失败。这听起来严格,但执行一两个月后,团队就会养成习惯。
现在LLM可以做两件事:生成更自然的描述,自动补充示例代码。测试用例包含了大量边界情况,LLM能从里面提取出"什么情况下接口会失败"这类信息。比如测试代码里有个case是库存为0时下单,LLM就能在文档里写出"库存不足时返回错误码10001"。但生成的内容必须人工审核,尤其是涉及金额、权限的敏感逻辑。实际做法是让LLM生成Markdown草稿,技术负责人review后再合并到主文档。
defenhance_api_doc(api_code, test_cases):
prompt =f"""
你是API文档专家,请根据以下信息生成接口文档的"使用场景"和"请求示例"章节:
接口代码:
{api_code}
单元测试用例:
{test_cases}
要求:
1. 使用场景要描述真实业务流程,不要只说技术实现
2. 请求示例要包含正常场景和异常场景各一个
3. 参数取值要符合业务规则(如金额大于0、手机号11位)
4. 用中文输出,语言简洁专业
"""
return call_llm(prompt)
CI/CD集成要设计成两个触发点:一个是代码合并时自动更新,一个是手动触发全量重新生成。文档生成放在build之后是因为需要编译后的字节码才能提取注解信息。生成的静态站点直接部署到S3或CDN,这样研发和外部调用方都能访问最新版本。
stages:
- build
- doc
- deploy
generate_docs:
stage: doc
script:
- mvn compile # 触发注解处理器
- mvn springdoc-openapi:generate # 生成OpenAPI JSON
- npm run docs:build # 渲染成静态站点
artifacts:
paths:
- docs/dist/
only:
- main
- develop
deploy_docs:
stage: deploy
script:
- aws s3 sync docs/dist/ s3://api-docs-bucket/
only:
- main
版本管理很关键,API v1.0和v2.0的文档要能并存。实际做法是在URL路径里带版本号,比如/docs/v1/和/docs/v2/,每次发布新版本时保留旧版本文档,避免已有调用方受影响。文档质量检查分自动化和人工审核两层,自动化这层可以写个脚本检查每个接口是否包含必需的文档元素,如果缺少关键信息,构建直接失败,强制开发者补全。
defvalidate_api_doc(openapi_json):
errors =[]
for path, methods in openapi_json['paths'].items():
for method, spec in methods.items():
# 检查必需字段
if'summary'notin spec:
errors.append(f"{method.upper()}{path} 缺少摘要")
if'responses'notin spec or'200'notin spec['responses']:
errors.append(f"{method.upper()}{path} 缺少成功响应定义")
# 检查示例代码
if'requestBody'in spec:
schema = spec['requestBody']['content']['application/json']['schema']
if'example'notin schema:
errors.append(f"{method.upper()}{path} 缺少请求示例")
return errors
核心接口的文档要求技术Leader做二次审核,重点看业务描述是否准确、示例代码能否真正运行。在代码评审时专门有个checklist,包含"文档是否同步更新"这一项。整个流程的关键在于每个环节都有验证机制,不会让低质量文档流到线上。

通知调用方这步很容易被忽略,但实际上API文档更新后,应该通过企业微信或邮件告知调用方,尤其是有Breaking Change的时候。文档生成最大的挑战不是技术实现,而是让团队形成"代码即文档"的意识。工具和流程都是辅助,核心还是开发者愿意在写代码时多花两分钟写清楚注释。
从接口契约到知识管理的战略高度
面试官问文档生成这个问题,表面上考察技术方案,实际上是在测试你对开发者体验和团队协作的理解。技术Leader更关心的不是你会用什么工具,而是你能不能看到文档在整个研发体系里的战略位置——它既是接口契约,又是知识沉淀,还是团队协作的粘合剂。
文档漂移是最大的敌人,一旦文档和代码不同步,调用方就会失去信任,再也不看文档了。把文档一致性校验嵌入到CI流水线,代码改了但注释没更新就直接构建失败。更高级的做法是在发布阶段做契约测试,用生成的OpenAPI定义去验证真实接口的响应是否匹配,这样能在上线前就拦住不一致的情况。
接口在迭代过程中会有Breaking Change,文档系统要能按版本分发,每个API版本对应独立的文档站点,用户能通过下拉菜单切换查看。更重要的是废弃策略,旧版本接口不能说下就下,要在文档里标注Deprecated状态、给出迁移指南、设置合理的下线时间窗。这些细节体现你考虑过调用方的迁移成本,而不是只站在服务提供方角度思考问题。
多语言支持看似是边缘话题,但如果团队有国际化需求就变得很关键。纯技术描述好翻译,业务术语和使用场景的翻译很容易出错。现在借助LLM能做得更智能,让模型在翻译时保留技术准确性,同时适配目标语言的表达习惯。比如中文文档里说"秒杀接口需要限流",英文翻译成"Rate limiting is required for flash sale endpoints"会更地道。
API文档只是冰山一角,水面下是整个团队的知识体系。好的文档系统应该能串联起设计文档、代码实现、测试用例、故障记录这些分散的知识节点。拿订单接口举例,文档里不只有参数说明,还应该能跳转到架构设计文档查看服务依赖关系、能关联到历史故障工单了解过哪些坑、能链接到性能测试报告看并发表现。这种立体化的知识网络能让新人快速理解系统全貌,老员工也能随时回溯历史决策。2025年知识库和RAG技术成熟后,这件事变得更可行——把文档、代码、工单都向量化,用户问"支付接口为什么要求幂等性"时能检索到相关的所有信息源。
文档质量直接影响团队效率。调用方如果每次对接都要来问参数含义、跑去翻代码理解业务逻辑,沟通成本就会吃掉自动化带来的收益。好的文档能让调用方自助完成大部分工作,只在遇到真正的业务问题时才需要人工介入。这不只是技术问题,更是团队协作文化的体现——愿意花时间写清楚文档的团队,往往代码质量也更高,因为清晰的表达背后是清晰的思考。