精炼回答
回答这道题要展现从局部到全局的思维层次。代码补全和代码理解有本质区别——补全只需要局部上下文,但真正有用的代码助手需要理解整个仓库的架构和依赖关系。上下文构建我会分三层来考虑:第一层是光标附近的代码,这是基础;第二层是通过AST解析出来的直接依赖,比如import的模块、调用的函数;第三层是间接依赖,需要通过依赖图做多跳查询。
现在主流做法是把代码检索当作RAG问题来解决,给代码库建立向量索引,用CodeBERT这类模型做embedding,然后根据当前编辑位置做语义检索。但关键是排序策略,要综合考虑语义相似度、调用距离、最近修改时间这几个维度。实际工程中会用混合检索,BM25召回加向量精排,这样既保证精度又控制延迟。
在token预算限制下,我会优先保证当前文件完整,然后是被直接调用的接口定义,实现细节可以截断或者只保留函数签名和注释。理想情况下上下文应该是动态演化的,根据用户的编辑行为实时调整,比如用户刚修改了某个工具类,那这个类的优先级就应该提高。
扩展分析
从信息检索本质看上下文构建的演进
讲清楚代码模型的上下文构建,最关键的是理解这个问题背后的信息检索本质。早期的代码补全工具像Eclipse的智能提示,只能看到当前文件和已经import的符号,这种方式在小项目还凑合,但面对几十万行代码的仓库就彻底失效了。真正的挑战不在于怎么让模型理解代码语法,而在于在海量代码中找到最相关的那部分,然后用有限的token预算把它们组织成模型能理解的形式。
这个问题的演进路径其实跟搜索引擎很像。最早大家想的是把整个仓库都塞进上下文,但这在工程上根本不可行——一个中型仓库可能有几百万行代码,即使GPT-4 Turbo的128k上下文也装不下。所以2022年之后的主流思路转向了检索增强生成这个范式,先通过检索缩小范围,再把精选内容喂给模型。这个转变背后的哲学很重要:我们不是在训练模型记住所有代码,而是在构建一个高效的代码索引系统,让模型能够按需获取信息。
代码不是孤立的文本,每个函数、每个类都是依赖网络中的一个节点。当你要补全一个调用支付接口的代码时,最相关的上下文不是语义上相似的代码片段,而是支付接口的定义、参数类型、返回值结构,以及已有的调用示例。这就涉及到静态分析和动态分析的结合——静态分析靠AST解析出调用图和依赖图,动态分析则要追踪运行时的调用链路。tree-sitter这类工具做跨语言的语法解析,Language Server Protocol提供符号索引能力,这些都是构建依赖关系的基础设施。
Repo-level理解的核心难点在于跨文件的语义关联。语义检索解决了"找到相似代码"的问题,但代码仓库的逻辑关系更复杂。假设你在写一个商品推荐服务的接口,需要调用用户画像服务、商品库存服务、价格计算服务。这些服务可能定义在不同的模块,用不同的RPC协议,但它们在业务逻辑上紧密耦合。纯语义检索可能找不到正确的依赖,因为"获取用户画像"和"查询商品库存"在向量空间里距离很远。这时候就需要图神经网络或者多跳推理,沿着调用图做路径搜索,把间接依赖也纳入上下文。
工程实现要平衡效果和延迟。理论上我们希望给模型提供完整的依赖链路,但实际工程中每增加一次图遍历都会增加延迟。现在比较实用的做法是混合策略:第一阶段用倒排索引和向量召回做粗筛,这一步要快,延迟控制在50ms以内;第二阶段对召回结果做依赖分析和调用链补全,这一步可以容忍200ms左右的延迟;第三阶段是排序和截断,根据token预算做最终的取舍。这种分阶段的设计能让代码补全保持在300ms以内,否则用户就会感觉卡顿。

关于上下文的动态演化,这是2025年比较前沿的方向。传统的上下文构建是静态的——用户触发补全时才去检索相关代码。但更聪明的做法是预测性预加载:当用户打开某个文件,或者跳转到某个函数定义时,系统在后台就开始构建可能需要的上下文。比如用户正在浏览订单处理逻辑,系统可以推测他接下来可能需要支付、物流、库存相关的代码,提前把这些模块的索引加载到内存。这种预测可以用简单的马尔可夫模型,也可以用专门的序列模型来训练。
大规模仓库的索引更新也是个实际的工程挑战。代码仓库每天可能有几十上百次提交,如果每次提交都重新索引整个仓库,成本受不了。增量索引的思路是用Git diff识别出修改的文件,只对变更部分重新生成embedding,然后更新向量索引的对应条目。但要注意依赖关系的传播,如果某个基础类被修改了,所有依赖它的代码的上下文都需要失效重建。这种失效传播可以用依赖图的拓扑排序来优化,避免全量扫描。
跨语言理解在微服务架构里特别常见。一个需求可能涉及Java写的后端服务、Python写的算法模型、TypeScript写的前端界面。这时候上下文构建不能只看单一语言的语法树,而要理解服务间的接口契约。优先索引接口定义文件,比如Protobuf的.proto文件、OpenAPI的swagger文档,因为它们是跨语言通信的规范。然后根据RPC调用关系,把不同语言的实现代码关联起来。
实践场景中的策略选择与优化路径
最典型的应用场景是代码补全,但要细分具体情况。比如在写业务逻辑代码的时候,用户可能正在实现一个支付回调处理函数,这时候上下文构建的重点是找到支付网关的接口定义、已有的交易状态枚举、历史订单的处理示例。遇到这种场景,优先通过AST解析当前函数的参数类型,假设参数是PaymentCallback对象,就沿着这个类型的定义往上追溯,把整个支付领域模型都纳入上下文。同时用BM25检索找到仓库里其他地方是怎么处理类似回调的,这种模式匹配对生成符合项目规范的代码特别有效。
另一个常见场景是代码审查和重构。当用户想把某个函数的实现改成异步模式,或者要把同步RPC调用替换成消息队列,这时候上下文构建的策略就完全不同。需要找到所有调用这个函数的地方,分析它们是否能容忍异步语义,还要检查是否有事务依赖。这种场景下单纯的语义检索没用,必须结合调用图做影响面分析。用静态分析工具生成完整的调用链路,然后把所有caller和callee的代码都放进上下文,让模型理解改动的影响范围。这时候token预算会很紧张,保留完整的函数签名和关键注释,但可以把循环体、异常处理这些实现细节截断。
实现层面有几个关键点直接影响用户体验。缓存策略首当其冲,上下文构建的结果要按文件粒度做缓存,用文件的Git commit hash作为缓存key。这样用户在同一个文件里多次触发补全,第二次就能直接复用检索结果,延迟能降到10ms以内。但缓存失效要特别小心,如果用户在另一个窗口修改了依赖文件,必须主动刷新缓存,否则模型看到的是过期上下文。可以用文件系统监听或者Language Server的didChange事件来触发失效。
并发控制同样重要。代码仓库的索引构建和上下文检索都是IO密集型操作,如果不做并发优化,延迟会爆炸。把检索任务拆成多个子任务并发执行,比如语义检索、AST解析、调用图查询可以同时做,最后再merge结果。但并发度不能太高,一般控制在CPU核数的2倍以内,避免线程切换开销。向量检索这种计算密集的操作,建议用GPU加速或者FAISS这种优化过的库。
优化方向上,2025年值得提的是预计算和懒加载的结合。对于高频访问的核心模块,比如工具类、常用的领域模型,可以在用户打开IDE的时候就预先构建好上下文,存在内存里。但长尾的业务代码就用懒加载,只有用户真正打开文件时才去检索。这种冷热分离的策略能让90%的场景延迟控制在100ms以内,同时不会占用太多内存。识别核心模块可以基于Git历史统计提交频率,或者用PageRank算法分析依赖图的重要性。
最后要避免的误区是追求完美的上下文。早期总想把所有相关代码都塞进上下文,结果token占用太高,模型推理变慢,用户体验反而变差。后来明白了一个道理,代码补全追求的是够用而不是完美。宁可给70%相关的上下文快速返回结果,也不要为了90%的准确率让用户等500ms。
从工程实践到架构思维的跃迁
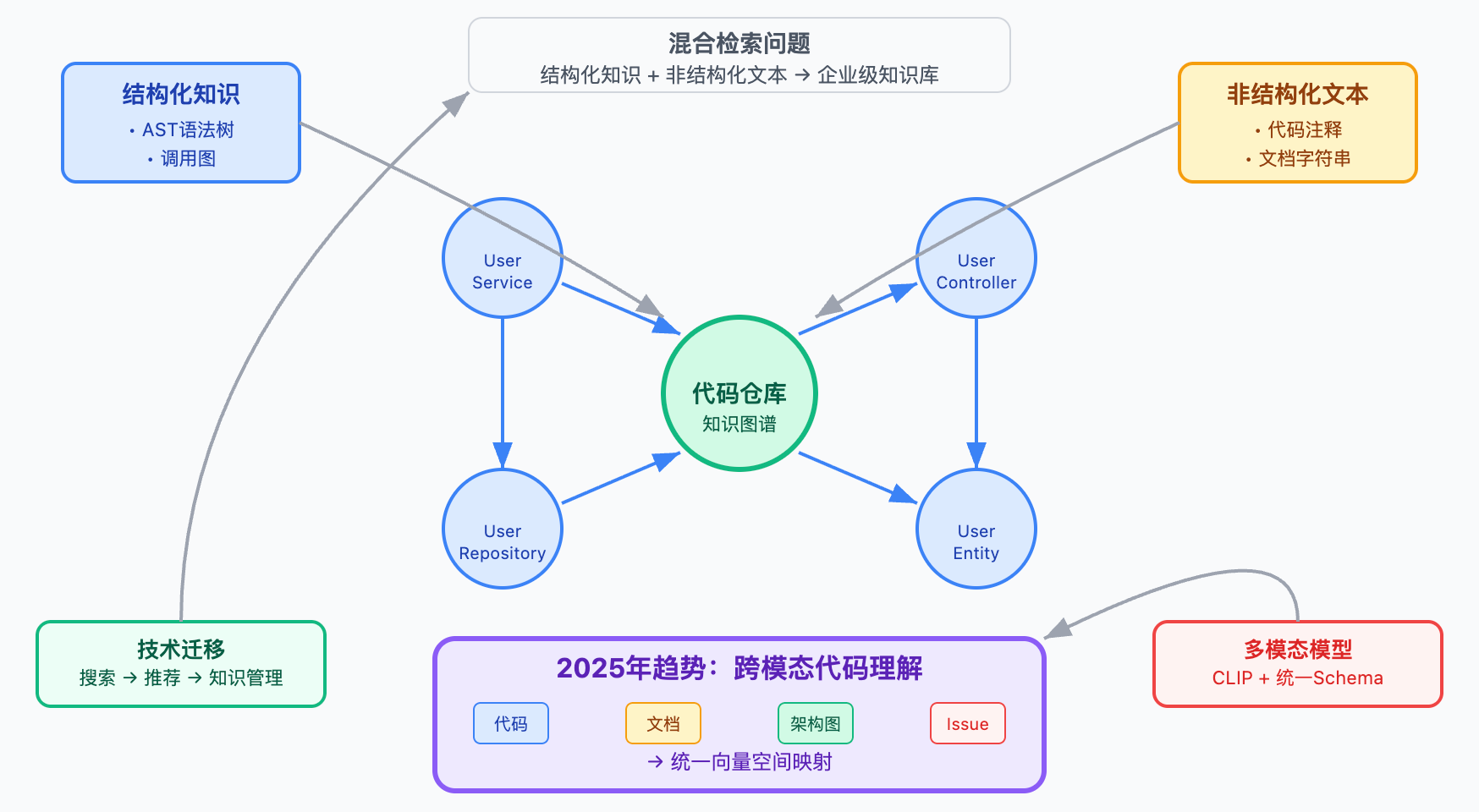
这道题表面是在考察对代码模型的理解,实际是在测试系统设计能力和工程判断力。代码仓库的依赖关系本质上就是一个知识图谱,节点是代码单元,边是调用关系和依赖关系。所以Repo-level理解跟企业级知识库的构建思路是相通的——都要解决结构化知识和非结构化文本的混合检索问题。如果之前有做过搜索、推荐或者知识管理的经验,这些技术都可以迁移到代码理解场景。
从2025年开始的趋势是代码理解不只看代码文本,还要结合文档、注释、设计图、甚至issue讨论。很多团队会把Confluence文档、Jira需求、架构图都纳入检索范围。比如用户在写某个功能,如果能找到对应的设计文档和历史讨论,模型生成的代码会更符合预期。这就涉及到跨模态的语义对齐问题,文本、表格、架构图要统一映射到同一个向量空间。可以用CLIP这类多模态模型做embedding,或者用统一的schema描述不同类型的知识。
如果从零开始设计一个代码助手,要先明确目标用户。如果是给内部团队用,可以深度定制,利用企业内部的代码规范和最佳实践。如果是做通用产品,就要在通用性和精度之间找平衡。迭代策略也很关键:第一阶段先保证基础补全能用,只做当前文件的上下文;第二阶段接入依赖分析,支持跨文件理解;第三阶段才考虑预测性加载和Agent能力。这种分阶段的思维体现了快速迭代和风险控制的能力,比想一步到位更实际。
说到底,代码模型的上下文构建是在解决一个信息过载和信息稀缺的矛盾——仓库里有海量代码,但真正相关的可能只有几百行。系统化的方法来平衡召回率和精确率、广度和深度、延迟和效果,这比单纯背诵RAG、Embedding、AST这些术语要有说服力得多。