精炼回答
AI编程工具的安全性需要多层防护机制来保障。首先要在训练阶段就注入安全编码实践,让模型学习OWASP Top 10等常见漏洞模式,并在训练数据中标注危险代码。生成代码时,必须集成静态代码分析工具如SonarQube、CodeQL进行实时扫描,检测SQL注入、XSS、硬编码密钥等问题。
实际应用中,建议设置代码审查关卡,不要直接采纳AI生成的代码。可以配置IDE插件在代码提交前自动运行安全检查,比如使用Snyk扫描依赖漏洞,用Semgrep检测危险函数调用。对于敏感场景如支付、鉴权模块,强制要求人工复核,重点关注边界条件处理和权限校验逻辑。
另外要建立上下文隔离,避免让AI处理包含敏感信息的代码片段,防止凭据泄露。定期用渗透测试和模糊测试验证生成代码的安全性,发现问题后将案例反馈到模型优化流程中。记住AI工具只是辅助,最终安全责任在开发者,需要保持对生成代码的质疑态度,特别是涉及用户输入处理、文件操作、网络请求这些高危区域的代码,必须逐行验证其防御措施是否到位。
扩展分析
面试时的回答策略
面试时遇到这道题,千万别一上来就堆砌工具名称,面试官更想看到你的系统性思维。建议用"防护全生命周期"的框架来组织回答,这样既能展现技术广度,又能体现架构视角。
开场可以这样定调:"AI编程工具的安全保障需要贯穿代码生成的全链路,我习惯从三个维度来看这个问题——源头预防、过程控制和结果验证。"这句话立刻把回答框架立住了,让面试官知道你有清晰的思考结构。
接下来快速点出关键措施建立可信度。源头预防可以提到训练数据的安全标注,比如让模型在学习阶段就认识OWASP常见漏洞模式;过程控制强调实时静态扫描,像CodeQL这类工具在代码生成时就介入检测;结果验证则突出人工复核机制,特别是支付鉴权等敏感模块必须有二次审查。这三板斧下来,既覆盖了技术手段,又体现了工程管理意识。
关键要传递一个态度:AI工具只是辅助角色,安全责任最终在开发者手里。面试时可以加一句"我们不能因为工具智能化就放松警惕,尤其处理用户输入、文件操作这些高危场景时,必须保持对生成代码的质疑精神"。这种表述会让面试官觉得你既懂技术,又有安全意识和责任担当。
说完框架后自然过渡到具体实践,可以说"具体落地时我会重点关注这几个环节",然后引出工具集成、审查流程等细节内容。这样的回答结构清晰、层次分明,30秒内就能给面试官留下专业印象。
问题的本质画像
面试官问到AI工具代码安全这道题,其实是在考察你对软件安全的系统性理解。先说清楚问题长什么样会更有说服力,AI生成代码最常见的安全隐患集中在几个高危区域,比如SQL注入、XSS跨站脚本、硬编码密钥、权限校验缺失。用一个具体例子让面试官感受到问题的真实性会很有效。
AI工具在生成数据库查询代码时,经常会直接拼接用户输入生成SQL语句,却没有做参数化处理。拿订单查询功能举例,如果让AI生成根据订单号查询的代码,它可能会写出直接拼接SQL的危险代码。这种写法直接把用户输入拼到SQL里,攻击者输入' OR '1'='1就能绕过查询条件。面试时点到这个程度就够了,不用展开讲注入原理,重点是让面试官看到你能识别AI生成代码的典型缺陷。
另一个高频问题是敏感信息硬编码。AI工具在生成配置类或数据库连接代码时,可能会把数据库密码、API密钥直接写在代码里。这时候可以补一句:"这些问题不是AI工具故意制造的,而是训练数据里大量存在这类不安全的示例代码,模型学到的就是这种模式。"这种分析会让面试官觉得你理解问题的根因,而不是简单吐槽工具不好用。
源头预防的关键策略
讲完问题画像,自然过渡到源头预防。这里最容易答偏的点是只谈工具侧的防护,忽略了模型训练阶段的工作。要让AI工具生成安全代码,第一步是在训练阶段就植入安全编码规范。
具体怎么做可以提两个方向。安全数据集的标注和清洗是基础工作。在模型训练时专门准备OWASP Top 10漏洞的反例数据集,把危险代码模式做负面标注,让模型学会识别和规避。比如训练数据里遇到字符串拼接SQL的代码,就标记为不安全实践,同时给出PreparedStatement的安全写法作为正例。这种对比学习能显著提升模型的安全感知能力。
在Prompt工程层面加入安全约束也很关键。现在很多AI编程工具都支持自定义System Prompt,可以在系统提示词里明确要求:"生成代码时必须使用参数化查询,禁止拼接SQL;所有用户输入必须经过校验和转义;敏感配置使用环境变量而非硬编码。"这相当于给AI戴上了一个安全规则的紧箍咒。面试时提到这点能体现你对2025年主流AI工具可配置性的了解,毕竟现在ChatGPT、Claude这些工具都支持定制化的安全策略注入。
过程控制的实时防护
源头预防说完,接着讲代码生成过程中的实时控制。这里的核心思路是"不信任AI的任何输出"。即使训练阶段做了安全优化,生成代码时仍然需要实时扫描兜底。
最直接的做法是集成静态代码分析工具。像CodeQL、SonarQube这些SAST工具可以在代码生成的瞬间就介入检查。具体实现上,可以在IDE插件层面做集成,当AI工具输出代码片段后,先经过静态扫描引擎处理,检测出SQL注入、硬编码密钥、不安全的反序列化等问题,再决定是否呈现给开发者。
这里有个细节值得展开。传统的静态扫描工具是批量分析整个代码库,但AI生成代码是增量式的片段输出,需要支持上下文感知的检查。比如AI生成了一个处理用户上传文件的方法,扫描工具不仅要检查这个方法本身有没有路径遍历漏洞,还要结合调用链路分析权限校验是否到位。面试时提到"上下文感知检查"这个概念,能显示你对安全检测深度的理解。
另一个过程控制的关键点是安全规则引擎的集成。可以把企业内部的安全编码规范转化为可执行的规则集,通过Semgrep这类语义扫描工具实时校验。比如公司规定所有HTTP请求必须带CSRF Token,那就配置规则检测代码里的表单提交逻辑是否包含Token生成和校验。支付模块的代码必须经过金额校验的双重检查,这类业务相关的安全规则都能固化到自动检测流程里。
结果验证的多层审查
讲完实时控制,要把话题引到结果验证层。静态分析工具有局限性,复杂的业务逻辑漏洞还是需要人工复核。这里建议按照代码敏感度分级处理。普通的工具方法、数据模型类可以信任AI生成的代码加上自动扫描的结果,但涉及鉴权、支付、数据导出这些核心链路,必须拉入人工审查环节。
具体实践上可以提到代码审查卡点的设置。在Git提交阶段配置Pre-commit钩子,AI生成的代码提交时自动触发安全检查,扫描不通过直接阻断提交。更进一步,在PR合并环节设置安全专家的强制Review规则,特别是那些操作敏感数据、调用外部接口的代码,必须有安全团队成员签字才能合入主干。
自动化测试也是验证环节的重要一环。除了代码审查,还要用DAST工具做动态测试。比如生成了一个登录接口的代码,部署到测试环境后用OWASP ZAP或Burp Suite跑一遍渗透测试,模拟SQL注入、暴力破解、会话劫持等攻击场景,看看生成的代码在真实攻击下的表现。这种动静结合的验证方式能大幅降低漏洞遗漏率。
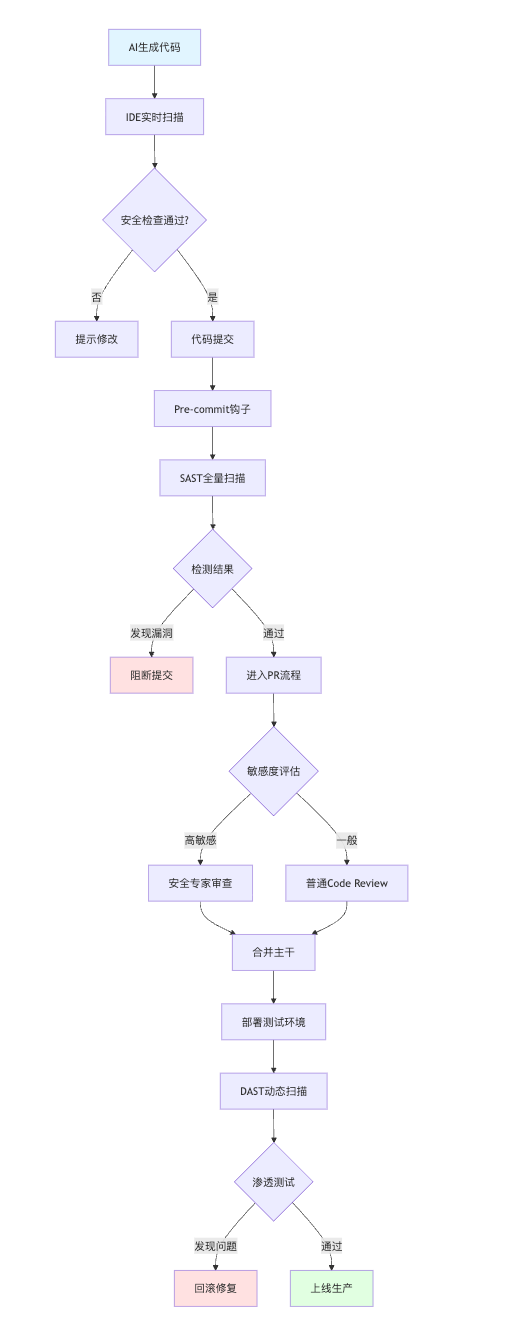
工具链的整合落地
前面讲的策略都需要工具支撑,实际落地时要在IDE、CI/CD、运行时三个层面部署安全工具。IDE层面集成GitHub Copilot的安全增强插件或者Amazon CodeWhisperer的漏洞扫描功能,让开发者在编码阶段就能看到安全提示。CI/CD环节接入Snyk做依赖扫描,检查AI生成代码引入的第三方库是否存在已知漏洞,同时用Checkmarx或Fortify跑全量的SAST分析。
运行时防护也不能忽视。即使代码通过了所有前置检查,部署到生产环境后还要配置WAF和RASP工具做最后一道防线。比如部署ModSecurity规则集拦截异常请求,或者使用Contrast Security这类运行时应用自保护方案,在代码实际执行时监控可疑行为。面试时提到运行时防护能体现你的纵深防御思维,毕竟静态检查再严格也可能有漏网之鱼。
持续改进的安全闭环
安全防护不是一次性工程,需要建立漏洞反馈的闭环机制。每次在生成代码里发现安全问题,都要把案例记录到安全知识库里。这个知识库包含漏洞的代码特征、修复方案、检测规则三部分。当积累到一定数量后,可以用这些数据对AI模型做微调,让它在相似场景下不再犯同样的错误。
另一个改进方向是安全规则的动态更新。随着攻击手段演进,OWASP会不断发布新的漏洞类型,公司内部的安全规范也会调整。需要有专人负责把这些最新的安全要求转化为检测规则和训练数据,定期刷新AI工具的安全基线。可以建立季度级的安全策略Review机制,确保AI工具的防护能力跟上威胁演变的速度。
如果想展现前瞻性,可以提到AI Agent在代码安全中的应用。2025年已经有团队在尝试用专门的安全Agent对AI生成的代码做自动化审查,这个Agent本身也是大模型驱动的,能理解代码的业务语义,发现那些静态工具难以识别的逻辑漏洞。比如一个订单折扣计算的方法,传统工具只能检查有没有整数溢出,但安全Agent能分析出折扣叠加逻辑是否存在被恶意利用的可能。这种AI对抗AI的思路代表了未来的方向。
实践应用
从引入工具开始建立边界
团队引入GitHub Copilot的时候,第一件事不是让大家马上用起来,而是先制定使用边界。明确规定涉及密钥管理、权限校验、支付结算这些核心模块的代码,AI只能提供参考不能直接采纳。数据库操作、文件上传、外部API调用这类高危操作,生成的代码必须经过人工逐行检查。
有个细节特别能加分,就是配置AI工具本身的安全选项。在GitHub Copilot的企业版里可以设置代码片段收集策略,禁止把包含敏感关键词的代码发送到云端。还能配置自定义的安全Prompt,让AI在生成代码时自动遵循公司的安全编码规范。这些配置项能把工具调教到可控状态,而不是盲目使用。
工具链的具体集成实践
在IDE这一层装上Copilot后,同时安装SonarLint插件做实时静态检查。当Copilot生成一段数据库操作代码时,SonarLint会在几秒内给出安全提示,比如发现了SQL拼接就直接标红告警。这个即时反馈特别重要,开发者在接受代码建议的瞬间就能看到安全问题,而不是等到提交代码才发现。如果是处理用户输入的逻辑,IDE里还会集成OWASP Dependency-Check插件,检查引入的第三方库有没有已知漏洞。这种IDE层面的实时拦截,能在问题扩散之前就消灭掉,比事后扫描效率高得多。
CI/CD环节的工具配置更要体系化。在GitLab Pipeline里设置多道检查关卡,第一关用Snyk扫描依赖项,确保AI生成代码引入的npm包或Maven库没有CVE漏洞。第二关跑Checkmarx的SAST全量分析,检测硬编码密钥、不安全的加密算法、未校验的重定向这些问题。第三关用自定义的Semgrep规则集,检查是否符合公司特定的安全规范。比如规定所有对外接口必须有请求频率限制,Semgrep就扫描Controller层代码看有没有@RateLimiter注解。这三关下来,任何一关失败构建就会被阻断,代码根本合不进主干。
代码审查的针对性设计
自动化工具能拦住常规问题,但业务逻辑层面的安全隐患还是需要人来判断。针对AI生成代码的审查要比普通代码更细致,在PR模板里增加专门的安全检查项。要求提交者确认代码里是否包含用户输入处理,如果有,必须说明做了哪些校验措施。是否涉及敏感数据操作,如果是,需要标注数据脱敏和访问日志的实现位置。是否调用了外部服务,如果调用了,要说明超时处理和异常降级策略。这些检查项逼着开发者在提交代码时就主动思考安全问题。
审查的时候还有个技巧,就是重点关注AI生成代码的**"接缝处"**。AI通常只能生成方法级别的代码片段,但它不理解这个方法会在什么上下文里被调用。举个例子,AI生成了一个导出用户数据的方法,代码本身看起来没问题,做了参数校验也做了SQL防注入。但审查时要检查调用这个方法的地方有没有做权限判断,确保普通用户不能导出别人的数据。这种跨模块的安全链路,AI是看不到的,必须靠人工审查来兜底。
真实案例的经验教训
曾经遇到过一次AI生成代码导致的安全问题,挺有代表性的。让Copilot生成一个文件上传的接口,AI给出的代码功能上没问题,能正常接收文件并保存到服务器。但仔细检查后发现,它只校验了文件大小,没有验证文件类型和文件名。攻击者可以上传一个后缀改成.jpg的JSP木马文件,如果保存路径没做好隔离,这个文件就能被容器解析执行。
// AI生成的原始代码 - 存在安全风险
@PostMapping("/upload")
publicStringuploadFile(@RequestParam("file")MultipartFile file){
if(file.getSize()> MAX_SIZE){
thrownewIllegalArgumentException("文件过大");
}
String fileName = file.getOriginalFilename();
String uploadPath ="/var/www/uploads/";
file.transferTo(newFile(uploadPath + fileName));
return"上传成功";
}
// 修复后的安全版本
@PostMapping("/upload")
publicStringuploadFile(@RequestParam("file")MultipartFile file){
// 检查文件大小
if(file.getSize()> MAX_SIZE){
thrownewIllegalArgumentException("文件过大");
}
// 验证文件类型(MIME类型)
String contentType = file.getContentType();
List<String> allowedTypes =Arrays.asList("image/jpeg","image/png","image/gif");
if(!allowedTypes.contains(contentType)){
thrownewSecurityException("不支持的文件类型");
}
// 验证文件扩展名
String originalFilename = file.getOriginalFilename();
String extension = originalFilename.substring(originalFilename.lastIndexOf("."));
if(!Arrays.asList(".jpg",".png",".gif").contains(extension.toLowerCase())){
thrownewSecurityException("不支持的文件扩展名");
}
// 生成安全的随机文件名,避免路径遍历
String safeFileName = UUID.randomUUID().toString()+ extension;
// 使用安全的路径拼接
Path uploadDir =Paths.get("/var/www/uploads").toAbsolutePath().normalize();
Path targetPath = uploadDir.resolve(safeFileName).normalize();
// 确保目标路径在上传目录内
if(!targetPath.startsWith(uploadDir)){
thrownewSecurityException("非法的文件路径");
}
// 保存文件
file.transferTo(targetPath.toFile());
// 记录上传日志
log.info("文件上传成功: {}, 用户: {}", safeFileName,getCurrentUser());
return"上传成功: "+ safeFileName;
}
在代码审查时发现了这个问题,立刻加上了文件类型白名单校验、MIME类型检测、安全文件名生成和路径遍历防护。从那以后在审查清单里专门加了一条,所有文件操作相关的AI生成代码,必须检查路径遍历防护、类型校验、权限隔离这三个点。这种从问题到规范的闭环,是实战经验的积累。
团队规范的平衡艺术
推行安全规范最大的挑战不是技术问题,而是怎么让团队接受,既要保证安全又不能影响开发效率。我们的做法是把安全规则分级,核心模块高标准严要求,边缘功能适度放松。比如用户登录、支付订单、权限管理这些模块,AI生成的代码必须经过安全专家评审才能上线。但像日志格式化、数据模型转换这种工具方法,自动化扫描通过就可以合并。这种分级策略让团队感觉到安全管控是有弹性的,不是一刀切的阻碍。
另一个实用的技巧是建立安全代码模板库。把经过验证的安全代码片段整理成模板,遇到类似场景时直接复用。比如参数化查询的标准写法、JWT鉴权的完整流程、AES加密的安全配置,这些模板都经过安全团队审核,开发者可以放心使用。当AI生成的代码不符合安全要求时,直接参考模板库修改,既提高了效率又保证了安全。
在规范推广上,每个季度组织一次AI代码安全复盘会,把这个季度发现的所有AI生成代码的安全问题拿出来讨论,分析根因并更新检测规则。让团队成员分享自己踩过的坑和修复经验,这种peer learning比单纯的制度宣讲效果好得多。这样不仅懂技术,还理解怎么在团队里落地安全文化。
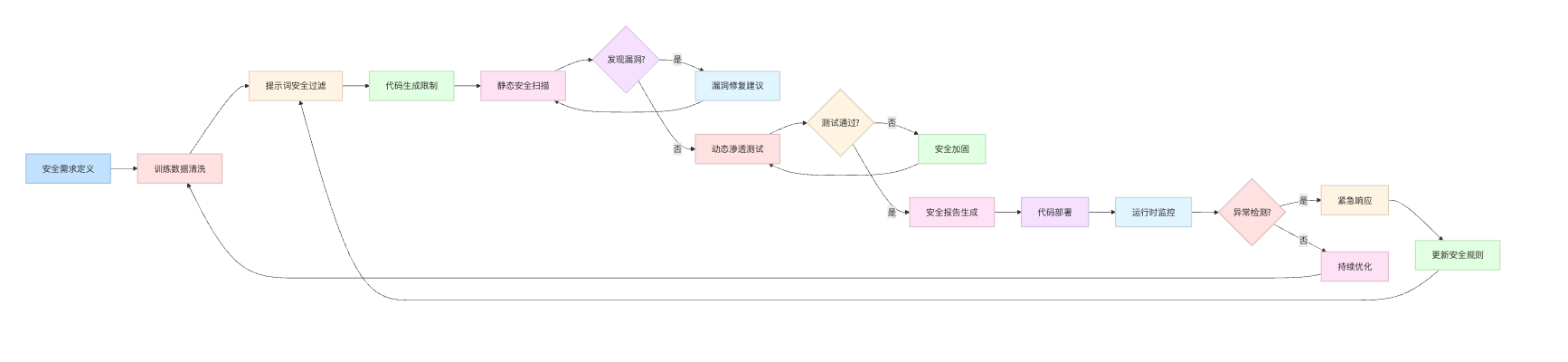
进阶思考
面试官真正想考察什么
面试官抛出这道题背后,其实是在判断你会不会成为那种盲目追逐新技术的工程师。2025年AI编程工具已经很普及了,但行业里确实出过不少因为滥用AI工具导致的安全事故,比如硬编码的密钥被提交到公开仓库、生成的权限校验逻辑存在绕过漏洞。面试官想看到的是你既能拥抱新工具提升效率,又能保持清醒头脑不把安全责任外包给AI。所以回答时传递的态度特别关键,要让面试官感觉到你是个谨慎的创新者而不是激进的冒险家。
典型的追问会围绕实战经验展开。面试官可能会问"你们团队真实遇到过哪些AI生成的安全问题",这个时候千万别说没遇到过,那会让面试官觉得你要么没实际用过要么缺乏安全敏感度。建议准备两三个真实踩过的坑,不用是惊天动地的大事故,日常开发里发现的小问题反而更真实。比如AI生成的数据校验逻辑只检查了非空但没验证格式,导致测试时发现可以输入特殊字符绕过业务规则。重点不是问题多严重,而是你怎么发现的、怎么修复的、后续采取了什么预防措施。
AI工具引入的新风险维度
面试官还可能会问"AI工具的安全风险和传统开发有什么不同",这是个很好的展现深度的机会。传统开发中安全问题主要来自开发者的知识盲区或粗心大意,但AI工具引入了新的风险维度。生成代码的不可预测性是第一个差异,同样的提示词在不同上下文下可能产生差异很大的代码,这种随机性增加了安全检测的难度。
上下文泄露风险是第二个新问题。开发者在给AI提供上下文时可能无意中包含了敏感信息,这些数据如果被工具收集就可能造成泄露。我们在实践中会严格规定,包含生产环境配置、客户数据、密钥信息的代码片段,绝对不能作为上下文输入给AI工具。
过度信任问题是第三个风险点。AI生成的代码看起来很专业,容易让开发者放松警惕直接采用,而传统开发中从StackOverflow复制代码时反而会更谨慎。点出这些差异能显示你对AI工具特性的深入理解,不是简单地把它当成代码生成器,而是理解它带来的新挑战。
工具选型的评估维度
另一个高频追问是"怎么评估和选型AI编程工具"。回答时可以从几个维度展开:首先看工具本身的安全能力,比如是否支持企业级部署、有没有代码审计功能、能不能配置安全策略。其次看生态集成度,能否和现有的SAST工具、IDE环境、CI/CD流程打通。还要考虑数据隐私保护,工具提供商会不会用你的代码片段做训练、敏感数据是否会离开本地环境。最后是厂商的安全响应能力,出现漏洞后修复速度怎么样、是否有专门的安全团队支持。把这些维度串起来讲,能体现你在技术选型时的全局思考。
从技术到文化的体系建设
如果想把回答拉到更高的层次,可以从技术、流程、文化三个维度谈安全体系建设。技术层面是工具和自动化能解决的,前面已经讲得很充分了。流程层面要强调把安全检查嵌入到开发的每个环节,而不是最后才补救,这需要在团队规范里明确AI生成代码的审查标准和责任划分。
文化层面最容易被忽视但其实最重要,要在团队里营造"安全是每个人的责任"的氛围,让大家理解AI工具只是辅助手段,生成的代码最终要为开发者自己负责。可以分享一些实践,比如定期组织AI代码安全案例分享会、把安全问题发现纳入绩效考核、对主动报告漏洞的同学给予正向激励。这种从技术到管理再到文化的完整思考,会让面试官觉得你具备带团队落地复杂变革的能力。
在创新和安全间找平衡
最后还能结合个人成长谈谈在创新和安全之间找平衡的思考。引入AI工具确实大幅提升了开发效率,但也确实经历过因为过度依赖导致的问题。关键是要建立一套渐进式的信任机制,初期对AI生成代码保持高度警惕严格审查,随着团队积累经验和完善检测规则,逐步扩大AI可以独立处理的场景范围。这种基于实践反馈的动态调整策略,既能享受新技术红利又能控制风险,是工程师成熟度的体现。面试官听到这种反思性的总结,会认为你不仅技术过硬,更具备在快速变化环境中持续学习和调整的能力。