精炼回答
知识工程和知识图谱是包含关系,知识工程是方法论和完整的工程体系,知识图谱是其核心产出物之一。知识工程关注如何从数据中提取、表示、组织和应用知识,而知识图谱本质上是用图结构存储的知识库。说得更直白点,你要构建一个智能问答系统,知识图谱只是那张存储实体和关系的网络,但知识工程要解决的是从需求分析到最终应用的全流程问题。
知识工程的完整流程包含六个核心阶段。首先是知识获取,从结构化数据库、文本、日志等各种源抽取知识,涉及实体识别、关系抽取、事件抽取等技术;然后是知识表示,把抽取的知识用本体、图谱、规则等形式建模;接着是知识融合,处理多源知识的实体对齐、冲突消解、质量评估;之后是知识存储,选择合适的图数据库或三元组存储;再往后是知识推理,基于已有知识推断隐含知识,补全缺失信息;最后是知识应用,把构建好的知识服务于搜索、推荐、问答等具体场景。整个流程是迭代的,应用中发现的问题会反馈到获取和融合环节持续优化。
扩展分析
两者关系的本质理解
面试时遇到这类"A和B有什么区别"的问题,最忌讳的就是东拉西扯。你需要在开场的30秒内让面试官感受到你思路清晰,用一个简洁的定位关系开头,然后快速勾勒出知识工程的轮廓。面试时可以直接说:"知识工程和知识图谱是包含关系,知识工程是一套完整的方法论和工程体系,知识图谱只是它的核心产出物。"这句话直接点明两者的层级关系,比分别解释定义要高效得多。
搞清楚知识工程这个概念的历史脉络,你才能给面试官展现出对领域的系统理解。知识工程最早出现在上世纪80年代专家系统的黄金时代,那时候的核心任务是把人类专家的经验规则编码到计算机系统里。你可以想象医生诊断疾病的过程:如果患者体温超过38度且咳嗽,那么可能是流感。这些if-then规则就是早期知识工程的主要成果。但那个年代的问题在于知识获取完全依赖人工访谈专家,成本高、更新慢,系统脆弱性极强。
到了2000年之后,特别是2012年Google正式提出Knowledge Graph概念,知识工程的重心发生了根本性转移。现在的知识工程更强调从大规模数据中自动化地提取和构建知识,知识图谱成为了知识表示的主流方案。这就是为什么很多人会混淆两者——因为在当前的技术语境下,知识图谱确实是知识工程最显性的产出。但你要明白,知识图谱只是承载知识的一种数据结构,它解决的是"用什么格式存储知识"的问题,而知识工程要回答的是"如何从零开始构建一个完整的知识智能系统"。
面试时可以用这样的类比来说明两者关系:"知识图谱和知识工程的关系,就像数据库和数据库系统开发的关系。数据库是存储数据的容器,但你要构建一个完整的业务系统,需要考虑需求分析、数据建模、ETL流程、查询优化、应用集成等全链路问题。"这个类比非常有效,因为任何有开发经验的面试官都能立刻理解这种层次差异。
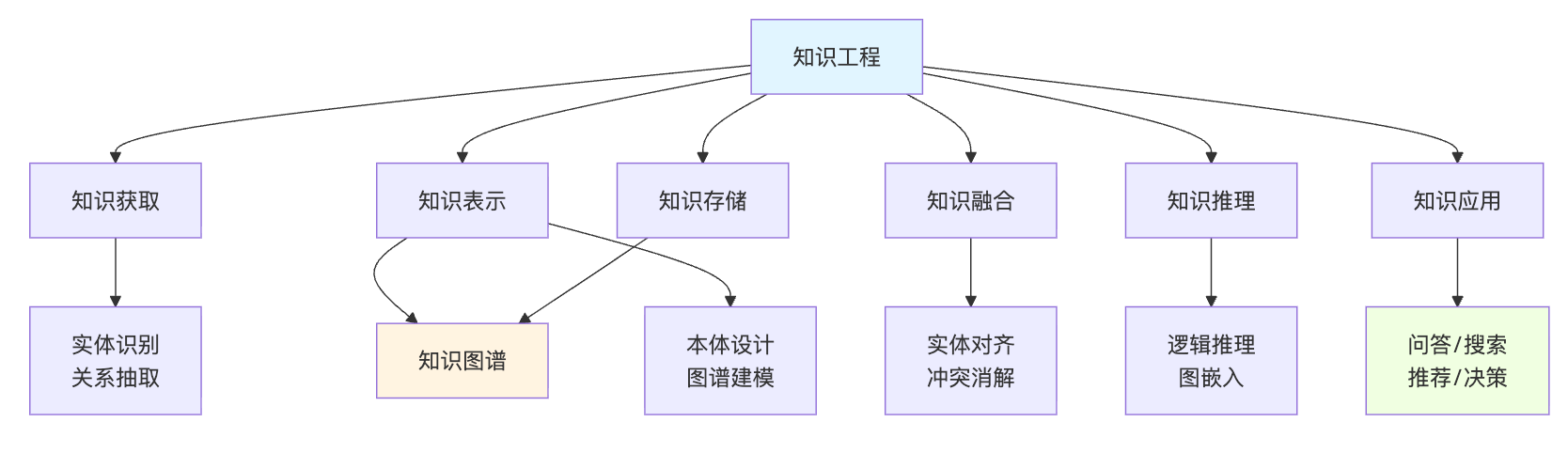
知识工程完整流程的深度剖析
接下来展开知识工程的完整流程时,关键是要把每个阶段的输入输出讲清楚,这样才能体现你的工程思维。知识获取阶段的输入是各种原始数据源,可能是结构化的数据库表,也可能是非结构化的新闻文本、用户评论、客服对话记录。这个阶段的核心任务是识别出实体和关系,输出的是带有语义标注的三元组候选集。比如从商品详情页提取出"iPhone 15-生产商-Apple"这样的结构化知识片段。这里的技术手段包括命名实体识别、关系抽取、事件抽取,如果遇到多模态数据还要做图像理解和视频分析。2025年的趋势是大模型在这个环节开始展现优势,用GPT-4或者Claude这类模型做few-shot学习,可以快速适配新领域的实体识别任务,不再需要大量标注数据。
知识表示阶段接收的是零散的三元组,要输出的是结构化的知识模型。这个阶段最容易被忽视但又极其重要,因为你需要设计本体(Ontology)来定义实体的类型层级和属性约束。拿电商场景举例,你要定义"商品"这个概念下面分为"实物商品"和"虚拟商品",实物商品有"重量"属性,虚拟商品有"有效期"属性。这些定义看起来简单,但直接决定了后续推理的能力边界。面试官如果追问这个环节,你可以提到OWL、RDF Schema这些标准,但更重要的是说明为什么要做本体设计——"本体就像代码里的类定义,它让知识具备了可复用和可扩展的能力"。
知识融合阶段处理的是多源知识的冲突问题。你从电商平台的商品库拿到的iPhone价格是5999元,从第三方价格监测网站拿到的是6199元,到底信哪个?这就需要实体对齐、属性融合、冲突消解的技术手段。实体对齐要解决"张三"和"张三丰"是不是同一个人的问题,冲突消解要根据数据源的可信度、时效性来决定采纳哪个值。实体对齐的难点在于不同数据源对同一实体的表述差异巨大,电商平台叫"Apple iPhone 15 Pro Max 256G 深空黑",用户评论里可能说"15PM黑色大杯"。这时候简单的字符串匹配完全不够用,要结合属性相似度、上下文语义、销量价格等多维特征做综合判断。更麻烦的是冲突消解,不同数据源的商品价格、库存、评分都可能不一致,你需要定义清楚优先级策略。
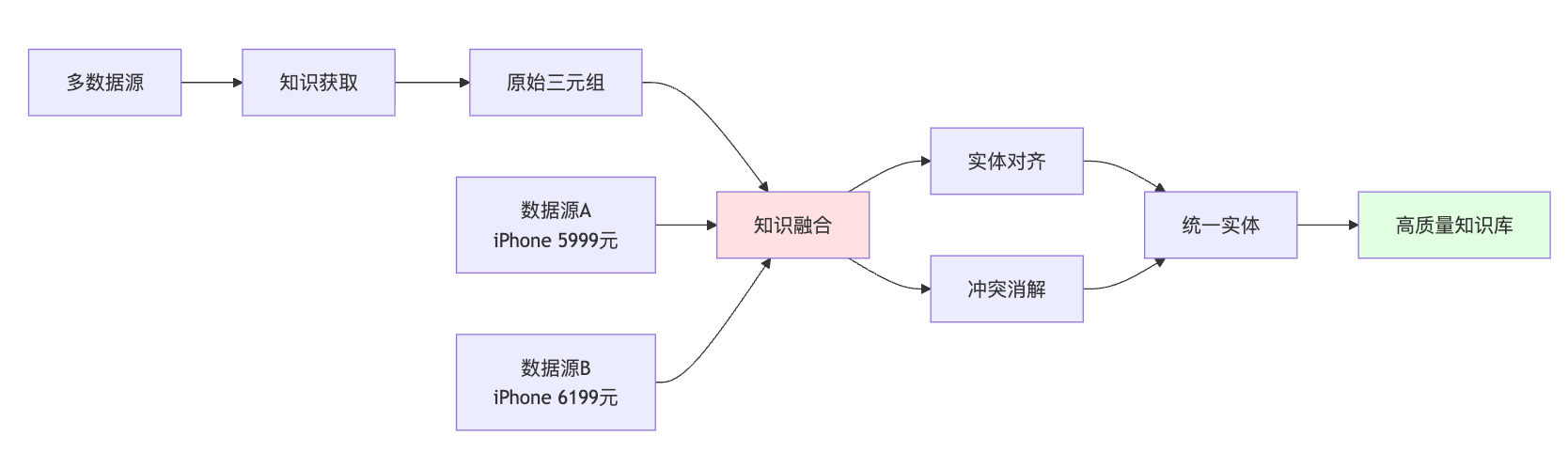
知识存储阶段相对好理解,就是选择合适的技术栈把知识持久化。图数据库像Neo4j、JanusGraph适合处理复杂关系查询,三元组存储像Jena、Virtuoso更符合语义Web标准。面试时不用纠结具体选哪个技术,重点是说明你理解不同存储方案的trade-off。比如图数据库查询性能好但数据导入慢,三元组存储标准化程度高但复杂查询需要写SPARQL语句,学习成本高。
知识推理阶段是让知识"活起来"的关键。你存储的是"苏格拉底是人"和"人都会死"这两条知识,通过推理可以得出"苏格拉底会死"这个新知识。这在实际应用中非常有价值,比如你的知识图谱里记录了"用户A购买过iPhone"和"iPhone属于高端手机",就可以推理出"用户A是高消费人群",这个标签可以用于精准营销。推理方法包括基于规则的逻辑推理、基于表示学习的知识图谱嵌入、基于神经网络的路径推理。2025年的热点是结合大模型做推理增强,把知识图谱作为外部知识库,让大模型在生成答案时进行事实校验和逻辑推理,这就是所谓的RAG(检索增强生成)架构的核心思路。
知识应用阶段是整个工程价值变现的环节。搜索场景可以用知识图谱做查询理解和结果排序优化,推荐场景可以基于实体关系做协同过滤,问答场景可以把自然语言问题转化为图谱查询。面试时重点强调这个阶段不是简单的数据查询,而是要把知识能力封装成API或者Agent的形式对外提供服务。比如构建一个商品导购Agent,它能理解用户说"我想要一部拍照好的手机",然后在知识图谱里检索"相机评分>90"的手机实体,结合用户画像做个性化推荐。这种把知识工程和Agent结合的思路非常契合2025年的技术趋势。
实践落地中的关键经验
面试中光讲理论框架是不够的,面试官更想听到的是你对知识工程实际落地的理解。假设要构建一个商品知识体系来支撑智能导购场景,首先在知识获取阶段会面临多源数据整合的问题。商品数据可能来自ERP系统的结构化表、用户评论的文本、商品图片的视觉特征,还有类目运营专家的经验知识。这时候要组合使用不同的获取方法,数据库的结构化信息直接映射成三元组,评论文本用NER和关系抽取模型处理,专家知识通过访谈整理成领域规则。这段描述的价值在于展示了对多源异构数据的处理能力,而不是停留在单一技术点上。
知识表示阶段的实践要点是本体设计的权衡。本体设计不是越复杂越好,要根据应用场景来决定粒度。如果只是做商品推荐,定义商品的类目层级和基本属性就够了;但如果要做智能问答,就需要细化到品牌、规格、适用人群这些维度,甚至要定义属性之间的约束关系,比如手机的屏幕尺寸和重量通常是正相关的。这种回答能体现你理解业务需求对技术方案的影响,这是高级工程师和初级工程师的分水岭。实际选择存储方案时也是类似的思路,图数据库查询灵活适合探索式分析,但如果你的应用场景主要是确定性的路径查询,向量嵌入配合ANN检索反而性能更好。
知识质量评估是很多候选人会忽略的点,但这恰恰是工程化成熟度的体现。知识图谱构建完不是结束,还要建立质量监控体系。关键指标包括覆盖率,看核心实体和关系的完整程度;准确率,抽样验证三元组的正确性;一致性,检查同一实体的属性是否冲突;时效性,监控知识的更新频率。具体方法可以分自动化和人工两类,自动化可以用规则检查明显错误,比如商品价格是负数、发布时间在未来;人工验证则要设计抽样策略,重点关注高频查询的实体和新增的知识。面试时提到这些细节,能让面试官感受到你对工程质量的重视。
知识应用阶段要结合2025年的技术趋势来讲。现在最热的方向是把知识图谱和大模型结合,构建RAG架构的智能应用。传统的问答系统把自然语言转成结构化查询,但这种方式理解能力有限。现在更好的做法是让大模型先理解用户意图,然后从知识图谱检索相关实体和关系,再让大模型基于检索结果生成答案。这样既利用了大模型的语言理解能力,又通过知识图谱保证了事实准确性。比如用户问"有没有续航好的轻薄本推荐",大模型解析出关键需求是笔记本电脑、续航时长、重量,然后在知识图谱里查询满足"电池容量>70Wh且重量<1.5kg"的实体,最后结合用户画像和实时价格生成个性化推荐。
知识工程项目最大的坑是范围控制,很多团队一开始就想构建覆盖所有业务的通用知识图谱,结果投入巨大但迟迟看不到效果。更好的做法是先选一个高价值的垂直场景做MVP,快速验证效果后再逐步扩展。另一个常见问题是数据质量和覆盖度的矛盾,追求高质量就要人工审核,但这会导致知识更新跟不上业务变化。实践中要分层处理,核心知识走严格的审核流程,长尾知识允许自动化获取但标注置信度,应用时根据场景选择合适的质量阈值。
面试中的高阶思考
面试官通过这道题真正想考察的不是你能不能背出知识工程的定义,而是你有没有系统工程思维。大厂招人最看重的就是这个——能不能把一个复杂问题拆解成可落地的方案,能不能理解技术选型背后的权衡逻辑。当你回答完知识工程的六个阶段,面试官大概率会追问知识工程和机器学习的关系。很多人会陷入"谁更重要"的比较陷阱,但面试官真正想听的是你对知识驱动和数据驱动融合趋势的理解。
机器学习是从数据中学习模式的方法,知识工程是显式构建知识体系的过程,两者不是替代关系而是互补的。现在最有效的AI系统都在结合两者的优势,用机器学习做知识获取和推理增强,用知识工程保证系统的可解释性和稳定性。比如大模型在做推理任务时容易产生幻觉,这时候外挂一个知识图谱做事实校验就是典型的融合方案。模型负责理解语义和生成流畅的回答,知识图谱保证事实的准确性,这就是RAG架构的核心思路。
另一个高频追问是如何评估知识工程项目的ROI。这个问题最能看出候选人有没有业务sense,因为很多技术人只会埋头做技术,不关心投入产出比。知识工程项目的ROI评估要分短期和长期两个维度。短期看业务指标的直接提升,比如问答系统的准确率从60%提升到85%,客服人工介入率下降30%,这些都是可量化的收益。更重要的是长期的复用价值,知识体系建立后可以支撑多个业务场景,边际成本会越来越低。评估时要把知识资产的复用性考虑进去,不能只看单一项目的投入产出。投入成本包括人力成本、数据标注成本、存储和计算资源,关键是展现你对成本结构的清晰认知。
回答这道题时要展现的最后一个维度是技术视野。2025年知识工程最大的变化就是和大模型、Agent的深度融合。现在看知识工程不能停留在传统的图谱构建上,更重要的是怎么让知识真正驱动智能体的决策。比如多智能体协作场景,每个Agent需要访问共享的知识库来理解任务上下文,这对知识的组织和检索效率提出了更高要求。或者提到MCP协议让知识源可以标准化接入各种AI应用,这种趋势意味着知识工程要更关注接口设计和服务化能力。这些表述能让面试官看到你不是活在过去的技术里,而是持续关注行业前沿,这正是大厂最看重的学习能力和技术敏感度。