精炼回答
NLG在对话系统中负责将系统意图转换为自然语言回复,扮演的是"最后一公里"的角色——系统已经理解了用户意图,也决定了要做什么回应,NLG负责把这个回应用自然、合适的语言表达出来。
业界主要有三种实现路径,它们其实是工程上在准确性、成本、灵活性三个维度的不同取舍。模板方法是预定义固定句式,用槽位填充变量,比如"您的订单{order_id}已发货"。优点是响应快、可控性强、不会出错,适合客服、通知类场景;缺点是表达僵化、难以应对复杂语境,维护成本随着模板数量增长而升高。
检索方法从候选回复库中匹配最合适的回复,通常基于语义相似度计算。它的优点是回复质量有保证(都是人工编写的)、表达自然流畅;缺点是覆盖面受限于语料库规模,遇到新场景就无法应答,且需要持续扩充维护语料库。很多FAQ机器人就是这个原理。
生成方法使用神经网络端到端生成回复,典型的就是GPT这类模型。优点是灵活性最强、可以处理开放域对话、表达多样性好;缺点是可控性差,容易产生事实性错误或不合适内容,推理成本高,在需要严格准确性的场景(如金融、医疗)风险较大。
实际工程中常采用混合策略:关键业务流程用模板保证准确性,常见问题用检索提升体验,开放闲聊用生成增加灵活性。选择哪种方式核心看场景对准确性、多样性、成本的权衡。
扩展分析
NLG在对话系统中的位置和三种方法的本质
要真正理解NLG的选型逻辑,首先要明确它在整个对话系统中的位置。一个完整的对话系统通常包含NLU(理解用户说什么)、DST(跟踪对话状态)、Policy(决策做什么)、NLG(生成回复)这几个模块。NLG接收到的输入通常是结构化的意图表示,比如一个JSON对象包含了动作类型、槽位信息、上下文状态等,它的任务是把这个冷冰冰的数据结构转换成让用户感觉舒服的自然语言。这个转换过程看似简单,实际上涉及语言的流畅性、礼貌性、个性化等多个维度。
模板方法的核心思想很简单,就是预先写好句式,运行时填变量。但工程实现远不止字符串替换这么简单。模板方法最大的优势是可控性,在金融或医疗这种对准确性要求极高的场景,你不能让AI自由发挥。比如银行APP告知用户账户余额,必须用"您的账户余额为XXX元"这种固定表达,不能生成"你还剩XXX块钱哦"这种随意的话。模板方法能保证每次输出都符合业务规范和法律要求。
更进阶的做法是支持条件逻辑。真实场景下会涉及单复数、性别、礼貌程度等变化,工程上通常会扩展模板引擎,支持类似{items|count:件商品}这种表达,根据items数量自动选择合适的量词。有些团队会用FreeMarker或Velocity这类成熟模板引擎。当模板数量超过几百条,维护确实成问题,业界通常的做法是建立模板管理平台,支持非技术人员通过UI配置模板,同时做好分类标签、版本管理、灰度发布。更重要的是建立触发条件的配置机制,用规则引擎决定什么情况下使用哪个模板。
检索方法本质上是信息检索问题。它预先准备一个回复库,每条回复可能对应一些关键词、语义向量或者问题模板。用户输入进来后,计算它和库中每条候选的相似度,返回得分最高的那条。关键是要说清楚"相似度"怎么算。早期简单的做法是关键词匹配,但现在更常见的是语义匹配。比如用户问"怎么退货"和"不想要了能退吗",关键词完全不同,但语义相似。现在主流做法是用预训练模型(比如Sentence-BERT)把问题和回复都编码成向量,在向量空间里计算余弦相似度。
FAQ场景特别适合检索,因为用户的常见问题就那么几百个,把答案提前写好、人工审核过,保证质量。而且这些回复可以包含图片、链接等富媒体内容,比生成方法灵活。但检索方法最大的问题是覆盖率,回复库里有的问题能答好,没有的就彻底答不了。而且用户换个说法,相似度计算可能就匹配不上。为了提高覆盖率,运营团队需要不断收集新问题、扩充语料库,这个人工成本不低。
生成方法经历了三个技术阶段。最早是基于Seq2Seq的端到端生成,用LSTM编码器-解码器结构,把输入序列映射到输出序列,但这种方法的问题是生成的回复容易陷入"我不知道"、"哈哈"这种安全但无意义的回复。
第二阶段是引入Attention机制和Transformer,让模型能关注输入的关键信息,出现了GPT、BART这些预训练模型,在大规模语料上学习语言模式,再在对话数据上微调,生成质量有明显提升,但仍然存在事实性错误和一致性问题。
现在是大模型时代,ChatGPT这类模型通过指令微调和RLHF(人类反馈强化学习),让生成的回复更符合人类偏好,优势是真正实现了开放域对话,可以聊任何话题,而且回复连贯自然。

但大模型虽然效果好,实际应用要考虑几个问题。成本方面,每次调用都要消耗GPU资源,高并发场景下费用不低;延迟方面,生成一个回复可能要几秒钟,用户等不了;可控性方面,模型可能生成不合适的内容,需要加安全审核层。这些都是工程落地时必须面对的真实挑战。
场景选型和系统思维
选择哪种NLG方法或者怎么组合,核心看业务的容错度和成本预算。如果让你设计一个客服对话系统的NLG模块,第一步不是比较技术优劣,而是问清楚业务的核心诉求:对话的核心场景是什么,是售后服务还是售前咨询?准确性要求有多高,能不能容忍偶尔出错?预算和响应时间的约束是什么?
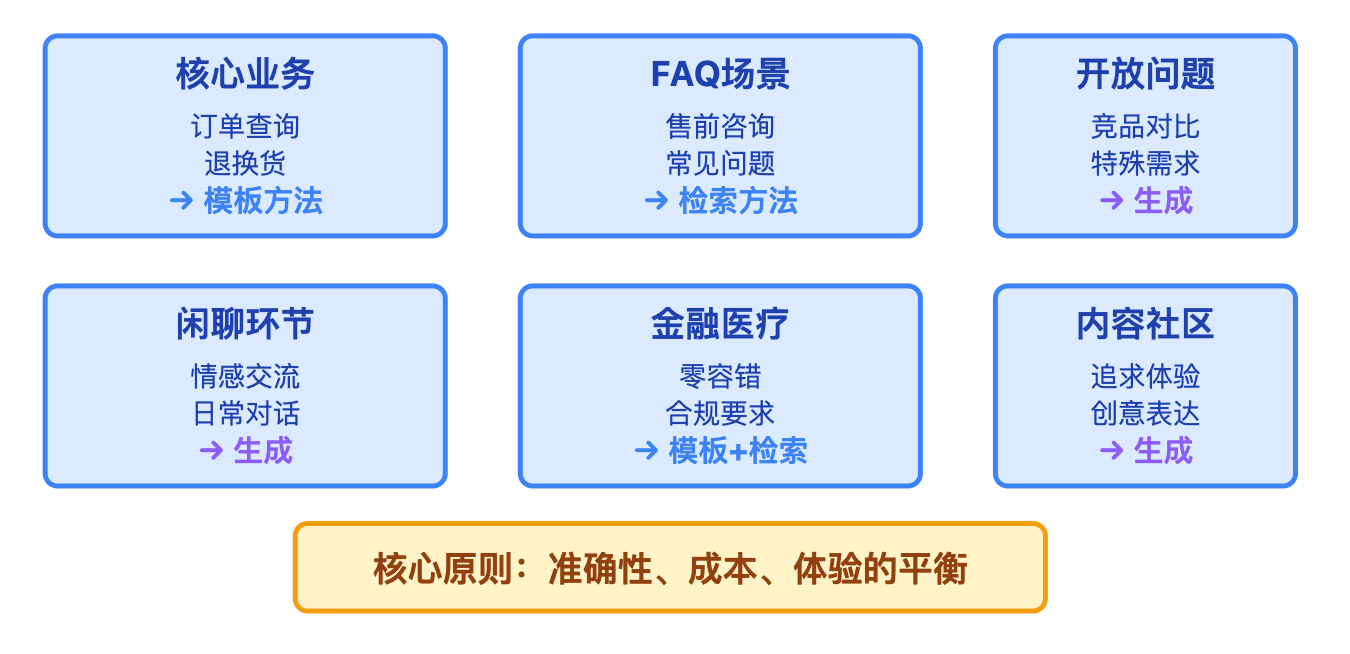
如果是订单查询、退换货申请这种核心业务流程,毫不犹豫选模板方法,因为这些场景的槽位是固定的,准确性是第一要务。物流状态只有"已揽收"、"运输中"、"派送中"几种,直接映射到对应话术就行,模板虽然表达单调,但用户看到的是准确信息,体验不会差。
如果是售前咨询或者FAQ场景,用户会问各种问题,模板覆盖不了,这时候检索方法就很合适,提前准备几百条高质量的问答对,用语义匹配找最相关的。检索的好处是回复都是运营团队写好的,符合品牌调性,还能带上产品链接、优惠券这些营销元素。
生成模型要放在兜底和增强体验的位置。当用户的问题既不在核心流程里,也不在FAQ库里,比如问"你们家和竞品比有什么优势",这种开放性问题就需要生成模型来应对。或者在闲聊环节,用户说"今天心情不好",生成模型能给出更自然的安慰回复,提升情感连接。但生成的内容必须经过安全审核,避免出现不合适的表达。
NLG只是对话系统的最后一环,但它的质量其实受前面所有环节的影响。如果NLU意图识别就错了,再好的NLG也无济于事。从系统思维的角度,技术选型不是拍脑袋,而是基于具体约束条件的权衡。理解这个问题的真实意图是考察技术选型能力、工程判断力和业务理解,面试官更想看到的是你能从业务目标倒推技术方案,展示的不仅是技术细节,更重要的是让面试官相信你能在实际项目中做出正确的判断。