精炼回答
多语言知识库构建的核心是建立统一的知识表示层,让不同语言的实体和关系映射到相同的语义空间。具体做法是先构建各语言的独立知识图谱,然后通过跨语言对齐把它们连接起来。
跨语言对齐主要解决实体对齐和关系对齐两个问题。实体对齐可以采用基于翻译的方法,比如将英文实体名翻译成中文再匹配,或者使用多语言嵌入模型如XLM-R、mBERT将不同语言的实体编码到统一向量空间,通过余弦相似度找对应关系。更精确的做法是训练跨语言实体链接模型,利用维基百科、DBpedia等已有的跨语言链接作为监督信号。
关系对齐相对复杂,因为不同语言对同一关系的表达差异很大。常见做法是定义统一的关系模式(schema),各语言的关系表达都映射到这套标准模式上,或者用关系嵌入学习让语义相同的关系在向量空间中接近。实际应用中,Google的Knowledge Graph就是通过爬取多语言维基百科,用Wikidata的QID作为全局实体标识符来实现对齐的。你也可以借助现有的跨语言资源如BabelNet、MUSE词典来辅助对齐,结合主动学习不断修正错误对齐,逐步提升知识库的跨语言一致性。
扩展分析
构建流程与核心思路
多语言知识库本质上是让不同语言的用户都能访问同一份知识,但看到的是各自语言的表达。它的核心价值在于打破语言壁垒,让知识在全球范围内流通。比如搜索引擎里,用户用中文搜"苹果公司"和用英文搜"Apple Inc.",背后访问的应该是同一个知识实体。这种统一的语义理解直接影响到跨境业务的用户体验。
整个构建过程其实是个从分散到统一的过程。首先各语言独立建图,把中文的知识图谱、英文的知识图谱先分别构建出来,这个阶段重点是保证单语言内部的质量。接着做跨语言映射,通过对齐技术把不同语言中指向同一事物的节点连接起来。最后是持续校准,因为语言在演化,新的表达方式不断出现,需要机制来保持对齐关系的时效性。
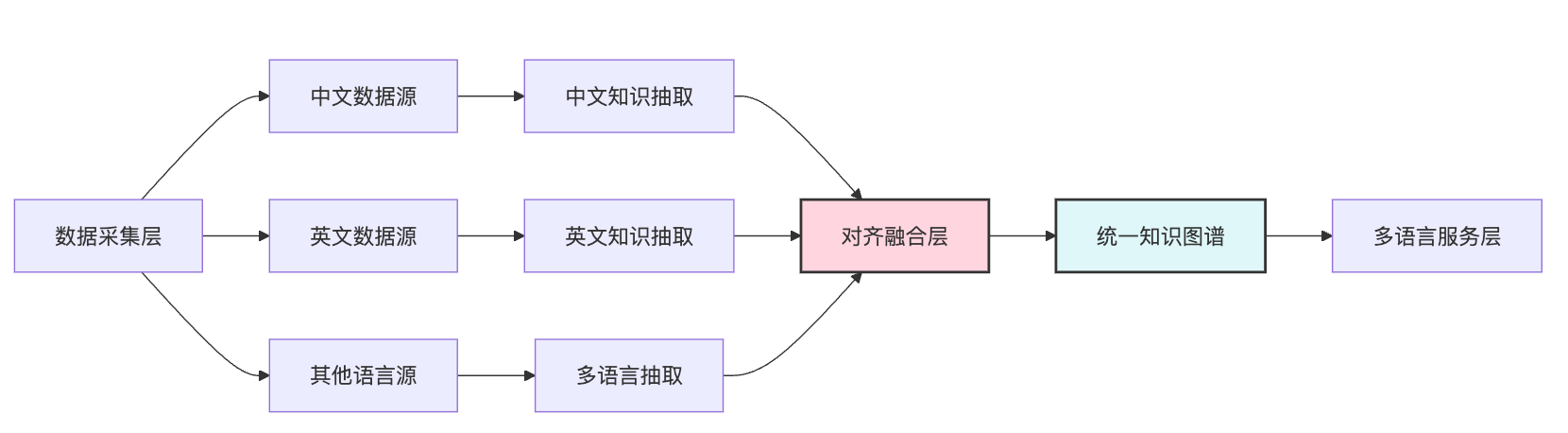
多语言知识库的架构是个分层设计。最底层是数据采集层,从不同语言的数据源拉取原始数据,这里要处理的核心问题是各语言数据质量参差不齐。往上是知识抽取层,针对每种语言独立构建NER、关系抽取等处理管道。再往上是对齐融合层,这是整个系统的关键,负责把不同语言抽取出的知识图谱连接起来。最顶层是统一服务层,对外提供多语言查询和推理能力。这个架构的核心设计原则是先保证单语言质量,再做跨语言融合。很多团队容易犯的错误是一开始就做多语言混合处理,结果每种语言都做不好。更明智的策略是用最适合该语言的模型和工具先把质量做扎实,比如中文用专门针对中文优化的BERT模型做实体识别,德语用针对德语语法特点设计的依存句法分析器。等单语言图谱质量稳定后再做对齐,错误传播就会少很多。
多语言抽取最大的挑战是不同语言的语言学特性差异巨大。拿实体识别来说,英语有明显的大小写特征,首字母大写的词很可能是实体,但中文没有这个特征,完全依赖上下文语义。德语的复合词特别多,"Lebensversicherungsgesellschaft"(人寿保险公司)是一个词但包含多个语义成分,切分不好就会漏掉实体。阿拉伯语是从右往左书写,分词逻辑也完全不同。应对策略是为每种语言定制预处理管道。高资源语言比如英语、中文,可以用XLM-RoBERTa这种大规模多语言预训练模型,在各自语言的标注数据上微调,效果能接近单语言模型。中等资源语言比如土耳其语、越南语,可以用迁移学习,先在高资源语言上训练好模型,再用少量目标语言数据适配。低资源语言比如斯瓦希里语,甚至可以考虑用跨语言投影方法,把英语的标注数据通过翻译对齐投影到目标语言上。
from transformers import AutoTokenizer, AutoModelForTokenClassification
classMultilingualEntityExtractor:
def__init__(self, language):
self.language = language
# 根据语言选择最佳模型
self.model_map ={
'zh':'hfl/chinese-roberta-wwm-ext',
'en':'dslim/bert-base-NER',
'de':'gbert-base-germanner',
'default':'xlm-roberta-large'
}
model_name = self.model_map.get(language, self.model_map['default'])
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForTokenClassification.from_pretrained(model_name)
defextract_entities(self, text):
# 针对不同语言做预处理
if self.language =='de':
text = self._split_compound_words(text)
tokens = self.tokenizer(text, return_tensors="pt")
outputs = self.model(**tokens)
entities = self._parse_entity_labels(outputs, tokens)
return entities这个设计的关键是model_map这个策略映射,不同语言用不同的专用模型,这比一刀切用通用多语言模型效果好。德语还专门做了复合词切分的预处理,这些细节处理会让准确率提升5-10个百分点。
跨语言对齐的本质就是在不同语言的语义空间之间建立映射关系,让语义相同的实体和关系找到彼此。对齐技术其实经历了三代演进,每一代都在解决上一代的痛点。最早的做法很直接,把英文实体名翻译成中文,然后做字符串匹配。比如"Apple Inc."翻译成"苹果公司",然后在中文知识库里找这个字符串。这种方法的优点是简单直观,不需要训练模型,特别适合冷启动。但缺陷也明显,翻译的多样性很难处理,"Apple Inc."可能被翻译成"苹果公司"、"苹果股份有限公司"、"美国苹果公司",字符串匹配很容易漏掉。而且翻译错误会直接导致对齐错误,比如"银行"这个词翻译成英文可能是"bank"也可能是"river bank",歧义很大。
2018年前后多语言预训练模型出现后,对齐方法发生了质的变化。像mBERT、XLM-R这些模型在100多种语言的大规模语料上预训练,学会了把不同语言的相同语义映射到接近的向量空间。这时候对齐就变成了向量相似度计算问题。这种方法的优势是能捕捉语义相似性,即使表述不完全一样也能对齐上。"iPhone 15 Pro"和"iPhone 15专业版"虽然字面不同,向量空间里距离很近就能对齐。
from sentence_transformers import SentenceTransformer
import numpy as np
classCrossLingualAligner:
def__init__(self):
# 使用多语言句子编码模型
self.encoder = SentenceTransformer('paraphrase-multilingual-mpnet-base-v2')
defalign_entities(self, entities_lang1, entities_lang2, threshold=0.85):
# 编码所有实体
embeddings_1 = self.encoder.encode([e['name']for e in entities_lang1])
embeddings_2 = self.encoder.encode([e['name']for e in entities_lang2])
alignments =[]
# 计算余弦相似度矩阵
similarity_matrix = np.dot(embeddings_1, embeddings_2.T)
for i, scores inenumerate(similarity_matrix):
best_match_idx = np.argmax(scores)
if scores[best_match_idx]> threshold:
alignments.append({
'entity1': entities_lang1[i],
'entity2': entities_lang2[best_match_idx],
'confidence':float(scores[best_match_idx])
})
return alignments这个threshold阈值很关键,设太低会有很多误匹配,设太高会漏掉正确对齐,实际生产中需要在验证集上调优。纯靠语义相似度还不够,因为有些实体名字很相似但实际是不同的东西,比如"迈克尔·乔丹"(篮球运动员)和"迈克尔·乔丹"(机器学习教授)。这时候要利用知识图谱的结构信息,看它们的关系和邻居节点。如果一个实体的邻居包含"芝加哥公牛队"、"NBA总冠军",另一个实体的邻居是"加州大学伯克利分校"、"机器学习论文",显然不是同一个人。
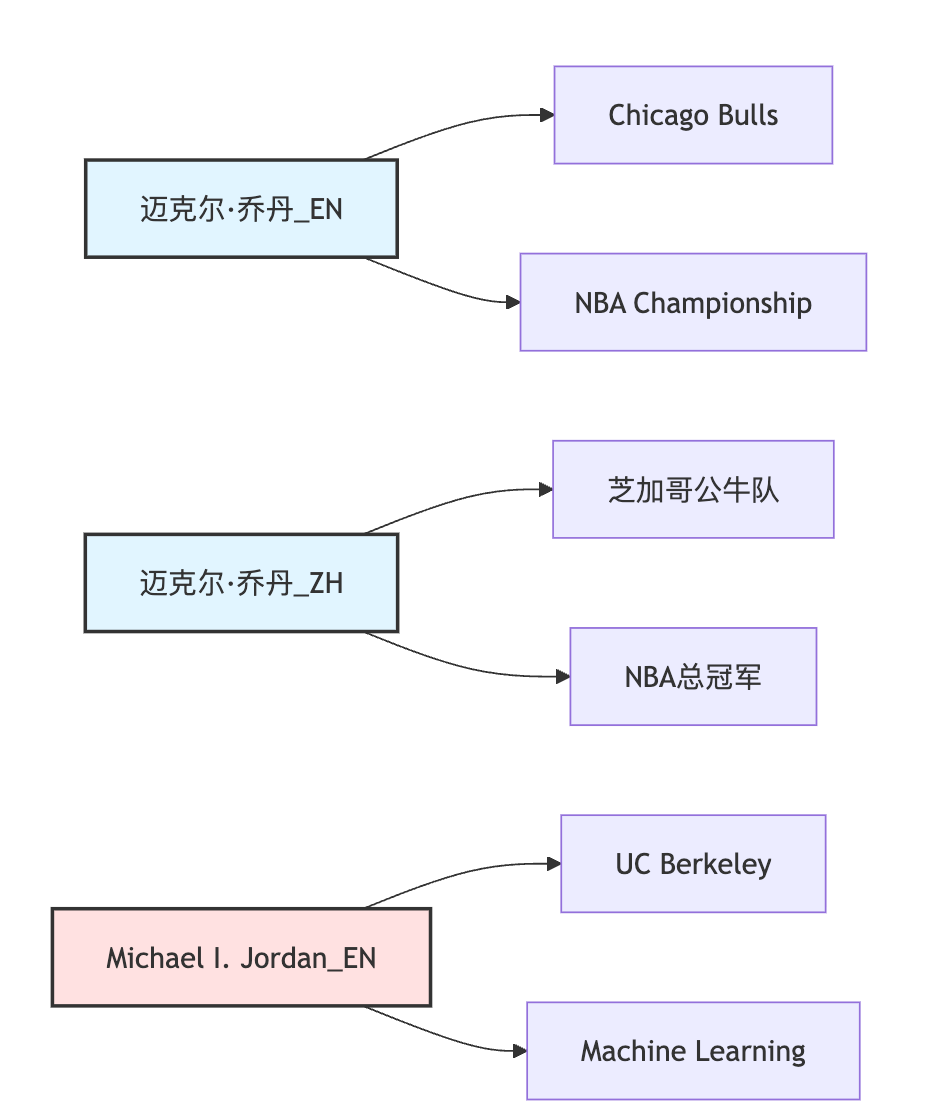
基于结构的对齐会计算两个候选实体的邻居节点相似度,如果A的邻居和D的邻居高度对齐,A和D对齐的置信度就高。反过来G的邻居跟A和D都不像,即使名字相同也不该对齐。这种方法在实体消歧上特别有效。
实体对齐和关系对齐的难度其实不在一个量级。实体对齐相对简单,因为实体名称本身包含大量信息,"埃菲尔铁塔"和"Eiffel Tower"即使语言不同,语义指向是明确的。但关系对齐难多了,因为不同语言对同一关系的表达方式差异巨大,甚至关系的粒度都不一样。英文里可能用"founded by"表示创立关系,中文里可能是"创立者"、"创始人"、"由...创办"等多种表达。更复杂的是,有些语言会把一个关系拆成多个,比如英语里"married to"是一个关系,但在某些文化的语言里可能会区分"第一次婚姻"、"第二次婚姻"这种更细粒度的关系。还有些语言对方向性的表达不同,中文的"属于"和英文的"belongs to"方向是相反的。
实际做的时候有两种思路。一种是预定义统一的关系本体(ontology),比如定义100个标准关系类型,各语言抽取出的关系都映射到这100个类型上。这种方法的好处是关系对齐变成了分类问题,坏处是表达能力受限,有些语言特有的微妙关系表达不出来。另一种是用关系嵌入学习,让语义相同的关系在向量空间接近,比如"founded by"和"创始人"应该编码到相近的位置。这种方法更灵活,但需要大量的跨语言关系对应数据来训练。
工程落地与性能优化
面对实际落地场景,技术选型最关键的是看团队现状和业务规模。如果团队规模小、需要快速验证,优先选择开箱即用的方案。比如直接用Hugging Face上预训练好的多语言模型,像sentence-transformers库里的paraphrase-multilingual-mpnet-base-v2,五行代码就能实现跨语言实体对齐,虽然精度可能不是最优但能快速出结果。但如果业务规模大,每天要处理千万级实体对齐,这时候就得考虑自己训练模型了。预训练模型虽然通用性好,但在特定领域效果不一定最优。拿金融领域举例,公司名称、金融产品的跨语言对齐有很多专业术语,通用模型可能对不准。这时候用领域数据在XLM-R基础上继续预训练,再在标注好的对齐数据上微调,准确率能提升10-15个百分点。
一个判断标准是,如果候选实体池小于10万,直接用预训练模型暴力计算相似度就够了;超过百万级别,就得考虑索引优化,用FAISS这种向量检索库建索引,把检索时间从几小时降到几分钟。再往上到亿级规模,可能需要分布式图计算框架,这时候就得上Neo4j或者自己基于Spark实现分布式对齐算法。
多语言数据预处理比单语言复杂得多,因为不同语言的脏数据表现形式完全不同。中文数据常见的问题是半角全角混用,"iPhone15"和"iPhone15"看起来一样但编码不同,不统一的话对齐就会漏掉。英文数据容易有大小写不一致的问题,"apple inc."和"Apple Inc."应该指向同一实体,但字面匹配会认为是不同的。预处理通常会分几步走,首先是字符标准化,把所有全角字符转半角,统一大小写处理策略。注意这里不能无脑全部转小写,有些缩写词转小写后会丢失信息,比如"WHO"(世界卫生组织)转小写变成"who"就有歧义了。接着是去噪,清理HTML标签、特殊符号、多余空格,这些在网页爬取的数据里特别常见。然后是语言检测,因为有些数据源标注的语言不准确,文本说是中文但里面夹杂大量英文,需要自动检测纠正。
import unicodedata
from langdetect import detect
classMultilingualPreprocessor:
defnormalize_text(self, text, language):
# 全角转半角
text = unicodedata.normalize('NFKC', text)
# 语言特定处理
if language =='zh':
text = self._remove_chinese_punctuation(text)
elif language =='en':
text = self._normalize_english_case(text)
elif language =='de':
text = self._handle_german_umlauts(text)
return text.strip()
def_remove_chinese_punctuation(self, text):
# 处理中文标点的多种变体
punctuation_map ={',':',','。':'.',';':';',':':':'}
for old, new in punctuation_map.items():
text = text.replace(old, new)
return text这个normalize_text方法的核心是分语言处理。NFKC归一化能解决全角半角问题,但不同语言还有各自的特殊性。中文要处理标点符号的多种变体,英文要处理首字母大写的实体识别特征,德语要处理变音字母ä、ö、ü的标准化。这些细节处理看起来琐碎,但直接影响对齐准确率。
大规模对齐的性能瓶颈是计算量爆炸。假设中文库有100万实体,英文库有200万实体,两两计算相似度需要2万亿次计算,即使用GPU也要跑好几天。优化思路分几个层次。首先是减少候选集,不是所有实体都需要跨语言对齐,有些实体天然就是单语言的,比如中国的地方美食"煎饼果子"大概率不需要对齐到英文实体。可以先做一个粗筛,用实体类型、领域标签过滤掉明显不需要对齐的部分,把候选集降到原来的30%左右。接着用分块策略,把实体按首字母或者类型分成多个块,只在可能相关的块之间计算相似度。比如人名实体只跟人名实体对齐,组织名只跟组织名对齐,这样又能减少70%的计算量。
classBlockedAligner:
def__init__(self):
self.entity_blocks ={}
defbuild_blocks(self, entities):
for entity in entities:
block_key = self._get_block_key(entity)
if block_key notin self.entity_blocks:
self.entity_blocks[block_key]=[]
self.entity_blocks[block_key].append(entity)
def_get_block_key(self, entity):
# 根据实体类型和首字母生成块键
entity_type = entity.get('type','UNKNOWN')
first_char = entity['name'][0].upper()
returnf"{entity_type}_{first_char}"这个分块策略的好处是可以并行处理,每个块独立计算互不影响,在分布式环境里能线性扩展。再进一步用近似最近邻搜索替代精确计算,FAISS库提供的HNSW索引,能在百万级向量里做最近邻搜索,速度比暴力计算快几百倍,召回率还能保持在95%以上。
import faiss
classFAISSAligner:
def__init__(self, dimension):
self.index = faiss.IndexHNSWFlat(dimension,32)
defadd_entities(self, embeddings):
self.index.add(embeddings.astype('float32'))
defsearch_similar(self, query_embeddings, k=5):
distances, indices = self.index.search(
query_embeddings.astype('float32'), k
)
return distances, indices这种方法特别适合在线对齐场景,新来一个实体需要实时找对齐关系,用FAISS几毫秒就能返回结果。
用XLM-R这类多语言模型有个常见误区,以为一个模型能解决所有语言问题。实际上它对不同语言的支持程度差异很大,对英语、中文这种高资源语言效果好,对泰语、越南语这种中等资源语言效果就明显下降,对一些低资源语言甚至还不如用翻译到英语再处理的效果。实战中的做法是分语言评估模型效果,在各自语言的验证集上测试准确率。如果某个语言效果特别差,就单独给它配一个专用模型。比如日语用专门的日语BERT,阿拉伯语用AraBERT,虽然增加了维护成本但准确率提升明显。架构上可以设计成模型路由器,根据输入语言自动选择最合适的模型。多语言模型的tokenizer处理不同语言时效率差异也很大。中文的tokenize效率通常比英文低很多,因为中文词边界不明显,tokenizer需要更多计算。实际部署时要注意batch处理,把同语言的文本放在一起处理,比混合语言batch快30%左右。
多语言知识融合最棘手的不是技术实现,而是冲突解决。不同语言的数据源可能对同一个事实有不同的描述,比如英文维基说某个CEO的任职时间是2020年,中文维基说是2019年,到底信谁?冲突类型可以分几种,最常见的是属性值冲突,比如人物的出生日期、公司的员工数量在不同语言来源里不一致。还有结构冲突,比如中文图谱里A的父节点是B,英文图谱里A的父节点是C。更隐蔽的是语义冲突,同一个概念在不同文化背景下的外延不同,比如"家庭"这个概念在不同文化里包含的成员范围不一样。
生产环境里通常采用置信度加权的方式。给每个数据源打个信任度分数,比如官方网站的可信度高于用户生成内容,近期更新的数据可信度高于陈旧数据。当出现冲突时,综合考虑数据源可信度、数据新鲜度、多源验证一致性来决定采用哪个值。如果冲突无法自动解决,可以保留多个版本并标注来源,让下游应用根据场景选择。
classConflictResolver:
defresolve_attribute_conflict(self, attribute_name, values_with_sources):
"""
解决属性值冲突
values_with_sources: [{'value': 2020, 'source': 'en-wiki', 'timestamp': '2024-01'}, ...]
"""
# 数据源权重
source_weights ={
'official':1.0,
'en-wiki':0.85,
'zh-wiki':0.85,
'user-generated':0.5
}
scored_values =[]
for item in values_with_sources:
score = source_weights.get(item['source'],0.5)
# 数据新鲜度加权
freshness_bonus = self._calculate_freshness(item['timestamp'])
# 多源一致性加权
consistency_bonus = self._check_consistency(item['value'], values_with_sources)
final_score = score *(1+ freshness_bonus + consistency_bonus)
scored_values.append({'value': item['value'],'score': final_score})
# 返回得分最高的值
returnmax(scored_values, key=lambda x: x['score'])['value']知识库不是一次性构建完就不变了,每天都有新实体产生、旧实体信息更新,对齐关系也需要动态维护。全量重跑对齐太慢,成本也高,需要设计增量对齐机制。对于新增实体,可以用FAISS索引做实时对齐。新实体来了,先编码成向量,然后在已有索引里搜索最相似的候选,如果相似度超过阈值就建立对齐关系。对于实体属性更新,比如某个人的职位变了,需要检查是否影响已有的对齐关系。如果变化很大,可能需要重新评估对齐的置信度。增量更新的关键是维护索引的一致性,每次添加新对齐关系,要同步更新多个索引结构,包括实体名称索引、向量索引、图结构索引。如果某个环节失败了,要有回滚机制保证数据一致性。
业务价值与进阶思考
跨境电商就是个特别典型的应用场景。同一个商品在不同站点有不同语言的标题和描述,但背后应该关联到同一个商品知识实体。当用户在德国站搜索"iPhone 15 Pro",系统能关联到英文站的评价数据和中文站的库存信息,这种跨语言的知识整合直接影响到用户体验和转化率。多语言知识库上线前后,可以对比同一个内容在不同语言用户群体里的点击率变化。如果对齐质量高,一篇关于"iPhone 15 Pro"的英文评测文章,应该能被搜索"iPhone 15 Pro评测"的中文用户发现,这时候跨语言内容消费占比就是个很好的业务指标。
文化差异导致的概念不对齐是个容易被忽略但影响深远的问题。文化差异导致的概念偏移分三个层次,第一层是表层词汇差异,比如英文的"coffee"在意大利语境里可能特指浓缩咖啡,在美国语境里更多指滴滤咖啡,这种可以通过地域标签来区分。第二层是关系粒度差异,有些文化对亲属关系划分得很细,表兄弟和堂兄弟是不同的词,英文都是cousin,这时候需要设计更细粒度的关系本体,允许不同语言映射到不同粒度的关系节点。第三层是价值观差异,比如"成功"这个概念在不同文化里内涵完全不同,这种没法强行对齐,更合理的做法是保留各语言的独立解释,在查询时根据用户的语言背景返回对应的文化解读。
低资源语言是多语言知识库绕不开的难题。像斯瓦希里语、乌尔都语这些语言,标注数据少,预训练语料也不够,直接训练模型效果很差。一种做法是利用高资源语言作为桥梁,通过英语这个pivot语言间接对齐。比如乌尔都语实体先对齐到英语,英语再对齐到中文,虽然多了一跳但总比没有强。另一种是利用同语系的语言特性,比如乌尔都语和印地语语法相近,可以用印地语的模型迁移过来,再用少量乌尔都语数据微调。还有个很实用的方法是利用跨语言字典和音译规则,很多低资源语言的实体名称直接音译自英语,通过音译模型可以建立初步映射。
多语言知识库的质量评估不能只看准确率,要从多个维度来衡量。对齐准确率是基础指标,衡量有多少对齐关系是正确的。召回率同样重要,衡量漏对齐了多少本该对齐的实体。还要看覆盖度,各语言的实体覆盖比例是否均衡,不能英文覆盖率90%中文只有30%。一致性指标衡量跨语言查询的结果是否一致,用中文查和用英文查同一个问题,答案应该在语义上等价。拿搜索场景举例,如果用户用德语搜"iPhone Akkulaufzeit"(iPhone电池续航),系统应该能关联到英文知识库里的battery life相关知识。质量评估就是抽样测试这类跨语言查询的成功率。如果发现某个语言对的对齐质量特别低,就针对性地增加这个语言对的训练数据或调整对齐策略。
2025年大语言模型的能力越来越强,有些团队开始尝试用GPT-4这类模型做跨语言对齐,给模型提供两个实体的描述,让它判断是否应该对齐。这种方法的好处是不需要训练,few-shot learning就能work,特别适合长尾语言和低资源场景。但成本比较高,更适合用在传统方法搞不定的hard case上,作为兜底方案。多语言知识库构建有一套比较成熟的开源工具链。数据采集层可以用Scrapy做多语言网页爬取,配合langdetect做语言检测。知识抽取层,spaCy的多语言支持很不错,对主流语言都有预训练模型。OpenEA是个专门做实体对齐的开源框架,内置了十几种对齐算法,从基于翻译的到基于图神经网络的都有,可以直接拿来做baseline。图数据库推荐Neo4j,它的Cypher查询语言对多语言支持友好,存储和查询跨语言图谱很方便。
分层架构的好处是各层可以独立迭代,知识抽取层的模型升级不影响对齐层,对齐算法优化也不需要重跑抽取。但坏处是错误会在层间传播,如果抽取层把实体识别错了,对齐层再准确也没用。所以实际设计时要在每层之间加置信度传递机制,对齐时不只看相似度,还要参考抽取阶段的置信度,这样能降低错误传播。这种讲利弊讲权衡的设计思路,才是真正经得起考验的工程实践。