精炼回答
LangChain的缓存机制主要通过缓存层拦截重复的LLM调用来工作。当你发起相同的提示词请求时,系统会先检查缓存中是否存在对应的响应,如果命中则直接返回缓存结果,避免重复的API调用和计算开销。这种设计解决了LLM应用中的两个关键痛点——API调用成本和响应延迟。
LangChain支持多种缓存后端,包括内存缓存、SQLite、Redis和语义缓存。内存缓存适合开发测试,Redis适合生产环境的分布式场景。特别值得注意的是语义缓存,它不仅匹配完全相同的输入,还能识别语义相似的查询并返回相关缓存结果。比如"手机续航"和"电池使用时间"其实是在问同一件事,语义缓存能够智能识别这种关联。
性能优化方面,需要根据应用场景选择合适的缓存策略。对于高频重复查询的场景,启用缓存能显著降低延迟和成本。合理设置TTL过期时间很关键,既要保证数据新鲜度,又要最大化缓存命中率。在处理大量用户请求的生产环境中,使用Redis集群可以提供更好的并发性能。
扩展分析
详细解释
LangChain采用了代理模式来实现缓存功能,缓存层作为代理对象包装了真正的LLM调用,所有的请求都先经过缓存层的处理。这种设计的优雅之处在于对上层应用完全透明,你不需要修改任何业务逻辑代码,只需要在配置层面启用缓存即可。
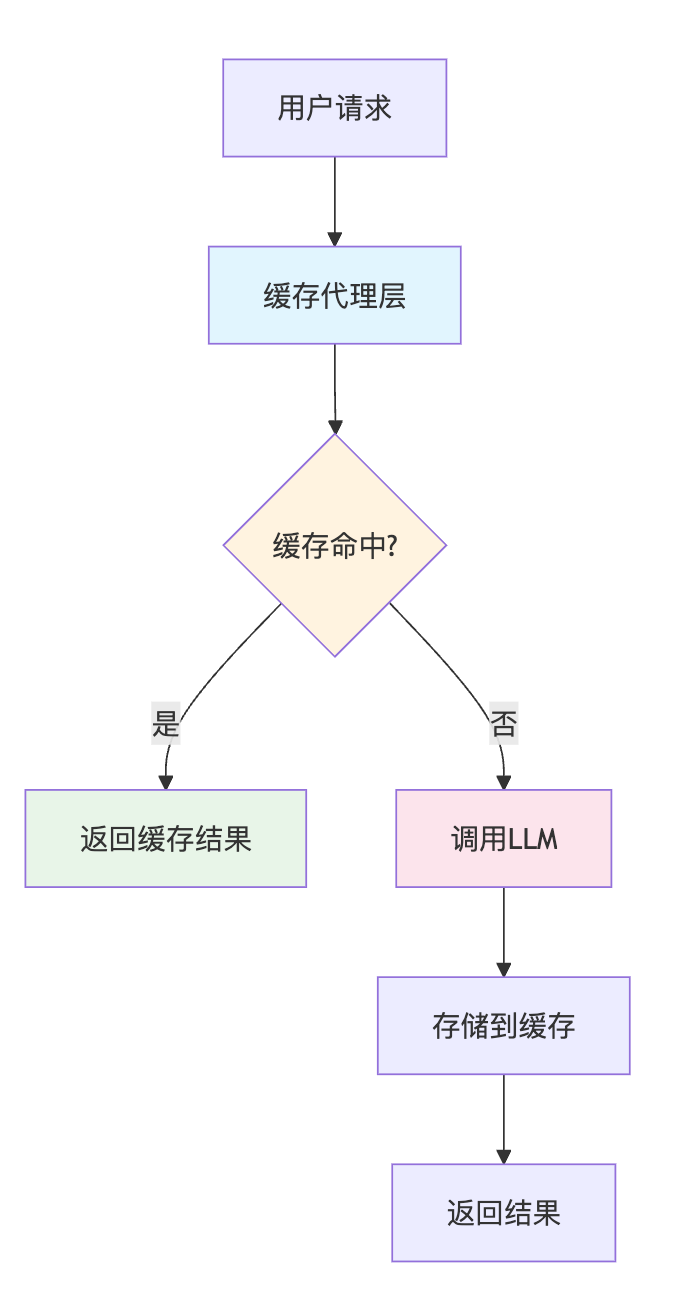
从具体的缓存实现方式来看,InMemoryCache是最简单的方案,它在应用程序里维护一个类似HashMap的数据结构,键是请求的哈希值,值是LLM的响应结果。这种方式的优势是访问速度极快,几乎没有网络开销,但显然只适合单机环境或者开发测试阶段。
// InMemoryCache的核心逻辑
publicclassInMemoryCache{
privatefinalMap<String,CacheEntry> cacheMap =newConcurrentHashMap<>();
publicStringgetCachedResponse(String prompt){
String cacheKey =generateHashKey(prompt);
CacheEntry entry = cacheMap.get(cacheKey);
if(entry !=null&&!entry.isExpired()){
return entry.getResponse();
}
returnnull;
}
publicvoidputCache(String prompt,String response,Duration ttl){
String cacheKey =generateHashKey(prompt);
CacheEntry entry =newCacheEntry(response,System.currentTimeMillis()+ ttl.toMillis());
cacheMap.put(cacheKey, entry);
}
privateStringgenerateHashKey(String prompt){
returnDigestUtils.md5Hex(prompt);
}
}java
SQLiteCache实际上是把缓存数据持久化到本地文件系统,这解决了应用重启后缓存丢失的问题。它适合那些对缓存一致性要求不高,但希望有一定持久化能力的场景。拿电商场景举例,商品描述生成这种相对稳定的内容就很适合用SQLiteCache,既有持久化效果,又不需要额外的缓存服务器。
RedisCache才是大厂生产环境的主流选择,它解决的是分布式场景下的缓存共享问题。当你有多个应用实例在处理用户请求时,RedisCache能确保所有实例共享同一份缓存数据。RedisCache的核心价值不仅在于分布式共享,还在于它提供的丰富的数据结构和过期策略,这让缓存管理变得更加灵活。
语义缓存是LangChain的创新特色,也是最值得深入了解的部分。传统的键值缓存基于精确字符串匹配,而语义缓存通过向量相似度来判断缓存命中。具体工作流程是先把用户的查询转换成向量表示,然后在向量空间中搜索相似的历史查询,如果相似度超过设定阈值就返回对应的缓存结果。
publicclassSemanticCache{
privatefinalVectorDatabase vectorDb;
privatefinalEmbeddingService embeddingService;
privatefinaldouble similarityThreshold;
publicSemanticCache(VectorDatabase vectorDb,EmbeddingService embeddingService){
this.vectorDb = vectorDb;
this.embeddingService = embeddingService;
this.similarityThreshold =0.85;
}
publicStringfindSimilarResponse(String query){
Vector queryVector = embeddingService.embed(query);
List<SimilarResult> similarResults = vectorDb.searchSimilar(queryVector, similarityThreshold,5);
if(!similarResults.isEmpty()){
return similarResults.get(0).getResponse();
}
returnnull;
}
publicvoidstoreQuery(String query,String response){
Vector queryVector = embeddingService.embed(query);
CacheEntry entry =newCacheEntry(query, response, queryVector,System.currentTimeMillis());
vectorDb.store(entry);
}
}java
语义缓存的技术挑战在于向量相似度计算比简单的哈希查找要复杂得多,这会带来额外的计算开销。而且相似度阈值的设定需要在缓存命中率和结果准确性之间找平衡,设得太低容易返回不相关的结果,设得太高又失去了语义匹配的意义。
实践应用
在实际的生产环境中,不同类型的查询需要不同的缓存策略。以电商平台的商品问答系统为例,商品基础信息查询重复度高且更新频率低,适合使用Redis缓存配置较长的TTL,比如设置24小时过期。而促销活动相关的查询则需要更短的缓存时间,通常设置为30分钟到1小时,确保价格信息的准确性。这种分层缓存策略能够在保证数据准确性的同时最大化缓存效果。
缓存配置的参数调优直接影响系统性能表现。缓存容量要根据业务QPS和平均响应大小来估算,一般建议预留30%的缓冲空间来应对流量峰值。Redis连接池的配置也很关键,maxTotal通常设置为应用实例数的2-3倍,maxIdle设置为maxTotal的80%左右,这样既能保证并发性能,又不会造成连接资源浪费。
// Redis缓存配置示例
@Configuration
publicclassCacheConfig{
@Bean
publicRedisTemplate<String,Object>redisTemplate(){
RedisTemplate<String,Object> template =newRedisTemplate<>();
// 连接池配置
JedisPoolConfig poolConfig =newJedisPoolConfig();
poolConfig.setMaxTotal(200);
poolConfig.setMaxIdle(160);
poolConfig.setMinIdle(50);
poolConfig.setTestOnBorrow(true);
JedisConnectionFactory factory =newJedisConnectionFactory(poolConfig);
template.setConnectionFactory(factory);
// 序列化配置
template.setKeySerializer(newStringRedisSerializer());
template.setValueSerializer(newGenericJackson2JsonRedisSerializer());
return template;
}
@Bean
publicCacheManagercacheManager(){
RedisCacheManager.Builder builder =RedisCacheManager
.RedisCacheManagerBuilder
.fromConnectionFactory(redisConnectionFactory())
.cacheDefaults(cacheConfiguration(Duration.ofHours(12)));
return builder.build();
}
}java
监控缓存性能的关键指标设计要建立有效的监控体系来及时发现问题。缓存命中率是最核心的指标,但不同业务场景下有不同的合理预期。一般来说,商品详情查询的命中率应该达到80%以上,用户个性化推荐的命中率可能只有40-60%,这是正常的。除了命中率,还要监控平均响应时间、缓存容量使用率和错误率等指标。
分布式环境下的缓存同步方案中,Redis Cluster是主流选择。Redis Cluster通过数据分片解决了单机容量限制,通过主从复制保证了高可用性。在实际部署时,建议至少使用3主3从的配置,这样既能承受单点故障,又能提供足够的并发能力。对于跨机房部署,要考虑网络延迟对缓存性能的影响,通常采用就近访问策略来减少网络开销。
对于一些可以预测的高频查询,比如热门商品的咨询问题,可以在系统启动时或者流量低峰期提前生成缓存内容。这种预热机制能确保用户在访问热点数据时始终能获得最优的响应体验。预热策略的设计需要结合业务数据分析,找出那些访问频率高且相对稳定的查询模式。
扩展思考
在AI应用日益普及的环境中,缓存设计不仅是技术问题,更是成本控制和用户体验的关键决策点。当你谈论缓存命中率时,要能联想到这背后的API成本节约。通过合理的缓存策略,可以将LLM API调用量降低50%以上,按照当前GPT-4的定价,这意味着每月可以节省数万元的运营成本。这种从技术指标到商业价值的转换能力,正是优秀工程师应该具备的商业sense。
缓存失效和更新机制的设计体现了对数据一致性的深度思考。主动失效适合那些有明确更新时点的数据,比如商品信息更新时主动清除相关缓存。被动失效则依赖TTL机制,适合那些更新时点不确定的场景。对于一些关键业务数据,还可以采用Cache-Aside模式,先更新数据库再删除缓存,这样能最大程度保证数据一致性。
LangChain的缓存不应该孤立地来看,而要考虑它与其他组件的协调关系。缓存策略要与负载均衡、API网关和监控系统协调配合,形成完整的性能优化方案。比如在API网关层面可以做一层粗粒度的缓存,在应用层面做细粒度的语义缓存,这样的多层缓存架构能够应对不同层次的性能优化需求。
即使没有直接的LangChain项目经验,也可以通过类比的方式来理解缓存设计的核心思路。Web开发中的数据库查询缓存、CDN缓存,移动端的图片缓存,这些都遵循相似的设计原则。关键是要理解缓存在整个系统架构中的作用,以及如何在性能、成本和数据一致性之间找到最佳平衡点。技术的本质往往是相通的,重要的是培养系统性思维和问题分析能力。