精炼回答
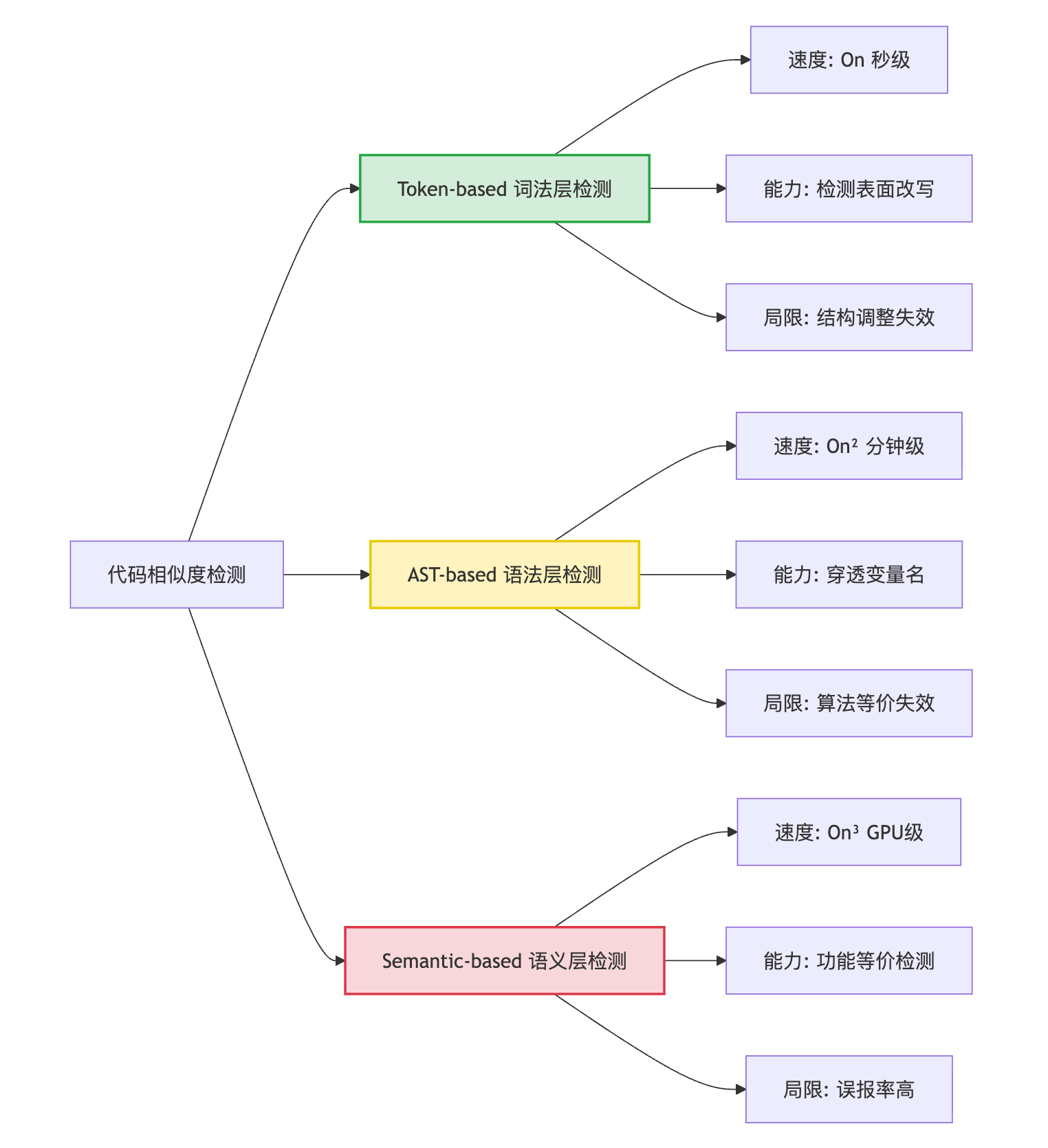
代码相似度计算没有绝对"更准"的方法,关键取决于你想检测什么类型的相似性。这三种方法本质上代表了检测的三个层次:Token-based看表面文本、AST-based看结构骨架、Semantic-based看实际行为。
Token-based是将代码做词法分析后按token序列比对,像MOSS、JPlag这类工具常用。它能快速检测变量重命名、注释修改这种表面抄袭,但对代码结构调整就无能为力了。比如把if-else改成switch,token完全不同但逻辑一样,它就检测不出来。时间复杂度基本是O(n)级别,处理百万行代码也就秒级响应,这是它最大的优势。
AST-based是解析语法树后比对结构,能穿透变量名和格式差异,直接看代码的骨架结构。像CloneDigger、PMD-CPD就是这个思路。它对语句重排、控制流变换更鲁棒,但遇到算法级别的等价改写就不行了——比如用递归改成循环实现同样功能,AST结构完全不同。因为要做语法解析和树比对,时间复杂度通常是O(n²)甚至O(n³)。
Semantic-based是分析代码的实际语义和行为,可以用符号执行、程序切片或者Code2Vec这类深度学习模型。它能识别算法层面的等价性,检测功能相同但实现完全不同的代码。缺点是计算成本高,而且容易误报——两段功能相似但确实是独立开发的代码也会被标记。
实际应用中,抄袭检测系统通常先用Token-based粗筛,再用AST-based精排,因为性能和准确度平衡最好。代码克隆检测偏好AST-based。而漏洞检测、代码搜索这种场景更需要Semantic-based,因为要找功能等价的代码片段。
扩展分析
核心技术原理与穿透能力对比
从Token-based开始讲起最自然。它本质上就是把代码当成一串词汇来处理,先做词法分析把代码切成关键字、标识符、运算符这些token,然后用序列比对算法计算相似度。常见的像Winnowing算法,它会对token序列做滑动窗口哈希,提取指纹来快速比对。MOSS那套系统用的就是这个思路,几十万份代码也能在几分钟内跑完。
但这个方法的穿透能力只到词法层,变量名一改、空格换行一调就能骗过它。更致命的是它看不懂代码逻辑,你把一个for循环改成while循环,token序列完全变了,但明眼人一看就知道是抄的,它就检测不出来。这就是为什么在学生作业检测场景下,总有人试图用自动化工具批量改写代码来逃避检测。
AST-based往前走了一步,它把代码解析成抽象语法树,关注的是代码的结构骨架而不是表面文本。比如一个if语句,不管你变量叫什么名字、有没有大括号、缩进几个空格,在AST里都是同一个条件分支节点。技术实现上比较经典的像树编辑距离算法,计算两棵AST之间需要多少次插入删除操作才能互相转换,距离越小越相似。还有子树匹配的方法,用哈希把相同的子树快速找出来,这个在检测代码克隆时特别有效。
但AST只能看到语法结构,看不到语义等价性。最典型的例子就是递归和迭代互换,两种写法的AST结构完全不同,一个是函数调用自己,一个是循环结构,但实现的功能是一样的。还有像冒泡排序和快速排序,虽然都是排序,但AST结构天差地别,这时候AST-based就无能为力了。
Semantic-based则是要理解代码的实际行为和语义,这里面其实有两条技术路线。传统的程序分析路线包括符号执行,它会模拟程序的执行路径,用符号变量推导出输入输出的关系。两段代码如果在数学上等价,符号执行能检测出来。还有程序切片技术,它能提取出影响某个变量的所有语句,形成一个语义依赖图,然后比对这些依赖图的相似性。比如漏洞检测系统需要找所有可能导致SQL注入的代码片段,这时候就得用语义分析,因为漏洞代码可能用完全不同的写法来构造SQL语句,但本质上都没做参数化查询。
现在更流行的是深度学习路线。像Code2Vec、GraphCodeBERT这些预训练模型,它们会把代码编码成向量,相似的功能在向量空间里距离就近。GitHub的Copilot检测代码重复就用了这套方案,它能识别出功能相同但写法完全不同的代码片段,甚至跨语言也能检测,比如一段Java代码和一段Python代码实现了同样的功能,语义模型能把它们映射到相近的向量空间。
但Semantic-based的代价要说清楚。第一是计算成本,符号执行可能遇到路径爆炸,深度学习模型推理也需要GPU资源。第二是误报问题,两段功能相似但确实是独立开发的代码也会被标记,这在开源代码检测时特别头疼。第三是可解释性差,尤其是深度学习方法,它告诉你两段代码相似度90%,但具体哪里相似、为什么相似很难解释,这在法律纠纷或者学术诚信检测中是个大问题。
这三种方法其实代表了相似度检测的三个层次——词法层、语法层、语义层。穿透能力逐层递增,但计算复杂度和误报风险也在增加。Token-based像是看代码的"长相",AST-based看的是"骨架",Semantic-based则是理解"灵魂"。
这里要特别澄清一个概念,相似度和等价性其实是两回事。相似度是个连续的度量值,两段代码可以60%相似也可以90%相似。但等价性是个离散的判断,要么等价要么不等价,它关注的是在所有可能输入下输出是否一致。比如x = a + b和x = b + a,它们在语义上完全等价,但如果用token序列算相似度,可能只有80%,因为token顺序不同。反过来,两段高度相似的代码,比如只改了一个边界条件,相似度可能95%,但语义上完全不等价,一个有bug一个没有。
场景化应用与工程实践
抄袭检测其实是个很大的范畴,课程作业检测和开源许可检查虽然都叫抄袭检测,但需求完全不同。学生作业检测主要防的是简单改写,把变量名从studentList改成dataList、加几行无关代码这种。这种场景用Token-based就够了,因为学生一般不会花太多心思深度改写,而且要处理几千份作业,性能是第一要求。设定阈值时要注意,不能一刀切说80%相似就判定抄袭,得结合代码长度。一个只有十行的Hello World程序,正常写可能就有70%相似度,但一个两百行的数据结构作业,如果有80%相似那基本就是抄的。
但开源许可检查就完全不同了,要防的是商业代码里混入了GPL许可的开源代码。这种场景下对方可能会故意改写,把函数名全改了、拆成几个文件、甚至用代码混淆工具处理过。这时候Token-based就不够用了,得上AST-based,因为要穿透变量名和格式差异,直接看代码结构。工程上一般会先对代码库做指纹索引,把常见开源项目的AST特征提前算好存下来。新代码进来时只需要比对指纹,不用每次都解析语法树,这样能把检测时间从分钟级降到秒级。
GitHub Copilot这类工具现在遇到一个很现实的问题——它生成的代码会不会跟训练数据里的某段代码完全一样?如果一模一样那可能涉及版权问题,但功能相似、写法不同的代码肯定不算侵权。所以它们用的是混合方案,先用Token-based做快速去重,把那些逐字符相同的代码片段直接过滤掉。然后用语义模型判断功能相似度,如果功能相似但写法差异够大,就认为是合理生成。阈值设定时要平衡两个指标,一个是去重率,确保不会原样复制训练数据;另一个是可用率,如果去重太严格导致能用的代码太少,用户体验就很差。实际运营中这个阈值需要持续调优,一般会结合用户反馈和法务建议动态调整。
代码克隆检测是另一个典型场景。大型项目里经常会有团队成员复制粘贴代码,改几个变量名就用了,时间长了项目里到处都是重复逻辑。这种克隆代码维护成本特别高,改一个bug要改十个地方,漏改一处就出问题。克隆检测用AST-based最合适,因为它能找出那些改了变量名、调整了语句顺序但结构相同的代码。比如PMD-CPD这类工具,它会标记出项目里所有克隆代码块,给重构提供依据。但要注意误报问题,像getter/setter方法、工厂模式的创建代码,这些本来就是标准写法,肯定会高度相似,不能全都标记成克隆代码。所以工程实现时要加白名单机制,把这些常见模式排除掉。
工程上的混合方案通常是三层过滤架构。第一层用Token-based做粗筛,这层主要是性能考虑,用哈希指纹快速比对,过滤掉明显不相似的代码,能减少90%以上的比对量。第二层用AST-based做精筛,把第一层筛出来的候选代码解析成语法树,计算结构相似度,这层能抓住大部分改写抄袭。第三层是语义检测,只在高风险场景才启用,比如检测出结构相似度很高但又不完全相同的代码,就进一步做语义分析确认是否真的等价。
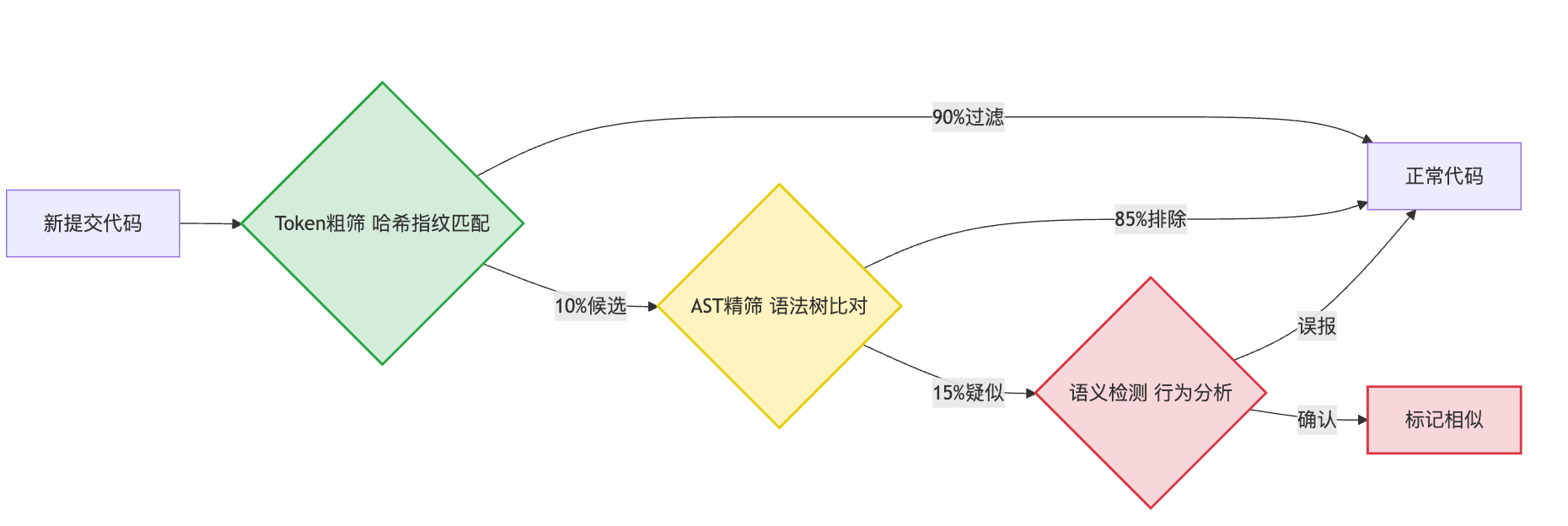
不同层的检测结果不能简单投票,要根据场景加权。比如在学生作业检测中,Token层的权重可以占到70%,因为大部分抄袭都是简单改写。但在开源许可检查中,AST层的权重要占到60%以上,因为对方可能会深度改写。假设Token相似度85%、AST相似度75%、语义相似度90%,在作业检测场景下最终得分可能是0.7×85 + 0.2×75 + 0.1×90 = 83.5分。但在开源检查场景下可能是0.2×85 + 0.6×75 + 0.2×90 = 80分。同样的代码对,不同场景下的判定结果可能不同。
百万级代码库做全量比对是不现实的,肯定要提前建索引。Token层可以用MinHash或SimHash建局部敏感哈希索引,相似的代码会映射到相同的桶里。AST层可以提取子树特征,对每个函数计算结构指纹存到倒排索引里。新代码来的时候先查索引找候选集,再做精确比对。增量更新时不用重建整个索引,只需要更新变化部分。比如代码仓库有新提交,可以只对diff的文件重新计算特征,其他文件的索引直接复用。这样每次提交的检测时间能控制在秒级,满足持续集成的性能要求。
评估相似度检测效果不能只看准确率,因为这里涉及两类错误。第一类是漏报,真正抄袭的代码没检测出来,这在学术诚信检测中后果很严重。第二类是误报,把正常代码标记成抄袭,这会伤害用户体验。不同场景对这两类错误的容忍度不同。学术检测场景宁可误报也不能漏报,所以阈值会设低一点,比如60%相似就标记出来人工复核。但代码推荐场景则相反,误报会导致很多正常代码被过滤掉,所以阈值会设高,可能要85%以上才报警。
系统设计与未来趋势
代码相似度检测系统最大的挑战不是算法本身,而是要在检测精度、计算成本、响应时间这三个维度之间找平衡点。百万级代码仓库,如果每次提交都要全量扫描,用AST-based可能要跑十几分钟,持续集成流程根本等不起。但如果为了速度只用Token-based,又会漏掉大量深度改写的抄袭。
自适应检测策略是一个很好的工程实践思路。根据代码变更的风险等级动态选择检测深度。比如核心支付模块的提交触发全量语义检测,普通业务代码只做Token和AST两层检测,配置文件和单元测试代码甚至可以跳过检测。这种分级策略能让系统资源用在刀刃上,既保证了关键模块的检测质量,又控制了整体的计算成本。
我之前负责过团队的代码质量体系建设,当时就遇到一个很棘手的问题——老项目里到处都是复制粘贴的代码,但重构成本太高,管理层不愿意投入资源。我的做法是先用AST-based工具扫描全量代码,生成一张克隆代码地图,然后按照修改频率和bug密度给每个克隆代码块标注优先级。那些频繁修改又经常出bug的克隆代码优先重构,冷门代码就暂时不动。这样既控制了技术债,又让重构投入产出比看得见,管理层也能接受。
2025年大模型在代码理解领域已经展现出明显优势。最近图神经网络在代码分析上有很多突破,它能把代码表示成程序依赖图,节点是变量和语句,边是数据流和控制流依赖。这种表示方式比AST更接近代码的真实语义,两段看起来完全不同的代码,如果程序依赖图相似,很可能就是功能等价的。现在一些代码搜索引擎就在用这个思路,你输入一段功能描述或者一小段示例代码,它能从海量代码库里找出功能相似但实现完全不同的代码片段。这比传统的关键词搜索强太多了。
大模型时代代码相似度检测其实面临一个有意思的问题——现在AI生成的代码越来越多,传统相似度检测方法可能不太够用了。因为大模型生成代码的模式和人类抄袭的模式不一样。人类抄袭通常是复制粘贴后局部修改,但大模型可能会生成功能相同、细节完全不同的代码。这时候需要更深层的语义理解才能检测出来。所以现在有研究在用对比学习训练代码相似度模型,让模型学会把功能相同的代码映射到相近的向量空间,即使跨语言也能检测。比如一段Python代码和一段Java代码实现了同样的功能,向量相似度就会很高。
代码相似度检测这个领域,学术界和工业界关注点其实有偏差。学术界更关心检测准确率,论文里各种复杂模型能把准确率刷到95%以上。但工业界更在意的是误报率和计算成本,一个准确率90%但几乎不误报、秒级响应的系统,往往比准确率95%但经常误报、需要几分钟的系统更实用。未来趋势是把深度学习模型和传统方法结合起来,用传统方法做粗筛保证性能,用深度学习模型做精排提升准确度,同时建立人工复核机制兜底,这样才能做到工程上真正可用。