精炼回答
Graph of Thoughts(GoT)通过有向无环图(DAG)结构来表示推理过程,其中节点代表中间思维状态,边代表思维之间的依赖关系。这种表示方式允许多条推理路径并行存在,思维可以分叉、合并、回溯,形成网状的推理网络。
具体来说,GoT会将复杂问题分解后,让不同的推理分支独立探索,再通过聚合节点整合多个分支的结论。比如在代码调试场景中,可以同时探索"语法错误"和"逻辑错误"两个方向,各自推进后再汇总成最终诊断结果。GoT的核心优势在于突破了链式推理的线性限制。传统的Chain-of-Thought只能按固定顺序逐步推理,而GoT支持思维的任意组合和重用。当某个推理分支遇到瓶颈时,可以从图中其他节点寻找突破口,甚至将之前的中间结果用于新的推理路径。
这种灵活的拓扑结构特别适合处理需要多角度验证的任务,比如数学证明需要同时验证必要性和充分性,或者在策略规划中需要评估多个并行方案。另外,图结构天然支持显式的推理状态管理,可以清晰追溯每个结论的推导依据,便于调试和优化推理过程。相比树状结构的Tree-of-Thoughts,GoT通过允许节点间的交叉连接,避免了重复计算相同的中间状态,提升了推理效率。
扩展分析
理解GoT的本质突破
要真正理解GoT,最重要的是用一句话抓住它的核心:GoT本质上是用图结构来组织大语言模型的思维过程,让AI的推理不再是单线条的链式思考,而是像人类大脑一样能够多线程并行探索。这个定义既点明了技术特征,又展现了对背后逻辑的理解。
理解这个技术最好的方式是看它的演进脉络。最早的Chain-of-Thought就像一条笔直的公路,问题只能按固定顺序A→B→C推理。Tree-of-Thoughts进化成了立交桥,允许在某些节点分叉探索不同方向。而GoT则是完整的城市路网,任意两个思维节点都可能建立连接,甚至可以从目的地反向回溯优化路径。这种类比能让人快速感受到技术的突破点在哪里。
GoT的核心机制体现在三个关键能力上。首先是思维节点可以任意连接形成复杂依赖,不像传统方法那样受限于时间序列。其次是多个推理分支的结果能够聚合成综合结论,这不是简单的文本拼接,而是理解不同证据链后的智能融合。最后是遇到死胡同时可以回溯到之前的节点重新探索,传统方法遇到错误只能从头来过,但GoT可以保留正确的部分,只修正出问题的分支。
让我们用一个直观的例子来固化理解。假设让AI对一组数字排序,CoT会让模型从头到尾比较一遍。ToT可能会尝试快排和冒泡两种策略选最优的。而GoT可以同时启动多个排序分支,把已排好序的小段当作中间节点,最后合并时直接复用这些节点,不需要重复计算。这个例子的好处是即使技术背景不深的人也能秒懂图结构带来的效率提升。
图结构的设计思想
要理解GoT的图结构,关键是要搞明白它和我们平常说的图搜索完全是两码事。这个区分非常重要,能有效防止把GoT的推理过程理解成在找最短路径。图中的每个节点其实就是大模型在某个推理阶段输出的一段完整文本,比如"根据用户行为判断这是价格敏感型客户"这样的中间结论。而边的作用不是简单连接,它代表的是推理的因果依赖——如果节点A的结论是节点B推理的前提,那就有一条从A指向B的边。
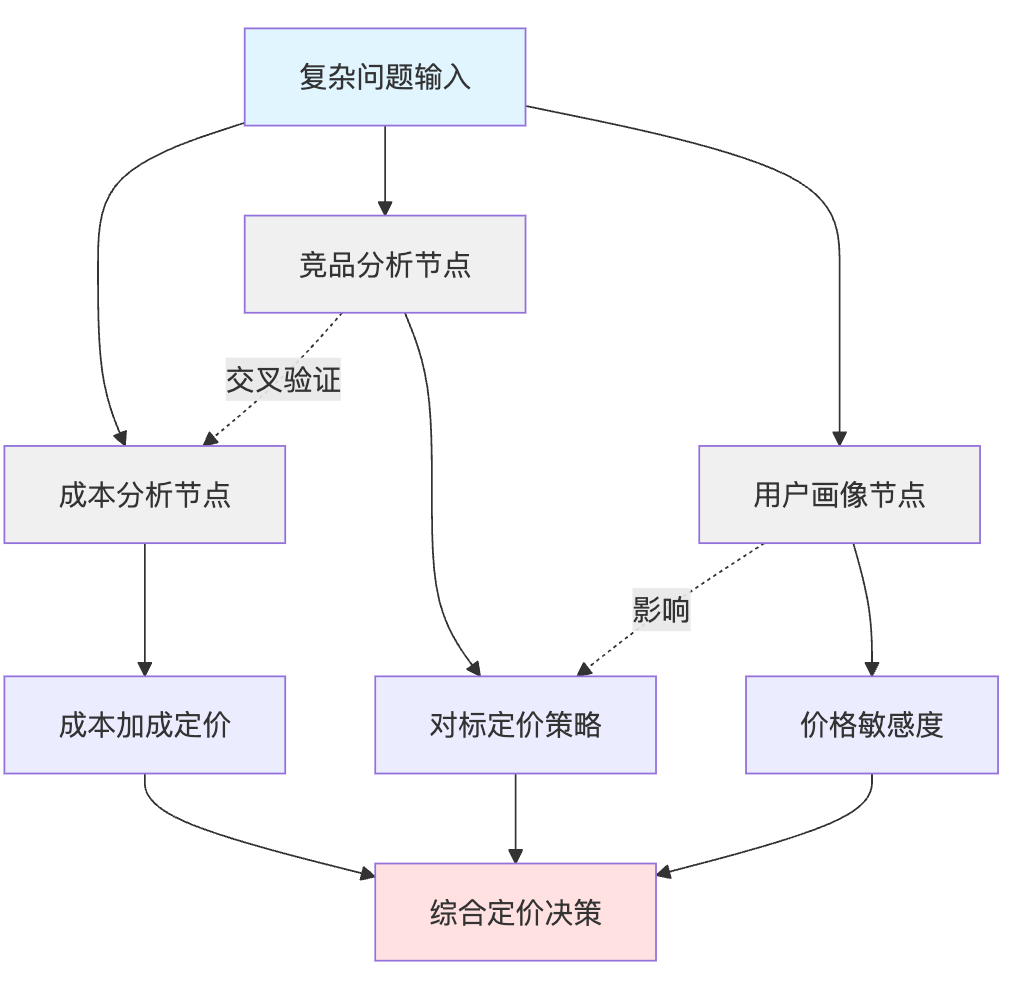
传统CoT里这些思考步骤只是按时间顺序排列的文本,前后步骤的依赖关系是隐式的。但GoT通过显式的边把这种依赖关系暴露出来,所以可以灵活组合不同的推理路径。拿商品定价策略来说,假设要给新品定价:CoT会让模型线性推理"先分析成本→再看竞品价格→最后定价",这三步必须顺序执行。ToT则允许模型同时尝试"成本加成法"和"竞品对标法"两个策略,最后选评分高的那个。而GoT可以让"成本分析"和"竞品分析"这两个节点并行计算,然后把它们的结果汇聚到一个"综合定价策略"节点,甚至还能加入"用户画像分析"节点与前两者交叉验证。注意GoT的关键差异是允许思维节点之间双向引用和多对多依赖,这在树结构里是做不到的。
GoT的核心操作需要从解决问题的角度来理解,而不是当成API文档来记忆。Generate操作是在构建推理图的局部拓扑,当推理到某个节点时,模型需要基于前置节点的结论生成新的思考内容。比如从"用户加购未下单"这个节点,可以Generate出"发送优惠券提醒"和"分析弃购原因"两个后续节点。Aggregate操作是GoT最精妙的地方,多个独立推理分支的结果怎么融合?不是简单拼接文本,而是让模型理解不同分支的证据链,综合得出更可靠的结论。比如"价格偏高"和"库存紧张"两个分支都指向"降低优先级推荐",Aggregate操作会让模型意识到这个结论有双重证据支撑。
Score和Refine操作要连起来理解才有意义。Score就像代码审查,给每个推理节点打分评估质量。Refine则是根据反馈修改代码,当发现某个节点的推理逻辑有漏洞时,不需要推翻整个图重来,只需要Refine这个节点并更新依赖它的下游节点。这种局部修正的能力是线性推理做不到的。
遍历策略是个容易被忽视但很重要的点。GoT的遍历策略要根据任务特点选择,如果是层层递进的分析任务,用类似BFS的方式能保证每个推理层级都充分展开。但如果是需要深挖某个分支的场景,比如排查系统故障根因,DFS式的深度优先更高效。更高级的做法是结合Score操作做优先级搜索,优先扩展那些推理质量高的节点。这些策略的选择权在系统设计者手里,而不是模型自己决定的,所以GoT框架需要暴露这些控制接口。
必须主动澄清一个常见误解:很多人第一次听到GoT会以为是在做图搜索算法,但实际上图只是组织推理过程的数据结构。真正产生推理内容的仍然是大语言模型,图结构只是告诉模型"现在该基于哪些前置结论来思考新问题"。换句话说,图的遍历过程控制的是模型推理的顺序和依赖关系,而不是在已有图上找路径。GoT的工程实现复杂度主要在于如何高效管理图的动态构建和状态更新。不像静态图可以一次性构建好,推理图是边推理边生成的,需要处理好节点的缓存复用、循环依赖检测、以及推理失败时的回溯机制。
实践应用场景
GoT不是银弹,关键是要精准把握它的适用场景。GoT最擅长的是那种需要把多条独立推理路径的结论汇总起来的场景。如果问题本身就是线性的,比如翻译一段文字,那用CoT就够了。如果需要探索多个方案然后选最优的,ToT更合适。但如果不同推理分支的中间结果需要相互引用和组合,那GoT才真正发挥价值。
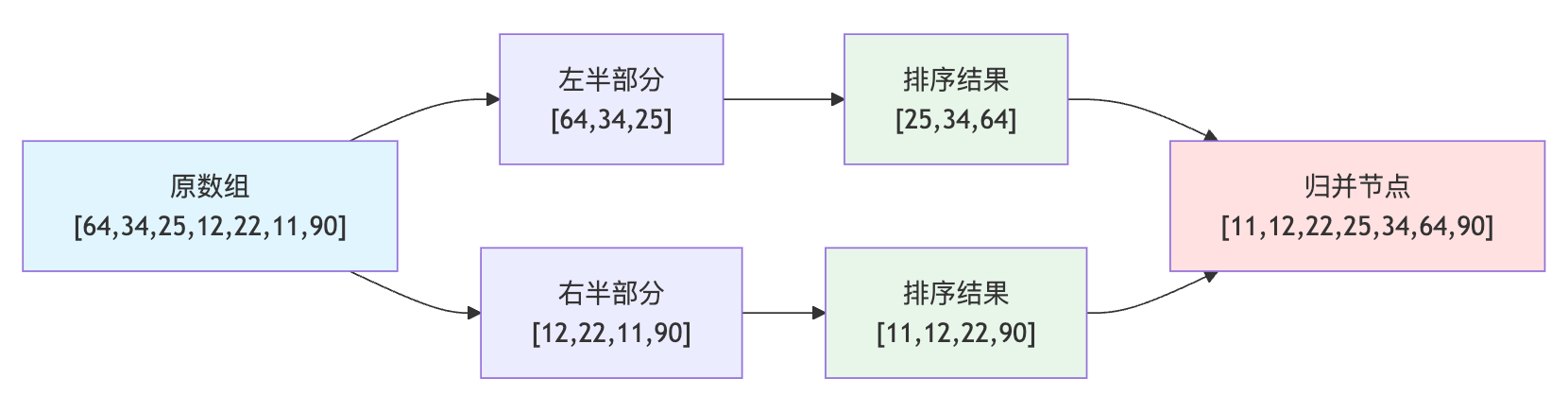
排序任务是个绝佳的例子,因为它足够经典但又能充分展现GoT的优势。拿排序一组数字来说,假设要让大模型对[64, 34, 25, 12, 22, 11, 90]这个数组排序。传统CoT会让模型一步步比较交换,但GoT可以把它分解成多个子问题:先把数组分成[64, 34, 25]和[12, 22, 11, 90]两个部分,让这两个部分各自排序,这是两个并行的推理节点。然后再生成一个聚合节点,它依赖前面两个排序结果,执行归并操作得到最终答案。注意这里的聚合节点会同时读取两个子列表的排序结果,这种多对一的依赖关系在链式推理里根本做不到。
 文档合并是另一个特别能说明问题的场景。假设要生成一份产品需求文档,需要整合技术可行性分析、市场调研报告、竞品对比三部分内容。用GoT的话,这三个分析可以并行进行,各自形成独立的推理分支。关键在于最后的整合节点不是简单拼接三段文本,而是要识别它们之间的矛盾和互补。比如技术分析说某个功能实现成本高,但市场调研显示用户强需求,那整合节点就需要推理出"优先级高但需要分阶段实现"这样的综合结论。这个例子展示了Aggregate操作的真正价值,而不只是把GoT当成并行计算工具。
文档合并是另一个特别能说明问题的场景。假设要生成一份产品需求文档,需要整合技术可行性分析、市场调研报告、竞品对比三部分内容。用GoT的话,这三个分析可以并行进行,各自形成独立的推理分支。关键在于最后的整合节点不是简单拼接三段文本,而是要识别它们之间的矛盾和互补。比如技术分析说某个功能实现成本高,但市场调研显示用户强需求,那整合节点就需要推理出"优先级高但需要分阶段实现"这样的综合结论。这个例子展示了Aggregate操作的真正价值,而不只是把GoT当成并行计算工具。
GoT听起来很美好,但实际使用的时候有几个问题必须想清楚。第一个是节点粒度的把握。如果把问题切得太细,图的节点数会爆炸,模型调用次数太多成本受不了。但切得太粗,图结构又退化成简单的分支合并,体现不出优势。这个度需要根据具体任务实验调优,没有通用标准。
第二个坑是评估函数的设计。前面提到的Score操作看似简单,实际上是个大难题——你怎么判断一个推理节点的质量?如果用模型自己打分,它可能倾向于给看起来流畅但逻辑有漏洞的回答高分。如果用规则打分,又很难覆盖复杂推理的各种情况。工程上常见的做法是结合多个简单指标,比如文本长度、是否包含关键信息、与前置节点的一致性等,然后加权组合。但说实话这块还是比较依赖人工调参的。
计算开销也是绕不开的问题。GoT相比ToT的计算量确实更大,因为它不仅要探索多个分支,还要处理分支间的交叉依赖和聚合操作。每次Aggregate都相当于额外调用一次模型,而且Prompt还要包含多个前置节点的内容,Token消耗会明显增加。所以GoT适合用在推理质量比成本更重要的场景,或者说单次推理失败的代价远高于多调用几次模型的成本。比如法律文书分析、医疗诊断建议这类对准确性要求极高的任务,多花点算力换更可靠的结论是值得的。
我的使用建议是:当你发现问题的不同子任务之间存在信息依赖,而不是完全独立时,就该考虑GoT了。比如多步规划场景,后续步骤的可行性依赖于前面几步的执行结果,这时候GoT的图结构能显式建模这些依赖关系。而如果各个子任务完全独立,只是最后投票选最优方案,那ToT的树结构就够用了,没必要引入图的复杂性。技术选型的核心是匹配问题特征,而不是追新。
批判性思考与边界认知
GoT和传统图算法的区别是个容易被误解的点。传统图算法是在已知的静态图上执行搜索,比如找从A到B的最短路径,图的结构是预先给定的。而GoT的图是动态生成的,每个节点的内容和连边关系都是推理过程中由模型产生的。传统图算法在解决"如何遍历"的问题,而GoT在解决"如何构建"的问题。图只是GoT用来组织推理依赖关系的容器,遍历策略只是副产品。
评估函数的设计是GoT落地的最大痛点之一。如果让模型自评,它往往缺乏自我纠错能力。如果用规则评分,又很难定义什么叫"好的推理"。比较实用的思路是设计混合评估体系——用规则检查基本合理性,比如推理节点是否包含必要的信息要素、是否与前置节点逻辑一致,同时引入对比机制,让模型在多个候选推理中做相对评判而不是绝对打分。但说实话,评估函数的调优很大程度上依赖任务特点和人工标注数据,目前还没有通用的最佳实践。
从工程角度看,GoT在实际产品中的落地面临几个挑战。推理图的可控性是个大问题,不像写死的程序逻辑,GoT的推理路径是模型动态生成的,很难保证每次都按预期执行。这在对稳定性要求高的生产环境里是个隐患。另外调试成本也很高,当推理结果不符合预期时,你需要回溯整个图结构找出是哪个节点出了问题,这比调试线性推理要复杂得多。实际解决方案可以考虑在关键节点加人工审核,或者设置推理深度和分支数的上限来控制复杂度。
如果你做过推荐或搜索相关的项目,会发现类似的思维其实早就存在。推荐系统里多路召回的思想——从用户兴趣、热门趋势、协同过滤等多个维度并行生成候选集,最后融合排序,这和GoT的多分支聚合有异曲同工之处。但要强调区别:推荐系统的多路召回是预设好的固定策略,而GoT的分支是模型根据推理状态动态决定的,灵活性更高但可控性更弱。
最后是可解释性的问题。GoT的图结构看起来能清晰展示推理路径,但实际上每个节点内部的推理过程仍然是黑盒。GoT提升的是"推理结构"的可解释性而不是"推理内容"的可解释性——你能看到模型先分析了什么再综合了什么,但具体为什么得出某个结论,仍然依赖模型本身的可解释性。这个认知能让我们对技术边界保持清醒认识,比盲目吹捧更有价值。