精炼回答
面试时回答技术选型问题,最忌讳的是泛泛而谈"要看具体情况",面试官更想听到的是你的决策框架和实战经验。技术选型本质是风险管理,核心判断标准是项目的风险容忍度——这取决于系统的业务重要性、团队技术储备和项目时间压力。
关键要说清楚具体场景的判断逻辑。支付链路为什么必须用Spring Boot而不是Go的新框架?不是因为Go不好,而是Java生态里针对交易一致性、重试补偿的轮子已经被踩过无数坑,出问题时Stack Overflow上搜一下就有答案。反过来,如果是内部数据分析平台的API,团队又想提升并发性能,这时候用Go重写就是合理的,因为即使遇到问题,降级方案也很容易准备。
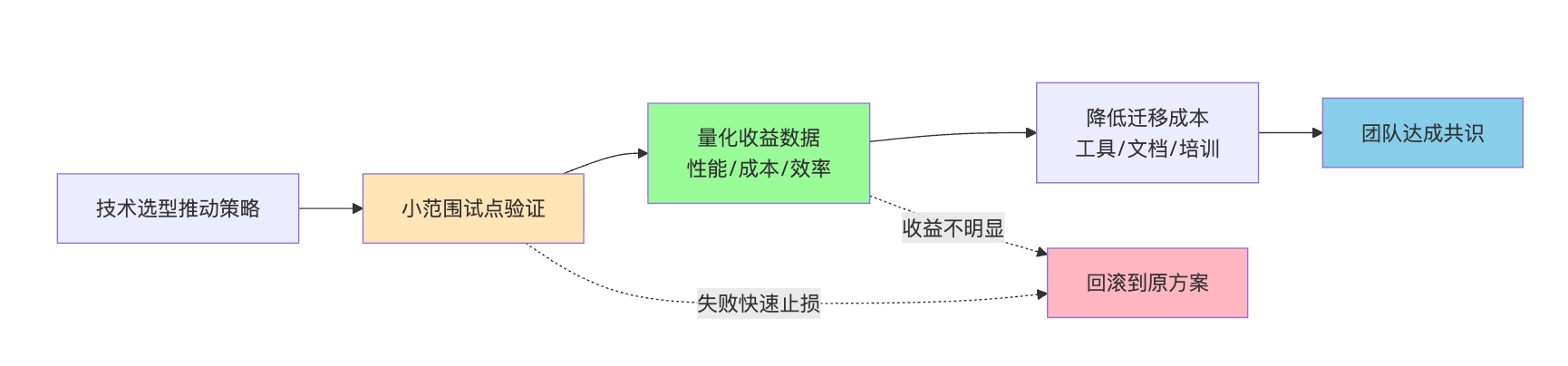
更重要的是要展示你会量化收益。面试官追问"怎么判断新技术值不值得用"时,千万别说"感觉比较好"。可以建立一个决策矩阵,横向是技术成熟度、学习成本、社区活跃度,纵向是性能提升、开发效率、维护成本。比如考虑用向量数据库替换ES做AI检索时,先在测试环境对比召回率和延迟数据,同时评估团队里有几个人能快速上手。如果性能提升30%但需要2周学习周期,项目又赶在1个月上线,那就先用ES加prompt工程优化,等下个迭代再切换。技术选型不是一锤子买卖,我倾向于在非关键路径先小范围验证,比如新的大模型推理框架先用在推荐理由生成这种边缘功能,跑稳定了再考虑扩展到主搜索。
扩展分析
面试官问技术选型时,其实是在考察你对技术决策底层逻辑的理解。很多候选人会背一套"用成熟技术保稳定,用新技术提性能"的标准答案,但这恰恰暴露了对选型本质的误解。真正让面试官眼前一亮的回答,需要你讲清楚技术选型背后的决策框架是如何演进的,以及不同时代背景下选型逻辑的变化。
技术选型这个话题其实可以追溯到软件工程诞生之初。上世纪60年代的"软件危机"让人们意识到,选择合适的技术栈比单纯追求性能更重要。那个年代的选型逻辑很简单:能用就行,因为可选项本身就很少。到了90年代互联网兴起,技术选型开始进入"生态竞争"阶段,Java能打败C++很大程度不是因为性能,而是因为JVM屏蔽了底层差异,开发者可以专注业务逻辑。这个阶段的选型核心是"降低复杂度"。
面试时可以这样切入历史脉络:技术选型的判断标准其实一直在变化,早期关注的是技术本身的能力边界,现在更关注的是整个技术生态的成熟度。比如2015年前后微服务架构火的时候,很多团队盲目把单体应用拆成几十个服务,结果发现光是服务间调用的链路追踪就搞不定,最后又退回去了。这说明当时Spring Cloud的监控生态还没成熟,选型时如果只看Netflix的技术博客,忽略了自己团队缺少SRE能力这个约束条件,就会踩坑。
这种回答方式的好处是,你展示了对技术趋势的洞察,而不是死记硬背某个框架的优缺点。面试官会追问:"那你怎么判断一个技术生态是否成熟?"这时候要给出可量化的标准。第一是GitHub的issue关闭速度,如果一个项目有上千个open issue堆积半年没人管,说明维护者精力不足;第二是Stack Overflow上相关问题的回答质量,如果高赞回答都是两三年前的,说明社区不活跃了;第三是大厂的生产实践,比如2025年向量数据库选型时,看到阿里和字节都在用Milvus并且有公开的踩坑文章,这就是强信号。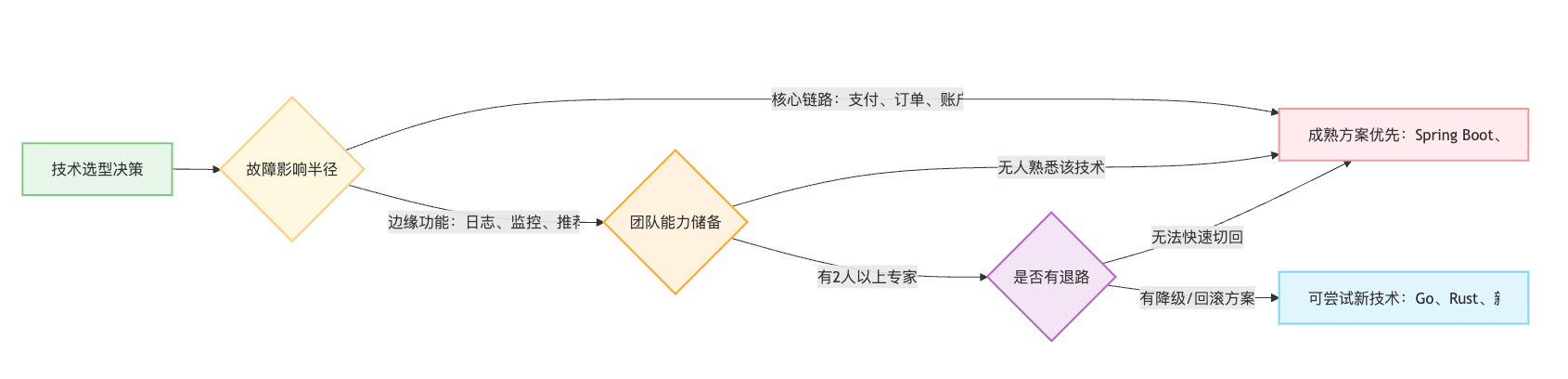
接下来要讲清楚新技术和成熟方案的根本区别。很多人以为区别在于性能指标,其实核心在于**"错误模式的可预测性"**。成熟方案的价值不是没有bug,而是遇到的问题大概率别人也遇到过,解决方案已经沉淀下来了。拿分布式事务举例,如果用Seata这种经过阿里双十一验证的方案,遇到超时、脑裂这些问题时,官方文档和社区都有最佳实践;但如果自研一套基于Raft的事务协议,可能性能测试跑得很漂亮,一旦出现网络分区导致的数据不一致,排查成本会高出一个数量级。
面试时可以用一个决策树的思维模型来组织回答:我判断用新技术还是成熟方案,会先问自己三个问题。这个系统的故障影响半径有多大?如果是支付系统,哪怕新技术能提升50%性能,我也会选Spring Boot这种十年稳定性验证的方案,因为一旦出问题,每分钟损失可能是百万级别。团队有没有应对未知问题的能力储备?比如要用Rust重写推荐服务,团队里至少要有两个人能看懂底层的内存管理逻辑,不然出了core dump根本查不出来。技术切换的退路在哪里?我之前参与过一个项目,把MySQL的全文检索切到Elasticsearch,上线前专门保留了双写逻辑,ES出问题可以瞬间切回MySQL模糊查询,这个兜底方案让我们敢于在生产环境试新技术。
现在要解决的关键问题是,怎么跟面试官解释"为什么有时候明知道新技术有坑还要用"。这里要引入**"技术债务"**的概念。成熟方案虽然稳定,但可能会积累技术债。拿AI应用举例,2025年大模型推理框架已经从vLLM迭代到更高效的SGLang,如果团队一直抱着"能用就不换"的心态,等到某天业务量暴增扛不住了,再去切换的成本会比提前迁移高出好几倍。面试时可以这样说:我认为技术选型要在保守和激进之间找平衡点。对于核心业务,我会用成熟方案打底,但同时在灰度环境持续跟进新技术的演进。比如推荐系统用的是TensorFlow Serving稳定版本,但测试环境会同步试跑最新的Triton Inference Server,一旦发现新方案在延迟和吞吐量上有明显优势,就可以快速切换,而不是等到老技术成为瓶颈时才被动升级。
面试官很可能会追问:"那你怎么说服团队和老板接受新技术的学习成本?"这时候要体现你的成本量化能力。可以举个具体场景:假设要把传统的关键词检索升级到向量检索来支持AI问答,我会先算一笔账,现在用户召回相关商品的准确率是70%,切到embedding检索后能提升到85%,这15%的提升对应的是转化率提高3个百分点,按照客单价和流量算下来,每月能多带来50万收入。而团队学习新技术需要2周时间,对应的人力成本是5万块。这样一算,一个月就能收回成本,老板自然愿意支持。但如果只是说"向量数据库很酷,我们应该试试",很难推动决策。
最后要讲一个容易被忽略的点:技术选型不是静态的,要随着系统生命周期调整策略。一个创业公司的MVP阶段,快速验证商业模式比技术完美更重要,这时候用Supabase这种all-in-one后端服务,比自己搭PostgreSQL+Redis+消息队列更合理。但当用户量到了百万级别,这种托管方案的定制性不足就会成为瓶颈,这时候必须迁移到自建的技术栈。面试时可以说:我会根据系统所处的阶段调整选型策略。早期追求迭代速度,倾向于用Firebase、Vercel这种开箱即用的服务;成长期关注扩展性,会切到Kubernetes+微服务架构;成熟期重点在成本优化,可能会把一些稳定模块用Rust重写来降低服务器开销。关键是每个阶段的目标不同,技术选型也要跟着变。
实战案例拆解
面试中讲完决策框架后,面试官最常问的就是"能不能举个你实际做过的选型案例"。这时候千万别临时编故事,而要准备几个有代表性的场景,按照"遇到什么问题→如何分析→最终选择→结果验证"这个思路来讲。关键是要让面试官感受到你真的在一线趟过坑。
先说说什么场景适合讲成功案例。面试官想听的不是"我们把MySQL换成MongoDB性能提升了10倍"这种抽象描述,而是具体的决策过程。可以这样组织语言:去年做用户画像系统时遇到一个典型场景,原来的方案是把用户行为数据存在MySQL里,每次做推荐要关联查询五六张表,高峰期延迟能到800ms。团队有人提议直接上图数据库Neo4j,因为用户关系本来就是图结构。但我当时没有直接同意,而是先做了技术预研。
这里要停顿一下,给面试官抛出你的分析逻辑。继续说:我先拉了一周的查询日志分析,发现80%的请求其实是简单的用户ID查标签,只有20%涉及复杂的好友推荐。如果全量迁移到Neo4j,意味着团队三个人都要学习Cypher语法,而且Neo4j的运维经验我们是零基础。这时候我想到了一个折中方案:核心的用户属性继续用MySQL存,但把关系数据单独抽出来放Redis的sorted set,用好友亲密度做score。这样改造只需要在应用层加一层聚合逻辑,团队改造成本不到一周,上线后P99延迟直接降到150ms。
// 混合存储方案的核心实现
publicclassUserProfileService{
@Autowired
privateUserMapper userMapper;
@Autowired
privateStringRedisTemplate redisTemplate;
/**
* 聚合用户基础信息和社交关系
* MySQL保底 + Redis优化热点
*/
publicUserProfilegetUserProfileWithFriends(Long userId){
// 从MySQL查基础属性(成熟方案保底)
UserBasicInfo basicInfo = userMapper.selectById(userId);
if(basicInfo ==null){
thrownewUserNotFoundException(userId);
}
// 从Redis查关系数据(新技术优化热点)
// ZSet按亲密度score排序,只取Top50好友
Set<String> friendIds = redisTemplate.opsForZSet()
.reverseRange("user:friends:"+ userId,0,49);
// 应用层组装,避免复杂join
returnUserProfile.builder()
.userId(userId)
.nickname(basicInfo.getNickname())
.tags(basicInfo.getTags())
.topFriends(friendIds)
.build();
}
/**
* 更新好友亲密度(异步任务定期计算)
*/
publicvoidupdateFriendIntimacy(Long userId,Long friendId,Double score){
String key ="user:friends:"+ userId;
redisTemplate.opsForZSet().add(key, friendId.toString(), score);
// 设置7天过期,自动清理不活跃关系
redisTemplate.expire(key,7,TimeUnit.DAYS);
}
}
这个案例的价值在于你展示了"不为了用新技术而用新技术"的克制。面试官如果追问"为什么不直接用Neo4j",你就可以接着说:当时也对比测试了Neo4j,在图遍历的场景下它确实比Redis快30%,但我们的业务其实不需要"找出三度好友"这种复杂查询。更关键的是Redis是团队已经在用的基础组件,出问题能5分钟定位,而Neo4j一旦遇到慢查询,可能要花半天时间去研究执行计划。这个风险收益比不划算。
接下来要准备一个"敢用新技术"的案例来平衡。2025年最合适的场景就是AI相关的技术选型,因为这个领域技术迭代特别快。可以这样讲:今年做智能客服升级的时候,遇到了一个典型的新老技术抉择。原来的知识库检索用的是Elasticsearch的BM25算法,用户问"订单迟迟不发货怎么办",系统只能匹配到"发货"这个关键词,但实际用户想问的是退款政策。这时候团队在讨论要不要引入向量数据库做语义检索。
这时候要展示你做调研的方法论:我先在测试环境做了AB对比。用OpenAI的embedding模型把1000条客服问答转成向量,分别测试了Milvus和Qdrant两个向量数据库。结果发现在我们这个规模下(100万级别的知识库),两者性能差异不到10%,但Milvus的中文文档更全,社区里有京东的生产案例可以参考。更关键的是,Milvus支持混合检索,可以同时保留原来的关键词检索作为兜底。
/**
* 混合检索策略:向量检索提升召回 + 关键词兜底
*/
publicclassHybridSearchService{
@Autowired
privateEmbeddingService embeddingService;
@Autowired
privateMilvusClient milvusClient;
@Autowired
privateElasticsearchClient esClient;
publicList<KnowledgeItem>search(String userQuery,int topK){
try{
// 向量检索(新技术提升语义召回)
float[] queryEmbedding = embeddingService.encode(userQuery);
List<KnowledgeItem> semanticResults =
milvusClient.search("knowledge_base", queryEmbedding, topK *2);
// 关键词检索(成熟方案兜底)
List<KnowledgeItem> keywordResults =
esClient.match("knowledge_base", userQuery, topK *2);
// RRF重排序融合两种结果
returnrerankByRRF(semanticResults, keywordResults, topK);
}catch(Exception e){
log.error("向量检索失败,降级到关键词检索", e);
// 降级策略:向量检索挂了也能正常服务
return esClient.match("knowledge_base", userQuery, topK);
}
}
/**
* Reciprocal Rank Fusion算法融合多路召回结果
*/
privateList<KnowledgeItem>rerankByRRF(
List<KnowledgeItem> list1,
List<KnowledgeItem> list2,
int topK){
Map<String,Double> scoreMap =newHashMap<>();
int k =60;// RRF常数
for(int i =0; i < list1.size(); i++){
String id = list1.get(i).getId();
scoreMap.merge(id,1.0/(k + i +1),Double::sum);
}
for(int i =0; i < list2.size(); i++){
String id = list2.get(i).getId();
scoreMap.merge(id,1.0/(k + i +1),Double::sum);
}
return scoreMap.entrySet().stream()
.sorted(Map.Entry.<String,Double>comparingByValue().reversed())
.limit(topK)
.map(e ->getKnowledgeItemById(e.getKey()))
.collect(Collectors.toList());
}
}
讲完案例后要补上结果验证:上线后我们持续监控了两周,发现用户问题的首次解决率从65%提升到82%,这直接减少了人工客服的介入量。但也遇到了一个坑:有些方言表达的embedding效果很差,比如"啥辰光发货"(上海话的"什么时候发货"),向量检索完全匹配不上。这时候就体现出混合检索的价值了,关键词"发货"还能兜住。这个经验让我更确信,引入新技术时一定要保留退路。
面试官很可能会问:"如果团队不同意你的方案怎么办?"这时候要展示你的推动能力:我遇到过一次推行gRPC替换HTTP接口时的阻力。有同事觉得protobuf的学习成本太高,改造现有接口要动几十个文件。我当时的做法是先选了一个新模块试点,写了一个简单的代码生成工具,把protobuf定义自动转成Java接口,团队发现改造成本其实不到半天。然后在周会上演示了一下性能对比数据:同样的请求,HTTP JSON格式的响应体是2KB,gRPC压缩后只有400字节,在弱网环境下延迟差距很明显。这种用数据说话的方式比空讲技术优势有效得多。
最后要提醒一个常见误区:很多人面试时会说"我选这个技术是因为它是行业标准"。这其实是个危险信号,面试官会觉得你缺乏独立思考。更好的表达是:当时Kafka在消息队列领域确实是主流选择,但我们业务场景比较特殊——消息体小但频率高,每秒要处理10万条日志。我对比测试后发现,Pulsar的多租户隔离和分层存储特性更适合我们,虽然它的社区规模不如Kafka,但Apache顶级项目的背书加上Yahoo的生产验证,让我觉得风险可控。结果上线半年确实省了不少存储成本。
进阶思考
当面试官抛出技术选型这道题时,他真正想考察的不是你会几种框架,而是你在面对不确定性时的决策能力。这道题其实是个陷阱:如果你只是列举"Kafka适合大流量、RabbitMQ适合可靠性"这种表面对比,面试官会觉得你只是个技术方案的搬运工;但如果你能讲出"在那个时间点、那个团队状态下、面对那个业务压力,为什么必须选这个技术",面试官立刻就能判断出你有没有真正主导过系统演进。
很多候选人会在这道题上暴露一个致命弱点:过度关注技术本身的性能参数,忽略了组织能力的约束。面试官很可能会追问:"你们团队只有3个后端,凭什么敢上Kubernetes?"这时候如果你只能说"K8s是容器编排的事实标准",基本就凉了。更好的回答是:我当时评估过自建K8s的运维成本,发现光是证书轮换、etcd备份这些琐事就会占掉一个人30%的精力。所以我们选了阿里云的ACK,虽然每月多花5000块钱,但省下来的时间能多做两个需求,ROI很划算。这种回答展示了你会算账,知道技术选型本质是资源分配问题。
面试官的另一个隐藏考察点是:你对技术趋势的判断力。2025年AI原生应用的技术选型跟传统Web系统完全不是一个逻辑。传统系统追求的是"久经考验的稳定性",但大模型领域半年就能迭代一代,如果你还抱着"等技术成熟了再用"的心态,等来的可能是业务被竞品碾压。这时候面试官想听到的是你怎么在快速迭代的领域做选型。可以这样表达:做RAG系统选向量数据库时,我没有等Milvus出到3.0稳定版,而是2.3的时候就开始用,因为这个领域的最佳实践还在形成过程中,早点踩坑反而能积累先发优势。但同时我会在架构设计上做好隔离,向量检索模块通过接口抽象,万一真要换成Qdrant或者Weaviate,改造成本也就一周。
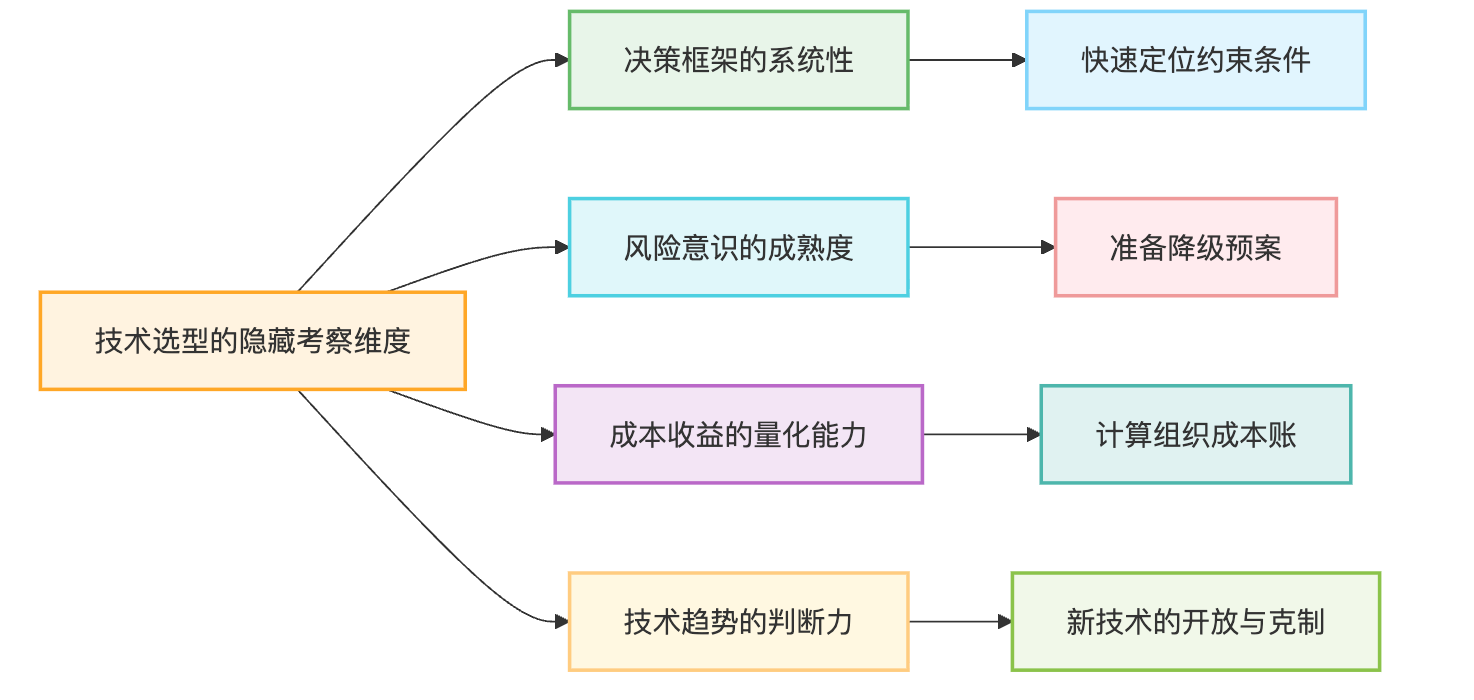
面试官还会通过追问来测试你的知识广度。比如你说选了PostgreSQL,他可能会问:"为什么不用MySQL?"这时候千万别掉进"PG比MySQL强"的二元对立陷阱。更聪明的回答是关联架构演进:我们业务有大量JSON格式的商品属性数据,MySQL处理起来要么拆成多个字段很难维护,要么用TEXT存储然后每次应用层解析很低效。PG的JSONB类型可以直接在数据库层做索引查询,这能少写很多胶水代码。而且我们后续要做向量检索,PG有pgvector插件,可以跟关系数据放在一起,省得维护两套数据库。这种回答展示了你会做技术栈的整体规划,不是头痛医头脚痛医脚。
特别要注意的一个追问方向是:"如果让你重新选型,会改什么决策?"这是个送分题,但很多人会说"我觉得当时的决策都挺好的"。面试官听到这种回答会觉得你要么在吹牛,要么缺乏反思能力。更诚恳的表达是:回头看,当时选gRPC做内部服务通信有点激进了。团队对protobuf不熟悉,导致接口变更时经常忘记更新proto文件,反而增加了联调成本。如果重来一次,我会先在服务网关层用gRPC提升性能,内部服务之间先保持HTTP+JSON,等团队习惯了再全量迁移。这次经验让我明白,技术栈的升级要考虑团队的接受曲线。这种坦诚的总结比完美的成功故事更有说服力。
最后要串联一个容易被忽略的点:技术选型跟代码质量、团队文化都是强相关的。如果面试官问到"怎么保证新技术不会成为技术债",可以这样展开:我在推Rust重写性能热点模块时,会要求团队每周做代码review,并且强制要求写单元测试覆盖核心逻辑。因为Rust的学习曲线陡,如果没有这些工程化保障,半年后可能只有一个人能维护这块代码,那就从技术升级变成了技术债务。技术选型不只是选框架,更是在选择一种协作方式。这个回答能让面试官看到你的全局观,明白技术决策最终要服务于团队的长期健康发展。
技术选型这道题看似在考技术,实际是在考你的工程思维和决策能力。记住,面试官想看到的不是完美的技术方案,而是你在权衡利弊后做出合理决策的全过程。把技术选型讲成一个有血有肉的故事,展示你如何在约束条件下找到最优解,这才是最打动人的回答。