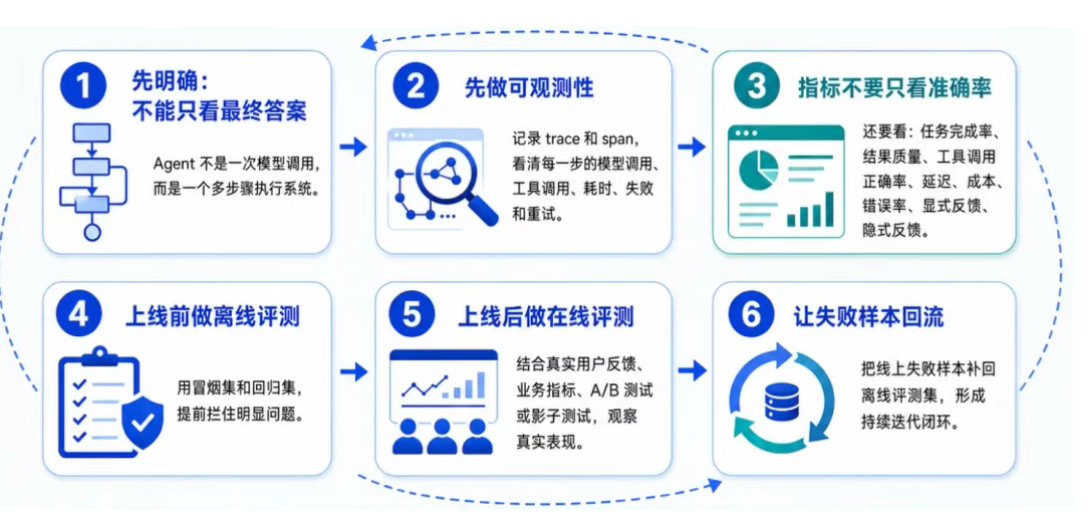
第一,先说明因为 Agent 是一个多步骤执行的系统,所以Agent 评测不能只看最终答案。
第二,先做可观测性,记录 trace 和 span,看清楚每一步的模型调用、工具调用、耗时、失败和重试。
第三,定义关键测评指标,例如任务准确率、任务完成率、结果质量、工具调用正确率、延迟、成本、错误率、显式反馈和隐式反馈。
第四,上线前做离线评测,用冒烟用例集和回归集拦住明显问题。
第五,上线后做在线评测,结合真实用户反馈、业务指标、A/B测试观察真实表现。
第六,把线上失败样本回流到离线评测集,形成持续迭代闭环。
标准流程见下图:
下面,我们将详细拆解每一步应该做什么,读完本篇文章,你对Agent测评会有更深的理解,会了解工程场景的实践做法。
二、Agent评测是系统工程
如果面试官问你“Agent 怎么评测”,不要一上来就只讲任务准确率,这个回答的深度是不够的,并且没法体现Agent测评实践中的工程意识。
我推荐更好的回答是
Agent 评测不能只看最终结果,而应该同时评估任务完成质量、执行链路、工具调用、延迟、成本、错误率和用户反馈。因为 Agent 本质上是一个带状态、带流程、带外部依赖的执行系统,不能只看一个指标。
这个回答会比“看准确率”好很多。因为对于Agent来说,它可能先判断用户意图,再决定是否检索,是否调用工具,调用哪个工具,工具返回结果能不能用,是否需要继续执行下一步。
这时候,最终答案只是结果,中间的每个链路都可能会影响最终结果,所以需要测评多个指标,这里提供几个场景,给大家思考:
一个 Agent 最后答对了,但中间调用了 8 次模型,成本非常高,它算好吗?
一个 Agent 最后答案没错,但用户等了 3分钟,它算好吗?
一个 Agent 在测试环境表现很好,但上线后频繁因为工具超时报错,它算好吗?
三、Agent系统的测评基础:可观测性
在面试中,如果你想让面试官觉得你真的懂工程落地,就一定要提到可观测性**,**因为如果没有可观测性,很多 Agent 问题根本定位不了。
我推荐这样回答
在做 Agent 评测前,我会先保证系统具备可观测性。也就是说,要能看到一次任务从用户输入到最终输出的完整执行链路,包括每一步调用了什么模型、什么工具、耗时多少、有没有失败、有没有重试,以及最终结果是怎么生成的。
很多 Agent 框架会把一次完整运行记录成trace,把其中每个步骤记录成span。像下面这些问题,如果系统没有可观测性,基本没办法定位过程问题,也就很难优化Agent,举一些例子:
比如一次任务耗时 2分钟,你不能直接说“模型太慢了”。原因可能是检索慢,可能是工具接口慢,也可能是多个步骤没有并行执行。
比如某个版本上线后成本突然变高,不一定是用户量涨了。可能是某个环节多调用了几次 LLM,导致单次任务成本上升。
还有一种情况更常见:用户觉得不好用,但最终答案并没有明显错误。真正的问题可能是某个工具失败后没有降级处理,导致整体体验很差。
四、Agent系统测评的关键指标
在面试时,回答 Agent 的评测指标,可以按这几个维度展开:
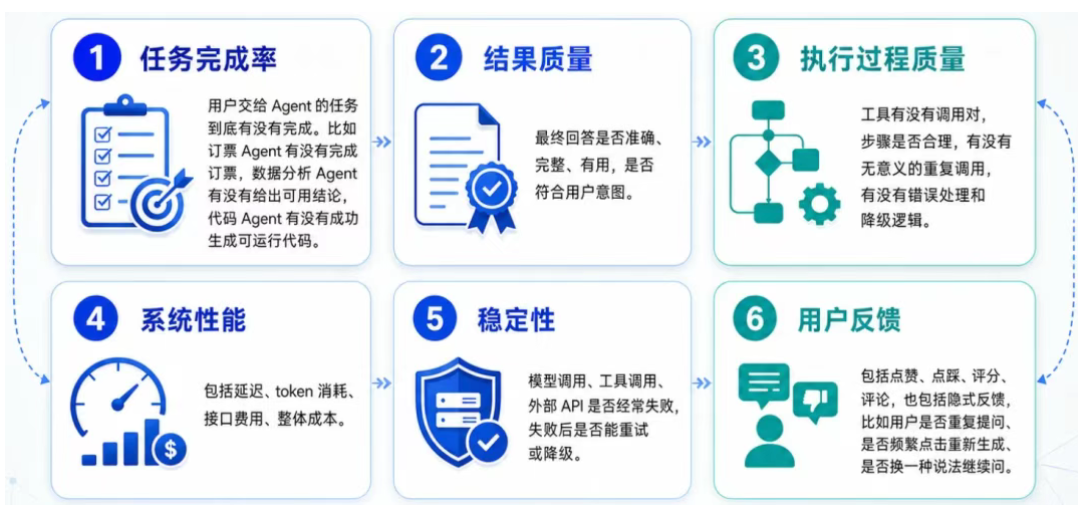
**第一,任务完成率:**用户交给 Agent 的任务到底有没有完成。比如订票 Agent 有没有完成订票,代码 Agent 有没有成功生成可运行代码。
**第二,结果质量:**最终回答是否准确、完整、有用,是否符合用户意图。
**第三,执行过程质量:**工具有没有调用对,步骤是否合理,有没有无意义的重复调用,有没有错误处理和降级逻辑。
**第四,系统性能:**包括延迟、token 消耗、接口费用、整体成本。
**第五,稳定性:**模型调用、工具调用、外部 API 是否经常失败,失败后是否能重试或降级。
**第六,用户反馈:**包括点赞、点踩、评分、评论,也包括隐式反馈,比如用户是否重复提问、是否频繁点击重新生成、是否换一种说法继续问。
推荐可以在面试里这样说,会显得更有产品意识
我不会只依赖用户的显式评分,因为用户通常不愿意主动反馈。我会结合隐式行为,比如重试、改写问题、继续追问、任务中断等,来判断 Agent 是否真的满足了用户需求
这里有一个面试加分点:隐式反馈往往比显式反馈更有用**。**因为很多用户根本不会认真点踩,也不会写评价,但如果他看完答案马上重试,或者连续换三种说法问同一个问题,这其实就是很强的负反馈,说明他对任务结果不满意。
五、离线评测:上线前先拦住明显问题
离线评测的思路是:准备一批测试数据,让 Agent 在受控环境里反复跑,对比不同版本的表现。
但要注意,Agent 的离线评测不能只准备“问题和标准答案”,还需要还要设计一部分“期望行为”,因为Agent的问题很多时候是出在中间过程,例如:
原来一次工具调用就能完成,现在变成三次。原来应该先检索再回答,现在直接开始编。原来工具失败后会降级处理,现在直接报错。
这些都是问题,但只看最终答案可能发现不了,所以你可以这样回答:
离线评测不仅要看最终答案,还要看过程指标,比如工具调用是否正确、调用次数是否异常、是否触发不必要的多轮推理、失败后是否正确重试或降级
离线评测的价值主要是两个
一是可重复。同一批测试集可以反复跑,方便比较版本变化。
二是适合接入 CI/CD。如果新版本在冒烟集或核心评测集上出现明显回归,就应该在上线前拦住。
在实践中有一个很实用的做法
准备两类评测集:一类是小型冒烟集,用来快速检查核心能力有没有坏;另一类是更大的回归评测集,用来看整体趋势。
六、在线评测:真实任务测评
在实践中,只有离线评测是肯定不够的,因为 Agent 上线之后,真实用户的问题一定比测试集复杂。
用户的问题可能更模糊,信息更少,表达更随意,所以更容易触发之前没覆盖过的边界情况。
所以面试里一定要讲在线评测,推荐你这样说
离线评测解决的是上线前的基础质量问题,但 Agent 真正的表现还要看线上,上线后需要持续观察真实流量里的任务完成率、延迟、成本、错误率、用户反馈和失败样本
在线评测能发现很多离线阶段看不到的问题,比如:
测试集里没有的新问题类型出现了;输入分布发生变化,模型表现开始漂移;某个外部工具间歇性超时,导致系统不稳定;离线分数看起来不错,但用户主观上并不满意。
七、最佳实践:离线与在线测评结合
在真正的工程实践中,Agent系统的评测是需要持续迭代的,因为 Agent 不是上线一次就结束的系统。在这个AI发展日新月异的时代,模型会变,工具会变,用户输入会变,业务场景也会变。
在面试中,推荐你这样回答,能充分体现你对生产系统的理解:
我会把 Agent 评测设计成一个闭环:上线前用离线评测拦住明显问题;上线后通过在线指标和用户反馈发现真实问题;再把线上失败样本沉淀回离线评测集,作为下一轮版本迭代的测试数据。
在实践中,一个比较完整的测评流程是:
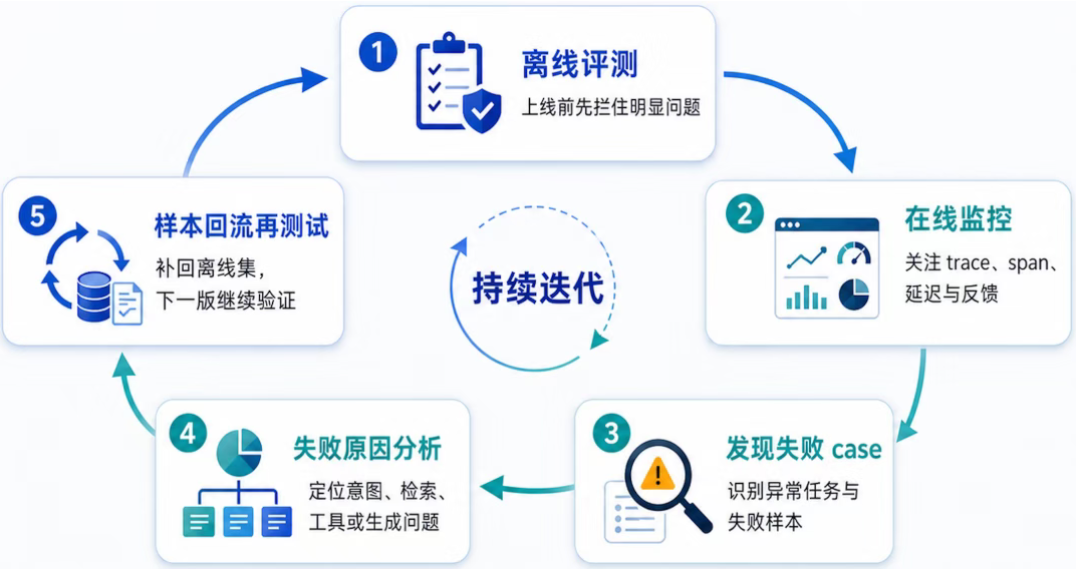
上线前,跑冒烟集和回归评测集。
上线后,监控 trace、span、延迟、成本、错误率和用户反馈。
发现失败 case 后,分析是意图理解问题、检索问题、工具调用问题,还是最终生成问题。
然后把这些失败 case 补回离线评测集。
下一版上线前,再用这些样本做回归测试。