精炼回答
在LangChain中实现流式输出主要通过streaming参数和回调机制来完成。你可以在初始化LLM时设置streaming=True,然后使用StreamingStdOutCallbackHandler或自定义回调处理器来实时处理token输出。具体实现时,创建LLM实例时传入callbacks=[StreamingStdOutCallbackHandler()],这样模型生成的每个token都会立即输出而不是等待完整响应。
对于更复杂的场景,你还可以继承BaseCallbackHandler自定义回调类,重写on_llm_new_token方法来处理每个新生成的token,比如实时更新UI界面或者将输出流式传输到前端。在使用Chain时,同样可以通过callbacks参数启用流式输出。
主要应用场景包括:聊天机器人界面需要逐字显示回复提升用户体验,长文本生成任务让用户看到实时进度避免等待焦虑,实时代码生成场景让开发者即时查看生成结果,以及需要低延迟响应的交互式应用。流式输出特别适合处理大模型的长响应时间问题,通过渐进式内容展示显著改善用户感知的响应速度。在生产环境中,结合WebSocket或Server-Sent Events可以构建真正的实时交互体验。
扩展分析
详细解释
传统的LLM调用是一个黑盒过程,用户发送请求后只能等待完整响应,就像点餐后厨师把整道菜做完才端上来。而流式输出打破了这个黑盒,让我们能够监听到生成过程中的每一个token,就像看着厨师一步步做菜的过程。这个核心机制基于观察者模式的应用,LLM在生成每个token时会触发回调事件,这些事件被注册的回调处理器捕获并处理。
LangChain在LLM的生成循环中埋了钩子,每当模型输出一个新token时,就会调用已注册的回调函数的on_llm_new_token方法。这个设计很巧妙,它没有改变LLM本身的工作方式,而是在外层包装了一个事件监听系统。你可以这样实现自定义的流式处理:
publicclassCustomStreamingHandlerextendsBaseCallbackHandler{
@Override
publicvoidonLlmNewToken(String token){
// 每个新token都会触发这个方法
System.out.print(token);
// 也可以发送到WebSocket、更新数据库等
}
@Override
publicvoidonLlmEnd(LlmResult result){
// 发送结束标记
System.out.println("\n[生成完成]");
}
@Override
publicvoidonLlmError(Exception error){
System.err.println("生成过程出现异常:"+ error.getMessage());
}
}与传统批量输出的本质区别在于数据处理模式从pull变成了push。传统方式是客户端主动拉取完整结果,而流式输出是服务端主动推送增量数据。更深层次的区别是资源利用方式的改变,流式输出允许客户端在接收数据的同时进行处理,而不是等待所有数据就绪后再开始处理。
流式输出主要解决了感知延迟问题。虽然整体生成时间可能没有显著改善,但用户的等待焦虑大大降低了。从系统角度看,它还解决了内存占用问题,特别是生成长文本时,不需要在内存中累积完整响应再返回。拿电商场景举例,当用户咨询复杂的商品对比问题时,如果AI需要生成1000字的详细分析,流式输出让用户立即看到分析开始,而不是盯着空白页面等待10秒钟。
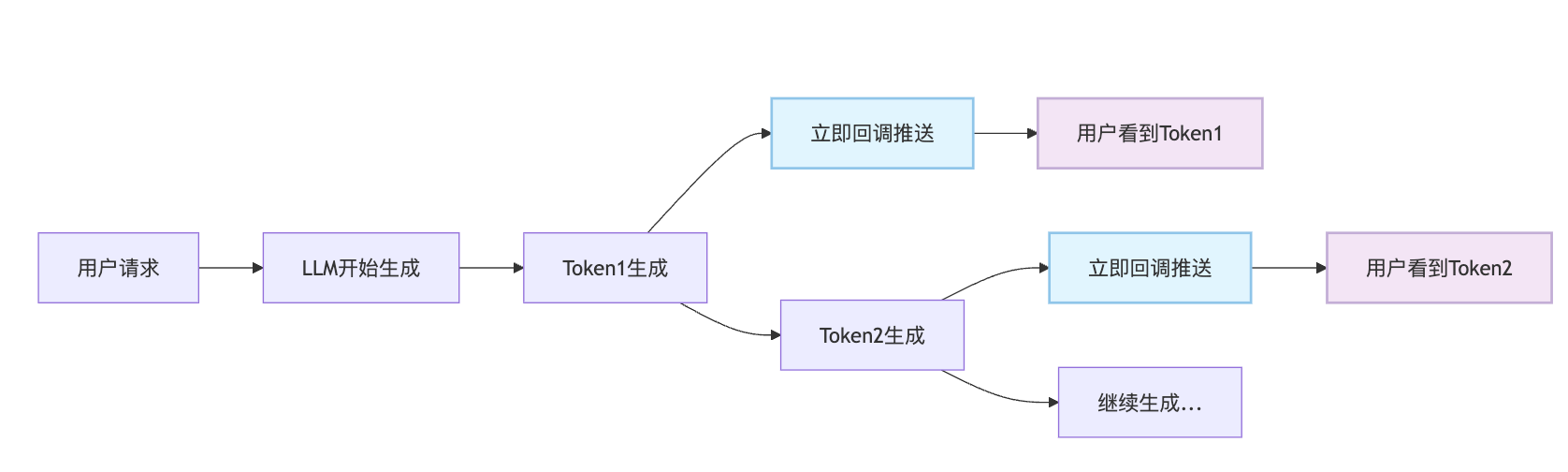
在LangChain框架中,流式输出位于LLM抽象层和应用层之间,通过回调系统将流式能力暴露给上层应用。无论是简单的Chain还是复杂的Agent,都可以通过统一的callbacks参数来启用流式输出,这种设计让流式能力具有很好的可组合性。选择不同实现方式主要看下游处理的复杂度,如果只是简单展示用标准处理器就够了,如果需要对每个token做业务逻辑处理比如实时翻译、格式化或者分发到多个渠道,就需要自定义处理器。
实践应用
真正的实战经验往往体现在细节的处理上。我来展示一个完整的聊天机器人实现,这个例子能够说明流式输出在真实业务中的应用价值。核心思路是将LangChain的流式能力与WebSocket结合,构建真正的实时交互体验:
@Component
publicclassStreamingChatService{
privatefinalObjectMapper objectMapper =newObjectMapper();
publicvoidhandleUserMessage(String userInput,WebSocketSession session){
// 创建自定义回调处理器
WebSocketStreamingHandler handler =newWebSocketStreamingHandler(session);
// 初始化LLM with streaming
ChatOpenAI llm =ChatOpenAI.builder()
.streaming(true)
.callbacks(Arrays.asList(handler))
.temperature(0.7)
.build();
try{
// 发送开始标记
sendMessage(session,newStreamMessage("",true,false));
// 执行对话
llm.predict(userInput);
}catch(Exception e){
handler.onLlmError(e);
}
}
privatevoidsendMessage(WebSocketSession session,StreamMessage message){
try{
String jsonMessage = objectMapper.writeValueAsString(message);
session.sendMessage(newTextMessage(jsonMessage));
}catch(Exception e){
log.error("Failed to send message", e);
}
}
}
publicclassWebSocketStreamingHandlerextendsBaseCallbackHandler{
privatefinalWebSocketSession session;
privatefinalObjectMapper objectMapper =newObjectMapper();
publicWebSocketStreamingHandler(WebSocketSession session){
this.session = session;
}
@Override
publicvoidonLlmNewToken(String token){
try{
// 构造实时消息
StreamMessage message =newStreamMessage(token,false,false);
String jsonMessage = objectMapper.writeValueAsString(message);
// 通过WebSocket推送到前端
session.sendMessage(newTextMessage(jsonMessage));
}catch(Exception e){
log.error("Failed to send streaming token", e);
}
}
@Override
publicvoidonLlmEnd(LlmResult result){
try{
// 发送结束标记
StreamMessage endMessage =newStreamMessage("",false,true);
String jsonMessage = objectMapper.writeValueAsString(endMessage);
session.sendMessage(newTextMessage(jsonMessage));
}catch(Exception e){
log.error("Failed to send end message", e);
}
}
@Override
publicvoidonLlmError(Exception error){
try{
StreamMessage errorMsg =newStreamMessage(
"抱歉,生成过程出现异常,请重试",
true,
true
);
String jsonMessage = objectMapper.writeValueAsString(errorMsg);
session.sendMessage(newTextMessage(jsonMessage));
}catch(IOException e){
log.error("Failed to send error message", e);
}
}
}
@Data
@AllArgsConstructor
publicclassStreamMessage{
privateString token;
privateboolean isError;
privateboolean isEnd;
}这里选择WebSocket而不是HTTP轮询,是因为流式输出需要服务端主动推送能力,WebSocket的双向通信特性正好匹配这个需求。与前端配合时,前端需要维护一个消息累积器,将接收到的token逐步拼接成完整内容,同时要处理网络断线重连的情况:
let currentMessage ='';
const websocket =newWebSocket('ws://localhost:8080/chat');
websocket.onmessage=function(event){
const data =JSON.parse(event.data);
if(data.isError){
showErrorMessage(data.token);
return;
}
if(data.isEnd){
finishTyping();
currentMessage ='';// 重置消息
}else{
currentMessage += data.token;
updateChatDisplay(currentMessage);
}
};
websocket.onclose=function(){
// 自动重连逻辑
setTimeout(()=>{
websocket =newWebSocket('ws://localhost:8080/chat');
},3000);
};生产环境部署时最关键的是连接管理和资源释放,WebSocket连接如果不正确释放会导致内存泄漏。其次是监控告警,需要跟踪每个会话的token生成速度和错误率。部署时还要考虑负载均衡的问题,WebSocket的有状态特性要求使用会话亲和性,这与传统的无状态HTTP服务有所不同。流式输出在用户体验上有明显优势,但系统资源消耗可能会略高,因为需要维护更多的连接状态,不过这个成本在用户体验敏感的场景下是完全值得的。
扩展思考
从技术发展趋势来看,流式输出代表了AI产品交互设计的发展方向,从传统的请求-响应模式向实时协作模式转变。这种变化不仅仅是技术实现层面的优化,更是用户体验设计哲学的革新。传统的AI应用往往给用户一种"黑盒"的感觉,用户提出问题后只能被动等待结果,而流式输出让用户能够"看到"AI的思考过程,这种透明度大大增强了用户对AI系统的信任感。
在实际业务场景中,这项技术的应用潜力远不止聊天机器人。实时代码生成场景下,开发者可以看到AI逐步构建代码逻辑的过程,及时发现问题并调整需求。协同文档编辑中,AI可以像人类协作者一样实时贡献内容,而不是等到完全完成后才呈现。在电商领域,商品描述生成、用户咨询解答、个性化推荐解释等场景都能从流式输出中获益。
性能优化方面需要考虑多个维度。回调函数的执行效率至关重要,不能在回调中做重计算,否则会阻塞token生成。WebSocket连接池的管理在高并发场景下需要合理控制连接数,避免资源耗尽。背压处理也是重要考虑点,当前端处理速度跟不上token生成速度时,需要有缓冲机制避免内存溢出。并发控制方面,多个用户同时使用流式对话时要注意资源竞争和隔离问题。
架构设计上,流式输出改变了整个交互模式的设计思路。前端需要考虑渐进式内容展示,包括loading状态的处理、内容格式化的时机、错误状态的展示等。后端要处理连接状态管理,包括连接的建立、维护、释放,以及异常情况下的清理工作。运维层面要监控流式传输的质量指标,比如token生成速度、连接稳定性、错误率等。这种全栈视角的考虑体现了现代AI应用开发的复杂性和系统性。
从业务价值角度看,流式输出的成本收益比在不同场景下差异很大。对于用户体验敏感的C端产品,流式输出带来的体验提升往往能够显著提高用户留存和满意度。对于B端的效率工具,实时反馈能够帮助用户更好地调整输入策略,提高工作效率。但在一些批处理场景下,流式输出的额外复杂度可能并不值得。技术选型时需要根据具体的业务需求和用户期望来权衡,而不是盲目追求技术的先进性。