精炼回答
代码重构可以部分自动化,但完全自动化很难实现。现代IDE已经支持大量自动化重构操作,比如IntelliJ IDEA的重命名变量、提取方法、内联函数、移动类等功能,这些都能在保证语义不变的前提下安全地修改代码。静态分析工具如SonarQube能自动检测代码坏味道并给出修复建议,像移除未使用的导入、简化条件表达式这类简单重构甚至可以一键完成。2025年AI辅助工具像GitHub Copilot或Cursor也能基于上下文建议重构方案,但涉及业务语义的重构AI还是会出错。
真正涉及架构层面的重构就不是工具能解决的了。比如将单体应用拆分为微服务、重新设计模块依赖关系、优化领域模型,这些需要你深刻理解业务逻辑和系统上下文,自动化工具无法替代人的判断。
优化代码结构的核心思路是降低复杂度和提高可维护性。你要消除重复代码把相似逻辑抽取成共用函数,缩短函数长度让一个函数只做一件事,降低圈复杂度减少嵌套的if-else,优化类的职责确保单一职责原则,解除不必要的耦合通过依赖注入等方式让模块间松耦合。实践中建议配合单元测试,每次重构后跑测试验证功能没被破坏,这样能放心大胆地改代码结构。记住重构是渐进式的,不要试图一次重写所有代码。
扩展分析
重构的本质与自动化边界
回答重构相关问题时,最重要的是先明确重构的本质——在不改变代码对外可见行为的前提下,改善其内部结构的过程。"不改变外部行为"这个约束条件很关键,它区分了重构和功能性修改,也解释了为什么自动化工具能介入,因为这类操作有明确的规则边界可以遵循。
IDE提供的基础重构功能本质上是做抽象语法树层面的变换。这些工具解析代码生成AST,通过模式匹配识别可重构点,然后按照预定义规则修改语法树结构,最后重新生成代码。比如IntelliJ IDEA的Extract Method功能,你选中一段代码按Alt+Shift+M,IDE会分析这段代码的输入输出依赖,自动生成合适的方法签名,并更新所有引用点。这种操作的安全性远高于手工查找替换,因为IDE能保证所有引用都被正确更新。
往上一层是静态分析工具的应用场景。SonarQube或者阿里的P3C代码规约插件能检测出代码坏味道,比如重复代码块超过6行、方法圈复杂度超过10、类之间循环依赖等。但这些工具给出的是问题清单,修复优先级需要人来判断。比如一个核心交易链路的圈复杂度问题应该优先重构,而一个临时脚本的告警可能就不值得投入精力。这种权衡判断是自动化工具做不到的。
2025年AI辅助编程工具确实带来了新可能性。Cursor或GitHub Copilot能根据上下文理解你的重构意图,甚至主动建议把相似代码抽成工具类。但AI的边界在于它不理解业务语义。比如你想把一段计算优惠金额的逻辑提取成独立方法,AI能帮你快速生成方法签名和调用点修改,但它不知道这个方法应该放在哪个类里,也不清楚参数设计是否符合团队的领域模型约定。这些决策必须由理解业务的人来做。
架构级重构就更需要人工判断了。假设要把单体应用中的用户模块拆成独立微服务,这涉及到数据库拆分、接口定义、事务边界调整、分布式会话处理等一系列决策。没有工具能自动判断"这个字段应该留在用户服务还是订单服务",因为这需要理解业务含义和未来演进方向。架构重构本质是在做权衡取舍,比如拆分后性能可能下降但独立部署能力增强,这些trade-off只能靠人结合业务场景来决策。
优化代码结构的系统方法
谈到优化方法时,你需要展现系统性的思考框架而不是背诵设计原则。拿单一职责原则来说,实践中的识别过程是这样的:当你看到一个类既负责数据校验、又做格式转换、还要记录日志时,就知道它职责不单一了。这时候应该把三类操作分别提取到Validator、Converter和Logger里,让每个类只因一种原因而修改。
// 重构前:职责混杂的God Class
publicclassOrderProcessor{
privateLogger logger =LoggerFactory.getLogger(OrderProcessor.class);
publicvoidprocess(Order order){
// 校验逻辑混在一起
if(order.getAmount()<=0){
thrownewIllegalArgumentException("订单金额必须大于0");
}
if(order.getUserId()==null){
thrownewIllegalArgumentException("用户ID不能为空");
}
if(order.getItems().isEmpty()){
thrownewIllegalArgumentException("订单商品不能为空");
}
// 格式转换逻辑
String json =String.format("{\"orderId\":\"%s\",\"amount\":%s,\"userId\":\"%s\"}",
order.getId(), order.getAmount(), order.getUserId());
// 日志记录逻辑
logger.info("开始处理订单: "+ json);
// 实际处理逻辑
saveToDatabase(order);
logger.info("订单处理完成: "+ order.getId());
}
privatevoidsaveToDatabase(Order order){
// 数据库操作
}
}
这个类的问题很明显,未来如果要修改校验规则、调整日志格式、更换JSON序列化方式,都要改这一个类,违反了单一职责原则。重构后的结构应该是这样:
// 重构后:职责分离,各司其职
publicclassOrderProcessor{
privatefinalOrderValidator validator;
privatefinalOrderLogger orderLogger;
privatefinalOrderRepository repository;
publicOrderProcessor(OrderValidator validator,
OrderLogger orderLogger,
OrderRepository repository){
this.validator = validator;
this.orderLogger = orderLogger;
this.repository = repository;
}
publicvoidprocess(Order order){
validator.validate(order);
orderLogger.logProcessing(order);
repository.save(order);
orderLogger.logCompleted(order);
}
}
// 校验职责独立出来
publicclassOrderValidator{
publicvoidvalidate(Order order){
if(order.getAmount()<=0){
thrownewIllegalArgumentException("订单金额必须大于0");
}
if(order.getUserId()==null){
thrownewIllegalArgumentException("用户ID不能为空");
}
if(order.getItems().isEmpty()){
thrownewIllegalArgumentException("订单商品不能为空");
}
}
}
// 日志职责独立出来
publicclassOrderLogger{
privatefinalLogger logger =LoggerFactory.getLogger(OrderLogger.class);
privatefinalObjectMapper objectMapper =newObjectMapper();
publicvoidlogProcessing(Order order){
try{
String json = objectMapper.writeValueAsString(order);
logger.info("开始处理订单: {}", json);
}catch(JsonProcessingException e){
logger.error("订单序列化失败", e);
}
}
publicvoidlogCompleted(Order order){
logger.info("订单处理完成: {}", order.getId());
}
}
重构后的代码不仅职责清晰,可测试性也大幅提升。现在你可以单独Mock OrderValidator来测试校验逻辑,而不用真的去执行数据库保存操作。这种改进在面试中展示出来,比空谈SOLID原则有说服力得多。
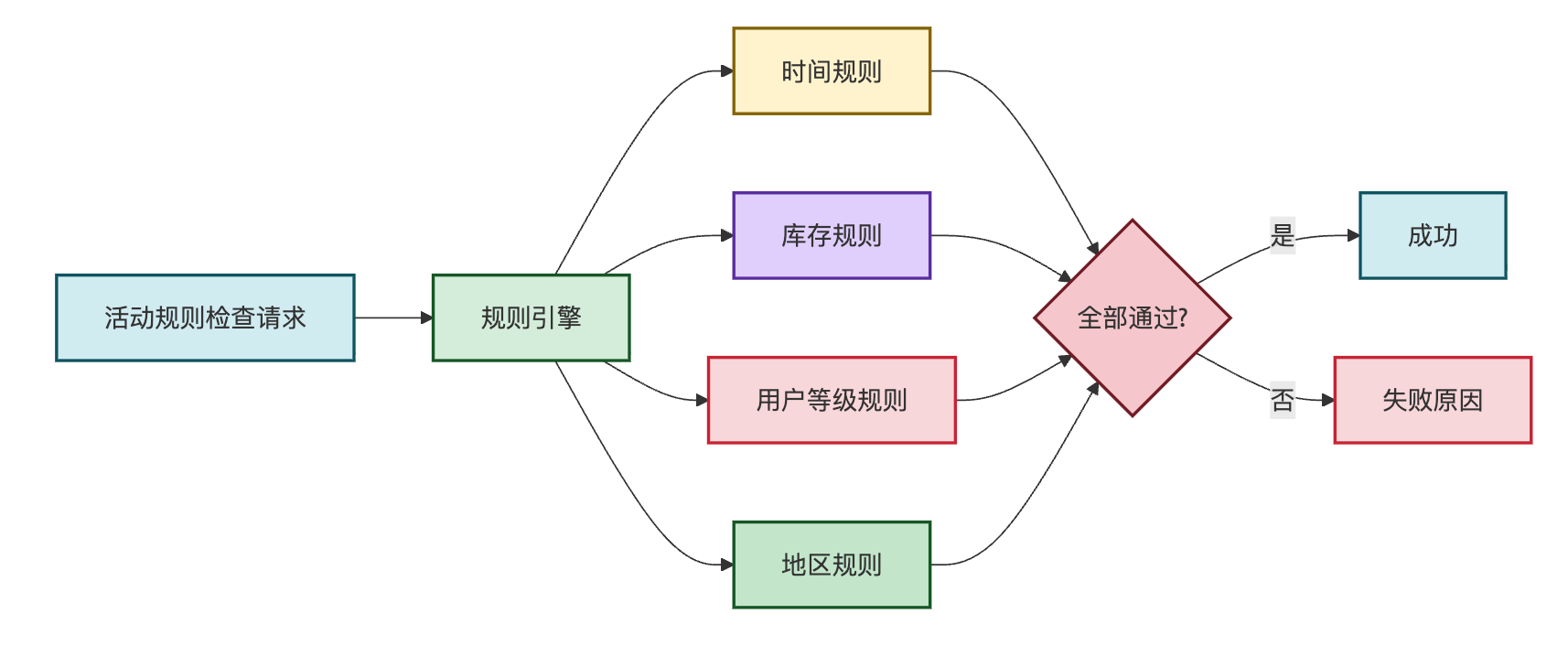
降低圈复杂度是另一个常见的优化方向。当一个方法里嵌套了多层if-else时,代码读起来就像走迷宫。实际项目中经常遇到的场景是活动规则判断,最初可能所有规则都堆在一个方法里:
// 重构前:复杂的条件判断,圈复杂度很高
publicclassActivityRuleChecker{
publicbooleancheck(Activity activity,User user){
if(activity.getStartTime().isAfter(LocalDateTime.now())){
returnfalse;
}
if(activity.getEndTime().isBefore(LocalDateTime.now())){
returnfalse;
}
if(activity.getStock()<=0){
returnfalse;
}
if(user.getLevel()< activity.getRequiredLevel()){
returnfalse;
}
if(!activity.getAllowedRegions().contains(user.getRegion())){
returnfalse;
}
// 可能还有十几个判断条件...
returntrue;
}
}
这种代码的问题是扩展性差,每次新增规则都要修改这个方法,而且测试覆盖所有分支组合的成本非常高。重构思路是引入策略模式或责任链模式,把每个规则封装成独立的类:
// 重构后:使用策略模式,每个规则独立维护
publicinterfaceActivityRule{
booleancheck(Activity activity,User user);
StringgetFailureReason();
}
publicclassTimeRuleimplementsActivityRule{
@Override
publicbooleancheck(Activity activity,User user){
LocalDateTime now =LocalDateTime.now();
return!activity.getStartTime().isAfter(now)
&&!activity.getEndTime().isBefore(now);
}
@Override
publicStringgetFailureReason(){
return"活动不在有效时间范围内";
}
}
publicclassStockRuleimplementsActivityRule{
@Override
publicbooleancheck(Activity activity,User user){
return activity.getStock()>0;
}
@Override
publicStringgetFailureReason(){
return"活动库存不足";
}
}
publicclassUserLevelRuleimplementsActivityRule{
@Override
publicbooleancheck(Activity activity,User user){
return user.getLevel()>= activity.getRequiredLevel();
}
@Override
publicStringgetFailureReason(){
return"用户等级不满足活动要求";
}
}
// 规则引擎负责组织规则执行
publicclassActivityRuleEngine{
privatefinalList<ActivityRule> rules;
publicActivityRuleEngine(List<ActivityRule> rules){
this.rules = rules;
}
publicCheckResultcheckAll(Activity activity,User user){
for(ActivityRule rule : rules){
if(!rule.check(activity, user)){
returnCheckResult.fail(rule.getFailureReason());
}
}
returnCheckResult.success();
}
}
这种重构让代码从1500行的God Class拆分成多个不到100行的小类,每个类只负责一个规则的判断。新增规则时只需要添加新的Rule实现类,符合开闭原则。我之前重构一个促销模块时采用这种方式,重构后新增一个会员日规则只花了20分钟,而之前类似改动至少要半天,因为要小心翼翼地在巨大的if-else堆里找插入点。
消除重复代码是优化中最常见也最容易被忽视的点。很多人觉得复制粘贴几行代码无所谓,但技术债就是这样累积起来的。遵循"三次法则"是个好习惯——第一次写功能直接实现,第二次遇到类似需求时会注意到重复,第三次再出现就必须重构了。这样既避免了过度设计,也不至于让技术债累积太多。
工作流程与风险控制
实际项目中重构的工作流程比技术细节更重要。日常开发中如果感觉某段代码读起来费劲,我会先跑一遍SonarQube或者P3C插件,看看工具能识别出哪些具体问题。假设扫出来说某个方法圈复杂度是18,远超建议的10,我不会立刻动手改,而是先分析这个方法在系统中的位置。如果是核心交易链路就会优先处理,如果是个边缘功能可能就加个TODO标记先放着。
确定要改之后,关键动作是先补充单元测试,把当前行为固定下来。很多人容易忽略这步直接动手改代码,结果改完发现功能有变化却说不清是哪里出了问题。我的习惯是把测试覆盖率提升到80%以上再开始重构,这样每次改完跑一遍测试就能立刻知道有没有破坏原有功能。Git提交信息也会明确标注'refactor',方便后续追溯问题时区分重构改动和功能改动。
小步快跑是另一个重要原则。团队应该约定重构必须拆成小的PR提交,每个PR只解决一个代码坏味道,而不是一次重写整个模块。这种方式有两个好处:一是方便代码审查,审查者能清楚看到每次改动的意图;二是出问题容易回滚,不会牵连其他改动。配置持续集成也是必须的,每次提交都会跑全量单元测试和集成测试,测试通过才能合并。
工具选型要根据重构范围来决定。处理局部方法级别的重构时,IDE自带的Refactor菜单基本够用,快捷键Alt+Shift+M提取方法、Shift+F6重命名,这些操作安全可靠,会自动更新所有引用点。当代码库已经积累了大量技术债,需要系统性识别问题时,静态分析工具就派上用场了。2025年AI工具已经成为日常开发的一部分,GitHub Copilot或Cursor能在重构时提供上下文感知的建议,但我会把AI建议当参考而不是直接采纳,特别是涉及业务逻辑的修改。
避坑经验往往最能展现工程成熟度。过度重构是个常见陷阱,我之前重构一个工具类时为了追求设计模式的优雅,引入了抽象工厂和建造者模式,结果代码从50行膨胀到200行,后来团队Review时被批评过度设计了。另一个坑是无测试重构,我见过有同事直接改核心代码没跑测试就上线,结果引发线上故障,这让我深刻认识到测试保护的重要性。
最现实的冲突是重构与业务需求的优先级博弈。产品经理催需求时你还坚持重构吗?我的做法是评估技术债的影响范围,如果不重构会阻碍后续需求开发,就会找产品沟通争取时间;如果只是局部代码不够优雅但不影响交付,就会在需求迭代中顺手改掉,而不是单独申请重构任务。这种务实态度比坚持技术纯粹性更可持续。
价值衡量与团队协作
证明重构的价值是个很实际的问题。产品经理不会因为代码更优雅就批准你延期上线,你得学会用业务语言说话。我之前重构一个促销模块的案例可以说明这点:原来的代码因为耦合严重,每次改需求都要三天,重构后拆成独立的规则引擎,同类需求缩短到半天,三个月节省的开发时间足够抵消重构投入。这种量化的ROI说明比谈代码美学更有说服力。
技术债务管理需要系统思考。成熟的工程师不会把重构当成单独任务,而是融入日常开发节奏。童子军规则是个好习惯——每次修改代码时让它比你接手时更干净一点,这种渐进式改进比集中重构更可持续。团队层面可以建立机制,比如每个迭代预留20%时间处理技术债,或者在CodeReview环节专门关注可维护性问题。
从更高维度看,重构是持续的开发习惯而不是单独的项目阶段。我在日常开发中会随时进行小规模重构,比如提交代码前花五分钟清理一下命名、合并重复逻辑。这比等到代码腐化严重了再做大规模重写要健康得多。准备好完整的重构案例对面试很有帮助,案例应该包含四个部分:重构前的痛点是什么、选择哪种重构策略、具体怎么推进的、最终效果如何验证。
AI工具的发展确实给重构带来了新可能。大模型现在不仅能生成代码,还能理解代码意图、识别设计缺陷。可以用Claude或GPT-4来分析遗留代码的逻辑让它生成重构建议,但要验证AI的判断而不是盲目采纳。有些团队已经在探索用Agent自动执行低风险重构,比如定期扫描代码库中的魔法数字、过长的参数列表这类明确的坏味道。不过人机协作的边界要清楚——AI擅长模式识别和机械重构,人负责业务语义判断和架构决策,这种分工才是合理的。