精炼回答
代码性能优化可以部分自动化,但完全自动化很难实现。现代编译器能做循环展开、内联优化、死代码消除等基础优化,IDE和静态分析工具也能检测出明显的性能问题,比如N+1查询、不必要的对象创建等。但复杂的架构问题、算法选择、业务逻辑优化还是需要人工介入。
识别性能瓶颈要先测量再优化。你可以用profiler工具来定位热点代码,像Java用JProfiler或VisualVM,Python用cProfile,前端用Chrome DevTools的Performance面板。这些工具能告诉你哪个函数耗时最长、内存分配在哪里。对于线上系统,APM工具如Prometheus、Skywalking能持续监控接口响应时间和资源使用情况。
定位到瓶颈后就针对性优化:CPU密集型问题看算法复杂度,比如把O(n²)改成O(n log n);IO密集型问题加缓存、批量处理或异步化;内存问题检查是否有对象池复用的空间,或者优化数据结构减少内存占用;数据库慢就看索引、SQL执行计划,必要时做分库分表。记住一点,过早优化是万恶之源,你得先通过实际数据证明某段代码确实是瓶颈,再动手改。
扩展分析
自动化的边界与人机协同
性能优化能不能自动化,这个问题的答案其实藏在技术的层次结构里。编译器层面的优化是完全透明的,比如Java的JIT会在运行时把热点代码编译成机器码,GCC的-O2、-O3优化级别能做指令重排和循环展开,这些都不需要开发者介入。你写的代码在编译器眼里就是一堆可以重组的指令,它会自动选择最优的执行路径。但这种优化有个天然的限制,就是只能在局部范围内生效,编译器看不到你的业务逻辑,也不知道哪些数据会被高频访问。
往上一层是工具辅助优化,这个阶段需要人机协同。静态分析工具比如SonarQube能标记出明显的性能坏味道,像在循环里创建数据库连接、字符串拼接用加号而不是StringBuilder这些。IntelliJ IDEA还会实时提示你哪里有不必要的装箱操作,哪个集合遍历可以改成Stream API提升可读性。但这些工具只能发现模式化的问题,它们不理解业务语义。比如一个查询在工具看来可能很慢,但如果它一天只执行一次且在凌晨跑批时运行,优化的优先级就应该很低。
最高层是架构决策级的优化,这完全依赖工程经验。该用缓存还是异步、算法复杂度要不要重构、要不要引入消息队列削峰填谷,这些决策背后都是对业务特性的深刻理解。我之前遇到过一个典型案例,当时压测发现接口响应慢,团队立刻想到要优化代码,但用JProfiler一分析才发现不是计算密集,而是数据库索引没建好。这种问题自动化工具很难发现,因为它需要结合业务流量特征和数据分布来判断。
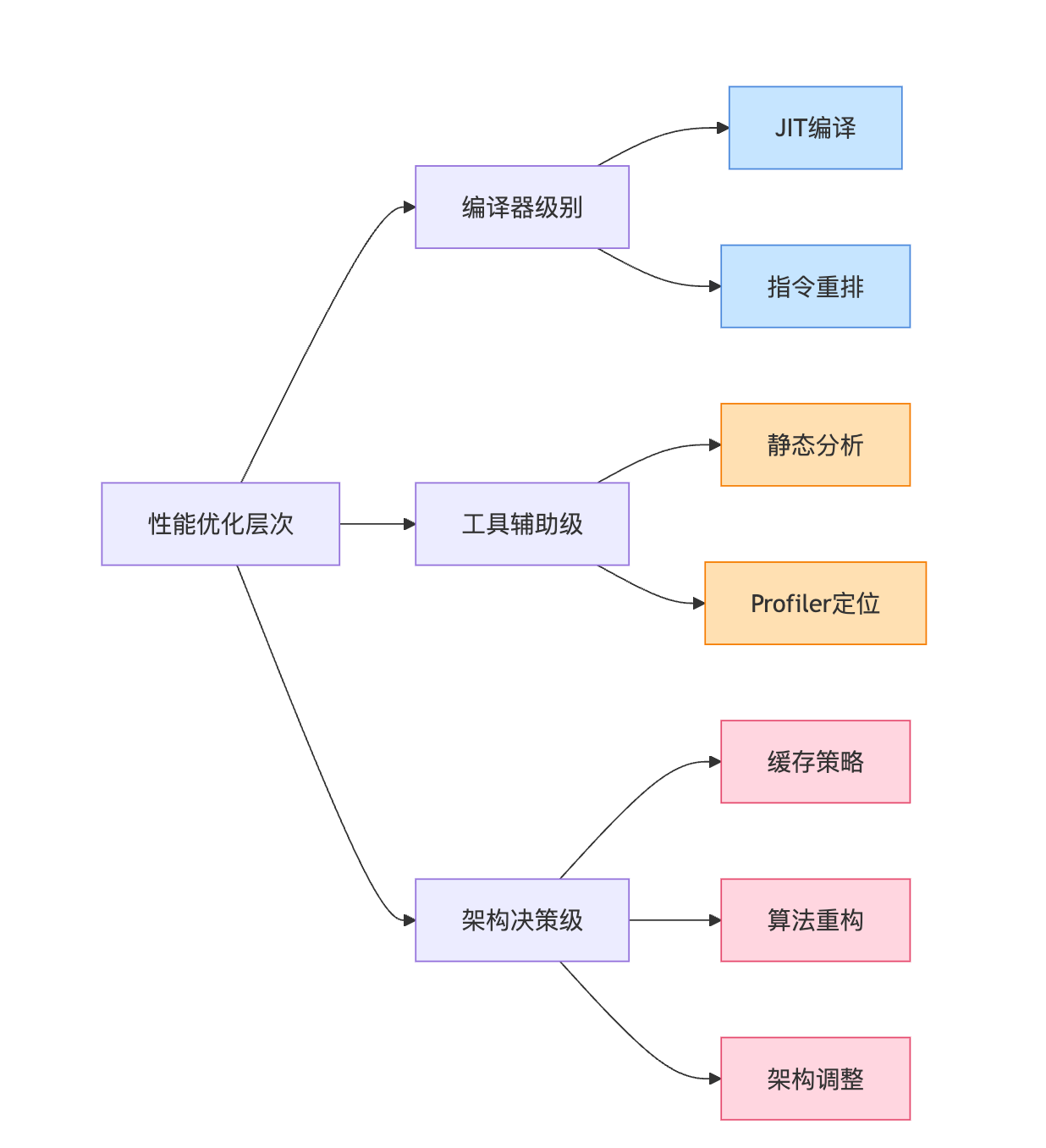
2025年AI辅助优化已经开始崭露头角,像GitHub Copilot这类工具能基于代码上下文提供优化建议,甚至能识别出某个循环可以用并行流处理、某个递归可以改成尾递归优化。但这些建议需要你结合实际场景判断是否适用。比如它建议用缓存,你得评估缓存一致性对业务的影响;它建议改算法,你得评估改造成本和收益比。所以性能优化的本质还是工程权衡,不是工具能自动决策的。
识别瓶颈的方法论
很多人优化性能的第一步就错了,他们凭感觉觉得某段代码慢就去改,结果改完发现整体性能提升不到1%。正确的做法是建立完整的性能指标体系,然后用数据说话。响应时间不能只看平均值,因为平均值会被极端值误导,你得看P50、P95、P99这些分位值。我之前遇到过一个接口P50只有50ms,看起来很健康,但P99能到2秒,后来发现是GC导致的长尾延迟,调整了堆参数后P99降到了200ms。
吞吐量要和资源利用率结合看,如果CPU已经打满但吞吐量还不够,说明需要优化算法而不是加机器。并发能力不只是看能接多少请求,还要看在高并发下错误率和响应时间的劣化程度。有些系统在低并发时表现很好,但一到高峰期就开始出现大量超时,这往往是线程池配置不合理或者锁竞争导致的。
定位瓶颈有两种策略,要根据场景灵活选择。自顶向下的策略适合线上问题排查,你从用户侧的慢开始往下追,先看APM的链路追踪发现是哪个服务慢,再看那个服务的哪个接口慢,最后定位到具体代码行。自底向上的策略更适合新功能上线前的性能摸底,你用压测工具逐步加压,观察在什么并发量下系统开始出现性能拐点,然后用profiler看那个拐点时的资源瓶颈在哪里。
具体到工具的选择,要按照问题发现的时间维度来组织。开发阶段用IDE的内置分析器快速发现明显问题,测试阶段用JMeter或Gatling做压力测试建立性能基线,预发布环境用JProfiler或Go的pprof做深度的CPU和内存分析,线上用Prometheus采集指标、Skywalking做分布式链路追踪。不同工具的开销也不一样,像JProfiler这种会对性能有一定影响,只适合在非生产环境用;Prometheus的埋点成本低,可以常驻在生产环境。

从现象到根因的分析路径需要结构化思维。如果监控显示接口响应时间突然变慢,首先看监控大盘确认影响面,是所有接口慢还是个别接口,是所有用户慢还是特定地域。然后下钻到具体接口的指标,看CPU、内存、数据库连接数这些资源指标有没有异常。接着用链路追踪定位到慢在哪个依赖服务或数据库查询上。最后拿着代码和SQL执行计划做假设验证,比如怀疑是索引失效就用EXPLAIN看执行计划,怀疑是锁竞争就看thread dump。这个分析过程要像讲故事一样流畅,每一步都有明确的判断依据。
实战中的优化手段
说到具体优化,我印象最深的是处理过一个支付页面加载慢的案例。用户反馈页面加载很慢,我先从用户视角确认问题,打开浏览器的Network面板看到主接口耗时3秒,但奇怪的是静态资源加载都正常。这时候不要急着看代码,先去APM平台看链路追踪,发现这3秒里有2.5秒都卡在一个查询用户订单历史的数据库调用上。拿到慢查询SQL后用EXPLAIN分析执行计划,发现查询条件里的时间范围字段没有索引,导致全表扫描了几百万条记录。加上索引后接口响应降到200ms,但我评估了这个索引会增加10%的写入耗时,考虑到读写比是100:1,这个代价是可以接受的。
批处理任务的优化则是另一种思路。有个每天凌晨跑的对账任务,原来需要4小时才能处理完,严重影响早上的业务。我先用火焰图看了下CPU热点,发现不是计算密集而是大量时间花在等待数据库返回上。分析代码后发现是在循环里逐条查询订单详情,典型的N+1问题。优化方案是先批量查出所有需要的订单ID,然后用IN查询一次性拿回来,这样把3000次数据库往返降到30次。改完后任务耗时降到40分钟,但批量大小不能无限大,我控制每批最多1000条,因为MySQL的IN条件太多会导致执行计划不稳定。
// 优化前:典型的N+1查询模式
publicvoidprocessOrders(List<String> orderIds){
for(String orderId : orderIds){
Order order = orderDAO.getById(orderId);// 每次都查数据库
reconcile(order);
}
}
// 优化后:批量查询,控制批次大小
publicvoidprocessOrders(List<String> orderIds){
List<String> batch =newArrayList<>();
for(String orderId : orderIds){
batch.add(orderId);
if(batch.size()>=1000){
List<Order> orders = orderDAO.getByIds(batch);// 批量查询
orders.forEach(this::reconcile);
batch.clear();
}
}
// 处理剩余的订单
if(!batch.isEmpty()){
List<Order> orders = orderDAO.getByIds(batch);
orders.forEach(this::reconcile);
}
}
java缓存优化是性能提升最明显的手段之一,但关键是要设计合理的缓存层次。我一般会用三层缓存策略:本地缓存用Caffeine访问耗时小于1ms,分布式缓存用Redis访问耗时小于5ms,最后才查数据库访问耗时50-200ms。这样设计后接口P99延迟从200ms降到3ms,数据库QPS从5000降到50,节省了90%的数据库连接资源。但要注意缓存一致性问题,用户修改资料后要主动清理缓存,避免读到脏数据。
@Service
publicclassUserProfileService{
@Cacheable(value ="userProfile", key ="#userId")
publicUserProfilegetUserProfile(String userId){
// 本地缓存命中率约70%
UserProfile cached = localCache.getIfPresent(userId);
if(cached !=null)return cached;
// Redis缓存命中率约25%
cached = redisCache.get("profile:"+ userId,UserProfile.class);
if(cached !=null){
localCache.put(userId, cached);
return cached;
}
// 数据库查询占比约5%
User user = userDAO.getById(userId);
Integer orderCount = orderDAO.countByUserId(userId);
UserProfile profile =newUserProfile(user, orderCount);
redisCache.set("profile:"+ userId, profile,300);// 缓存5分钟
localCache.put(userId, profile);
return profile;
}
}
监控埋点是线上问题排查的基础设施,我一般会用Micrometer来做性能指标采集,它能无缝集成到Spring Boot和Prometheus。埋点时要特别关注P50、P95、P99这些分位值,因为它们能反映真实的用户体验。如果某天发现P99突然从100ms涨到2秒,就能立刻触发告警。关键是这些指标采集的开销很低,对业务代码几乎没有侵入性。
优化的优先级与工程权衡
性能优化最容易犯的错误是过早优化和盲目优化。很多人还没搞清楚瓶颈在哪就开始改代码,结果发现改完性能没提升反而引入了bug。真正有效的优化遵循二八定律,80%的性能问题往往集中在20%的代码路径上。我会先用APM看接口调用量分布,找出TOP10的高频接口,然后看这些接口里哪些P99延迟高,这些才是优化的重点。有些接口虽然慢但一天只调用几次,优化它的投入产出比太低。
ROI评估能力是大厂最看重的软实力之一。我会先估算优化能节省多少资源成本,比如把某个接口从200ms优化到50ms,按日调用量1000万次计算,能节省大约40台服务器。然后评估改造成本,如果需要重构核心链路可能要2个人月,那这个投入产出比就很划算。但如果只是优化一个低频接口,哪怕能优化50%,但节省的资源折算下来一年才几千块,那就不值得投入人力。我见过有团队花一周时间优化一个管理后台的查询,把响应时间从2秒降到500ms,但这个功能一天就几个运营人员用,完全是浪费精力。
优化还要警惕局部优化导致全局恶化。比如为了加快单次查询速度加了一堆索引,结果写入性能下降了30%。或者为了降低接口响应时间引入了异步处理,但异步队列的积压监控没做好,导致部分消息丢失影响了业务正确性。还有个常见的坑是工具本身的开销,像JProfiler这种重量级工具会让程序慢几倍,你在它的环境里看到的热点可能在生产环境根本不是问题。
自动化集成要结合CI/CD流程来做。我们会在CI阶段集成JMH做微基准测试,每次代码提交都会跑核心接口的性能基准,如果响应时间比基线慢20%就会阻断合并。这个阈值不能设太严,因为代码改动本身可能就需要付出一些性能代价,关键是让团队意识到性能劣化。预发布环境会用JMeter做全链路压测,模拟生产环境的流量模型,这个数据会作为上线评审的重要依据。现在有些团队开始用大模型来分析监控指标的异常模式,比如它能识别出某个接口在特定时间段流量激增但响应时间稳定,这种情况下不需要告警;但如果流量没变响应时间突然劣化,那就要立刻通知。这比传统的静态阈值告警更智能,能减少很多误报。
最后要强调的是,性能优化不是炫技,而是在资源约束下做出最优解的能力。真正有效的优化是建立性能意识,在写代码的时候就考虑复杂度,在设计架构的时候就预留扩展空间。工具只能告诉你现象,比如这个函数占用了80%的CPU时间,但它不知道这个函数是不是必须这么复杂,有没有更好的算法能替代。所以性能优化的本质是人机协同,编译器负责底层优化,工具负责辅助发现问题,但架构层面的决策还得靠人的判断和经验。