精炼回答
AI编程工具的开源替代品主要包括Continue(支持多种LLM的IDE插件)、Tabby(自托管的代码补全服务)、CodeGeeX(清华开源的代码生成模型)、StarCoder(Hugging Face的代码大模型)、Fauxpilot(Copilot的开源实现)等。这些工具可以部署在本地或私有云,数据完全可控。
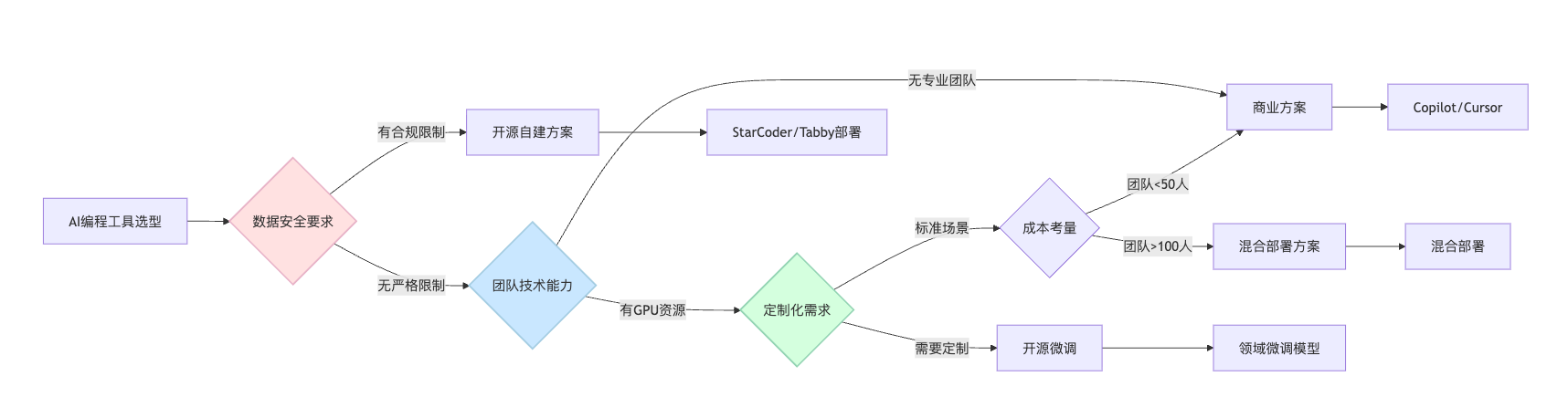
选择方案时核心看三个维度。首先是数据安全性,如果你处理的是金融、医疗等敏感代码,开源方案部署在内网是更安全的选择,商业方案即使承诺不训练你的数据,代码仍需上传到他们服务器。其次看团队技术能力,开源方案需要自己搭建、维护、调优模型,还要处理GPU资源调度,没有专门的运维和算力资源会很吃力;商业方案开箱即用,但长期成本可能更高。最后是效果要求,GitHub Copilot、Cursor这类商业产品在代码补全准确率和上下文理解上确实领先,特别是使用了GPT-4或Claude的场景,开源模型需要在特定领域fine-tune才能接近。
我的建议是,初创团队或个人开发者直接用商业方案,企业内部有合规要求就选开源自建,如果预算充足也可以考虑商业产品的私有化部署版本,兼顾效果和安全。
扩展分析
面对这个问题时千万别急着罗列工具清单,真正要展示的是你对技术选型的系统性思考能力。开源AI编程工具我倾向于按交互模式来分类,因为这直接决定了集成成本和使用体验。
嵌入式补全工具像Tabby和FauxPilot,它们的特点是在你敲代码时实时提示下一段代码。技术上依赖Fill-in-the-Middle模型架构,需要极低的延迟,一般要求推理时间控制在200ms以内。这类工具部署时最大的挑战是GPU资源调度,如果团队只有几十个开发者,用单张A10就能跑起来,但上百人规模就需要考虑模型服务的横向扩展。我见过有团队用StarCoder部署了代码补全服务,结果高峰期推理队列积压,开发者等3秒才能看到提示,体验还不如不用。
对话式代码生成工具以Continue为代表,它本质上是个LLM的适配器,可以接入OpenAI、Claude、本地部署的Llama,甚至你自己微调的模型。这种设计让你有灵活的降级策略,比如敏感项目用本地模型,通用需求调API。Continue支持上下文索引,能把整个代码仓库向量化,这样生成的代码会更符合你的项目风格。
自托管的完整平台像CodeGeeX和StarCoder不只是模型,还包括代码索引、向量检索、Fine-tuning的Pipeline。StarCoder的优势是训练数据透明,你能看到它在哪些开源项目上训练的,这对评估代码许可证风险很重要。而且Hugging Face提供了完整的Fine-tuning脚本,如果你们有内部代码库,可以用LoRA做领域适配。Fine-tuning一个15B参数的模型,用4张A100大概需要半天时间。
商业方案和开源方案的核心差距不在模型能力,而在工程化成熟度。GitHub Copilot背后不只是Codex模型,还有海量的Telemetry数据在持续优化。它知道用户在什么场景下接受了建议、什么时候拒绝了,这些反馈循环是开源工具很难复制的。假设你在开发支付系统,代码里会包含风控规则、限额配置这些业务逻辑。即使GitHub承诺数据不留存,但代码片段在网络传输中就有泄露风险,这时候开源方案部署在内网是唯一选择。
成本结构也要算清楚。商业产品看起来是按人头付费,比如Copilot每人每月10美元,但如果团队规模上百人,一年就是十几万成本。开源方案前期投入大,需要买GPU、配运维,但边际成本低。如果团队有100个开发者,用商业方案年成本大概12万美元,自建的话前期硬件投入可能要5万美元,加上一个专职运维,总成本第一年会持平,第二年开始自建更划算。当然这个账要算上机会成本,如果因为自建导致工具延迟上线,影响了研发效率,那反而得不偿失。
我习惯用决策树的方式做选型。第一个节点是合规要求,如果你的行业有数据出境限制,或者代码属于商业机密,那直接走开源分支,连评估商业方案的必要都没有。第二个节点是团队能力,开源方案不是部署完就结束了,后续需要持续维护。模型服务挂了要能快速定位,推理速度慢了要会做量化优化,效果不好要懂得收集badcase做Fine-tuning。如果团队没有专门的AI工程师,或者运维团队对GPU调度不熟悉,那就别给自己挖坑。第三个节点是定制化需求,如果你们的技术栈比较小众,或者有大量内部框架,开源方案的价值就凸显出来。比如你们用自研的RPC框架,商业产品的代码补全根本不认识这些API,但你可以用公司内部代码Fine-tune一个StarCoder,让它学会你们的编码规范和常用模式。
不同企业阶段的选型策略要结合实际情况。创业公司阶段人少事多,核心是快速验证产品,别在工具上浪费时间。直接给每个开发者买Copilot或者Cursor,每人每月几十块钱的成本完全可以接受。等团队到50人以上,代码库积累到一定规模,再考虑自建。成长期企业通常团队规模几百人,有了专门的基础架构团队,代码安全开始成为关注点。这时候可以考虑混合方案,比如通用场景用商业产品,核心业务代码用开源工具。具体来说,前端代码、测试代码这些可以用GitHub Copilot,因为敏感度低,商业产品效果好。后端的订单、支付、用户相关代码,部署一套Continue接本地模型,数据不出内网。大型企业通常有严格的安全审计要求,所有代码工具都需要走采购流程。这时候即使选商业方案,也倾向于要私有化部署版本,比如GitHub Copilot for Business的企业版,数据可以留在你的VPC里。当然成本会高很多,可能是SaaS版本的3-5倍,但这是满足合规的必要投入。
实战落地
我之前在评估AI编程工具的时候走过一些弯路,后来总结出一套比较实用的评估流程。先做POC验证可行性,再算成本模型看投入产出比,最后做灰度验证看实际效果。具体到可行性验证这一步,我会先在单个项目上试跑一周,重点看三个数据:推理延迟要在500ms以内,因为超过这个阈值开发者就会感觉卡顿;代码接受率至少要到30%,也就是AI给10条建议你能用3条,低于这个比例说明模型效果不行;还有就是系统稳定性,一周内服务可用率要达到99%以上。
假设一个20人的技术团队,主要做Web应用开发,代码库以Java和TypeScript为主。这种情况我会直接推荐用Cursor或者GitHub Copilot,理由很简单,团队没有专职运维,也没有GPU资源,自建开源方案的人力成本远高于工具费用。而且初创公司代码迭代快,商业产品的代码补全对常见框架支持更好,能直接提升效率。唯一要注意的是,如果代码里包含核心算法或者商业机密,要在IDE配置里把这些文件路径加到排除列表,避免敏感代码被发送到云端。
中型团队的案例要体现混合架构的思路。我见过一个200人规模的研发团队,他们的做法是分场景选型。移动端代码和前端代码用GitHub Copilot,因为这部分代码敏感度低,商业产品的效果优势明显。但后端的支付、风控这些核心模块,他们部署了Tabby接本地的CodeLlama模型,推理服务跑在内网的4张T4卡上。这个方案的好处是,开发者用同一个IDE插件,底层根据项目路径自动路由到不同的模型服务。他们在GitLab的CI配置里维护了一个敏感项目清单,IDE启动时会拉取这个配置,匹配到敏感项目就切到内网模型。
金融或政务行业的选型逻辑完全不一样,数据安全是一票否决项。我了解到一个银行的案例,他们最终选择了StarCoder做私有化部署,还专门用内部的代码库做了Fine-tuning。这个决策背后的考量是,银行内部有大量自研的中间件和框架,比如分布式事务管理、消息队列的封装,这些代码模式在公开训练集里根本没有。他们用LoRA方法在内部代码上微调了一个月,让模型学会了这些特定的编程范式,最终代码接受率从20%提升到45%。
谈到从商业方案迁移到开源方案,这个迁移不是简单的工具替换,最大的挑战是开发者习惯的改变。如果团队之前用GitHub Copilot用了一年,开发者已经习惯了它的代码风格和提示逻辑。突然换成开源模型,即使客观效果只差10%,主观感受可能会觉得差了50%。比较稳妥的做法是先做AB测试,让20%的开发者试用开源方案,收集他们的反馈并持续优化模型。同时要做好预期管理,明确告诉团队这是出于数据安全考虑的必要迁移,不是为了省钱。
很多团队容易犯的错误是高估自己的技术能力,觉得开源方案就是下载个模型跑起来这么简单。实际上模型部署只是第一步,后续的监控、优化、故障处理都需要专业能力。我见过有团队部署了CodeGeeX,结果模型推理速度慢,他们不知道怎么做量化加速,最后服务就荒废了。另一个误区是忽略网络成本,如果你用云服务商提供的代码大模型,每次推理都要走公网,在网络不稳定的环境下体验会很差。这种情况还不如用本地部署的小模型,虽然效果差点但响应稳定。
我习惯用三类指标来评估选型效果。技术指标主要看推理延迟的P99值和服务可用率,这决定了用户体验的下限。业务指标包括代码接受率、每日活跃用户数、平均节省的编码时间,这些数据可以从IDE插件的埋点日志里拿到。成本指标不只算工具费用,还要算GPU折旧、运维人力、因为工具故障导致的研发时间损失。比如商业方案每年花12万美元,但开发者几乎没有故障投诉。开源方案硬件加人力成本第一年10万美元,但因为服务不稳定导致开发者抱怨,还要算上团队士气的隐性损失。从ROI角度看,不一定是开源方案更划算。
未来演进
选型这件事不是技术团队单方面决定的,尤其在大公司。法务要评估代码许可证风险,开源模型的训练数据来源会影响生成代码的合规性。采购要走预算审批流程,你得准备好成本对比表和ROI测算。安全团队会关注数据流向,你需要提供详细的部署架构图,证明敏感代码不会出内网。这种跨部门协作能力在技术管理岗位上特别重要,因为你未来要为团队的技术决策负责。
现在Agent化编程正在改变选型逻辑。Cursor的Composer模式能理解需求后自动修改多个文件,这对代码理解能力要求更高。开源方案要跟上这个趋势,可能需要结合RAG技术,把代码库、API文档、历史提交记录都向量化,这样Agent才能做出更精准的判断。Continue最近支持了MCP协议,可以让AI调用外部工具,比如查数据库Schema、读API文档,这让开源方案在复杂任务上的能力也在快速提升。
我的经验是,选型不要追求一步到位,可以先用商业方案快速验证价值,等团队规模和代码库到一定程度,再考虑自建或混合方案。技术选型的本质是在约束条件下找最优解,而不是追求技术上的完美。纯粹的开源或商业方案都不是最优解,实际落地时往往是混合架构。一个比较成熟的方案是用Continue做统一的IDE插件,后端根据代码仓库路由到不同的模型服务。公开仓库的代码可以调GitHub Copilot的API,内部核心仓库走本地部署的StarCoder,敏感度中等的代码可以用阿里云或腾讯云的代码大模型服务。关键是怎么做路由策略和权限控制,你需要在IDE插件里识别当前文件属于哪个仓库,然后查配置中心决定用哪个后端。如果用户同时打开了公开项目和私有项目,还要保证上下文不会泄露。
技术选型能力的本质是在多个约束条件下做权衡判断,展现出系统性思考和协作推动能力,比单纯的技术深度更有说服力。