精炼回答
对话历史窗口是指在多轮对话中保留的历史消息数量,用于为大模型提供上下文信息。由于模型的token限制和成本考虑,我们不能无限制地保留所有历史对话,需要通过窗口机制来截取最近的若干轮对话。这就像人的短期工作记忆,只能记住最近发生的几件事,时间久远的细节就会自然遗忘。
保留多少轮其实没有固定答案,这取决于你的具体场景。一般来说3-10轮是比较常见的选择。如果是客服场景,可能5轮左右就够了,因为用户的问题往往比较聚焦,"我的订单为什么还没发货""怎么申请退款"这类咨询基本几轮就能解决。但如果是技术咨询或复杂的任务型对话,可能需要保留10轮甚至更多,因为后续问题经常依赖前面的大量上下文,比如用户先描述系统架构,然后问数据库设计,接着讨论性能优化,这些环节环环相扣。
实际应用中你需要权衡几个因素:token成本会随窗口增大线性增长,窗口每扩大一倍,每次调用的费用就跟着翻倍;响应延迟也会变长,模型需要对输入的所有token做Attention计算,输入越长计算量越大;但窗口太小又会导致上下文丢失,模型回答变得答非所问,用户明明刚问过的事情,下一轮就"失忆"了。比较实用的做法是采用滑动窗口策略,保留最近N轮对话,或者使用智能截断,优先保留system提示词和最近几轮,对中间的历史做摘要压缩。有些场景还会根据对话的重要性动态调整窗口大小,比如检测到话题切换时就清空历史,重新开始计数。关键是要在你的实际业务中测试和调优,找到成本和效果的最佳平衡点。
扩展分析
技术约束与实现策略
对话窗口本质上受限于模型的上下文长度,但这里有个容易被忽略的细节。假设你用的是GPT-3.5,它支持4K token,但这4K要同时容纳系统提示词、历史对话和当前输入,还要预留输出空间。如果系统提示词占了500个token,你希望模型能生成最多1000个token的回复,那实际留给历史窗口的就只有2500个token左右。

更麻烦的是token计数的不对称性,用户说"帮我查一下昨天下单的商品物流"这句话可能只有十几个token,但模型返回的物流详情可能就要几百个token。这意味着一轮完整的QA对可能消耗几百个token,所以5轮历史对话轻松就能占掉2000个token。
最简单的固定窗口策略就是保留最近N轮对话,超过就丢弃最早的。实现起来就是个FIFO队列,在Java里用LinkedList或者ArrayDeque就能搞定,每次添加新消息前检查一下size,超限了就removeFirst。但这种方法太机械了,可能正好把关键信息丢掉。比较好的做法是把System Prompt和最近3轮对话强制保留,中间的历史按重要性决定是否保留。怎么判断重要性呢?可以通过关键词匹配、实体识别或者用户明确的引用来判断。比如用户说"就是你刚才说的那个方案",这时候就得往前追溯找到"那个方案"具体是什么,这轮对话就不能简单按时间顺序被淘汰掉。
有些团队会用另一个模型对历史对话做总结,比如把前10轮对话压缩成200个token的摘要,然后只保留摘要加最近3轮原文。这个方法的好处是能保留更长的上下文语义,坏处是增加了额外的模型调用成本和延迟。实际落地时,摘要策略更适合那种对话轮次特别长的场景,比如心理咨询或者法律咨询,用户可能聊20轮以上,如果不做压缩根本装不下。你要算清楚账,如果你的场景中10%的对话会超过窗口限制,那这10%的请求会多一次摘要调用,但每次后续交互都能省下800个token的成本,长期来看还是划算的。
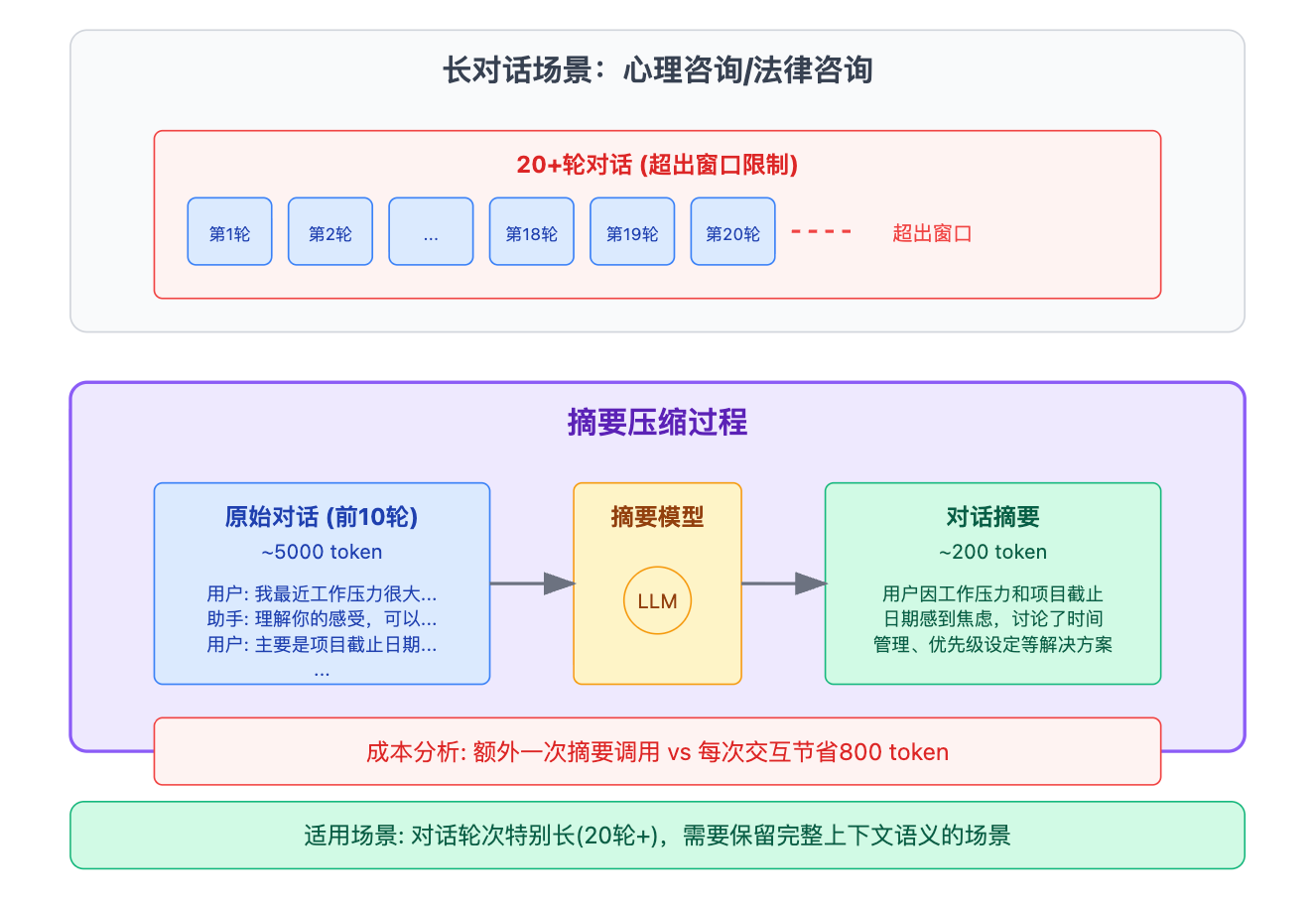
成本是最直观的影响因素。每多保留一轮对话,每次调用模型都要为这些历史token付费。假设单轮对话是200个token,保留5轮就是1000个token,保留10轮就是2000个token。如果你的QPS是100,每天就是860万次请求,多保留5轮意味着每天多消耗86亿个input token。按照OpenAI的定价,这能差出几千美元。响应延迟也会随窗口增大而增加,虽然不是线性关系,但影响确实存在。在实测中,输入token从2K增加到4K,首token延迟大概增加20%到30%,这对实时客服场景来说是不能接受的。
对话质量的影响是个曲线关系。窗口太小会导致模型失忆,用户体验很差。但窗口太大也有问题,模型可能会被过多的历史信息干扰,注意力分散,反而抓不住当前问题的重点。最佳的窗口大小应该刚好覆盖任务所需的上下文范围,既不丢失关键信息,也不引入噪音。对于需要跨会话记忆的场景,光靠对话窗口是不够的。比如用户上周咨询过产品推荐,这周再来,窗口里肯定没有上周的对话了。这时候需要有个外部的知识库或者用户画像系统,把重要信息持久化存储。可以把对话分为短期工作记忆和长期知识记忆,短期记忆就是窗口里的最近几轮,用来处理当前任务的上下文;长期记忆通过向量数据库或者关系数据库存储,在需要时通过检索注入到上下文里。
实践落地方案
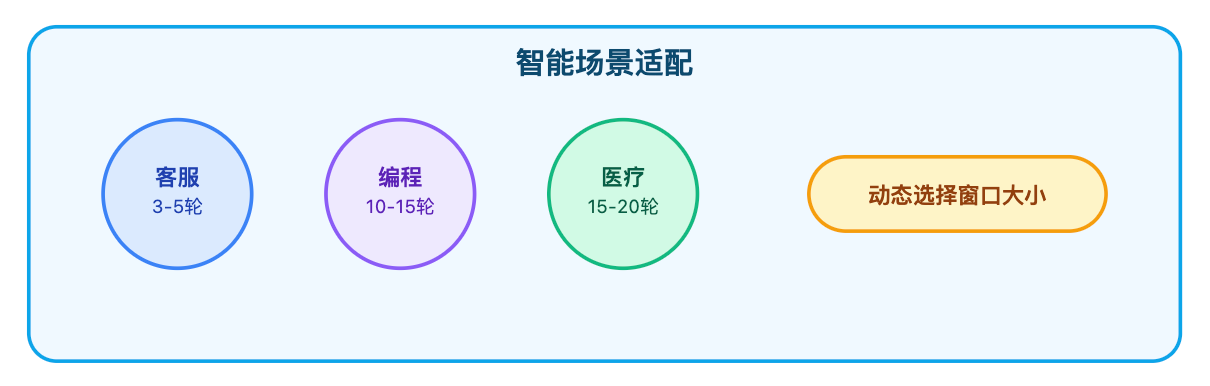
窗口大小没有银弹,要根据场景特点来配置。在线客服这种场景,用户的问题通常比较聚焦,"我的订单为什么还没发货""怎么申请退款"这类咨询,基本上3到5轮就能解决。这时候配置5轮窗口就够了,保留太多历史反而会让模型注意力分散。但如果是智能编程助手,用户可能先描述需求,然后你生成代码,接着他提出修改意见,再优化,再调试,这种场景可能需要10轮甚至15轮的上下文,因为后面的每一步都强依赖前面的代码和需求描述。再比如医疗咨询或者法律咨询这种专业领域,用户往往需要描述复杂的背景信息,然后逐步细化问题,这种场景我见过有团队配置到20轮,因为丢失任何一个关键细节都可能导致诊断出错。
最基础的实现就是用个队列来管理消息列表,代码结构大概是这样:
publicclassConversationWindow{
privatefinalint maxRounds;
privatefinalDeque<Message> messages;
publicConversationWindow(int maxRounds){
this.maxRounds = maxRounds;
this.messages =newLinkedList<>();
}
publicvoidaddMessage(Message message){
// 一轮对话包含用户消息和助手回复,所以是2倍
if(messages.size()>= maxRounds *2){
messages.pollFirst();// 移除最早的用户消息
messages.pollFirst();// 移除对应的助手回复
}
messages.addLast(message);
}
publicList<Message>getContext(){
returnnewArrayList<>(messages);
}
}
这里有个容易忽略的细节,就是一轮对话其实是两条消息,用户输入和模型输出要成对管理。但这种固定窗口的做法太机械了,实际项目中我会加上动态调整策略。比如检测到话题切换时主动清空历史,避免不同话题的上下文互相干扰。判断话题切换可以用简单的规则,像"换个话题""我想问别的"这类明确的表达,或者更智能一点,计算当前输入和最近几轮对话的语义相似度,如果突然降到某个阈值以下,就认为话题变了。
更好的做法是分级保留,System Prompt永远保留,最近3轮强制保留,中间的历史按重要性做取舍。可以给消息打标签,比如用户明确说"记住这个"的内容,或者包含数字、日期、订单号这类关键实体的消息,优先级就高。实现上可以给Message类加个priority字段,溢出时不是简单的FIFO,而是按优先级排序后删除最不重要的。
拿电商场景举例,如果是商品咨询,用户问"这个手机支持5G吗""有什么颜色"这种,其实每轮对话都相对独立,不太需要长上下文。这时候配置一个较小的窗口,比如3轮,就能把成本压到很低。但如果是售后客服,用户可能先反馈问题,然后你问诊断信息,再给出解决方案,这种场景就必须保留完整的上下文,可能需要7轮左右。我会按对话类型做分层配置,用意图识别判断当前是哪种类型,然后动态选择窗口大小。这种设计思路不是一刀切地配置参数,而是根据业务特点做精细化管理。
落地时我的做法是先通过数据分析找到用户对话的轮次分布,比如80%的对话在5轮内结束,那我就把窗口配置成5轮。然后用灰度发布的方式小流量验证效果,看用户满意度和成本的变化。如果发现窗口不够导致理解错误的bad case比较多,就适当增加;如果成本压力大但用户体验没明显提升,就适当减少。上线之后我会重点监控几个指标,一个是窗口截断率,看有多少比例的对话触发了窗口溢出;一个是平均token消耗,这直接关系到成本;还有就是用户的多轮对话完成率,如果窗口配置不合理,用户可能中途就放弃了。通过这些指标的变化趋势,可以及时发现问题并调整策略。

架构演进与扩展思考
对话窗口解决的是短期工作记忆问题,但很多场景需要的知识量远超窗口容量。这时候就要靠RAG来做长期知识的检索注入。比如技术客服场景,用户可能问"上个月你们帮我解决的那个数据库连接问题,用的是什么方案",这种跨会话的信息窗口里肯定没有,但可以通过向量检索从历史工单库里找出来,动态插入到当前上下文。窗口和知识库是两个互补的层次,一个管短期上下文,一个管长期知识,配合起来才能覆盖完整的记忆需求。
现在GPT-4 Turbo已经支持128K上下文,Claude 3甚至能到200K,国产模型像通义千问、文心一言也都在往长上下文方向演进。但要注意一个关键问题:上下文长度和实际可用性不是一回事。模型宣称支持128K,不代表你真的能塞满128K还能保持高质量输出。实测下来,当上下文超过一定长度,模型的注意力会衰减,对中间部分的信息提取能力明显下降,这在学术界叫做"lost in the middle"现象。所以实际项目中,即使用长上下文模型,我还是会控制窗口大小在合理范围,把真正重要的信息通过检索和摘要的方式注入,而不是无脑塞满。
在Agent场景下,对话窗口的管理会更复杂。因为不是简单的用户和助手对话,而是用户、多个Agent、工具调用结果之间的多方交互。这时候窗口里不仅要存用户消息,还要存Agent的思考过程、工具调用的输入输出,信息密度比普通对话高得多。我见过的做法是把Agent的内部思考链路和用户可见的对话分开管理,用户侧保留简洁的交互历史,Agent侧保留完整的推理trace,需要的时候才选择性地把关键推理步骤注入到上下文。这种分层设计能显著降低token消耗,同时保持Agent的决策质量。
对话窗口是内存态的,但用户可能中断会话再回来继续,这时候就需要会话恢复机制。可以把会话ID、窗口内容、用户画像这些信息序列化存到Redis或者数据库里,设置合理的过期时间。比如24小时内用户重新发起对话,就从缓存里恢复完整窗口;超过24小时就只保留关键信息摘要,避免上下文过时导致答非所问。