精炼回答
知识图谱是一种结构化的语义知识库,以图的形式存储和表示现实世界中的实体及其相互关系。它的核心是用节点和边来组织知识,让机器能够理解和推理。你可以把它想象成一张巨大的知识网络,每个节点都是一个知识点,节点之间的连线则说明了它们的关联方式。
这张网络里有三个核心要素。实体就是图中的节点,代表客观存在的事物或抽象概念。比如在医疗知识图谱中,"阿司匹林"、"心脏病"、"张三"都是实体,它们是知识的基本单元。关系是连接两个实体的边,描述实体之间的语义关联。像"阿司匹林-治疗-心脏病"中的"治疗"就是关系,它让独立的实体产生了意义连接。关系是有方向性的,"张三-患有-心脏病"和"心脏病-患者-张三"虽然信息相近但语义方向不同。属性是附加在实体上的键值对信息,用来描述实体的特征。比如实体"阿司匹林"可以有属性"剂型:片剂"、"生产厂家:拜耳"、"有效期:3年",这些属性丰富了实体的描述维度。
在实际应用中,搜索引擎用知识图谱构建右侧的知识卡片,智能问答系统通过遍历关系路径来回答"阿司匹林能治疗什么病",推荐系统利用实体间的关联做个性化推荐。知识图谱本质上是让碎片化的数据建立了可计算的语义网络,这是它区别于传统数据库的关键。
扩展分析
面试中遇到知识图谱这种概念题,你有30秒的黄金时间建立第一印象。很多校招生回答这道题最容易犯的错误就是概念混淆,特别是关系和属性经常搞不清楚。我见过太多同学说着说着就把"价格"说成关系了,这种细节失误会让面试官觉得你理解不够深入。
知识图谱的本质是三元组结构。开场可以这样说:"知识图谱本质上是用三元组来表示知识的,最基础的形式就是'实体-关系-实体'这种结构。这种表示方式让原本散落在文档、表格里的非结构化信息,变成了机器可以直接遍历和推理的网络结构。"这一句话点出了知识图谱和传统数据存储的本质区别,比单纯说图结构更专业,因为三元组是存储和计算的基本单元。
接下来用一个具体例子串起三要素。比如你可以说:"拿电商场景举例,'iPhone 15'是一个实体,'苹果公司'也是一个实体,它们之间通过'生产商'这个关系连接起来。同时'iPhone 15'这个实体本身还有属性,像价格5999元、存储容量256GB、上市时间2023年9月,这些键值对信息就是属性。"这个例子用一句话把实体、关系、属性都说清楚了,而且场景熟悉,面试官很容易理解。
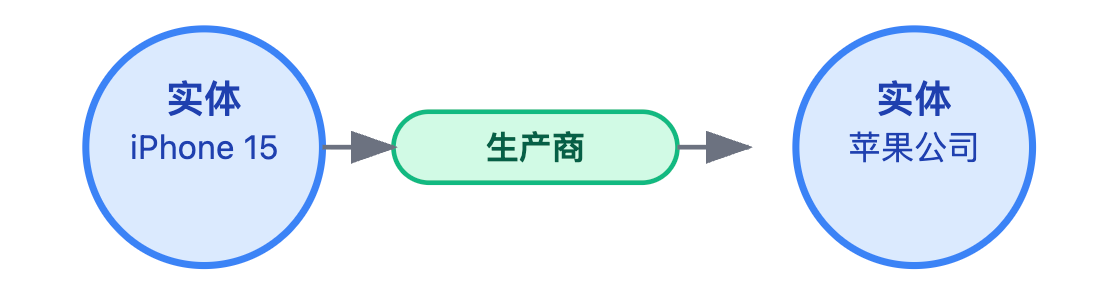
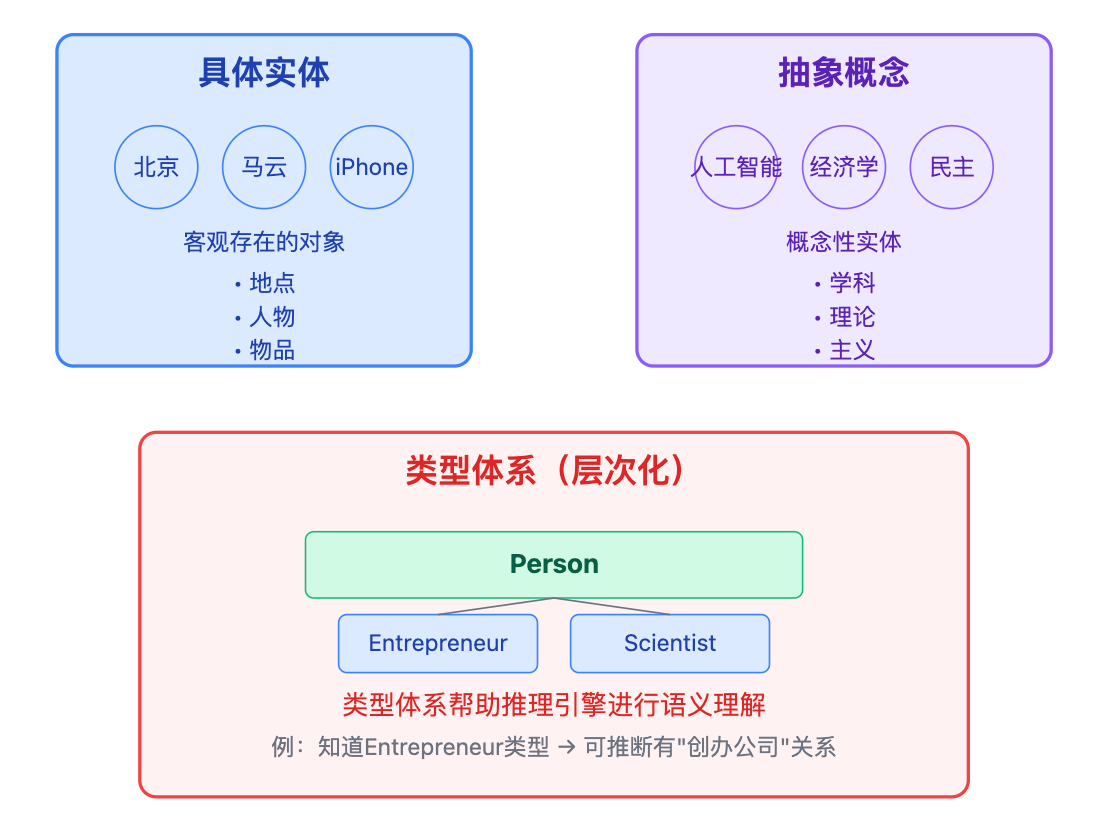
说到实体的时候,很多人只会说"实体就是节点"就结束了,这太单薄。面试官更想听到你对实体的分类理解。实体通常分为具体实体和抽象概念两大类,像"北京""马云"这种客观存在的就是具体实体,而"人工智能""经济学"这种概念性的也是实体。更重要的是,每个实体都有类型标签,比如"马云"属于Person类型,"阿里巴巴"属于Organization类型。类型体系通常是层次化的,像Person下面可以细分为Entrepreneur、Scientist,这种分类帮助推理引擎做语义理解,比如知道Entrepreneur这个类型就能推断出相关实体可能有"创办公司"这种关系。
关系这部分是最容易展现你理解深度的地方。千万别只说关系是连接两个实体的边,这太浅了。关系是有方向性和语义约束的,比如"创办"这个关系,主语必须是人,宾语必须是组织,反过来就不成立。我们不能说"阿里巴巴-创办-马云",这在语义上是不通的。实际应用中关系大致分为几类,像"父子""兄弟"这种家族关系,"创办""任职"这种职业关系,"位于""包含"这种空间关系,还有"治疗""导致"这种因果关系。不同类型的关系在推理时有不同的特性,比如"父子"关系具有传递性,但"朋友"关系通常没有。
属性最容易和关系混淆,面试时一定要说清楚区分标准。属性的值通常是字面量,比如数字、字符串、日期这些基础数据类型,而关系连接的是另一个实体。举个容易混淆的例子:"商品-价格-5999"这里5999是字面量,所以价格是属性。但"商品-生产商-苹果公司"这里苹果公司本身是个实体,所以生产商是关系而不是属性。这个区分标准说出来,基本上面试官就知道你理解透了。属性丰富了实体的静态描述,而关系构建的是实体之间的动态网络。查询"iPhone的价格是多少"只需要读取属性,但回答"iPhone的用户还可能买什么"就需要遍历关系网络。
三者之间的协同关系是个高级话题,但说清楚了能大幅提升你的回答质量。在知识图谱里,实体是骨架,关系是血管,属性是血肉。一个实体通过关系连接到其他实体形成网络,同时自身携带的属性提供详细信息。举个完整的例子:"iPhone 15-生产商-苹果公司"这是关系三元组,但iPhone 15这个实体节点上还挂着"价格:5999""存储:256GB"这些属性,苹果公司这个实体节点上也有"成立时间:1976""总部:库比蒂诺"这些属性。查询时既能通过关系跳转找到相关实体,也能直接读取实体自身的属性信息。
面试官如果问知识图谱和关系数据库有什么区别,这是个送分题。关系数据库是表结构,强调的是数据的规整存储,表之间通过外键关联。知识图谱是图结构,强调的是语义网络,实体之间通过有语义的关系直接连接。在关系数据库里查询"iPhone的用户还买了什么",你得写多表JOIN,先关联用户表、订单表、商品表,逻辑是通过外键追踪数据路径。在知识图谱里,这个查询变成了图遍历:"iPhone-被购买-用户A,用户A-购买-AirPods",直接沿着语义关系走就行。关系数据库适合结构化的事务处理,知识图谱适合需要语义推理和关联发现的场景。
实战应用场景
前面把概念说清楚了,但面试官其实更关心你能不能把知识图谱用起来。很多校招生到这里就开始背应用场景了,什么搜索引擎、推荐系统一股脑全往外倒,结果面试官一追问具体怎么用就卡壳了。谈应用的时候要让面试官感觉到你是从实际问题出发,而不是为了用技术而用技术。
搜索引擎是知识图谱最直观的应用。用户搜"阿司匹林"的时候,右侧会出现一个知识卡片,显示它的成分、用途、副作用。这不是简单的关键词匹配,而是搜索引擎从知识图谱里把"阿司匹林"这个实体节点,以及它的属性和关系网络一次性提取出来展示。更进一步,当用户搜"治疗头痛的药",系统会先识别出"头痛"这个症状实体,然后沿着"治疗"关系找到所有相关的药物实体,这就是语义搜索。传统关键词搜索做不到这种理解层面的匹配。
智能问答系统处理多跳推理是知识图谱的强项。处理"iPhone的创始人是谁"这种问题,需要先识别出"iPhone"和"创始人"两个关键信息,然后在知识图谱里找到"iPhone-生产商-苹果公司",再找到"苹果公司-创始人-乔布斯",经过两跳关系得到答案。更复杂的问题像"乔布斯创办的公司生产了哪些产品",这需要反向遍历和多分支查询,先从"乔布斯"找到"创办"关系连接的所有公司实体,再从这些公司找"生产"关系连接的产品实体。这种多步推理是传统数据库很难高效完成的。
风控场景下,知识图谱用来识别隐藏的关联风险。比如一个贷款申请人的手机号、地址、设备ID在图谱里和多个黑名单用户有关联路径,即使这个人本身没有不良记录,系统也能通过关系传播计算出风险评分。所谓关系传播就是沿着关系边给实体节点打分,黑名单用户的分数会按一定衰减率传递给关联实体,当一个新用户和多个高风险节点有路径连接,他的风险分就会累加上去。
说完应用场景,构建流程也是面试常问的点。构建流程主要分三步:实体识别、关系抽取和知识融合。实体识别是从文本里把有意义的名词短语提取出来,像从新闻"苹果公司发布iPhone 15"里识别出"苹果公司"和"iPhone 15"这两个实体。关系抽取是判断实体之间的语义连接,这个例子里要识别出"发布"这个关系。知识融合是把不同来源的知识合并,比如多篇新闻都提到iPhone 15,系统要判断它们说的是同一个实体,把信息整合到一个节点上。
存储方案上,知识图谱通常用图数据库,Neo4j是最常见的选择。它的优势是原生支持图遍历,查询"从实体A出发三跳内能到达哪些实体"这种问题,图数据库比关系数据库快几个数量级。下面是一个简单的Neo4j查询示例:
// 查询iPhone相关的两跳推荐
MATCH(product:Product{name:'iPhone 15'})-[r1]-(entity1)-[r2]-(entity2:Product)
WHERE entity2.name <>'iPhone 15'
RETURNDISTINCT entity2.name, entity2.price
LIMIT10这个查询会找到所有和iPhone 15有两跳关系的其他产品,可以用来做关联推荐。在传统关系数据库里实现同样的逻辑,需要多层嵌套的JOIN,性能会差很多。
技术进阶思考
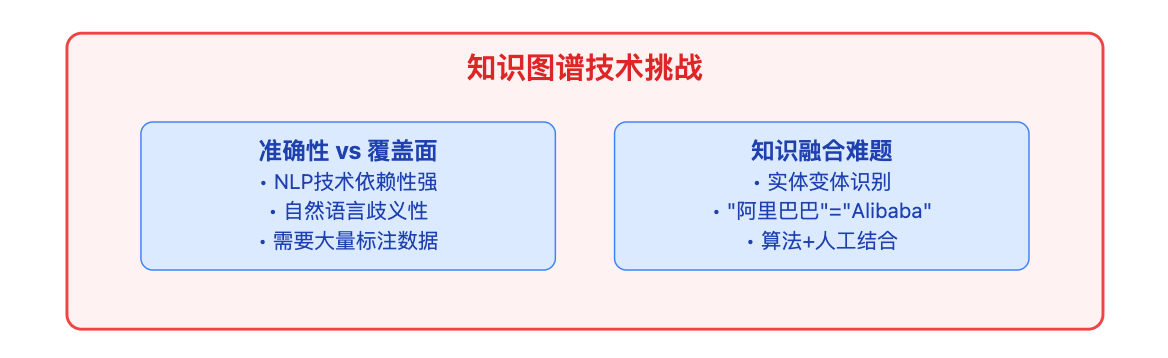
知识图谱最大的难点是知识抽取的准确性和覆盖面之间的平衡。实体识别和关系抽取依赖NLP技术,但自然语言的歧义性很强,像"苹果发布新产品"这句话,苹果可能是公司也可能是水果,发布可能是正式推出也可能只是透露消息。更难的是知识融合,不同数据源对同一个实体的表述可能完全不同,"阿里巴巴"和"Alibaba"和"阿里集团"指的是同一个公司,系统需要判断这些变体应该合并成一个实体节点。这个过程既需要算法支持,也需要大量人工标注数据来训练模型。
知识图谱本质上是让碎片化的数据建立了可计算的语义网络,这个转变让机器从记忆信息升级到理解信息。无论是搜索、推荐还是问答,核心都是利用这张语义网络做关联发现和推理决策。知识图谱其实是AI从感知智能走向认知智能的关键一步,深度学习让机器学会了识别图像和理解语音,但要做复杂推理和决策,还需要结构化的知识作为支撑。这就是为什么各大科技公司都在投入巨资构建自己的知识图谱,因为它是通往真正智能的必经之路。