精炼回答
Self-Consistency是一种提升大模型推理准确性的技术,核心思想是让模型对同一个问题生成多个不同的推理路径,然后通过投票选出最一致的答案。本质上是Chain-of-Thought的增强版本。
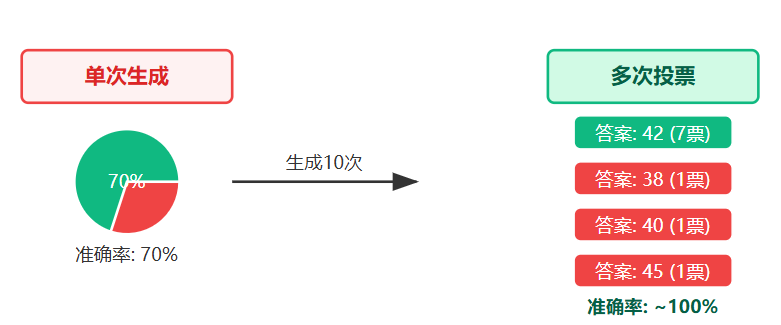
这个方法的必要性源于大模型的采样随机性。当你用非零temperature采样时,模型每次生成的推理过程都可能不同,但如果推理正确,多数路径应该会收敛到相同答案。比如让模型解数学题,可能有的路径用代数方法,有的用几何方法,但正确答案应该一致。多次生成加投票能够有效降低单次推理的偶然错误。单次生成时,模型可能因为某个推理步骤的随机性走向错误分支,最终得出错误答案。但当你生成10次、20次时,偶然性错误会被稀释,真正正确的答案会在多数路径中出现,这就像用统计学的方式对抗随机性。
在实际应用中,比如医疗诊断辅助、代码bug分析这类需要高准确率的场景,Self-Consistency特别有价值。虽然增加了计算成本,需要多次推理,但通过投票机制能显著提升输出可靠性,是用算力换质量的典型策略。
扩展分析
深入理解:从问题起源到设计哲学
要真正理解Self-Consistency,需要从Chain-of-Thought的局限性讲起。CoT让模型生成推理步骤确实提升了准确率,但有个致命问题:单次生成的推理路径可能受随机性影响走偏。就像走迷宫,一开始选错了岔路口,后面再怎么认真走也到不了终点。
那为什么同一个模型对同一个问题会产生不同的推理路径?这涉及到语言模型的生成机制。大模型生成文本时不是每次都选概率最高的那个词,而是根据概率分布采样。temperature参数控制这个分布的平滑度,当temperature大于0时,每次采样会带来随机性。比如模型在某个推理步骤可能有三种思路,概率分别是0.5、0.3、0.2,那它可能这次选第一种,下次选第二种。正是这种随机性让多次生成产生了不同的推理路径。
这里有个关键点需要强调:不同的推理路径不等于胡乱猜测。虽然采样有随机性,但模型学到的知识和推理能力是确定的。不同路径就像不同的解题方法,有的用代数有的用几何,但只要推理逻辑正确,最终答案应该一致。那些因为偶然性走偏的路径会得出不一致的错误答案,而正确的推理路径会自然收敛到同一个结果。这就是Self-Consistency设计的核心哲学:用推理路径的一致性来验证答案的正确性。
投票机制的有效性可以从概率的角度理解。假设模型真实的推理能力能让它有70%的概率生成正确路径。单次生成时,你有30%的概率拿到错误答案。但如果生成10次,那些30%的错误会分散到不同的错误答案上,而70%的正确概率会让正确答案在多次生成中反复出现。投票时,正确答案得票最多的概率会远高于70%。比如一道数学题的答案是42,10次生成中可能7次得到42,剩下3次分别得到38、45、40。投票时42以绝对优势胜出,准确率从70%提升到接近100%。
从理论角度看,用贝叶斯的视角来理解会更深刻:我们真正想要的是在所有可能推理路径上的边缘概率分布。单次生成只采样了一条路径,Self-Consistency通过多次采样近似了这个边缘分布,投票选出的答案本质上是后验概率最大的那个。这种理论基础让Self-Consistency不只是一个工程技巧,而是有坚实数学基础的方法论。
Self-Consistency和其他方法有着本质区别。和传统集成学习对比,集成学习是训练多个不同的模型,每个模型的知识结构不同。而Self-Consistency是同一个模型的多次采样,利用的是推理路径的多样性而不是模型的多样性。成本上也完全不同,集成学习需要训练和维护多个模型,Self-Consistency只需要一个模型多次推理。和Beam Search对比,Beam Search是在解码过程中同时维护多条概率最高的路径,目标是找到全局概率最大的序列。而Self-Consistency是让推理过程本身具有随机性,生成多条不同的推理路径后投票。关键区别在于,Beam Search追求的是模型认为概率最高的答案,Self-Consistency追求的是推理逻辑最一致的答案。在翻译任务中,Beam Search会找出模型认为最流畅的译文。但在数学推理中,概率高不等于逻辑对,Self-Consistency通过多样化采样和投票,能发现那些推理路径正确但表述方式不同的答案。
实践落地:从理论到工程实现
在实际项目中使用Self-Consistency,首先要判断任务类型。Self-Consistency最适合那些有明确正确答案的场景,像数学应用题求解、代码bug诊断、逻辑推理这类任务,投票才有实际意义。开放式创作任务比如写营销文案、生成创意广告语,每次生成都应该有独特性,投票反而会扼杀创造力。

实现时有两个关键参数需要调整。temperature通常设置在0.7到1.0之间。这个值如果太低,比如0.1,每次生成的路径会非常相似,失去了多样性采样的意义;太高,比如1.5,生成的推理可能太发散,质量不稳定。
采样次数的选择本质上是在成本和收益之间找平衡,一般从5次开始测试,观察答案分布的收敛情况。如果5次里有4次都得到同一个答案,说明模型对这个问题比较确定,5次可能就够了。但如果答案很分散,就需要增加到10次甚至20次。实际项目中可以记录不同任务类型的历史数据,比如代码生成任务平均需要8次采样才能稳定,那就把8次作为这类任务的默认值。
投票策略需要根据任务特点灵活选择。对于分类任务,比如判断一段文本是正面还是负面情感,简单的多数投票就很有效。假设生成10次,8次判断为正面,2次判断为负面,那答案就是正面。
但对于生成任务就复杂一些,比如代码生成,10次可能产生10段不完全相同的代码,这时候不能简单统计完全匹配的次数。可以提取关键要素做投票,比如代码的核心算法逻辑、关键API调用、边界条件处理等,只要这些关键部分一致,就认为是同一个答案。或者换个思路,让模型对这10段代码再做一次判断,选出最合理的那段,相当于用模型自己来评估一致性。
用Python实现的核心逻辑大概是这样:
defself_consistency_reasoning(prompt, model, n_samples=10):
"""
Self-Consistency推理实现
Args:
prompt: 输入提示词
model: 语言模型实例
n_samples: 采样次数
Returns:
final_answer: 投票得出的最终答案
confidence: 答案的一致性程度(0-1之间)
"""
answers =[]
# 多次采样生成不同推理路径
for i inrange(n_samples):
response = model.generate(
prompt,
temperature=0.8,# 保持适度随机性
max_tokens=512
)
# 从完整推理过程中提取最终答案
answer = extract_final_answer(response)
answers.append(answer)
# 统计投票结果
from collections import Counter
vote_counts = Counter(answers)
final_answer = vote_counts.most_common(1)[0][0]
# 计算置信度
confidence = vote_counts[final_answer]/ n_samples
return final_answer, confidence
defextract_final_answer(response):
"""
从模型生成的完整推理过程中提取最终答案
这个函数需要根据具体任务设计提取逻辑
"""
# 示例:匹配"答案是"或"答案为"后面的内容
import re
match= re.search(r'答案[是为][::]?\s*(\S+)', response)
ifmatch:
returnmatch.group(1)
# 如果没匹配到,返回最后一个数字或关键词
return response.strip().split()[-1]这个实现中有个关键设计:返回confidence值表示答案的一致性程度。如果10次生成中9次都是同一个答案,confidence就是0.9,说明模型很确定。但如果最高票答案只出现了3次,confidence只有0.3,这时候可能需要人工介入检查,或者增加采样次数再试。这个置信度在实际业务中非常有用,可以作为是否需要人工复核的判断依据。
在Google的论文中,他们在GSM8K这个数学推理数据集上测试,Self-Consistency把GPT-3的准确率从57%提升到了74%,涨了17个百分点。在常识推理任务CSQA上,准确率从70%提升到83%。但这个提升幅度和任务特性强相关,如果任务本身推理路径的多样性很高,提升就明显;如果任务比较简单,单次就能做对,Self-Consistency的增益就有限。
成本问题是实际落地时绕不开的话题。Self-Consistency最大的代价是推理成本成倍增加。如果单次推理耗时1秒,生成10次就是10秒。在对延迟敏感的场景,比如实时客服对话,这个延迟可能不可接受。但如果是离线分析任务,比如批量处理用户反馈做情感分类,10倍的时间成本是可以接受的,因为准确率提升带来的业务价值更大。拿电商场景来说,如果是用AI审核商品描述是否违规,单次检查可能漏掉一些边界case。这时候用Self-Consistency生成5次,投票决定是否违规,虽然审核时间从100毫秒增加到500毫秒,但能把误判率降低一半,避免误封正常商品或者漏放违规商品,这个trade-off是值得的。
为了降低成本,可以用动态采样策略。先生成3次,如果3次答案完全一致,就直接返回,不需要继续生成。只有当答案不一致时,才继续采样到10次。这样在模型比较确定的问题上能节省大量计算。另外可以把采样并行化,10次推理同时发起,总延迟还是单次推理的时间,只是消耗了更多GPU资源。这种工程优化在实际项目中能显著改善用户体验。
场景判断与技术组合
判断什么时候该用Self-Consistency,需要满足三个条件:任务有明确的对错标准,能客观判断答案正确性;单次推理的准确率还有提升空间,不是已经接近100%;业务能接受成倍的计算成本,或者错误的代价远高于计算成本。满足这三点,Self-Consistency就是个值得尝试的方案。
Self-Consistency在整个prompt工程体系中是提升可靠性的重要手段,它和Few-shot、CoT、思维树等技术是互补的关系。可以先用Few-shot给出示例,再用CoT引导推理,最后用Self-Consistency做验证。比如在做智能客服的时候,如果遇到用户问题理解错误会导致整个对话走偏的情况,可以考虑用多路径验证思路,先生成多种理解方式,然后判断哪种最合理。虽然可能因为延迟要求没有完全采用,但这个思路和Self-Consistency的本质是一致的——用冗余计算换取鲁棒性。理解这些技术的组合方式,才能在实际项目中灵活应对不同场景的需求。