精炼回答
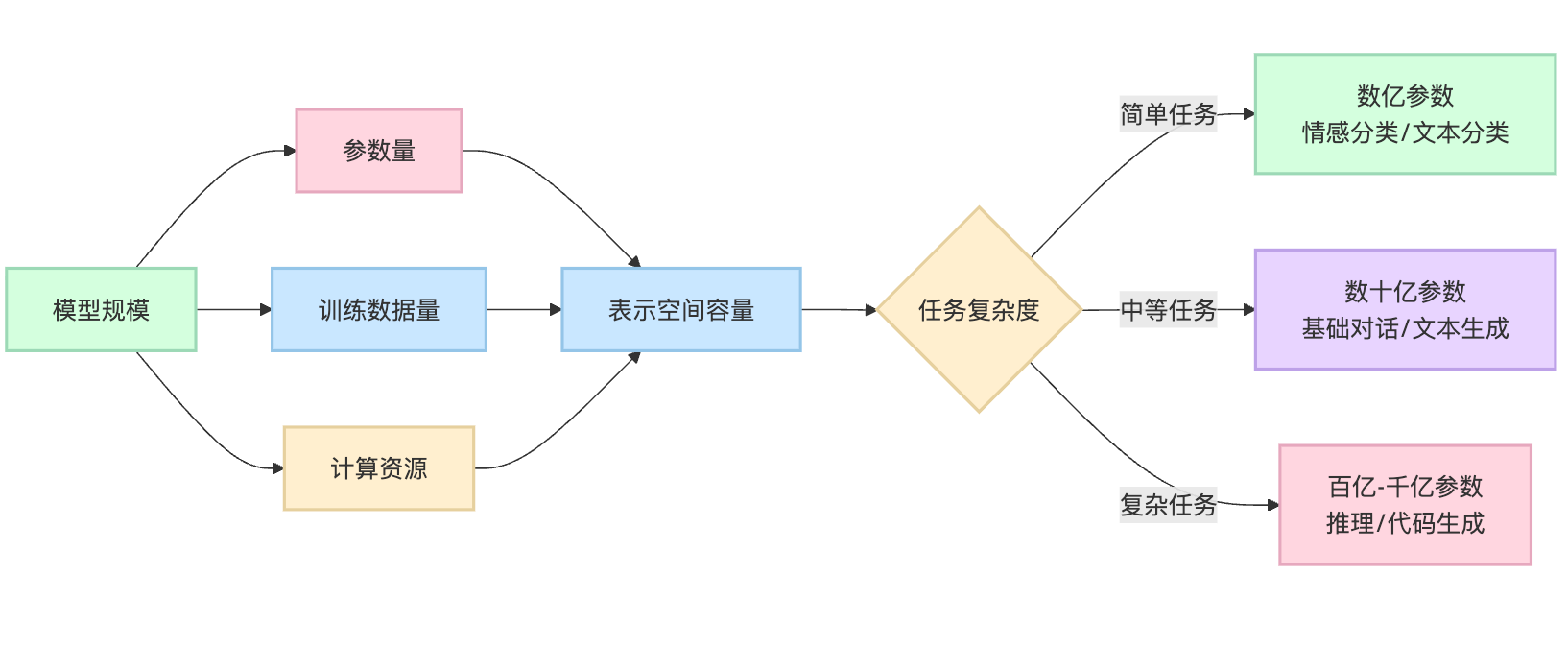
模型规模增大带来能力提升,本质上是参数量增加扩展了表示空间的容量。更多参数意味着能存储更丰富的语言模式、知识关联和推理路径,网络深度和宽度的增长让模型能捕捉更复杂的特征层次和抽象关系。你会发现10亿参数的模型可能只能做简单的文本分类,但到了70亿参数就能进行基础对话,1750亿参数的GPT-3展现出few-shot学习能力,而千亿级别模型开始涌现复杂推理和代码生成能力。
关于临界点,确实存在涌现现象的阶段性跃迁。研究表明某些能力像多步推理、算术运算在特定规模以下几乎不可用,跨过某个阈值后突然显著提升,这个阈值因任务而异,通常在百亿到千亿参数之间。不过规模收益并非无限递增,当前观察到边际收益递减的趋势——从1000亿扩展到10000亿的提升幅度,明显小于从100亿到1000亿的跨越。实际中还受制于数据质量和训练方法,单纯堆参数在高质量数据耗尽后效果会打折扣。现在的研究方向已经转向在合理规模下优化训练效率、数据配比和对齐策略,而不是盲目追求更大规模。
扩展分析
面试时被问到这个问题,千万别上来就开始讲神经网络原理或者背论文结论。面试官更想听到的是你对Scaling Law这个核心逻辑的理解。Scaling Law本质上揭示了一个幂律关系,也就是说模型的损失函数随着规模增长呈现可预测的下降趋势。但这里有个关键点要特别强调——不是单纯增加参数就行,而是参数量、训练数据量和计算量这三个维度需要协同增长。这就像盖房子,你不能只加钢筋不加水泥,三者得按比例配合才能发挥效果。
当你回答这个问题时,开场30秒可以这样组织:先一句话点出"模型规模越大能力越强,这背后遵循Scaling Law规律",然后立刻补充"但这个规律成立需要三要素同步扩展——参数量、训练数据和计算资源"。这样既显得有理论支撑,又不会陷入空泛的概念堆砌。面试时你可以直接说"OpenAI在2020年的研究发现,当我们把参数量从N扩展到10N时,如果数据量和算力也相应增长,模型损失会按照幂律曲线稳定下降"。这种表达既展示了你对经典研究的了解,又没有陷入公式推导的细节。
关于临界点这个追问,直接给出判断会比犹豫更好。你可以明确说"存在临界点,但它不是固定数值,而是随具体任务变化"。涌现能力指的是模型在某个规模阈值之前,对特定任务的表现几乎是随机猜测的水平,但跨过这个阈值后性能会发生质的飞跃。这不是线性渐进的改善,而是类似相变的突变过程。举个容易理解的例子,拿多步数学推理来说,一个60亿参数的模型可能完全做不了三位数加法的连续运算,准确率只有百分之几,但当参数扩展到620亿之后,同样的任务准确率能冲到70%以上,这中间不是慢慢爬升的,而是在某个规模附近突然跃升的。
这时候如果能举个对比案例就很加分了。情感分类这种简单任务,可能几亿参数就接近天花板了,BERT这个量级的模型(3亿参数左右)就已经接近人类水平,继续扩大规模收益很小。但多步推理能力通常要到百亿参数规模才开始显现,像代码生成、逻辑推理这种需要深层抽象的能力,你会发现GPT-2的15亿参数时基本不可用,GPT-3扩展到1750亿参数时才真正展现出实用价值。GPT系列的演进就是最好的说明材料:GPT-1的1.17亿参数主要验证了预训练的可行性,GPT-2扩展到15亿参数时能生成连贯文本但缺乏指令理解,GPT-3跳到1750亿参数后突然展现出few-shot学习能力——给几个例子就能完成新任务,这在更小规模时几乎不可能实现。而Google的PaLM模型在5400亿参数时,在推理任务上又比GPT-3有明显提升,特别是那些需要多步骤逻辑链的场景。讲完例子记得回扣一句"所以临界点本质上取决于任务复杂度和所需的知识抽象层次"。
不过面试时一定要补充Chinchilla Law带来的新认识。DeepMind在2022年的研究发现,之前很多模型其实是"参数过剩但数据不足"。他们提出对于一个N参数的模型,最优训练数据量应该大约是20N个token,这个比例比之前普遍采用的配置要高得多。你可以说"这就解释了为什么Chinchilla虽然只有700亿参数,但因为用了1.4万亿token的训练数据,在很多任务上反而超过了1750亿参数的GPT-3——不是规模不重要,而是我们之前没把数据这个维度扩展到位"。这个观点能展示你对最新研究的理解,也说明了你不是简单地认为"越大越好"。
如果面试官继续深挖,你要准备好边际收益递减这个点。可以补充说"不过从业界实践看,规模扩展到一定程度后收益会明显放缓,这也是为什么现在大家开始更关注训练方法和数据质量的优化"。从GPT-3的1750亿到PaLM的5400亿,参数量增长了3倍,但在很多基准测试上的提升可能只有几个百分点,这跟从GPT-2到GPT-3那种跨越式进步完全不是一个量级。而且训练成本是超线性增长的,这也是为什么现在业界开始转向探索混合专家模型、高效微调这些方向,而不是一味堆大模型。这种回答既展示了对前沿趋势的了解,又避免给人留下"只会堆算力"的印象,既承认了规模的价值,又说明了你理解实际工程中的权衡考量,会让面试官觉得你是个有全局观的候选人,而不是只会纸上谈兵的理论派。
实践应用
面试时如果能把前面那些理论说得头头是道,面试官十有八九会追问一句:"那实际项目中你会怎么决策?"这个问题其实是在考察你有没有工程思维,会不会只是纸上谈兵。我见过不少同学这时候就慌了,开始含糊地说"看情况而定",这种回答等于没说。你得给出一个清晰的决策框架,让面试官看到你能把理论落地。
先说明评估是否需要更大模型,你会看三个维度——任务复杂度、现有模型的瓶颈表现、以及资源约束。然后立刻给个具体判断标准:"如果当前模型在验证集上已经过拟合,loss不再下降但指标提升缓慢,同时错误case主要集中在需要复杂推理的场景,这时候才考虑扩大规模。但如果错误更多是因为训练数据的噪声或者分布偏差,那优先要做的是清洗数据而不是换大模型"。这种回答既展示了你的分析能力,又说明你不会盲目追求大模型。
成本权衡这块特别容易让面试官看出你是不是有实战经验。你可以直接说:"训练一个百亿参数模型和十亿参数模型,成本可能差十倍以上,但性能提升可能只有几个点。我会先用小规模模型做消融实验,比如在1亿、10亿、50亿这几个档位上分别训练几个epoch,观察loss下降曲线和关键指标的变化趋势。如果发现50亿参数时曲线还在陡降,那继续扩展可能有收益;但如果已经趋于平缓,那说明瓶颈不在模型容量,投入更多算力性价比就很低了"。这种表达方式既务实又专业,面试官会觉得你是真的思考过这个问题。
对于小团队来说,这个话题特别能体现你的资源意识。面试时可以坦诚地说:"如果团队算力有限,我会优先考虑三个路径——用开源模型做base然后在垂直领域数据上微调、通过知识蒸馏把大模型能力迁移到小模型、或者用Adapter这类参数高效的方法只训练少量参数"。这里可以举个接地气的例子:拿商品描述生成来说,与其从头训练一个百亿模型,不如拿LLaMA-7B在电商语料上做LoRA微调,可能只需要训练几千万参数就能达到接近的效果,训练时间和成本能压缩到原来的十分之一。这种回答既展示了你对前沿技术的了解,又说明你会根据资源情况灵活选择方案。
Chinchilla Law在实践中的应用是个特别好的加分点。现在我选模型规模时会反向计算数据需求,假设准备了5000亿token的高质量数据,按照Chinchilla的1:20比例,最优的模型规模应该在250亿参数左右,而不是硬上千亿参数但数据不够导致欠训练。实际中我会更看重数据质量而不是单纯的数量,宁愿花时间做数据清洗、去重、多样性筛选,也不会为了凑token数去爬一堆低质量网页。因为垃圾数据喂得再多,模型也学不到有用的模式。这种回答能让面试官感受到你对数据价值的深刻理解。
识别任务临界点这个技巧特别实用。我会用渐进式扩展的策略来探测,先在小规模模型上跑通整个pipeline,然后按2倍、5倍、10倍这样的步长逐步扩大,每个档位都在关键测试集上跑eval。如果发现某个指标在某个规模点突然跳升,比如从30%准确率跃升到65%,那这个规模附近可能就是该任务的涌现阈值。特别要关注那些需要多步推理的任务,它们的临界点通常比简单分类任务高得多,可能在数十亿到上百亿参数之间,提前做小规模实验能避免盲目投入。
最后一定要主动提避坑指南,这能让面试官看出你的成熟度。最常见的误区就是看到别人用千亿模型效果好就直接照搬,完全不考虑自己的任务特点和数据情况。我见过有些场景其实是典型的长尾分布问题,真正需要解决的是如何让模型在低频样本上也有稳定表现,这时候做好数据增强和困难样本挖掘,可能比单纯扩大模型规模更有效。还有个容易忽视的点是推理成本,训练时用大模型可能还能接受,但如果上线后每次请求都要调用千亿模型,延迟和GPU成本可能完全无法承受。所以选型时要提前考虑部署场景,必要时通过蒸馏或量化把最终serving的模型压缩到可接受的规模。这种全链路的思考方式会让面试官印象深刻,觉得你不是只会调参的算法工程师,而是真正能解决实际问题的人。
扩展思考
面试时回答这个问题,面试官其实不只是在考察你对Scaling Law的理解,更深层的意图是看你有没有对AI领域的全局认知和批判性思维。很多校招生会觉得自己没做过大模型项目就没底气谈这个话题,但其实面试官更看重的是你的思考方式和技术判断力,而不是你调过多大的模型。关键是要展现出你理解技术趋势但不盲从、认可规模化价值但也看到局限性的成熟心态。
当你把前面的理论和实践都说完之后,面试官很可能会继续追问一些开放性问题来测试你的思考深度。比如会问"你觉得模型规模会一直扩展下去吗"或者"除了堆参数还有什么方向",这时候千万别给出那种模棱两可的答案。你可以明确表态:规模化是重要路径但不是唯一路径,现在业界已经在探索更高效的架构创新了。然后立刻举个具体方向,比如像Mixture of Experts这种稀疏激活的架构,Google的Switch Transformer有1.6万亿参数,但每次推理只激活其中一小部分专家网络,这样就能在保持模型容量的同时大幅降低计算成本。这种回答既说明你关注前沿,又展示了对技术演进路线的理解。
如果面试官问到具体数值,比如"你觉得多少参数是个合理的上限",这其实是个陷阱问题,没有标准答案。聪明的回答方式是把问题转化成场景讨论:对于通用对话来说百亿参数可能是个性价比不错的区间,但对于需要深度专业知识的领域比如法律咨询或医疗诊断,可能需要更大规模来容纳海量领域知识。然后可以补充一句"不过我更关注的是单位参数的知识密度,现在很多研究在探索如何通过更好的训练目标和数据配比,让小模型也能达到大模型的效果"。这样回答既没有给出武断的数字,又说明你理解问题的复杂性。
即使你没有实际训练过大模型,也完全可以谈自己的观察和思考。面试时可以说"虽然我没有从头训练过百亿级模型,但在跟进开源社区的实践中,我注意到一个有意思的现象——同样7B参数规模,LLaMA经过精心设计的训练策略,效果能超过很多更大规模但训练不够充分的模型"。然后自然过渡到你的思考:"这让我意识到模型能力不只取决于参数量,训练数据的质量、tokenizer的设计、甚至学习率调度这些细节都可能带来非线性的影响"。这种表达方式既诚实又有见地,面试官会觉得你是个善于学习和总结的人。
展现批判性思维的时候,可以主动提出对规模化路线的反思。当前这种暴力扩展的趋势某种程度上是因为我们还没找到更本质的智能涌现机制,人类大脑才860亿神经元,但我们的模型已经上万亿参数了,这说明参数效率还有巨大提升空间。现在有些工作在探索动态网络、神经架构搜索、还有受生物启发的脉冲神经网络,这些可能代表着超越简单规模扩展的新范式。这种回答能让面试官看到你不是只会跟风追热点,而是真的在思考技术的本质和未来。
最后要把技术理想和工程现实平衡好。面试官可能会问"如果让你设计下一代AI系统,你会怎么做",这时候可以坦诚地说:理想状态下我当然希望有无限算力去训练万亿参数模型,但实际中更现实的路径可能是混合架构——用一个中等规模的基座模型做通用理解,然后针对不同垂直领域配上专门优化的小模块,通过模块化设计在性能和成本之间找平衡。这种务实的思路恰恰是面试官想看到的,说明你不只会谈技术概念,更懂得在约束条件下做最优决策。